客快物流大数据项目(六十五):仓库主题

文章目录
仓库主题
一、背景介绍
二、指标明细
三、表关联关系
1、事实表
2、维度表
3、关联关系
四、仓库数据拉宽开发
1、拉宽后的字段
2、SQL语句
3、Spark实现
五、仓库数据指标计算开发
1、计算的字段
2、Spark实现
仓库主题
一、背景介绍
从2005年开始,网购快递每年以倍增的速度增长。重大节日前是快递爆仓发生的时段。如五一节前夕、国庆节前夕、圣诞节前夕、元旦前夕、春节前夕。新兴的光棍节,网购日,2010年“光棍节、圣诞节、元旦”和春节前夕,淘宝网、京东商城等网商集中促销造成部分民营快递企业多次发生爆仓现象。如2011年11月11日世纪光棍节,淘宝网当天交易额33亿,包裹堆积成山,快递公司原有的交通工具和人员,远远无法满足运送这么多包裹的要求,因此造成包裹被堆积在仓库长达十几天。广州市甚至出现同城快件10天不到的情况。
快递爆仓是国内快递业普遍存在的问题,如何缓解快递业的爆仓现状成为快递业和电商企业共同面临的问难题。快递业爆仓严重影响了快递企业的声誉和服务质量,同时也影响了电子商务的发展。通过对快递业爆仓问题进行分析,可以带动快递企业找寻本身存在的问题,并找出有效的策略。
“爆仓”主要有两方面原因:
- 一方面是电子商务迅速发展,但物流产业的人力、基础设施等投入都赶不上电子商务发展速度,出现了部分供需失衡的现象。
- 另一方面则是由于目前柴油供应紧张等因素影响,运力受到一定限制,所以到货周期变长。
快递业的蓬勃发展迅速地改变了人们的生活、购物方式,成就了部分企业甚至行业的快速发展。
- 天气原因 (大雪,洪水,台风)导致的,交通瘫痪。
- 集中促销加剧了爆仓现象的发生。由于网上商家借助圣诞节和春节提前进行促销,其力度之大创历年之最。并且很多网商采取了免快递费的促销方式也助推了快件量爆增。据粗略统计,网购快件量是去年的近2倍,大大超出了以网购快递为主民营快递企业的承受能力。
- 重大的赛会(比如运动会),安检比以往增强导致物流中转的效率下降。
- 比较长的假日(春节,五一,十一,元旦等), 假日期间不断的有新的包裹进入快递公司仓库,而多数的收货地址又是单位无法派送,导致仓库包裹累积过多,以及假日后几天派送工作的成倍增长。
- 网络技术运用落后。在我国信息技术运用范围不断扩大的背景下,网络技术逐渐取代EDI技术,为快递业提供信息处理、信息共享、信息传输服务。但是,当前我国快递企业信息化水平还相对较低,物流信息技术运用范围较窄,导致网络技术运用还处于初级阶段。
- 信息系统软件开发不力。 信息系统软件开发不力也是制约物流技术在快速业运用的关键,快递管理软件可以优化快递企业物流功能及业务集成,实现供应商、企业、消费者、竞争者资源的集成管理,实现快递企业内外部资源的优化配置,物流系统集成主要包括制造资源、企业内部资源、供应商资源、供应链系统等。
- 缺乏产业联动机制。作为上游的电子商务产业没有与决递产业形成联动发展、融合发展的机制。如电子商务在一个时间段集中促销应与相关的快递企业进行通报,让快递企业配置相关的资源。
除了不可抗力导致的快递爆仓,在信息化建设的同时实时的监测仓库的库存积压情况是一个常用的解决方案,一方面可以在重大活动前提前清理库存,另一方面也可以动态监测各仓库的运力情况。
二、指标明细
|
指标列表 |
维度 |
|
最大发车次数 |
各仓库最大发车次数 |
|
各网点最大发车次数 |
|
|
各线路最大发车次数 |
|
|
各客户类型最大发车次数 |
|
|
各类型包裹最大发车次数 |
|
|
各区域最大发车次数 |
|
|
各公司最大发车次数 |
|
|
最小发车次数 |
各仓库最小发车次数 |
|
各网点最小发车次数 |
|
|
各线路最小发车次数 |
|
|
各客户类型最小发车次数 |
|
|
各类型包裹最小发车次数 |
|
|
各区域最小发车次数 |
|
|
各公司最小发车次数 |
|
|
平均发车次数 |
各仓库平均发车次数 |
|
各网点平均发车次数 |
|
|
各线路平均发车次数 |
|
|
各客户类型平均发车次数 |
|
|
各类型包裹平均发车次数 |
|
|
各区域平均发车次数 |
|
|
各公司平均发车次数 |
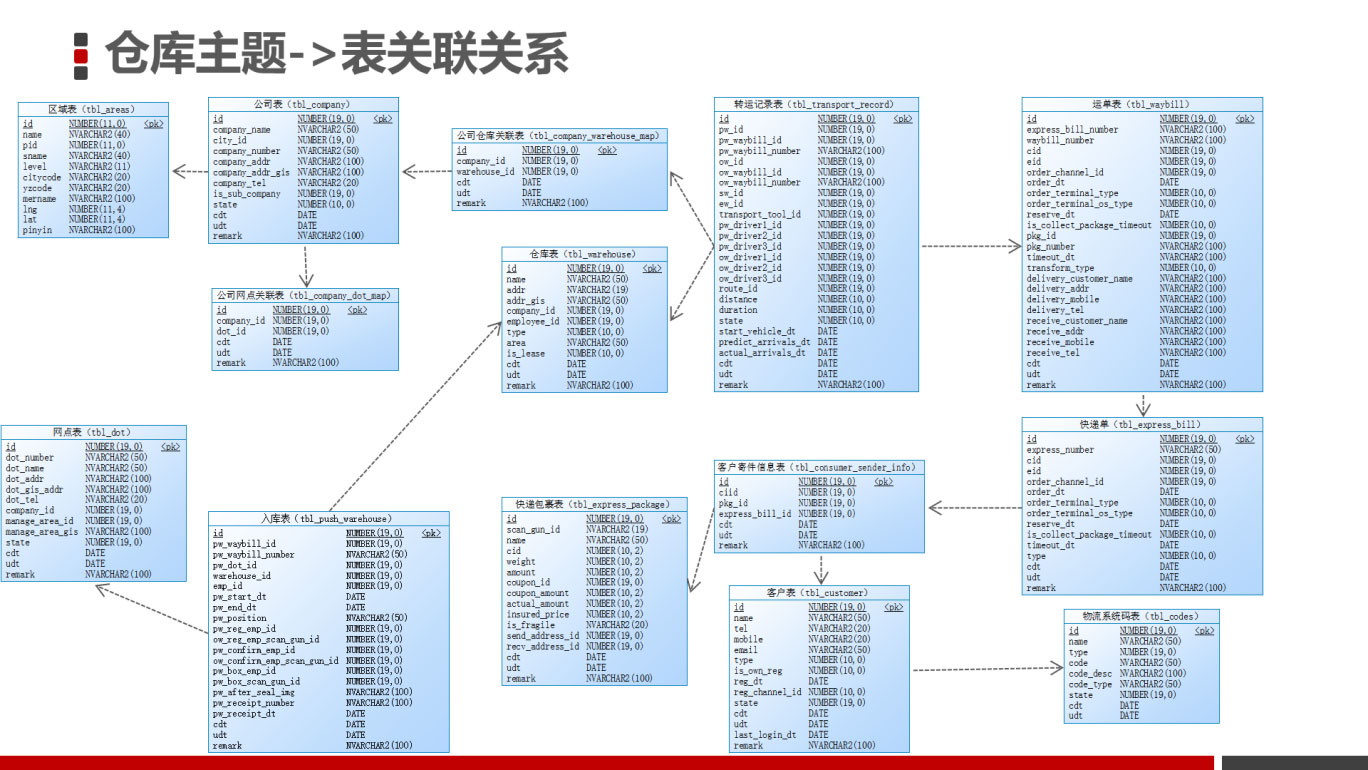
三、表关联关系
1、事实表
|
表名 |
描述 |
|
tbl_transport_record |
运输记录表 |
2、维度表
|
表名 |
描述 |
|
tbl_company_warehouse_map |
公司仓库关联表 |
|
tbl_warehouse |
仓库表 |
|
tbl_company |
公司表 |
|
tbl_areas |
区域表 |
|
tbl_waybill |
运单表 |
|
tbl_express_bill |
快递单表 |
|
tbl_consumer_sender_info |
客户寄件信息表 |
|
tbl_express_package |
快递包裹表 |
|
tbl_customer |
客户表 |
|
tbl_codes |
物流系统码表 |
|
tbl_dot |
网点表 |
|
tbl_push_warehouse |
入库表 |
|
tbl_company_dot_map |
公司网点关联表 |
3、关联关系
运输记录表与维度表的关联关系如下:
四、仓库数据拉宽开发
1、拉宽后的字段
|
表 |
字段名 |
别名 |
字段描述 |
|
tbl_transport_record |
Id |
id |
ID |
|
tbl_transport_record |
pwId |
pw_id |
入库表ID |
|
tbl_transport_record |
pwWaybillId |
pw_waybill_id |
入库运单ID |
|
tbl_transport_record |
pwWaybillNumber |
pw_waybill_number |
入库运单号 |
|
tbl_transport_record |
owId |
ow_id |
出库表ID |
|
tbl_transport_record |
owWaybillId |
ow_waybill_id |
出库运单ID |
|
tbl_transport_record |
owWaybillNumber |
ow_waybill_number |
出库运单号 |
|
tbl_transport_record |
swId |
sw_id |
起点仓库ID |
|
tbl_warehouse |
name |
sw_name |
起点仓库名称 |
|
tbl_transport_record |
ewId |
ew_id |
终点仓库ID |
|
tbl_transport_record |
transportToolId |
transport_tool_id |
运输工具ID |
|
tbl_transport_record |
pwDriver1Id |
pw_driver1_id |
入库车辆驾驶员 |
|
tbl_transport_record |
pwDriver2Id |
pw_driver2_id |
入库车辆跟车员1 |
|
tbl_transport_record |
pwDriver3Id |
pw_driver3_id |
入库车辆跟车员2 |
|
tbl_transport_record |
owDriver1Id |
ow_driver1_id |
出库车辆驾驶员 |
|
tbl_transport_record |
owDriver2Id |
ow_driver2_id |
出库车辆跟车员1 |
|
tbl_transport_record |
owDriver3Id |
ow_driver3_id |
出库车辆跟车员2 |
|
tbl_transport_record |
routeId |
route_id |
运输路线ID |
|
tbl_transport_record |
distance |
distance |
运输里程 |
|
tbl_transport_record |
duration |
duration |
运输耗时 |
|
tbl_transport_record |
state |
state |
转运状态id |
|
tbl_transport_record |
startVehicleDt |
start_vehicle_dt |
发车时间 |
|
tbl_transport_record |
predictArrivalsDt |
predict_arrivals_dt |
预计到达时间 |
|
tbl_transport_record |
actualArrivalsDt |
actual_arrivals_dt |
实际达到时间 |
|
tbl_transport_record |
cdt |
cdt |
创建时间 |
|
tbl_transport_record |
udt |
udt |
修改时间 |
|
tbl_transport_record |
remark |
remark |
备注 |
|
tbl_company |
id |
company_id |
公司ID |
|
tbl_company |
companyName |
company_name |
公司名字 |
|
tbl_areas |
id |
area_id |
区域ID |
|
tbl_areas |
name |
area_name |
区域名称 |
|
tbl_express_package |
id |
package_id |
快递包裹ID |
|
tbl_express_package |
name |
package_name |
快递包裹名称 |
|
tbl_customer |
id |
consumer_id |
客户ID |
|
tbl_customer |
name |
consumer_name |
客户姓名 |
|
tbl_codes |
consumerType |
consumer_type |
客户类型Code |
|
tbl_codes |
consumerTypeName |
consumer_name_desc |
客户类型名称 |
|
tbl_dot |
id |
dot_id |
网点ID |
|
tbl_dot |
dotName |
dot_name |
网点名称 |
|
tbl_transport_record |
yyyyMMdd(cdt) |
Day |
创建时间 年月日格式 |
2、SQL语句
SELECT wsDF."id" AS id,wsDF."pw_id" AS pw_id,wsDF."pw_waybill_id" AS pw_waybill_id,wsDF."pw_waybill_number" AS pw_waybill_number,wsDF."ow_id" AS ow_id,wsDF."ow_waybill_id" AS ow_waybill_id,wsDF."ow_waybill_number" AS ow_waybill_number,wsDF."sw_id" AS sw_id,warehouseDF."name" AS sw_name,wsDF."ew_id" AS ew_id,wsDF."transport_tool_id" AS transport_tool_id,wsDF."pw_driver1_id" AS pw_driver1_id,wsDF."pw_driver2_id" AS pw_driver2_id,wsDF."pw_driver3_id" AS pw_driver3_id,wsDF."ow_driver1_id" AS ow_driver1_id,wsDF."ow_driver2_id" AS ow_driver2_id,wsDF."ow_driver3_id" AS ow_driver3_id,wsDF."route_id" AS route_id,wsDF."distance" AS distance,wsDF."duration" AS duration,wsDF."state" AS state,wsDF."start_vehicle_dt" AS start_vehicle_dt,wsDF."predict_arrivals_dt" AS predict_arrivals_dt,wsDF."actual_arrivals_dt" AS actual_arrivals_dt,wsDF."cdt" AS cdt,wsDF."udt" AS udt,wsDF."remark" AS