爬虫逆向学习(二):那些年遇到的花式字体反爬
常见字体反爬破解策略
- CSS偏移反爬虫
-
- 案例场景
- 破解策略
- SVG字体反爬
-
- 案例场景
- 破解策略
- 自定义字体反爬
-
- 案例场景
- 破解策略
CSS偏移反爬虫
案例场景
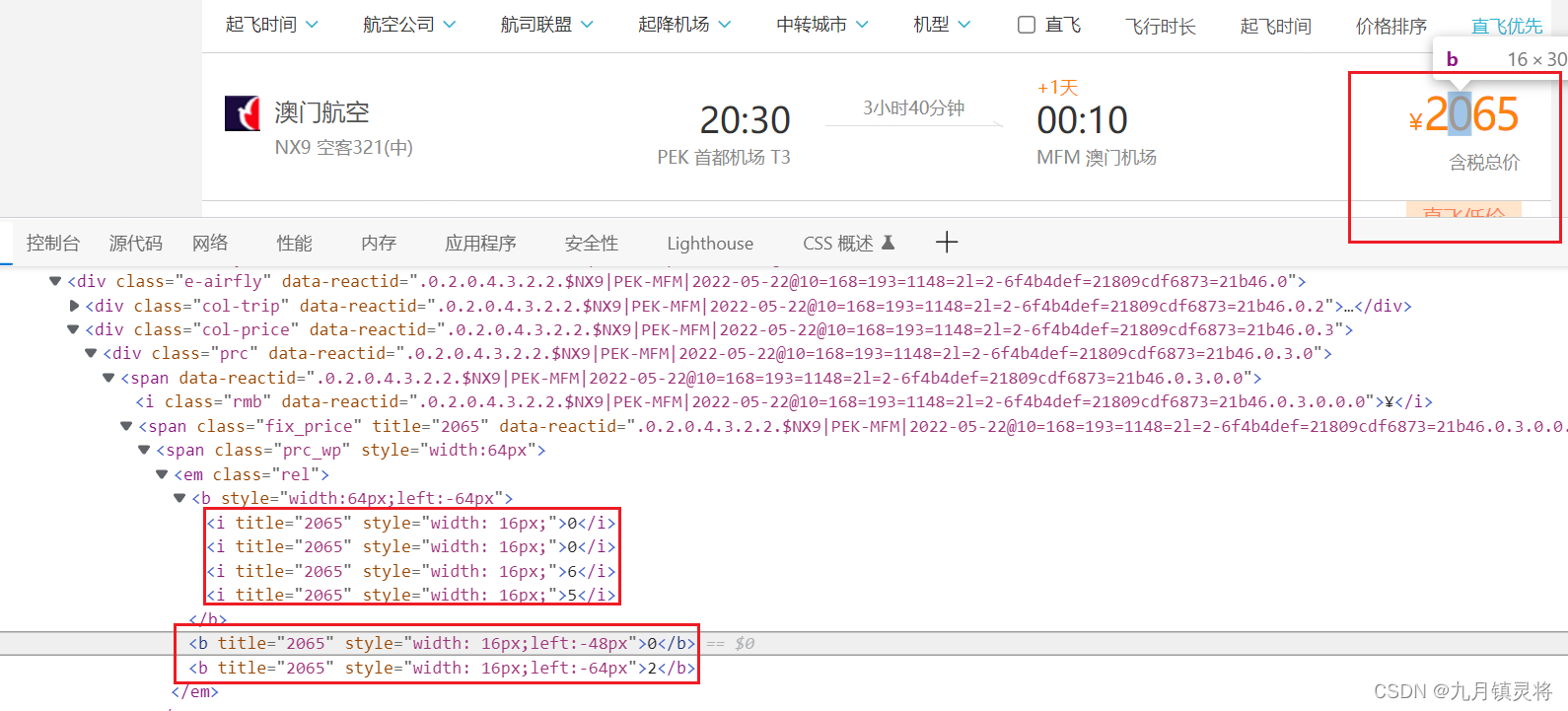
css偏移反爬虫是通过样式left偏移覆盖数据实现反爬,如下图所示,这个某哪儿的机票数据,一般情况下,红色框中三个b标签我们会提取第一个,但是仔细观察会发现第一个b标签的数据跟页面展示的不一样,第一个b标签提取到的文本是0065,而页面展示的是2065,明显是错误数据。
这个时候我们仔细观察第二个b标签和第三个b标签,发现第二个b标签的文本跟页面展示的文本中的第二个数字一致,第三个b标签的文本跟页面展示的文本中的第一个数字一致,同时style样式中left有规律性的倍数,可以确定是通过left偏移覆盖的。
破解策略
css偏移反爬虫中left偏移是有规律的,我们只要知道偏移的倍数和每个文本的偏移位置即可解决问题。继续观察上图b标签的样式,left出现的长度有-64px、-48px、16px,因此可以确定偏移的倍数是16。
前面我们已经知道第二个b标签的文本跟页面展示的文本中的第二个数字一致,第三个b标签的文本跟页面展示的文本中的第一个数字一致,同时第一个b的left长度是64px,我们用第二个和第三个b标签的left与64px相减,就能确定第三个b标签的位置为第一个,第二个b标签的位置为第二个,这样就能解决反爬了。

SVG字体反爬
案例场景
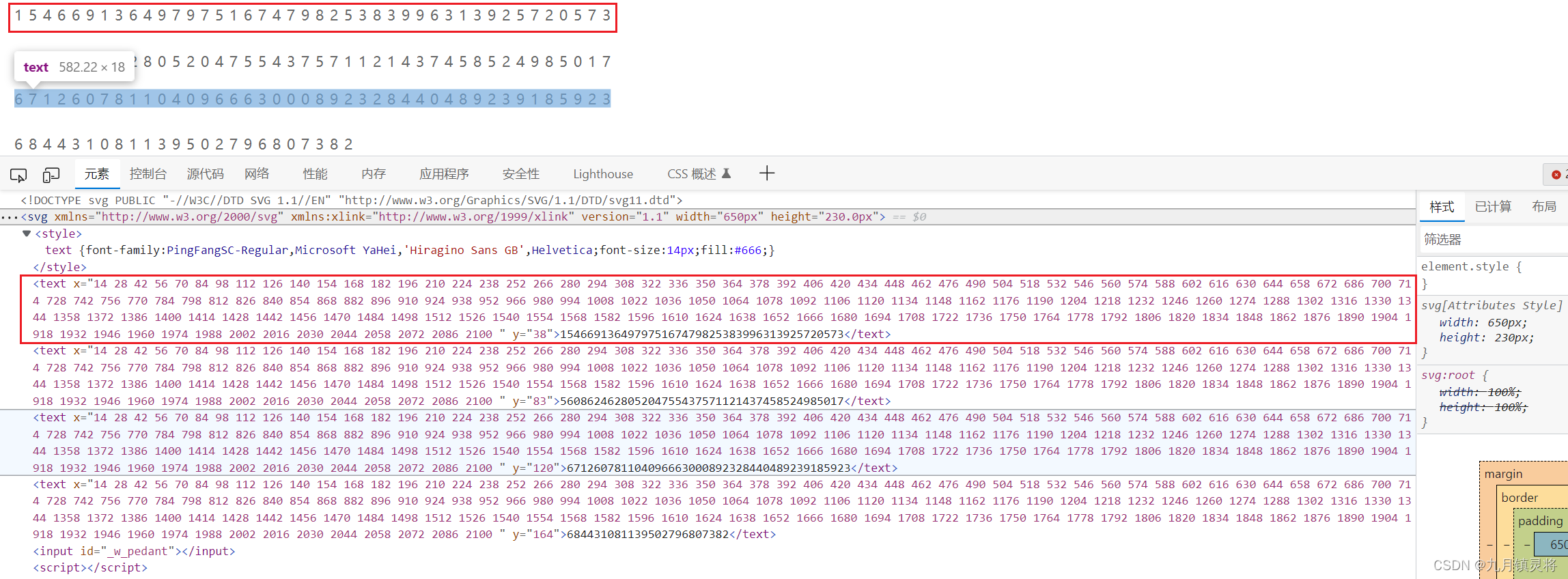
SVG字体反爬会在css中加载一个svg字体文件,通过设置标签的background值来偏移显示对应的svg字体。如下图所示,界面显示正常的电话号码,但是看代码却发现d标签都是没有文本,我们随便点击一个d标签,通过右侧可以发现d[class^="vhk"]标签的background-image样式加载了一个svg文件,.vhk08k设置了一个background值
