ResNet深度残差(论文理解)
今日学习了深度残差连接模块的概念(ResNet)
问题提出的背景为:
1. 随着网络层的加深,模型在测试集和训练集上的误差也随之增大具体如下图表示
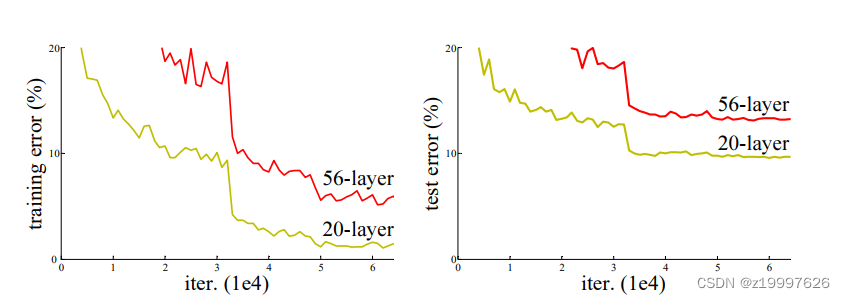
56层的网络模型误差明显高于20层的网络模型误差
2. 网络层数的加深会带来梯度爆炸与梯度消失的问题
梯度消失:在神经网络的训练过程中会产生误差梯度,而有时误差梯度会非常小,这就会导致权重值更新会受到阻碍,甚至达到停滞的阶段。
梯度爆炸:与梯度消失问题相反,在深层网路的训练过程中梯度误差会不停的累加,这会导致权重动荡的幅度很大,极端情况下权重值会异常大。
3:下降的原因不是因为过拟合(过拟合情况模型在训练集上的表现应该更好),而且在加深网络层后并没有减少误差
问题解决方法:
1.非该论文提出的方法:添加本征映射层,其他层复制已经学习过的浅层。 SGD无法找出最优2 该论文提出的方法: 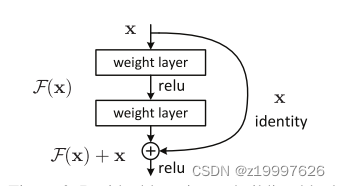
从梯度更新的角度
无残差模块梯度更新:
有残差模块的梯度更新:相对于无残差模块,有残差模块添加了固有的梯度所以在训练时即使权重过小,但是固有梯度任然可以使网络不断训练.
网络结构
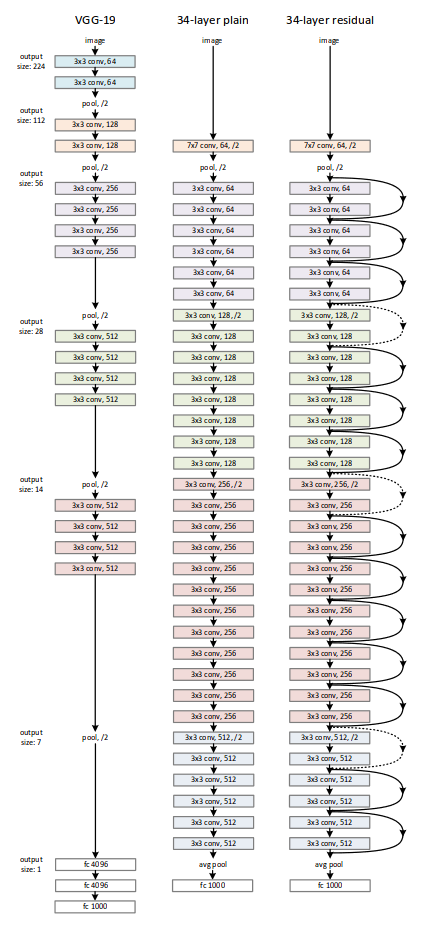
1.对于输出feature map大小相同的层,有相同的filter 即channel即可,当feature map大小减半时(池化层)channel数量翻倍
2.维度相匹配时使用实线连接,相反使用虚线连接。维度不相互匹配时有三种方案可供选择
A:zero padding操作增加维度
B:使用 1*1的卷积核,直接设置channel 数
C:所有的shortcuts使用全连接层映射
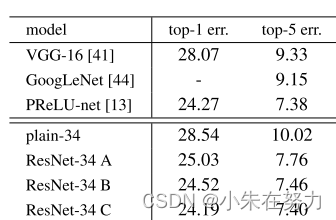
原论文中对比了三种操作方法,C方法在数值上变现更好,但是会增加计算复杂度,所以一般使用B方法 .