remark,companyDF."id" AS company_id,companyDF."company_name" AS company_name,areasDF."id" AS area_id,areasDF."name" AS area_name,wsDF ."pw_waybill_number",expressBillDF."express_number",expressBillDF."cid",consumerSenderDF."ciid",expressPackageDF."id" AS package_id,expressPackageDF."name" AS package_name,consumerDF."id" AS consumer_id,consumerDF."name" AS consumer_name,codesDF16."code" AS consumer_type,codesDF16."code_desc" AS consumer_name_desc,wsDF ."sw_id",warehouseDF."id" ,pwDF."warehouse_id",pwDF."pw_dot_id",dotDF."id" AS dot_id,dotDF."dot_name" AS dot_nameFROM "tbl_transport_record" wsDF --运输记录表LEFT JOIN "tbl_company_warehouse_map" companyWarehouseMapDF ON wsDF."sw_id" =companyWarehouseMapDF."warehouse_id" --公司仓库关联表LEFT JOIN "tbl_company" companyDF ON companyWarehouseMapDF."company_id" = companyDF ."id" --公司表LEFT JOIN "tbl_areas" areasDF ON companyDF."city_id"= areasDF."id" --区域表LEFT JOIN "tbl_waybill" waybillDF ON wsDF ."pw_waybill_number"=waybillDF."waybill_number"--运单表LEFT JOIN "tbl_express_bill" expressBillDF ON expressBillDF."express_number"=waybillDF."express_bill_number" --快递单表LEFT JOIN "tbl_consumer_sender_info" consumerSenderDF ON consumerSenderDF."ciid" = expressBillDF."cid" --客户寄件信息表LEFT JOIN "tbl_express_package" expressPackageDF ON consumerSenderDF."pkg_id" = expressPackageDF."id" --快递包裹表LEFT JOIN "tbl_customer" consumerDF ON consumerDF."id" =consumerSenderDF."ciid" --客户表LEFT JOIN "tbl_codes" codesDF16 ON codesDF16 ."type" =16 AND consumerDF."type" = codesDF16 ."code" --物流系统码表LEFT JOIN "tbl_warehouse" warehouseDF ON wsDF ."sw_id"=warehouseDF."id" --仓库表LEFT JOIN "tbl_push_warehouse" pwDF ON pwDF."warehouse_id" =warehouseDF."id" --入库表LEFT JOIN "tbl_dot" dotDF ON pwDF."pw_dot_id" =dotDF."id"3、Spark实现
实现步骤:
- 在dwd目录下创建 WarehouseDWD 单例对象,继承自OfflineApp特质
- 初始化环境的参数,创建SparkSession对象
- 获取转运记录表(tbl_transport_record)数据,并缓存数据
- 判断是否是首次运行,如果是首次运行的话,则全量装载数据(含历史数据)
- 获取客户表(tbl_customer)数据,并缓存数据
- 获取快递员表(tbl_courier)数据,并缓存数据
- 获取包裹表(tbl_pkg)数据,并缓存数据
- 获取网点表(tbl_dot)数据,并缓存数据
- 获取区域表(tbl_areas)数据,并缓存数据
- 获取仓库表(tbl_warehouse)数据,并缓存数据
- 获取交通工具表(tbl_transport_tool)数据,并缓存数据
- 获取线路表(tbl_route)数据,并缓存数据
- 获取公司网点关联表(tbl_company_dot_map)数据,并缓存数据
- 获取公司表(tbl_company)数据,并缓存数据
- 获取客户地址关联表(tbl_consumer_address_map)数据,并缓存数据
- 获取客户地址表(tbl_address)数据,并缓存数据
- 获取字典表(tbl_codes)数据,并缓存数据
- 根据以下方式拉宽仓库车辆明细数据
- 根据客户id,在客户表中获取客户数据
- 根据快递员id,在快递员表中获取快递员数据
- 根据客户id,在客户地址表中获取客户地址数据
- 根据快递单号,在包裹表中获取包裹数据
- 根据包裹的发货网点id,获取到网点数据
- 根据网点id, 获取到公司数据
- 根据入库id和出库id,获取仓库信息
- 根据线路id,获取线路信息
- 创建仓库车辆明细宽表(若存在则不创建)
- 将仓库车辆明细宽表数据写入到kudu数据表中
- 删除缓存数据
3.1、初始化环境变量
初始化仓库明细拉宽作业的环境变量
package cn.it.logistics.offline.dwdimport cn.it.logistics.common.{Configuration, SparkUtils}import cn.it.logistics.offline.OfflineAppimport org.apache.spark.SparkConfimport org.apache.spark.sql.SparkSession/** * 仓库主题开发 * 将运输记录事实表的数据与维度表的数据进行拉宽操作,将拉宽后的数据写入到kudu数据库中 */object WareHouseDWD extends OfflineApp { //定义应用的名称 val appName = this.getClass.getSimpleName /** * 入口函数 * @param args */ def main(args: Array[String]): Unit = { /** * 实现步骤: * 1)初始化sparkConf对象 * 2)创建sparkSession对象 * 3)加载kudu中的事实表和维度表的数据(将加载后的数据进行缓存) * 4)定义维度表与事实表的关联 * 5)将拉宽后的数据再次写回到kudu数据库中(DWD明细层) * 5.1:创建仓库明细宽表的schema表结构 * 5.2:创建仓库宽表(判断宽表是否存在,如果不存在则创建) * 5.3:将数据写入到kudu中 * 6):将缓存的数据删除掉 * 7)停止任务,释放sparksession对象 */ //1)初始化sparkConf对象 val sparkConf: SparkConf = SparkUtils.autoSettingEnv( SparkUtils.sparkConf(appName) ) //2)创建sparkSession对象 val sparkSession: SparkSession = SparkUtils.getSparkSession(sparkConf) sparkSession.sparkContext.setLogLevel(Configuration.LOG_OFF) //数据处理 execute(sparkSession) } /** * 数据处理 * * @param sparkSession */ override def execute(sparkSession: SparkSession): Unit = { sparkSession.stop() }}3.2、加载仓库及车辆相关的表并缓存
- 加载转运记录表的时候,需要指定日期条件,因为仓库主题最终需要Azkaban定时调度执行,每天执行一次增量数据,因此需要指定日期。
- 判断是否是首次运行,如果是首次运行的话,则全量装载数据(含历史数据)
//TODO 3)加载kudu中的事实表和维度表的数据(将加载后的数据进行缓存)//加载运输工具表的数据val recordDF: DataFrame = getKuduSource(sparkSession, TableMapping.transportRecord, Configuration.isFirstRunnable).toDF().persist(StorageLevel.DISK_ONLY_2)//加载公司仓库关联表的数据val companyWareHouseMapDF: DataFrame = getKuduSource(sparkSession, TableMapping.companyWarehouseMap, true).toDF().persist(StorageLevel.DISK_ONLY_2)//加载公司表的数据val companyDF: DataFrame = getKuduSource(sparkSession, TableMapping.company, true).toDF().persist(StorageLevel.DISK_ONLY_2)//加载区域表的数据val areasDF: DataFrame = getKuduSource(sparkSession, TableMapping.areas, true).toDF().persist(StorageLevel.DISK_ONLY_2)//加载运单表的数据val wayBillDF: DataFrame = getKuduSource(sparkSession, TableMapping.waybill, true).toDF().persist(StorageLevel.DISK_ONLY_2)//加载快递单表的数据val expressBillDF: DataFrame = getKuduSource(sparkSession, TableMapping.expressBill, true).toDF().persist(StorageLevel.DISK_ONLY_2)//加载客户寄件信息表数据val senderInfoDF: DataFrame = getKuduSource(sparkSession, TableMapping.consumerSenderInfo, true).toDF().persist(StorageLevel.DISK_ONLY_2)//加载包裹表数据val expressPackageDF: DataFrame = getKuduSource(sparkSession, TableMapping.expressPackage, true).toDF().persist(StorageLevel.DISK_ONLY_2)//加载客户表数据val customerDF: DataFrame = getKuduSource(sparkSession, TableMapping.customer, true).toDF().persist(StorageLevel.DISK_ONLY_2)//加载物流码表数据val codesDF: DataFrame = getKuduSource(sparkSession, TableMapping.codes, true).toDF().persist(StorageLevel.DISK_ONLY_2)//加载仓库表数据val warehouseDF: DataFrame = getKuduSource(sparkSession, TableMapping.warehouse, true).toDF().persist(StorageLevel.DISK_ONLY_2)//加载入库数据val phWarehouseDF: DataFrame = getKuduSource(sparkSession, TableMapping.pushWarehouse, true).toDF().persist(StorageLevel.DISK_ONLY_2)//加载入库数据val dotDF: DataFrame = getKuduSource(sparkSession, TableMapping.dot, true).toDF().persist(StorageLevel.DISK_ONLY_2)//导入隐士转换import sparkSession.implicits._//客户类型表val customerTypeDF: DataFrame = codesDF.where($"type" === CodeTypeMapping.CustomType).select( $"code".as("customerTypeCode"), $"codeDesc".as("customerTypeName"))3.3、定义表的关联关系
