【论文解读】RepLKNet,基于Swin架构的超大核网络
摘要
pytoch代码:https://github.com/DingXiaoH/RepLKNet-pytorch
论文翻译:https://wanghao.blog.csdn.net/article/details/124875771?spm=1001.2014.3001.5502
RepLKNet的作者受vision transformers (ViT) 最新进展的启发,提出了31×31的超大核模型,与小核 CNN 相比,大核 CNN 具有更大的有效感受野和更高的形状偏差而不是纹理偏差。借鉴 Swin Transformer 的宏观架构,提出了一种架构 RepLKNet。在 ImageNet 上获得 87.8% 的 top-1 准确率,在 ADE20K 上获得 56.0% mIoU,这在具有相似模型大小的最先进技术中非常具有竞争力。

论文的贡献
论文的主要贡献有:
-
总结了使用超大核的五条准则:
-
用 depth-wise 超大卷积,最好再加底层优化。
-
加 shortcut
-
用小卷积核做重参数化
-
要看下游任务的性能,不能只看 ImageNet 点数高低
-
小 feature map 上也可以用大卷积,常规分辨率就能训大 kernel 模型
-
-
基于以上准则,简单借鉴 Swin Transformer 的宏观架构,我们提出了一种架构 RepLKNet,其中大量使用超大卷积,如 27x27、31x31 等。这一架构的其他部分非常简单,都是 1x1 卷积、Batch Norm 等喜闻乐见的简单结构,不用任何 attention。
-
基于超大卷积核,对有效感受野、shape bias(模型做决定的时候到底是看物体的形状还是看局部的纹理?)、Transformers 之所以性能强悍的原因等话题的讨论和分析。我们发现,ResNet-152 等传统深层小 kernel 模型的有效感受野其实不大,大 kernel 模型不但有效感受野更大而且更像人类(shape bias 高),Transformer 可能关键在于大 kernel 而不在于 self-attention 的具体形式。
挑战传统认知
RepLKNet的出现,打破了大家对CNN的固有的认知,主要有:
-
超大卷积不但不涨点,而且还掉点?RepLKNet证明,超大卷积在过去没人用,不代表其现在不能用。在现代 CNN 设计(shortcut、重参数化等)的加持下,kernel size 越大越涨点!
-
超大卷积效率很差?超大 depth-wise 卷积并不会增加多少 FLOPs。如果再加点底层优化,速度会更快,31x31 的计算密度最高可达 3x3 的 70 倍!
-
大卷积只能用在大 feature map 上?作者发现,在 7x7 的 feature map 上用 13x13 卷积都能涨点。
-
ImageNet 点数说明一切?我们发现,下游(目标检测、语义分割等)任务的性能可能跟 ImageNet 关系不大。
-
超深 CNN(如 ResNet-152)堆叠大量 3x3,所以感受野很大?作者发现,深层小 kernel 模型有效感受野其实很小。反而少量超大卷积核的有效感受野非常大。
-
Transformers(ViT、Swin 等)在下游任务上性能强悍,是因为 self-attention(Query-Key-Value 的设计形式)本质更强?作者用超大卷积核验证,发现kernel size 可能才是下游涨点的关键。
整体架构
作者也说了,架构就是用了Swin Transformer ,主要在于把 attention 换成超大卷积和与之配套的结构,再加一点 CNN 风格的改动。根据以上五条准则,RepLKNet 的设计元素包括 shortcut、depth-wise 超大 kernel、小 kernel 重参数化等。整体架构如下:
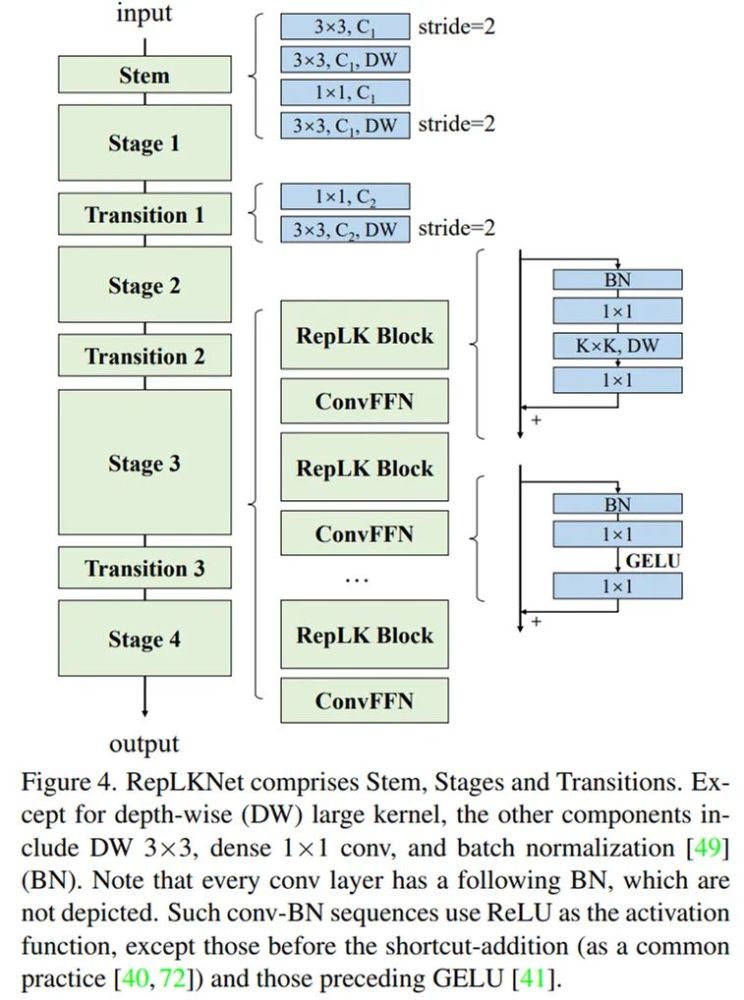
参考文章:
https://zhuanlan.zhihu.com/p/481445076?utm_source=wechat_session&utm_medium=social&utm_oi=56560353017856&utm_campaign=shareopn