Java|优先级队列(堆)
文章目录
- 什么是优先级队列(堆)
- 基于二叉树的堆(二叉堆)
-
- 二叉堆的特点
- 堆的实现
-
- 堆的定义
- 堆的上浮(添加)操作
- 在堆中取出最大值
- heapify - 堆化
- 优先级队列实现
- 对象之间的大小关系比较
-
- Comparable接口
- Comparator接口
- TopK问题
-
- 面试题17.14.最小K个数
- 原地堆排序
什么是优先级队列(堆)
普通队列是一种LILO的结构,按照元素入队顺序出队,先入先出
而优先级队列(PriorityQueue)又称为堆,是一种按照优先级的大小动态入队出队的的数据结构
动态指的是元素个数会动态变化,而非固定的
现实中的的优先级队列:
- 大家肯定有过排队买票的经历,正常来说,我们都是按照排队的顺序买票的,不过呢,为了照顾老弱伤残以及军人等,他们享有优先购票的权利,可以直接到走到窗口前购票
- 操作系统的任务调度:一般来说系统任务优先级要高于普通的软件,因为对于CPU和内存等硬件来说,当资源不够用的时候,优先让优先级高的应用继续执行
优先级队列不同于排序,最核心的不同点在于排序是数组元素个数确定的情况,而优先级队列是在动态变化的
普通链式队列和优先级队列的时间复杂度比较:
| 入队 | 出队 | |
|---|---|---|
| 普通链式队列 | O(1) | O(n) |
| 优先级队列 | O(log n) | O(log n) |
在计算机领域中,若见到log n时间复杂度,近乎一定和"树"结构相关(这里并非指的是一定要构造一棵树结构,而是算法的过程在逻辑上是一颗树)
基于二叉树的堆(二叉堆)
二叉堆的特点