- 为了在DWS层任务中方便的获取每日增量仓库数据(根据日期),因此在DataFrame基础上动态增加列(day),指定日期格式为yyyyMMdd
代码如下:
//TODO 4)定义维度表与事实表的关联val joinType = "left_outer"val wsDetailDF: DataFrame = recordDF.join(companyWareHouseMapDF, recordDF.col("swId") === companyWareHouseMapDF.col("warehouseId"), joinType) // 转运记录表与公司仓库关联表关联 .join(companyDF, companyWareHouseMapDF.col("companyId") === companyDF.col("id"), joinType) //公司仓库关联表与公司表关联 .join(areasDF, companyDF.col("cityId") === areasDF.col("id"), joinType) //公司表与区域表关联 .join(wayBillDF, recordDF.col("pwWaybillNumber") === wayBillDF.col("waybillNumber"), joinType) //运单表与转运记录表关联 .join(expressBillDF, wayBillDF.col("expressBillNumber") === expressBillDF.col("expressNumber"), joinType) //运单表与快递单表关联 .join(senderInfoDF, expressBillDF.col("cid") === senderInfoDF.col("ciid"), joinType) //客户寄件信息表与快递单表关联 .join(expressPackageDF, senderInfoDF.col("pkgId") === expressPackageDF.col("id"), joinType) //客户寄件信息表与包裹表关联 .join(customerDF, senderInfoDF.col("ciid") === customerDF.col("id"), joinType) //客户寄件信息表与客户表关联 .join(customerTypeDF, customerDF.col("type") === customerTypeDF.col("customerTypeCode"), joinType) //客户表与客户类别表关联 .join(warehouseDF, recordDF.col("swId")===warehouseDF.col("id"), joinType) //转运记录表与仓库表关联 .join(phWarehouseDF, phWarehouseDF.col("warehouseId")=== warehouseDF.col("id"), joinType) //入库表与仓库表关联 .join(dotDF, dotDF("id")=== phWarehouseDF.col("pwDotId"), joinType)//转运记录表与网点表关联 .withColumn("day", date_format(recordDF("cdt"), "yyyyMMdd"))//虚拟列,可以根据这个日期列作为分区字段,可以保证同一天的数据保存在同一个分区中 .sort(recordDF.col("cdt").asc) .select( recordDF("id"), //转运记录id recordDF("pwId").as("pw_id"), //入库表的id recordDF("pwWaybillId").as("pw_waybill_id"), //入库运单id recordDF("pwWaybillNumber").as("pw_waybill_number"), //入库运单编号 recordDF("owId").as("ow_id"),//出库id recordDF("owWaybillId").as("ow_waybill_id"), //出库运单id recordDF("owWaybillNumber").as("ow_waybill_number"), //出库运单编号 recordDF("swId").as("sw_id"), //起点仓库id warehouseDF.col("name").as("sw_name"), //起点仓库名称 recordDF("ewId").as("ew_id"), //到达仓库id recordDF("transportToolId").as("transport_tool_id"), //运输工具id recordDF("pwDriver1Id").as("pw_driver1_id"), //入库车辆驾驶员 recordDF("pwDriver2Id").as("pw_driver2_id"), //入库车辆驾驶员2 recordDF("pwDriver3Id").as("pw_driver3_id"), //入库车辆驾驶员3 recordDF("owDriver1Id").as("ow_driver1_id"), //出库车辆驾驶员 recordDF("owDriver2Id").as("ow_driver2_id"), //出库车辆驾驶员2 recordDF("owDriver3Id").as("ow_driver3_id"), //出库车辆驾驶员3 recordDF("routeId").as("route_id"),//线路id recordDF("distance").cast(IntegerType), //运输里程 recordDF("duration").cast(IntegerType), //运输耗时 recordDF("state").cast(IntegerType), //转运状态id recordDF("startVehicleDt").as("start_vehicle_dt"), //发车时间 recordDF("predictArrivalsDt").as("predict_arrivals_dt"), //预计到达时间 recordDF("actualArrivalsDt").as("actual_arrivals_dt"), //实际到达时间 recordDF("cdt"), //创建时间 recordDF("udt"), //修改时间 recordDF("remark"), //备注 companyDF("id").alias("company_id"), //公司id companyDF("companyName").as("company_name"), //公司名称 areasDF("id").alias("area_id"), //区域id areasDF("name").alias("area_name"), //区域名称 expressPackageDF.col("id").alias("package_id"), //包裹id expressPackageDF.col("name").alias("package_name"), //包裹名称 customerDF.col("id").alias("cid"), customerDF.col("name").alias("cname"), customerTypeDF("customerTypeCode").alias("ctype"), customerTypeDF("customerTypeName").alias("ctype_name"), dotDF("id").as("dot_id"), dotDF("dotName").as("dot_name"), $"day" )3.4、创建仓库车辆明细宽表并将仓库车辆明细数据写入到kudu数据表中
仓库车辆明细宽表数据需要保存到kudu中,因此在第一次执行仓库车辆明细拉宽操作时,仓库车辆明细宽表是不存在的,因此需要实现自动判断宽表是否存在,如果不存在则创建
实现步骤:
- 在WarehouseDWD 单例对象中调用save方法
实现过程:
- 在WarehouseDWD 单例对象Main方法中调用save方法
//TODO 5)将拉宽后的数据再次写回到kudu数据库中(DWD明细层)save(wsDetailDF, OfflineTableDefine.wareHouseDetail)3.5、删除缓存数据
为了释放资源,仓库明细宽表数据计算完成以后,需要将缓存的源表数据删除。
//删除缓存,释放资源companyWareHouseMapDF.unpersist()companyDF.unpersist()areasDF.unpersist()wayBillDF.unpersist()expressBillDF.unpersist()senderInfoDF.unpersist()expressPackageDF.unpersist()customerDF.unpersist()customerTypeDF.unpersist()warehouseDF.unpersist()phWarehouseDF.unpersist()dotDF.unpersist()recordDF.unpersist()3.6、完整代码
package cn.it.logistics.offline.dwdimport cn.it.logistics.common.{CodeTypeMapping, Configuration, OfflineTableDefine, SparkUtils, TableMapping}import cn.it.logistics.offline.OfflineAppimport org.apache.spark.SparkConfimport org.apache.spark.sql.functions.date_formatimport org.apache.spark.sql.types.IntegerTypeimport org.apache.spark.sql.