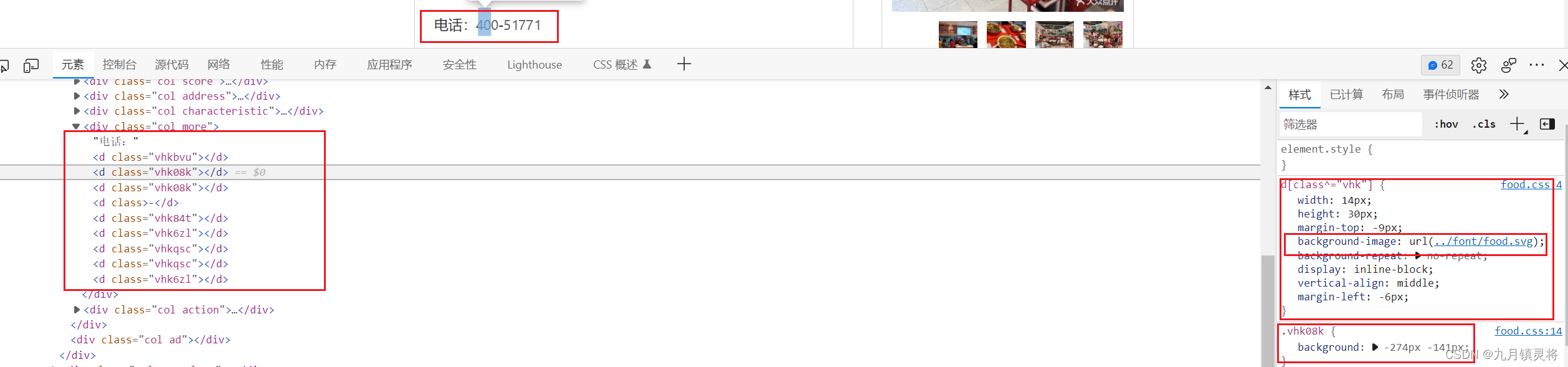
点击进去food.css,可以发现所有被隐藏文本的变迁它们的class属性都在这里定义了background,这里我们可以理解这些值是用来显示背景图片的内容,而这个背景图片就是svg文件。
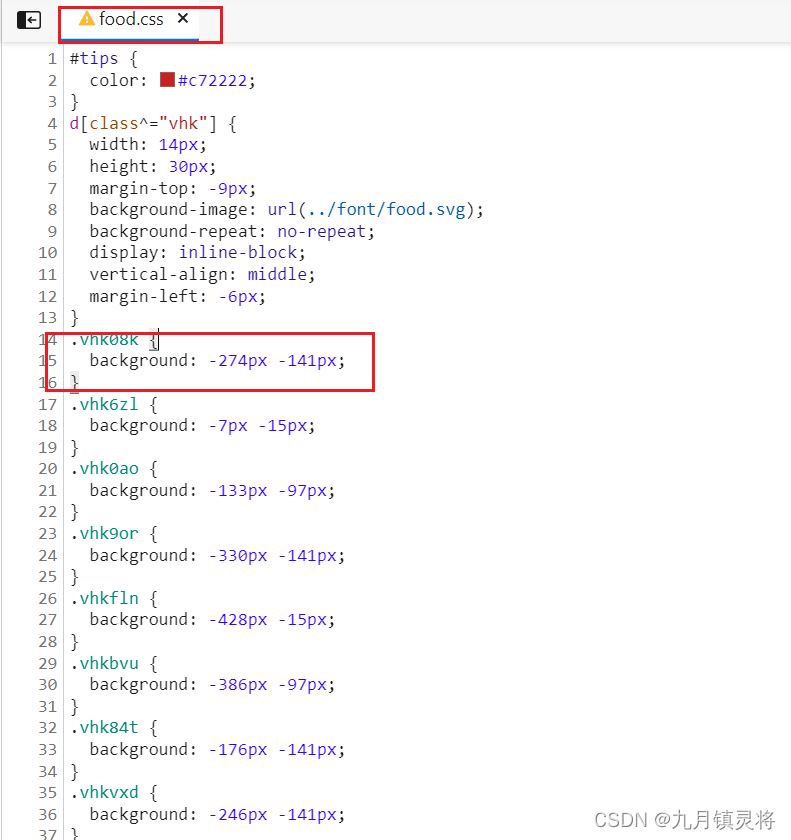
我们打开svg文件,可以看到有几行数字,每行数字它们的y轴一致,x轴两个数字相差14,这里只要我们提供一个x和y值就能确定显示指定的数字,也就是说上面的b标签设置的background值便能确定一个数字,只要我们找到映射规则便能确定是哪个了。
破解策略
svg与css的一些位置差异
SVG: x轴:位置参数越大越往右 y轴:位置参数越大越往下CSS: x轴:位置参数越小越往右 y轴:位置参数越小越往下拿.vhk08k {background: -274px -141px;}这个来举例,,通过上图我们知道y值的范围是38,83,120,164,元素定位时可以存在一定的差异定位,但是这个差异位置不能是比这个元素小,而是需要比这个元素大,所以确定.vhk08k的y值在第四行,我们看看第四行的所有x值14 28 42 56 70 84 98 112 126 140 154 168 182 196 210 224 238 252 266 280 294 308 322 336 350 364 378 392 406 420 434 448 462 476 490 504 518 532 546 560 574 588 602 616 630 644 658 672 686 700 714 728 742 756 770 784 798 812 826 840 854 868 882 896 910 924 938 952 966 980 994 1008 1022 1036 