- 是一棵完全二叉树,基于数组存储(元素都是靠左排列,数组中不会存有null结点,因此不会浪费空间)
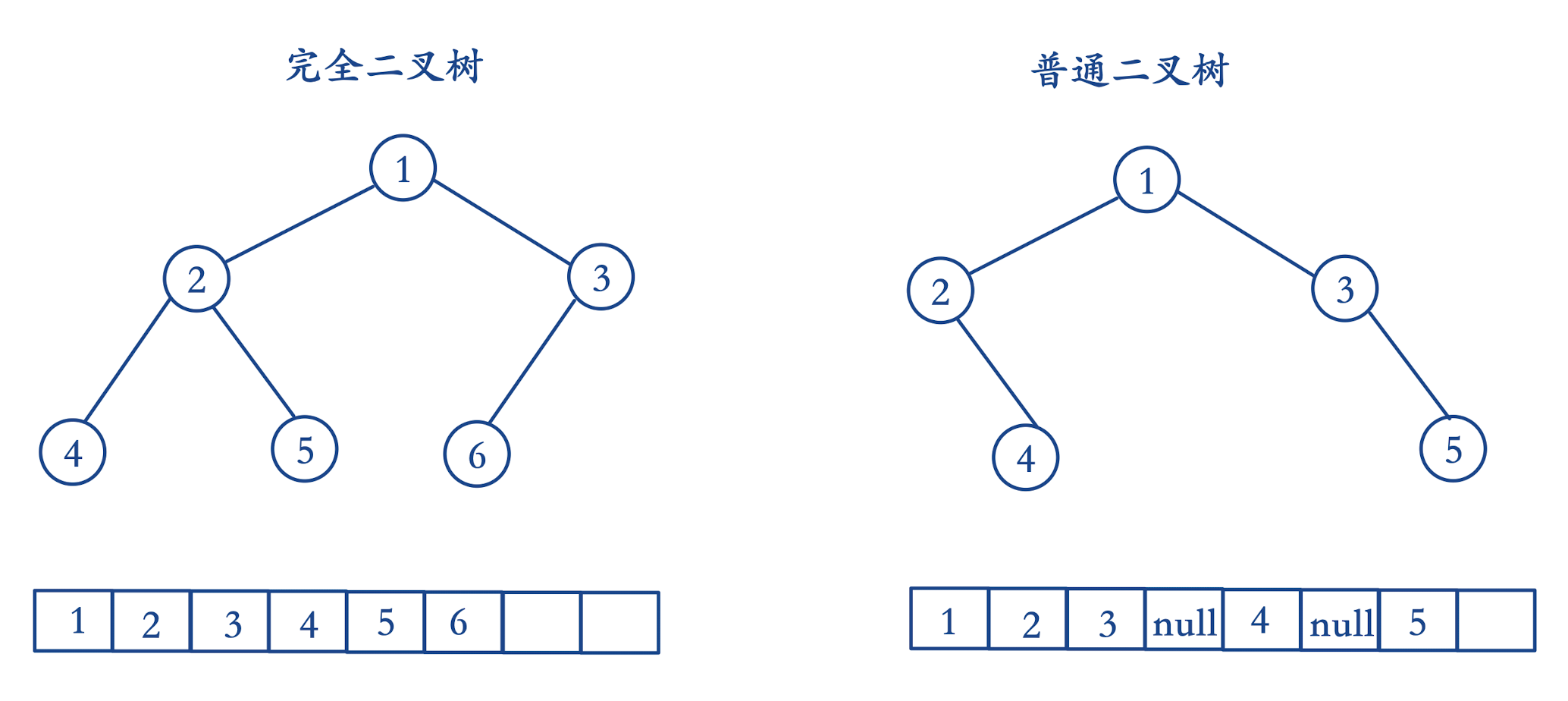
-
关于结点值:
堆中的根结点值 >= 子树结点中的值(称为最大堆、大根堆)
堆中的根结点值 <= 子树结点中的值(称为最小堆、小根堆)
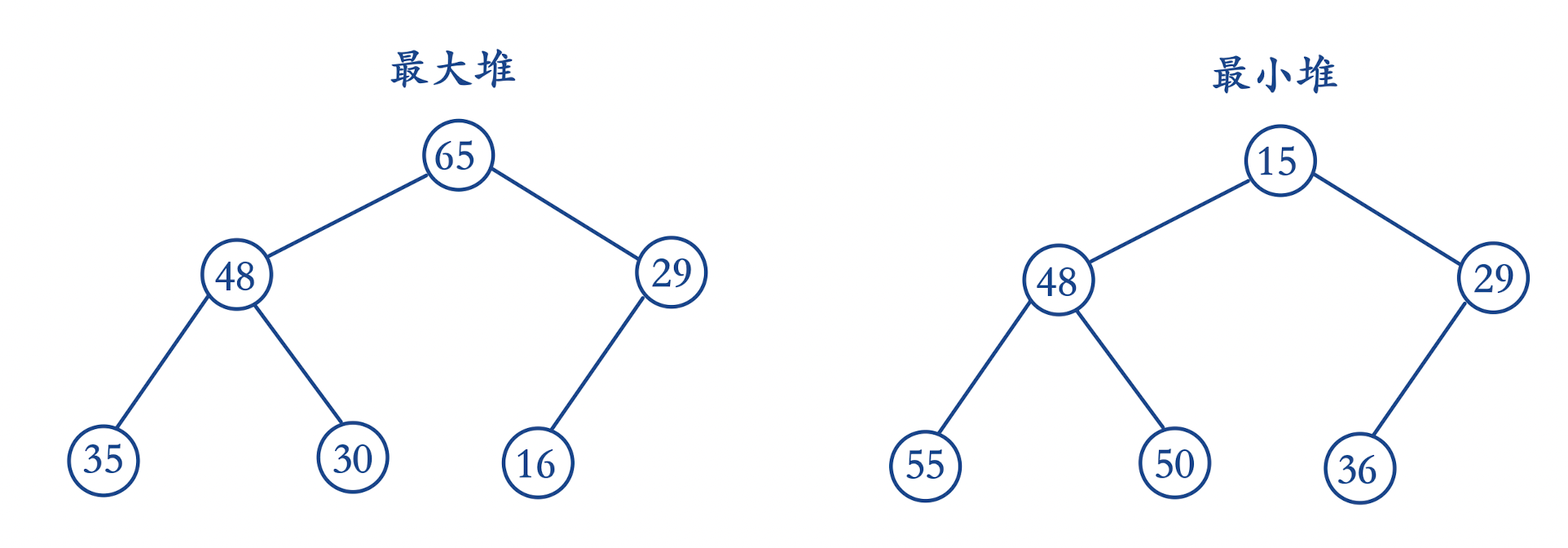
注意一点,最大堆和最小堆的意思并不是深度越深值越小或越大,这个定义只针对根结点和子树结点之间的关系
JDK中的PriorityQueue默认是基于最小堆的实现
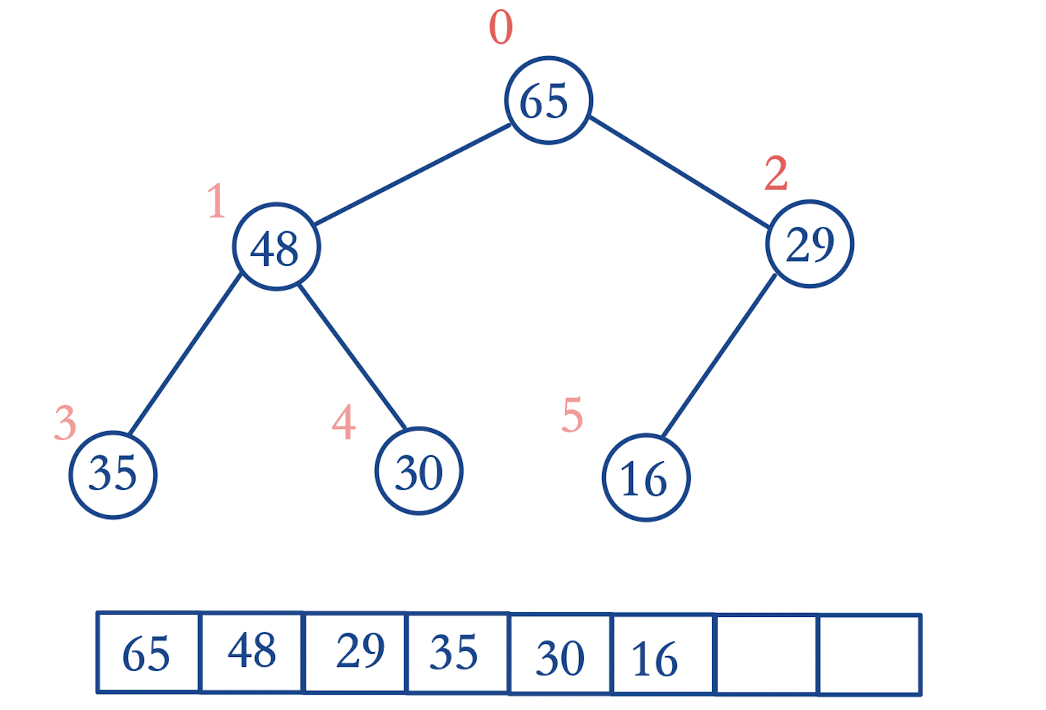
- 堆是基于数组来存储的,结点之间的关系通过数组下标来表示:
根结点的编号为0,作为数组下标的开始
假设此时某个结点的编号为i,且存在父结点和子结点
父结点的编号:(i-1)/2
左子树的结点编号:left = 2 * i + 1
右子树的结点编号: right = 2 * i + 2
堆的实现
基于动态数组ArrayList实现的最大堆
堆的定义
public class MaxHeap { private List<Integer> elementData; private int size; public MaxHeap() { this(10); } public MaxHeap(int size) { elementData = new ArrayList<>(size); } public int getSize() { return size; } //获取索引k指向结点的父结点索引 public int