{DataFrame, SparkSession}import org.apache.spark.storage.StorageLevel/** * 仓库主题开发 * 将运输记录事实表的数据与维度表的数据进行拉宽操作,将拉宽后的数据写入到kudu数据库中 */object WareHouseDWD extends OfflineApp { //定义应用的名称 val appName = this.getClass.getSimpleName /** * 入口函数 * @param args */ def main(args: Array[String]): Unit = { /** * 实现步骤: * 1)初始化sparkConf对象 * 2)创建sparkSession对象 * 3)加载kudu中的事实表和维度表的数据(将加载后的数据进行缓存) * 4)定义维度表与事实表的关联 * 5)将拉宽后的数据再次写回到kudu数据库中(DWD明细层) * 5.1:创建仓库明细宽表的schema表结构 * 5.2:创建仓库宽表(判断宽表是否存在,如果不存在则创建) * 5.3:将数据写入到kudu中 * 6):将缓存的数据删除掉 * 7)停止任务,释放sparksession对象 */ //1)初始化sparkConf对象 val sparkConf: SparkConf = SparkUtils.autoSettingEnv( SparkUtils.sparkConf(appName) ) //2)创建sparkSession对象 val sparkSession: SparkSession = SparkUtils.getSparkSession(sparkConf) sparkSession.sparkContext.setLogLevel(Configuration.LOG_OFF) //数据处理 execute(sparkSession) } /** * 数据处理 * * @param sparkSession */ override def execute(sparkSession: SparkSession): Unit = { //TODO 3)加载kudu中的事实表和维度表的数据(将加载后的数据进行缓存) //加载运输工具表的数据 val recordDF: DataFrame = getKuduSource(sparkSession, TableMapping.transportRecord, Configuration.isFirstRunnable).toDF().persist(StorageLevel.DISK_ONLY_2) //加载公司仓库关联表的数据 val companyWareHouseMapDF: DataFrame = getKuduSource(sparkSession, TableMapping.companyWarehouseMap, true).toDF().persist(StorageLevel.DISK_ONLY_2) //加载公司表的数据 val companyDF: DataFrame = getKuduSource(sparkSession, TableMapping.company, true).toDF().persist(StorageLevel.DISK_ONLY_2) //加载区域表的数据 val areasDF: DataFrame = getKuduSource(sparkSession, TableMapping.areas, true).toDF().persist(StorageLevel.DISK_ONLY_2) //加载运单表的数据 val wayBillDF: DataFrame = getKuduSource(sparkSession, TableMapping.waybill, true).toDF().persist(StorageLevel.DISK_ONLY_2) //加载快递单表的数据 val expressBillDF: DataFrame = getKuduSource(sparkSession, TableMapping.expressBill, true).toDF().persist(StorageLevel.DISK_ONLY_2) //加载客户寄件信息表数据 val senderInfoDF: DataFrame = getKuduSource(sparkSession, TableMapping.consumerSenderInfo, true).toDF().persist(StorageLevel.DISK_ONLY_2) //加载包裹表数据 val expressPackageDF: DataFrame = getKuduSource(sparkSession, TableMapping.expressPackage, true).toDF().persist(StorageLevel.DISK_ONLY_2) //加载客户表数据 val customerDF: DataFrame = getKuduSource(sparkSession, TableMapping.customer, true).toDF().persist(StorageLevel.DISK_ONLY_2) //加载物流码表数据 val codesDF: DataFrame = getKuduSource(sparkSession, TableMapping.codes, true).toDF().persist(StorageLevel.DISK_ONLY_2) //加载仓库表数据 val warehouseDF: DataFrame = getKuduSource(sparkSession, TableMapping.warehouse, true).toDF().persist(StorageLevel.DISK_ONLY_2) //加载入库数据 val phWarehouseDF: DataFrame = getKuduSource(sparkSession, TableMapping.pushWarehouse, true).toDF().persist(StorageLevel.DISK_ONLY_2) //加载入库数据 val dotDF: DataFrame = getKuduSource(sparkSession, TableMapping.dot, true).toDF().persist(StorageLevel.DISK_ONLY_2) //导入隐士转换 import sparkSession.implicits._ //客户类型表 val customerTypeDF: DataFrame = codesDF.where($"type" === CodeTypeMapping.CustomType).select( $"code".as("customerTypeCode"), $"codeDesc".as("customerTypeName")) //TODO 4)定义维度表与事实表的关联 val joinType = "left_outer" val wsDetailDF: DataFrame = recordDF.join(companyWareHouseMapDF, recordDF.col("swId") === companyWareHouseMapDF.col("warehouseId"), joinType) // 转运记录表与公司仓库关联表关联 .join(companyDF, companyWareHouseMapDF.col("companyId") === companyDF.col("id"), joinType) //公司仓库关联表与公司表关联 .join(areasDF, companyDF.col("cityId") === areasDF.col("id"), joinType) //公司表与区域表关联 .join(wayBillDF, recordDF.col("pwWaybillNumber") === wayBillDF.col("waybillNumber"), joinType) //运单表与转运记录表关联 .join(expressBillDF, wayBillDF.col("expressBillNumber") === expressBillDF.col("expressNumber"), joinType) //运单表与快递单表关联 .join(senderInfoDF, expressBillDF.col("cid") === senderInfoDF.col("ciid"), joinType) //客户寄件信息表与快递单表关联 .join(expressPackageDF, senderInfoDF.col("pkgId") === expressPackageDF.col("id"), joinType) //客户寄件信息表与包裹表关联 .join(customerDF, senderInfoDF.col("ciid") === customerDF.col("id"), joinType) //客户寄件信息表与客户表关联 .join(customerTypeDF, customerDF.col("type") === customerTypeDF.col("customerTypeCode"), joinType) //客户表与客户类别表关联 .join(warehouseDF, recordDF.col("swId")===warehouseDF.col("id"), joinType) //转运记录表与仓库表关联 .join(phWarehouseDF, phWarehouseDF.col("warehouseId")=== warehouseDF.col("id"), joinType) //入库表与仓库表关联 .join(dotDF, dotDF("id")=== phWarehouseDF.col("pwDotId"), joinType)//转运记录表与网点表关联 .withColumn("day", date_format(recordDF("cdt"), "yyyyMMdd"))//虚拟列,可以根据这个日期列作为分区字段,可以保证同一天的数据保存在同一个分区中 .sort(recordDF.col("cdt").asc) .select( recordDF("id"), //转运记录id recordDF("pwId").as("pw_id"), //入库表的id recordDF("pwWaybillId").as("pw_waybill_id"), //入库运单id recordDF("pwWaybillNumber").as("pw_waybill_number"), //入库运单编号 recordDF("owId").as("ow_id"),//出库id recordDF("owWaybillId").as("ow_waybill_id"), //出库运单id recordDF("owWaybillNumber").as("ow_waybill_number"), //出库运单编号 recordDF("swId").as("sw_id"), //起点仓库id warehouseDF.col("name").as("sw_name"), //起点仓库名称 recordDF("ewId").as("ew_id"), //到达仓库id recordDF("transportToolId").as("transport_tool_id"), //运输工具id recordDF("pwDriver1Id").as("pw_driver1_id"), //入库车辆驾驶员 recordDF("pwDriver2Id").as("pw_driver2_id"), //入库车辆驾驶员2 recordDF("pwDriver3Id").as("pw_driver3_id"), //入库车辆驾驶员3 recordDF("owDriver1Id").as("ow_driver1_id"), //出库车辆驾驶员 recordDF("owDriver2Id").as("ow_driver2_id"), //出库车辆驾驶员2 recordDF("owDriver3Id").as("ow_driver3_id"), //出库车辆驾驶员3 recordDF("routeId").as("route_id"),//线路id recordDF("distance").cast(IntegerType), //运输里程 recordDF("duration").cast(IntegerType), //运输耗时 recordDF("state").cast(IntegerType), //转运状态id recordDF("startVehicleDt").as("start_vehicle_dt"), //发车时间 recordDF("predictArrivalsDt").as("predict_arrivals_dt"), //预计到达时间 recordDF("actualArrivalsDt").as("actual_arrivals_dt"), //实际到达时间 recordDF("cdt"), //创建时间 recordDF("udt"), //修改时间 recordDF("remark"), //备注 companyDF("id").alias("company_id"), //公司id companyDF("companyName").as("company_name"), //公司名称 areasDF("id").alias("area_id"), //区域id areasDF("name").alias("area_name"), //区域名称 