1050 1064 1078 1092 1106 1120 1134 1148 1162 1176 1190 1204 1218 1232 1246 1260 1274 1288 1302 1316 1330 1344 1358 1372 1386 1400 1414 1428 1442 1456 1470 1484 1498 1512 1526 1540 1554 1568 1582 1596 1610 1624 1638 1652 1666 1680 1694 1708 1722 1736 1750 1764 1778 1792 1806 1820 1834 1848 1862 1876 1890 1904 1918 1932 1946 1960 1974 1988 2002 2016 2030 2044 2058 2072 2086 2100 ,274在266和280之间,这里要去大的那个位置,也就是280,而280在所有x值的下标是20,我们只要找到文本的第20个数字就是了。第四行全部文本值是684431081139502796807382,而第20个数字就是0,这样就找到了。
处理流程:
- 找到引入svg文件的css文件
- 提取到每个标签定义的
background - 加载svg提取每个y值对应的x值和文本值
- 通过标签
background进行映射得到最终的数字
import reimport requestsfrom lxml import etreecss_url = 'http://www.porters.vip/confusion/css/food.css'svg_url = 'http://www.porters.vip/confusion/font/food.svg'css_resp = requests.get(css_url)params = re.findall(r'\.(v.*?) {.*?background: -(\d+)px -(\d+)px;}', css_resp.text.replace('\n', '').replace('\n', ''))css_params = {}for item in params: css_params[item[0]] = { 'x': int(item[1]), 'y': int(item[2]), }svg_resp = requests.get(svg_url)page = etree.HTML(svg_resp.content)svg_ys = [item for item in page.xpath('//text/@y')]svg_xs = [item for item in page.xpath('//text/@x')]svg_ts = [item for item in page.xpath('//text/text()')]svg_params = {}for x, y, t in zip(svg_xs, svg_ys, svg_ts): if y not in svg_params: svg_params[int(y)] = { 'x': x.split(' '), 't': t }result = {}for item in css_params: item_x = css_params[item]['x'] item_y = css_params[item]['y'] item_svg_y = [int(i) for i in svg_ys if item_y <= int(i)][0] item_svg_x = item_x // 14 item_svg_t = svg_params[item_svg_y]['t'][item_svg_x] result[item] = int(item_svg_t)print(result)自定义字体反爬
案例场景
自定义字体反爬是值指网站自己设计一个字体格式标准来渲染文字,而网页中的文字不再是文字,而是相应的字体编码,通过复制或者简单的采集是无法采集到编码后的文字内容!