parent(int k){ return (k - 1) / 2; } //获取索引k指向结点的左子结点索引 public int leftChild(int k){ return k * 2 + 1; } //获取索引k指向结点的右子结点索引 public int rightChild(int k){ return k * 2 + 2; } public boolean isEmpty(){ return size == 0; } public String toString(){ return elementData.toString(); }}堆的上浮(添加)操作
为了保证添加完依然是完全二叉树,所以直接在末尾添加,不过在末尾添加一个元素之后,该二叉树可能不再是一个最大堆了
如果是这种情况,我们就要让该元素走到合适的位置,让这个完全二叉树依然满足最大堆的条件
让元素走到合适的位置处的过程就叫做"上浮"
具体操作是:不断通过索引值将新添加结点与父结点进行大小关系的比较,如果大于父结点,就交换彼此的结点值,直到该结点值 <= 父结点位置或者已经走到树根了(这就是上浮的终止条件)
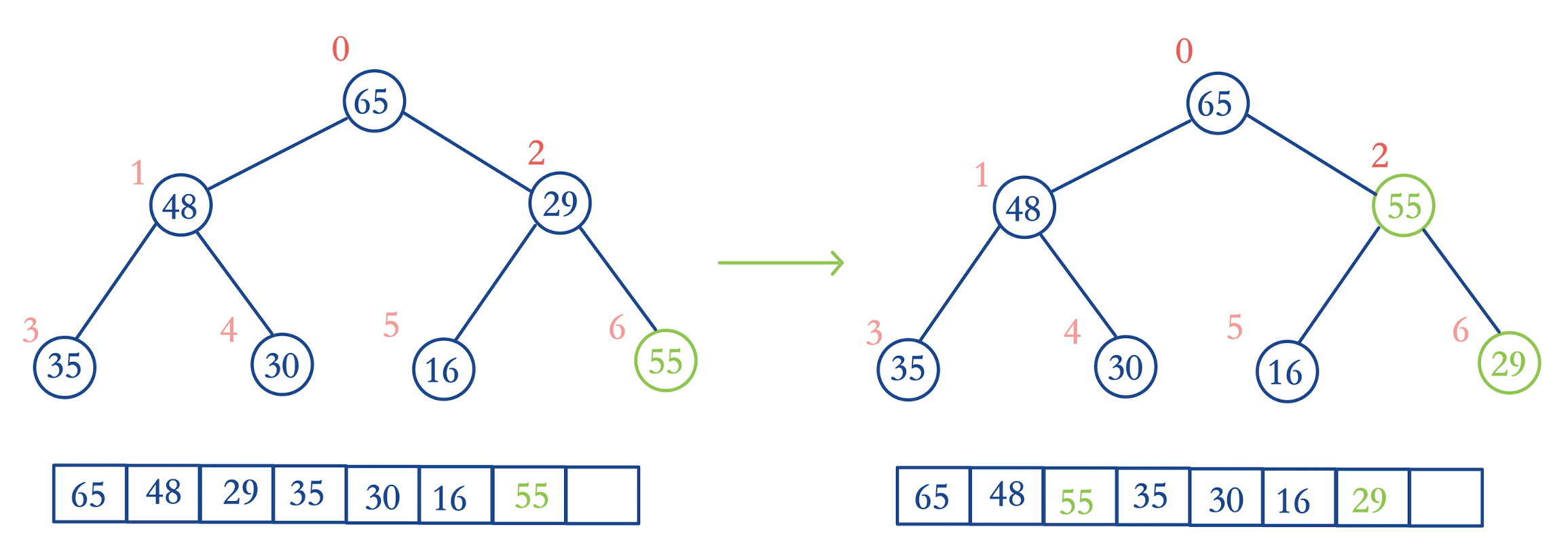
通过"上浮"操作后,原先被破坏的最大堆又成为了最大堆
代码实现:
public void add(int val){ elementData.add(val); size++; //上浮 siftUp(size - 1);}//上浮操作定义private void siftUp(int k) { //当k不为根结点,且k指向的结点值大于其父结点的值时上浮 while(k > 0 && elementData.get(k) > elementData.get(parent(k))){ swap(k, parent(k));//交换两个索引所对应的值 k = parent(k);//不断让k指向交换后的索引位置 }}//传入两个索引,交换两个索引指向的值private void swap(int k, int parent){ int childVal = elementData.get(k); int parentVal = elementData.get(parent); elementData.set(k, parentVal); elementData.set(parent, childVal);}在堆中取出最大值
取出最大值其实非常容易,我们可以直接取出树根结点即可
但是取出最大值之后,完全二叉树就会被破坏,考虑到该优先级队列是由数组实现的,因此,我们可以把最后一个元素覆盖掉首元素,这就完成了删除,且没有破坏完全二叉树
不过这么做还是有个问题,将小元素放到树根,这破坏了最大堆的性质
我们构造一个方法,实现元素的下沉操作,让其仍然满足最大堆的性质
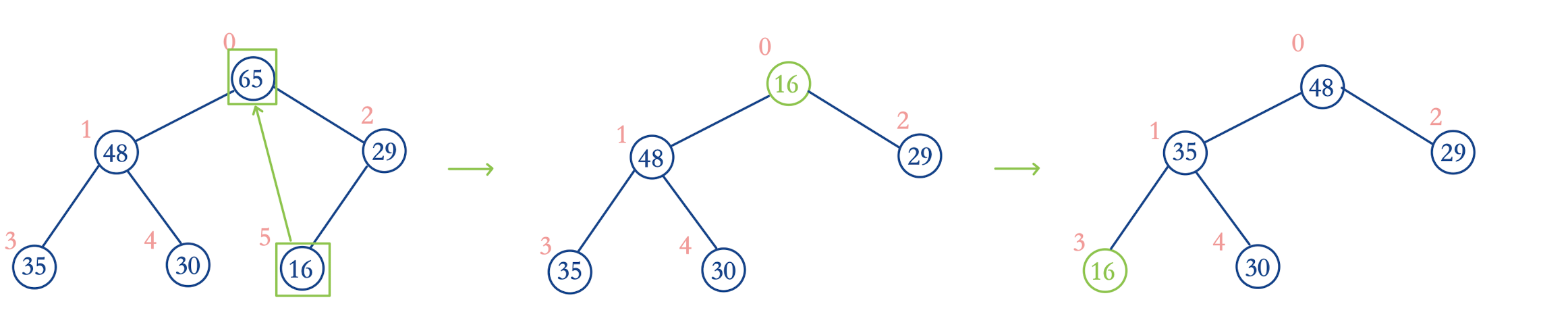
关于下沉的边界条件是:左子树的索引k小于结点个数size 这说明还存在左子树
下沉操作主要有两步:
- 找到左右子树的最大值交换
- 继续向下判断
代码实现:
public int extractMax(){ if(isEmpty()){ throw new NoSuchElementException("heap is empty! cannot extract!"); } //树根就是最大值 