expressPackageDF.col("id").alias("package_id"), //包裹id expressPackageDF.col("name").alias("package_name"), //包裹名称 customerDF.col("id").alias("cid"), customerDF.col("name").alias("cname"), customerTypeDF("customerTypeCode").alias("ctype"), customerTypeDF("customerTypeName").alias("ctype_name"), dotDF("id").as("dot_id"), dotDF("dotName").as("dot_name"), $"day" ) //TODO 5)将拉宽后的数据再次写回到kudu数据库中(DWD明细层) save(wsDetailDF, OfflineTableDefine.wareHouseDetail) //删除缓存,释放资源 companyWareHouseMapDF.unpersist() companyDF.unpersist() areasDF.unpersist() wayBillDF.unpersist() expressBillDF.unpersist() senderInfoDF.unpersist() expressPackageDF.unpersist() customerDF.unpersist() customerTypeDF.unpersist() warehouseDF.unpersist() phWarehouseDF.unpersist() dotDF.unpersist() recordDF.unpersist() sparkSession.stop() }}五、仓库数据指标计算开发
1、计算的字段
|
字段名 |
字段描述 |
|
id |
数据产生时间 |
|
whMaxTotalCount |
各仓库最大发车次数 |
|
whMinTotalCount |
各仓库最小发车次数 |
|
whAvgTotalCount |
各仓库平均发车次数 |
|
dotMaxTotalCount |
各网点最大发车次数 |
|
dotMinTotalCount |
各网点最小发车次数 |
|
dotAvgTotalCount |
各网点平均发车次数 |
|
routeMaxTotalCount |
各线路最大发车次数 |
|
routeMinTotalCount |
各线路最小发车次数 |
|
routeAvgTotalCount |
各线路平均发车次数 |
|
consumerTypeMaxTotalCount |
各类型客户最大发车次数 |
|
consumerTypeMinTotalCount |
各类型客户最小发车次数 |
|
consumerTypeAvgTotalCount |
各类型客户平均发车次数 |
|
packageMaxTotalCount |
各类型包裹最大发车次数 |
|
packageMinTotalCount |
各类型包裹最小发车次数 |
|
packageAvgTotalCount |
各类型包裹平均发车次数 |
|
areaMaxTotalCount |
各区域最大发车次数 |
|
areaMinTotalCount |
各区域最小发车次数 |
|
areaAvgTotalCount |
各区域平均发车次数 |
|
companyMaxTotalCount |
各公司最大发车次数 |
|
companyMinTotalCount |
各公司最小发车次数 |
|
companyAvgTotalCount |
各公司平均发车次数 |
2、Spark实现
实现步骤:
- 在dws目录下创建 WarehouseDWS 单例对象,继承自OfflineApp特质
- 初始化环境的参数,创建SparkSession对象
- 根据指定的日期获取拉宽后的仓库宽表(tbl_warehouse_transport_detail)增量数据,并缓存数据
- 判断是否是首次运行,如果是首次运行的话,则全量装载数据(含历史数据)
- 指标计算
- 各仓库最大发车次数
- 各仓库最小发车次数
- 各仓库平均发车次数
- 各网点最大发车次数
- 各网点最小发车次数
- 各网点平均发车次数
- 各线路最大发车次数
- 各线路最小发车次数
- 各线路平均发车次数
- 各类型客户最大发车次数
- 各类型客户最小发车次数
- 各类型客户平均发车次数
- 各类型包裹最大发车次数
- 各类型包裹最小发车次数
- 各类型包裹平均发车次数
- 各区域最大发车次数
- 各区域最小发车次数
- 各区域平均发车次数
- 各公司最大发车次数
- 各公司最小发车次数
- 各公司平均发车次数
- 获取当前时间yyyyMMddHH
- 构建要持久化的指标数据(需要判断计算的指标是否有值,若没有需要赋值默认值)
- 通过StructType构建指定Schema
- 创建仓库指标数据表(若存在则不创建)
- 持久化指标数据到kudu表
2.1、初始化环境变量
package cn.it.logistics.offline.dwsimport cn.it.logistics.common.{Configuration, DateHelper, OfflineTableDefine, SparkUtils}import cn.it.logistics.offline.OfflineAppimport org.apache.spark.SparkConfimport org.apache.spark.rdd.RDDimport org.apache.spark.sql.{DataFrame, Row, SparkSession}import org.apache.spark.sql.types.{DoubleType, LongType, Metadata, StringType, StructField, StructType}import org.apache.spark.sql.functions._import org.apache.spark.storage.StorageLevelimport scala.collection.mutable.ArrayBuffer/** * 仓库主题指标开发 * 将计算好的指标数据结果写入到kudu数据库中 */object WarehouseDWS extends OfflineApp{ //定义应用程序的名称 val appName = this.getClass.getSimpleName /** * 入口函数 * @param args */ def main(args: Array[String]): Unit = { /** * 实现步骤: * 1)创建SparkConf对象 * 2)创建SparkSession对象 * 3)读取仓库明细宽表的数据 * 4)对仓库明细宽表的数据进行指标的计算 * 5)将计算好的指标数据写入到kudu数据库中 * 5.1:定义指标结果表的schema信息 * 5.2:组织需要写入到kudu表的数据 * 5.3:判断指标结果表是否存在,如果不存在则创建 * 5.4:将数据写入到kudu表中 * 6)删除缓存数据 * 7)停止任务,退出sparksession */ //TODO 1)创建SparkConf对象 val sparkConf: SparkConf = SparkUtils.autoSettingEnv( SparkUtils.sparkConf(appName) ) //TODO 2)创建SparkSession对象 val sparkSession: SparkSession = SparkUtils.getSparkSession(sparkConf) sparkSession.sparkContext.setLogLevel(Configuration.LOG_OFF) //处理数据 execute(sparkSession) } /** * 数据处理 * * @param sparkSession */ override def execute(sparkSession: SparkSession): Unit = { sparkSession.stop() }}2.2、加载仓库车辆宽表增量数据并缓存
加载仓库车辆宽表的时候,需要指定日期条件,因为仓库车辆主题最终需要Azkaban定时调度执行,每天执行一次增量数据,因此需要指定日期。
//TODO 3)读取仓库明细宽表的数据val whDetailDF: DataFrame = getKuduSource(sparkSession, OfflineTableDefine.wareHouseDetail, Configuration.isFirstRunnable).toDF().persist(StorageLevel.DISK_ONLY_2)2.3、指标计算
//根据仓库的日期进行分组val whDetailGroupByDayDF: DataFrame = whDetailDF.select("day").groupBy("day").count().cache()//导入隐式转换import sparkSession.implicits._//定义计算好的指标结果集合对象val rows: ArrayBuffer[Row] = ArrayBuffer[Row]()//循环遍历每个日期的仓库明细宽表数据whDetailGroupByDayDF.collect().foreach(row=>{ //获取到要处理的数据所在的日期 val day: String = row.getAs[String](0) //返回指定日期的仓库明细数据 val whDetailByDayDF: DataFrame = whDetailDF.where(col("day") === day).toDF().persist(StorageLevel.DISK_ONLY_2) //TODO 4)对仓库明细宽表的数据进行指标的计算 //各仓库发车次数(从哪个仓库发出的货物,根据发出仓库的仓库id进行分组) val wsTotalCountDF: DataFrame = whDetailByDayDF.groupBy("sw_id").agg(count("id").alias("cnt")).cache() //各仓库最大发车次数 val maxAndMinAndAvgTotalCountDF: Row = wsTotalCountDF.agg(max($"cnt"), min($"cnt"), avg($"cnt")).first() val wsMaxTotalCount: Any = maxAndMinAndAvgTotalCountDF(0) //各仓库最小发车次数 val wsMinTotalCount: Any = maxAndMinAndAvgTotalCountDF(1) //各仓库平均发车次数 val wsAvgTotalCount: Any = maxAndMinAndAvgTotalCountDF(2) //各网点发车次数 val dotTotalCountDF: DataFrame = whDetailByDayDF.groupBy("dot_id").agg(count("id").alias("cnt")).cache() //各网点最大发车次数 val maxAndMinAndAvgDotTotalCountDF: Row = dotTotalCountDF.agg(max($"cnt"), min($"cnt"), avg($"cnt")).first() val dotMaxTotalCount: Any = maxAndMinAndAvgDotTotalCountDF(0) //各网点最小发车次数 val dotMinTotalCount: Any = maxAndMinAndAvgDotTotalCountDF(1) //各网点平均发车次数 val dotAvgTotalCount: Any = maxAndMinAndAvgDotTotalCountDF(2) //各线路发车次数 val routeTotalCountDF: DataFrame = whDetailByDayDF.groupBy("route_id").agg(count("id").alias("cnt")).cache() //各线路最大发车次数 val