我们可以看看某点评网的自定义字体反爬,可以看到文本是乱码的,查看源代码可以发现其实就是编码格式不用。
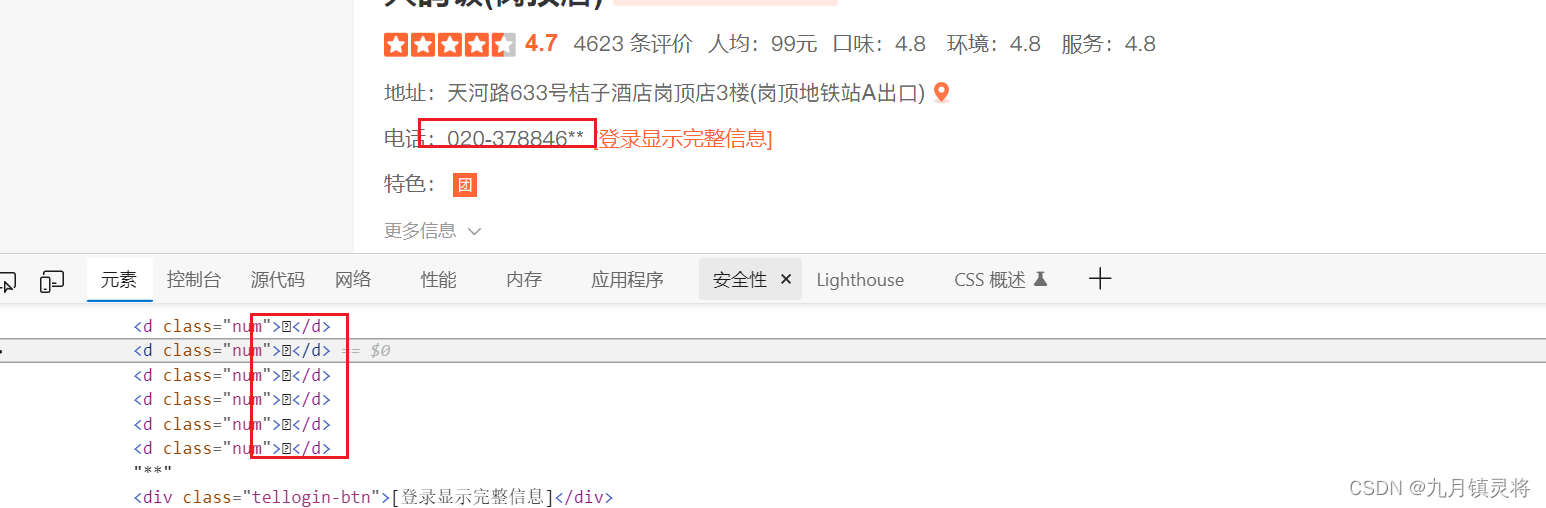

我们知道字体反爬是自己字体编码标准,每个字体编码会对应某个字体,我们从源代码是可以知道改字体的编码,那么剩下的只要找到这个编码对应的字体就可以破解了。
破解策略
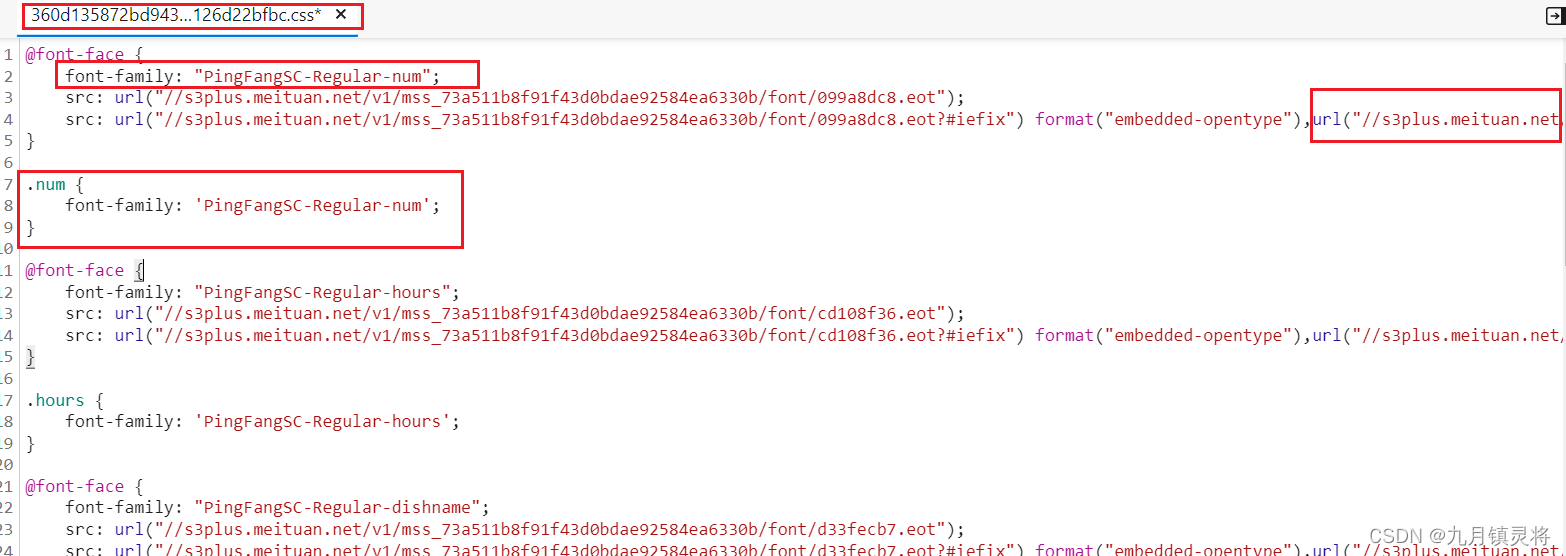
随便点击一个标签,在右侧可以看到它定义的属性,这里设置了font-family,点击进入对应的css文件

可以确定这里就是字体文件引入的地方,这个css文件定义了多个字体编码标准,其实就是对应不用文本类型时会使用不用的编码标准。
将这几个woff文件下载下来,然后用High-Logic FontCreator字体工具打开
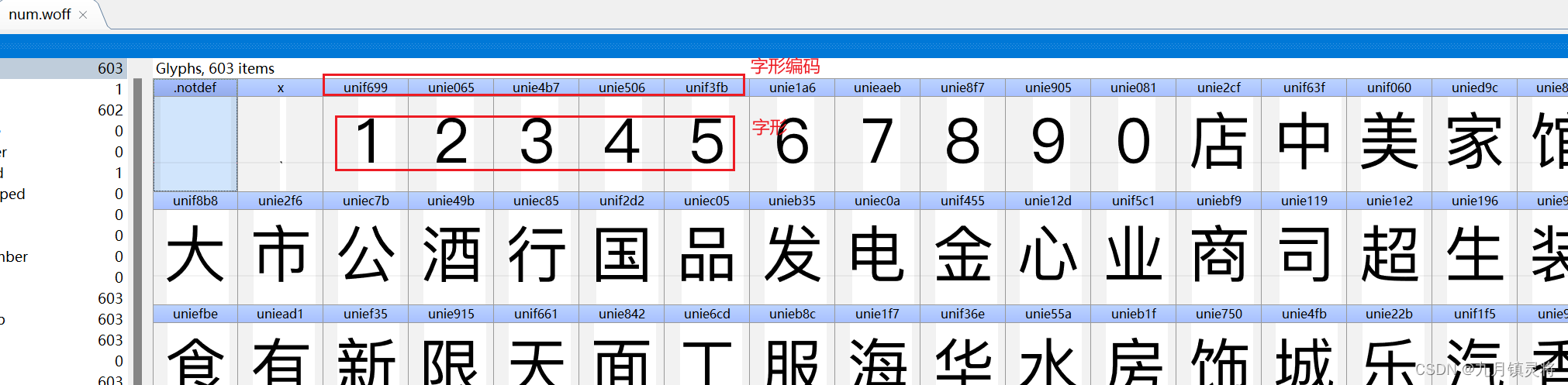
发现其实这几个woff它们定义的字体无论从顺序还是数量都是一样的,只是不同woff文件字体对应的编码不同,那我们只要确定所有字体,然后拿到字形编码映射上就可以破解了。