maxAndMinAndAvgRouteTotalCountDF: Row = routeTotalCountDF.agg(max($"cnt"), min($"cnt"), avg($"cnt")).first() val routeMaxTotalCount: Any = maxAndMinAndAvgRouteTotalCountDF(0) //各线路最小发车次数 val routeMinTotalCount: Any = maxAndMinAndAvgRouteTotalCountDF(1) //各线路平均发车次数 val routeAvgTotalCount: Any = maxAndMinAndAvgRouteTotalCountDF(2) //各类型客户发车次数 val cTypeCountDF: DataFrame = whDetailByDayDF.groupBy("ctype").agg(count("id").alias("cnt")).cache() //各类型客户最大发车次数 val maxAndMinAndAvgCtypeTotalCountDF: Row = cTypeCountDF.agg(max($"cnt"), min($"cnt"), avg($"cnt")).first() val consumerTypeMaxTotalCount: Any = maxAndMinAndAvgCtypeTotalCountDF(0) //各类型客户最小发车次数 val consumerTypeMinTotalCount: Any = maxAndMinAndAvgCtypeTotalCountDF(1) //各类型客户平均发车次数 val consumerTypeAvgTotalCount: Any = maxAndMinAndAvgCtypeTotalCountDF(2) //各类型客户发车次数 val pkgCountDF: DataFrame = whDetailByDayDF.groupBy("package_id").agg(count("id").alias("cnt")).cache() //各类型包裹最大发车次数 val maxAndMinAndAvgPkgTotalCountDF: Row = pkgCountDF.agg(max($"cnt"), min($"cnt"), avg($"cnt")).first() val packageMaxTotalCount: Any = maxAndMinAndAvgPkgTotalCountDF(0) //各类型包裹最小发车次数 val packageMinTotalCount: Any = maxAndMinAndAvgPkgTotalCountDF(1) //各类型包裹平均发车次数 val packageAvgTotalCount: Any = maxAndMinAndAvgPkgTotalCountDF(2) //各区域发车次数 val areaCountDF: DataFrame = whDetailByDayDF.groupBy("area_id").agg(count("id").alias("cnt")).cache() //各区域最大发车次数 val maxAndMinAndAvgAreaTotalCountDF: Row = areaCountDF.agg(max($"cnt"), min($"cnt"), avg($"cnt")).first() val areaMaxTotalCount: Any = maxAndMinAndAvgAreaTotalCountDF(0) //各区域最小发车次数 val areaMinTotalCount: Any = maxAndMinAndAvgAreaTotalCountDF(1) //各区域平均发车次数 val areaAvgTotalCount: Any = maxAndMinAndAvgAreaTotalCountDF(2) //各公司发车次数 val companyCountDF: DataFrame = whDetailByDayDF.groupBy("company_id").agg(count("id").alias("cnt")).cache() //各公司最大发车次数 val maxAndMinAndAvgCompanyTotalCountDF: Row = areaCountDF.agg(max($"cnt"), min($"cnt"), avg($"cnt")).first() val companyMaxTotalCount: Any = maxAndMinAndAvgCompanyTotalCountDF(0) //各公司最小发车次数 val companyMinTotalCount: Any = maxAndMinAndAvgCompanyTotalCountDF(1) //各公司平均发车次数 val companyAvgTotalCount: Any = maxAndMinAndAvgCompanyTotalCountDF(2) //将计算好的指标数据封装到row对象中 val rowInfo: Row = Row( day, if(wsMaxTotalCount==null) 0L else wsMaxTotalCount.asInstanceOf[Number].longValue(), if(wsMinTotalCount==null) 0L else wsMinTotalCount.asInstanceOf[Number].longValue(), if(wsAvgTotalCount==null) 0L else wsAvgTotalCount.asInstanceOf[Number].longValue(), if(dotMaxTotalCount==null) 0L else dotMaxTotalCount.asInstanceOf[Number].longValue(), if(dotMinTotalCount==null) 0L else dotMinTotalCount.asInstanceOf[Number].longValue(), if(dotAvgTotalCount==null) 0L else dotAvgTotalCount.asInstanceOf[Number].longValue(), if(routeMaxTotalCount==null) 0L else routeMaxTotalCount.asInstanceOf[Number].longValue(), if(routeMinTotalCount==null) 0L else routeMinTotalCount.asInstanceOf[Number].longValue(), if(routeAvgTotalCount==null) 0L else routeAvgTotalCount.asInstanceOf[Number].longValue(), if(consumerTypeMaxTotalCount==null) 0L else consumerTypeMaxTotalCount.asInstanceOf[Number].longValue(), if(consumerTypeMinTotalCount==null) 0L else consumerTypeMinTotalCount.asInstanceOf[Number].longValue(), if(consumerTypeAvgTotalCount==null) 0L else consumerTypeAvgTotalCount.asInstanceOf[Number].longValue(), if(packageMaxTotalCount==null) 0L else packageMaxTotalCount.asInstanceOf[Number].longValue(), if(packageMinTotalCount==null) 0L else packageMinTotalCount.asInstanceOf[Number].longValue(), if(packageAvgTotalCount==null) 0L else packageAvgTotalCount.asInstanceOf[Number].longValue(), if(areaMaxTotalCount==null) 0L else areaMaxTotalCount.asInstanceOf[Number].longValue(), if(areaMinTotalCount==null) 0L else areaMinTotalCount.asInstanceOf[Number].longValue(), if(areaAvgTotalCount==null) 0L else areaAvgTotalCount.asInstanceOf[Number].longValue(), if(companyMaxTotalCount==null) 0L else companyMaxTotalCount.asInstanceOf[Number].longValue(), if(companyMinTotalCount==null) 0L else companyMinTotalCount.asInstanceOf[Number].longValue(), if(companyAvgTotalCount==null) 0L else companyAvgTotalCount.asInstanceOf[Number].longValue() ) rows.append(rowInfo) println(rowInfo) //删除缓存,释放资源 whDetailByDayDF.unpersist() wsTotalCountDF.unpersist() companyCountDF.unpersist() areaCountDF.unpersist() pkgCountDF.unpersist() cTypeCountDF.unpersist() routeTotalCountDF.unpersist() dotTotalCountDF.unpersist()})2.4、通过StructType构建指定Schema
//定义表结构信息val schema = StructType(Array( StructField("id", StringType, false, Metadata.empty), StructField("wsMaxTotalCount", LongType, true, Metadata.empty), //各仓库最大发车次数 StructField("wsMinTotalCount", LongType, true, Metadata.empty), //各仓库最小发车次数 StructField("wsAvgTotalCount", LongType, true, Metadata.empty), //各仓库平均发车次数 StructField("dotMaxTotalCount", LongType, true, Metadata.empty), //各网点最大发车次数 StructField("dotMinTotalCount", LongType, true, Metadata.empty), //各网点最小发车次数 StructField("dotAvgTotalCount", LongType, true, Metadata.empty), //各网点平均发车次数 StructField("routeMaxTotalCount", LongType, true, Metadata.empty), //各线路最大发车次数 StructField("routeMinTotalCount", LongType, true, Metadata.empty), //各线路最小发车次数 StructField("routeAvgTotalCount", LongType, true, Metadata.empty), //各线路平均发车次数 StructField("consumerTypeMaxTotalCount", LongType, true, Metadata.empty), //各客户类型最大发车次数 StructField("consumerTypeMinTotalCount", LongType, true, Metadata.empty), //各客户类型最小发车次数 