我们使用from fontTools.ttLib import TTFont导入python字体工具包,然后将woff转化成xml看看
woff_file = 'woff文件路径'woff_data = TTFont(woff_file)woff_data.saveXML('保存路径')一般来说,字体反爬是两个方式表现:
形式一:GlyphID id与 GlyphID name形成对应关系。
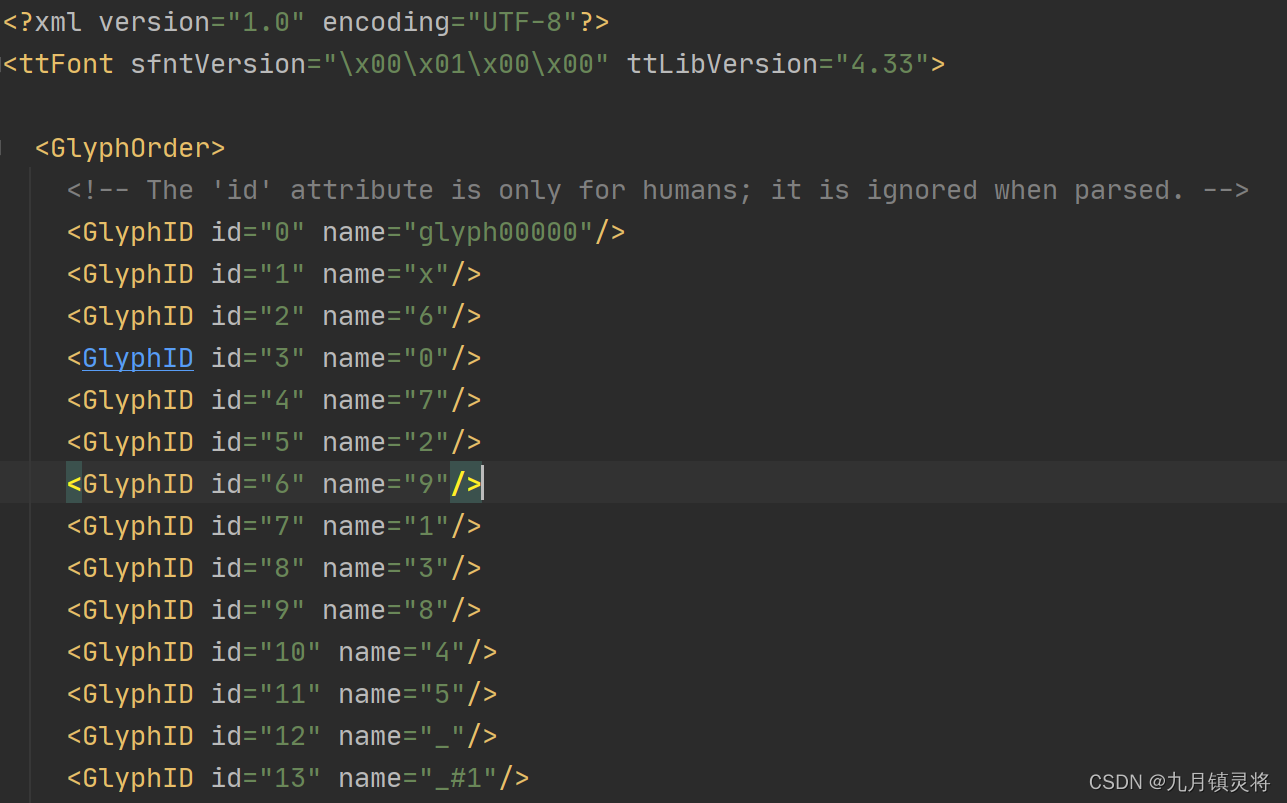
形式二:通过TTGlyph name的xy坐标信息形成文字
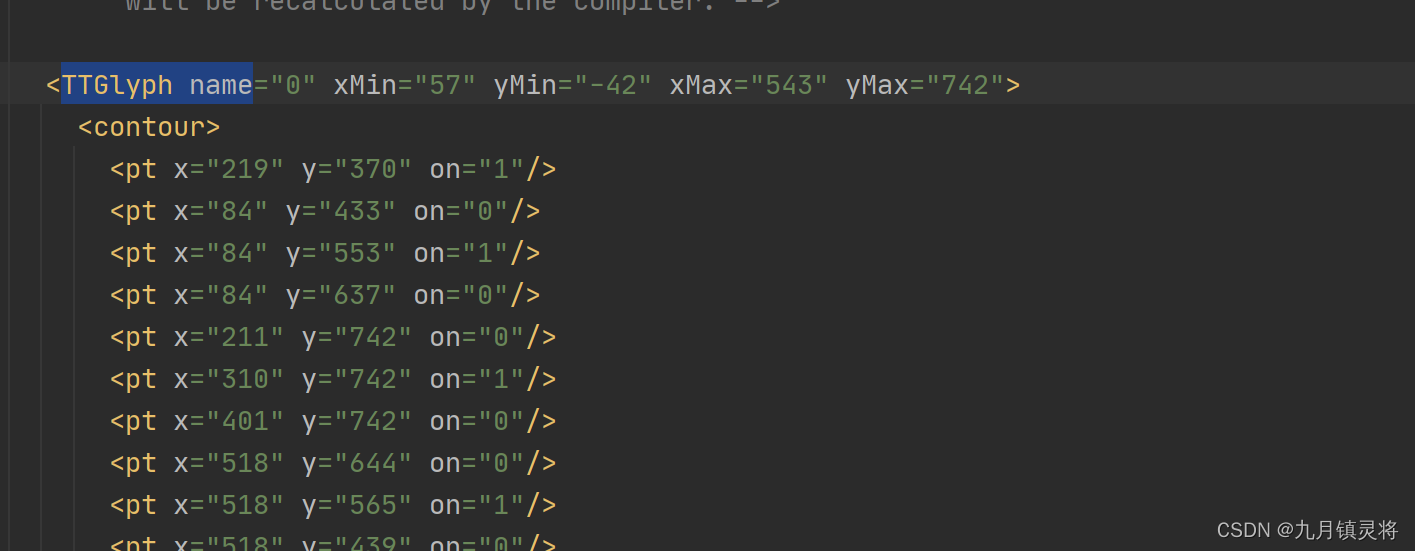
这个地方适用的是第一种,虽然说GlyphID id与 GlyphID name形成的对应关系并不是实际的字体和编码对应关系,但是我们已经知道所有的字体以及其顺序了,只要拿到编码就行
def see_xml_font_1(): words = '1234567890店中美家馆小车大市公酒行国品发电金心业商司超生装园场食有新限天面工服海华水房饰城乐汽香部利子老艺花专东肉菜学福饭人百餐茶务通味所山区门药银农龙停尚安广鑫一容动南具源兴鲜记时机烤文康信果阳理锅宝达地儿衣特产西批坊州牛佳化五米修爱北养卖建材三会鸡室红站德王光名丽油院堂烧江社合星货型村自科快便日民营和活童明器烟育宾精屋经居庄石顺林尔县手厅销用好客火雅盛体旅之鞋辣作粉包楼校鱼平彩上吧保永万物教吃设医正造丰健点汤网庆技斯洗料配汇木缘加麻联卫川泰色世方寓风幼羊烫来高厂兰阿贝皮全女拉成云维贸道术运都口博河瑞宏京际路祥青镇厨培力惠连马鸿钢训影甲助窗布富牌头四多妆吉苑沙恒隆春干饼氏里二管诚制售嘉长轩杂副清计黄讯太鸭号街交与叉附近层旁对巷栋环省桥湖段乡厦府铺内侧元购前幢滨处向座下臬凤港开关景泉塘放昌线湾政步宁解白田町溪十八古双胜本单同九迎第台玉锦底后七斜期武岭松角纪朝峰六振珠局岗洲横边济井办汉代临弄团外塔杨铁浦字年岛陵原梅进荣友虹央桂沿事津凯莲丁秀柳集紫旗张谷的是不了很还个也这我就在以可到错没去过感次要比觉看得说常真们但最喜哈么别位能较境非为欢然他挺着价那意种想出员两推做排实分间甜度起满给热完格荐喝等其再几只现朋候样直而买于般豆量选奶打每评少算又因情找些份置适什蛋师气你姐棒试总定啊足级整带虾如态且尝主话强当更板知己无酸让入啦式笑赞片酱差像提队走嫩才刚午接重串回晚微周值费性桌拍跟块调糕' word_dict = {} dir_path = 'D:\\python\\spider\\dz_dp\\font' for file_name in os.listdir(dir_path): font_type = file_name.split('.', 1)[0] if font_type not in word_dict: word_dict[font_type] = {} woff_file_path = os.path.join(os.path.join(dir_path, file_name)) font = TTFont(woff_file_path) gly_list = font.getGlyphOrder()[2:] for index, gly in enumerate(gly_list): word_dict[font_type][gly] = words[index] return word_dict下载所有woff类型后,通过上面方法便能得到每种类型下每个编码对应的字体