StructField("consumerTypeAvgTotalCount", LongType, true, Metadata.empty), //各客户类型平均发车次数 StructField("packageMaxTotalCount", LongType, true, Metadata.empty), //各类型包裹最大发车次数 StructField("packageMinTotalCount", LongType, true, Metadata.empty), //各类型包裹最小发车次数 StructField("packageAvgTotalCount", LongType, true, Metadata.empty), //各类型包裹平均发车次数 StructField("areaMaxTotalCount", LongType, true, Metadata.empty), //各区域最大发车次数 StructField("areaMinTotalCount", LongType, true, Metadata.empty), //各区域最小发车次数 StructField("areaAvgTotalCount", LongType, true, Metadata.empty), //各区域平均发车次数 StructField("companyMaxTotalCount", LongType, true, Metadata.empty), //各公司最大发车次数 StructField("companyMinTotalCount", LongType, true, Metadata.empty), //各公司最小发车次数 StructField("companyAvgTotalCount", LongType, true, Metadata.empty)//各公司平均发车次数))2.5、持久化指标数据到kudu表
//将rows对象转换成rdd对象val data: RDD[Row] = sparkSession.sparkContext.makeRDD(rows)//使用rdd和schema创建dataFrame对象val quotaDF: DataFrame = sparkSession.createDataFrame(data, schema)//quotaDF.show()//将数据写入到kudu数据库save(quotaDF, OfflineTableDefine.wareHouseSummary)2.6、完整代码
package cn.it.logistics.offline.dwsimport cn.it.logistics.common.{Configuration, DateHelper, OfflineTableDefine, SparkUtils}import cn.it.logistics.offline.OfflineAppimport org.apache.spark.SparkConfimport org.apache.spark.rdd.RDDimport org.apache.spark.sql.{DataFrame, Row, SparkSession}import org.apache.spark.sql.types.{DoubleType, LongType, Metadata, StringType, StructField, StructType}import org.apache.spark.sql.functions._import org.apache.spark.storage.StorageLevelimport scala.collection.mutable.ArrayBuffer/** * 仓库主题指标开发 * 将计算好的指标数据结果写入到kudu数据库中 */object WarehouseDWS extends OfflineApp{ //定义应用程序的名称 val appName = this.getClass.getSimpleName /** * 入口函数 * @param args */ def main(args: Array[String]): Unit = { /** * 实现步骤: * 1)创建SparkConf对象 * 2)创建SparkSession对象 * 3)读取仓库明细宽表的数据 * 4)对仓库明细宽表的数据进行指标的计算 * 5)将计算好的指标数据写入到kudu数据库中 * 5.1:定义指标结果表的schema信息 * 5.2:组织需要写入到kudu表的数据 * 5.3:判断指标结果表是否存在,如果不存在则创建 * 5.4:将数据写入到kudu表中 * 6)删除缓存数据 * 7)停止任务,退出sparksession */ //TODO 1)创建SparkConf对象 val sparkConf: SparkConf = SparkUtils.autoSettingEnv( SparkUtils.sparkConf(appName) ) //TODO 2)创建SparkSession对象 val sparkSession: SparkSession = SparkUtils.getSparkSession(sparkConf) sparkSession.sparkContext.setLogLevel(Configuration.LOG_OFF) //处理数据 execute(sparkSession) } /** * 数据处理 * * @param sparkSession */ override def execute(sparkSession: SparkSession): Unit = { //TODO 3)读取仓库明细宽表的数据 val whDetailDF: DataFrame = getKuduSource(sparkSession, OfflineTableDefine.wareHouseDetail, Configuration.isFirstRunnable).toDF().persist(StorageLevel.DISK_ONLY_2) //根据仓库的日期进行分组 val whDetailGroupByDayDF: DataFrame = whDetailDF.select("day").groupBy("day").count().cache() //导入隐式转换 import sparkSession.implicits._ //定义计算好的指标结果集合对象 val rows: ArrayBuffer[Row] = ArrayBuffer[Row]() //循环遍历每个日期的仓库明细宽表数据 whDetailGroupByDayDF.collect().foreach(row=>{ //获取到要处理的数据所在的日期 val day: String = row.getAs[String](0) //返回指定日期的仓库明细数据 val whDetailByDayDF: DataFrame = whDetailDF.where(col("day") === day).toDF().persist(StorageLevel.DISK_ONLY_2) //TODO 4)对仓库明细宽表的数据进行指标的计算 //各仓库发车次数(从哪个仓库发出的货物,根据发出仓库的仓库id进行分组) val wsTotalCountDF: DataFrame = whDetailByDayDF.groupBy("sw_id").agg(count("id").alias("cnt")).cache() //各仓库最大发车次数 val maxAndMinAndAvgTotalCountDF: Row = wsTotalCountDF.agg(max($"cnt"), min($"cnt"), avg($"cnt")).first() val wsMaxTotalCount: Any = maxAndMinAndAvgTotalCountDF(0) //各仓库最小发车次数 val wsMinTotalCount: Any = maxAndMinAndAvgTotalCountDF(1) //各仓库平均发车次数 val wsAvgTotalCount: Any = maxAndMinAndAvgTotalCountDF(2) //各网点发车次数 val dotTotalCountDF: DataFrame = whDetailByDayDF.groupBy("dot_id").agg(count("id").alias("cnt")).cache() //各网点最大发车次数 val maxAndMinAndAvgDotTotalCountDF: Row = dotTotalCountDF.agg(max($"cnt"), min($"cnt"), avg($"cnt")).first() val dotMaxTotalCount: Any = maxAndMinAndAvgDotTotalCountDF(0) //各网点最小发车次数 val dotMinTotalCount: Any = maxAndMinAndAvgDotTotalCountDF(1) //各网点平均发车次数 val dotAvgTotalCount: Any = maxAndMinAndAvgDotTotalCountDF(2) //各线路发车次数 val routeTotalCountDF: DataFrame = whDetailByDayDF.groupBy("route_id").agg(count("id").alias("cnt")).cache() //各线路最大发车次数 val maxAndMinAndAvgRouteTotalCountDF: Row = routeTotalCountDF.agg(max($"cnt"), min($"cnt"), avg($"cnt")).first() val routeMaxTotalCount: Any = maxAndMinAndAvgRouteTotalCountDF(0) //各线路最小发车次数 val routeMinTotalCount: Any = maxAndMinAndAvgRouteTotalCountDF(1) //各线路平均发车次数 val routeAvgTotalCount: Any = maxAndMinAndAvgRouteTotalCountDF(2) //各类型客户发车次数 val cTypeCountDF: DataFrame = whDetailByDayDF.groupBy("ctype").agg(count("id").alias("cnt")).cache() //各类型客户最大发车次数 val maxAndMinAndAvgCtypeTotalCountDF: Row = cTypeCountDF.agg(max($"cnt"), min($"cnt"), avg($"cnt")).first() val consumerTypeMaxTotalCount: Any = maxAndMinAndAvgCtypeTotalCountDF(0) //各类型客户最小发车次数 val consumerTypeMinTotalCount: Any = maxAndMinAndAvgCtypeTotalCountDF(1) //各类型客户平均发车次数 val consumerTypeAvgTotalCount: Any = maxAndMinAndAvgCtypeTotalCountDF(2) //各类型客户发车次数 val pkgCountDF: DataFrame = whDetailByDayDF.groupBy("package_id").agg(count("id").alias("cnt")).cache() //各类型包裹最大发车次数 val maxAndMinAndAvgPkgTotalCountDF: Row = pkgCountDF.agg(max($"cnt"), min($"cnt"), avg($"cnt")).first() val packageMaxTotalCount: Any = maxAndMinAndAvgPkgTotalCountDF(0) //各类型包裹最小发车次数 val packageMinTotalCount: Any = maxAndMinAndAvgPkgTotalCountDF(1) //各类型包裹平均发车次数 val packageAvgTotalCount: Any = maxAndMinAndAvgPkgTotalCountDF(2) //各区域发车次数 val areaCountDF: DataFrame = whDetailByDayDF.groupBy("area_id").agg(count("id").alias("cnt")).cache() //各区域最大发车次数 val maxAndMinAndAvgAreaTotalCountDF: Row = areaCountDF.agg(max($"cnt"), min($"cnt"), avg($"cnt")).first() val areaMaxTotalCount: Any = maxAndMinAndAvgAreaTotalCountDF(0) //各区域最小发车次数 val areaMinTotalCount: Any = maxAndMinAndAvgAreaTotalCountDF(1) //各区域平均发车次数 val areaAvgTotalCount: Any = maxAndMinAndAvgAreaTotalCountDF(2) //各公司发车次数 val companyCountDF: DataFrame = whDetailByDayDF.groupBy("company_id").agg(count("id").alias("cnt")).cache() //各公司最大发车次数 val maxAndMinAndAvgCompanyTotalCountDF: Row = areaCountDF.agg(max($"cnt"), min($"cnt"), avg($"cnt")).first() val companyMaxTotalCount: Any = maxAndMinAndAvgCompanyTotalCountDF(0) //各公司最小发车次数 val companyMinTotalCount: Any = maxAndMinAndAvgCompanyTotalCountDF(1) //各公司平均发车次数 val companyAvgTotalCount: Any = maxAndMinAndAvgCompanyTotalCountDF(2) //将计算好的指标数据封装到row对象中 val rowInfo: Row = Row( day, if(wsMaxTotalCount==null) 0L else wsMaxTotalCount.asInstanceOf[Number].longValue(), if(wsMinTotalCount==null) 0L else wsMinTotalCount.asInstanceOf[Number].longValue(), if(wsAvgTotalCount==null) 0L else wsAvgTotalCount.asInstanceOf[Number].longValue(), if(dotMaxTotalCount==null) 0L else dotMaxTotalCount.asInstanceOf[Number].longValue(), if(dotMinTotalCount==null) 0L else dotMinTotalCount.asInstanceOf[Number].longValue(), if(dotAvgTotalCount==null) 0L else dotAvgTotalCount.asInstanceOf[Number].longValue(), if(routeMaxTotalCount==null) 0L else routeMaxTotalCount.asInstanceOf[Number].longValue(), if(routeMinTotalCount==null) 0L else routeMinTotalCount.asInstanceOf[Number].longValue(), if(routeAvgTotalCount==null) 0L else routeAvgTotalCount.asInstanceOf[Number].longValue(), if(consumerTypeMaxTotalCount==null) 0L else consumerTypeMaxTotalCount.asInstanceOf[Number].longValue(), if(consumerTypeMinTotalCount==null) 0L else consumerTypeMinTotalCount.asInstanceOf[Number].longValue(), if(consumerTypeAvgTotalCount==null) 0L else consumerTypeAvgTotalCount.asInstanceOf[Number].longValue(), if(packageMaxTotalCount==null) 0L else packageMaxTotalCount.asInstanceOf[Number].longValue(), if(packageMinTotalCount==null) 0L else packageMinTotalCount.asInstanceOf[Number].longValue(), if(packageAvgTotalCount==null) 0L else packageAvgTotalCount.asInstanceOf[Number].longValue(), if(areaMaxTotalCount==null) 0L else areaMaxTotalCount.asInstanceOf[Number].longValue(), if(areaMinTotalCount==null) 0L else areaMinTotalCount.asInstanceOf[Number].longValue(), if(areaAvgTotalCount==null) 0L else areaAvgTotalCount.asInstanceOf[Number].longValue(), if(companyMaxTotalCount==null) 0L else companyMaxTotalCount.asInstanceOf[Number].longValue(), if(companyMinTotalCount==null) 0L else companyMinTotalCount.asInstanceOf[Number].longValue(), if(companyAvgTotalCount==null) 0L else companyAvgTotalCount.asInstanceOf[Number].longValue() ) rows.append(rowInfo) println(rowInfo) //删除缓存,释放资源 whDetailByDayDF.unpersist() wsTotalCountDF.unpersist() companyCountDF.unpersist() areaCountDF.unpersist() pkgCountDF.unpersist() cTypeCountDF.unpersist() routeTotalCountDF.unpersist() dotTotalCountDF.unpersist() }) //定义表结构信息 val schema = StructType(Array( StructField("id", StringType, false, Metadata.empty), StructField("wsMaxTotalCount", LongType, true, Metadata.empty), //各仓库最大发车次数 StructField("wsMinTotalCount", LongType, true, Metadata.empty), //各仓库最小发车次数 StructField("wsAvgTotalCount", LongType, true, Metadata.empty), //各仓库平均发车次数 StructField("dotMaxTotalCount", LongType, true, Metadata.empty), //各网点最大发车次数 StructField("dotMinTotalCount", LongType, true, Metadata.empty), //各网点最小发车次数 StructField("dotAvgTotalCount", LongType, true, Metadata.empty), //各网点平均发车次数 StructField("routeMaxTotalCount", LongType, true, Metadata.empty), //各线路最大发车次数 StructField("routeMinTotalCount", LongType, true, Metadata.empty), //各线路最小发车次数 StructField("routeAvgTotalCount", LongType, true, Metadata.empty), //各线路平均发车次数 StructField("consumerTypeMaxTotalCount", LongType, true, Metadata.empty), //各客户类型最大发车次数 StructField("consumerTypeMinTotalCount", LongType, true, Metadata.empty), //各客户类型最小发车次数 StructField("consumerTypeAvgTotalCount", LongType, true, Metadata.empty), //各客户类型平均发车次数 StructField("packageMaxTotalCount", LongType, true, Metadata.empty), //各类型包裹最大发车次数 StructField("packageMinTotalCount", LongType, true, Metadata.empty), //各类型包裹最小发车次数 StructField("packageAvgTotalCount", LongType, true, Metadata.empty), //各类型包裹平均发车次数 StructField("areaMaxTotalCount", LongType, true, Metadata.empty), //各区域最大发车次数 StructField("areaMinTotalCount", LongType, true, Metadata.empty), //各区域最小发车次数 StructField("areaAvgTotalCount", LongType, true, Metadata.empty), //各区域平均发车次数 StructField("companyMaxTotalCount", LongType, true, Metadata.empty), //各公司最大发车次数 StructField("companyMinTotalCount", LongType, true, Metadata.empty), //各公司最小发车次数 StructField("companyAvgTotalCount", LongType, true, Metadata.empty)//各公司平均发车次数 )) //将rows对象转换成rdd对象 val data: RDD[Row] = sparkSession.sparkContext.makeRDD(rows) //使用rdd和schema创建dataFrame对象 val quotaDF: DataFrame = sparkSession.createDataFrame(data, schema) //quotaDF.show() //将数据写入到kudu数据库 save(quotaDF, OfflineTableDefine.wareHouseSummary) sparkSession.stop() }}- 📢博客主页:https://lansonli.blog.csdn.net
- 📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正!
- 📢本文由 Lansonli 原创,首发于 CSDN博客🙉
- 📢停下休息的时候不要忘了别人还在奔跑,希望大家抓紧时间学习,全力奔赴更美好的生活✨