int max = elementData.get(0); //让最后一个元素覆盖掉根结点 elementData.set(0, elementData.get(size - 1)); //最后一个元素还没删除,因此这里要把它删掉 elementData.remove(size - 1); size--; //让当前的首元素下沉 siftDown(0); return max;}private void siftDown(int k){ while(leftChild(k) < size){ int j = leftChild(k); //判断是否存在右子树 if(j + 1 < size && elementData.get(j + 1) > elementData.get(j)){ //此时右子树存在且大于左子树 j++; } //j指向子结点中最大的那个 if(elementData.get(k) < elementData.get(j)){ swap(k, j); }else{ break; } k = j; }}如果我们尝试连续取出最大值,能得到一串递减的结果集
heapify - 堆化
如果现在有任意一个数组,我们可以将其看作是一个完全二叉树
如果我们通过一定的方法将其转换为最大堆,那么这个过程就称为堆化
堆化的一种方法就是遍历数组,依次调用我们在上面写过的add方法添加到最大堆中
这种方法的时间复杂度是O(nlogn) -> 遍历O(n),调用add的时间复杂度O(logn)
但是有一种原地heapfiy的方法,他的时间复杂度仅为O(n):
从最后一个非叶子结点开始进行元素siftDown操作,逐步向前,直到调整到根结点为止
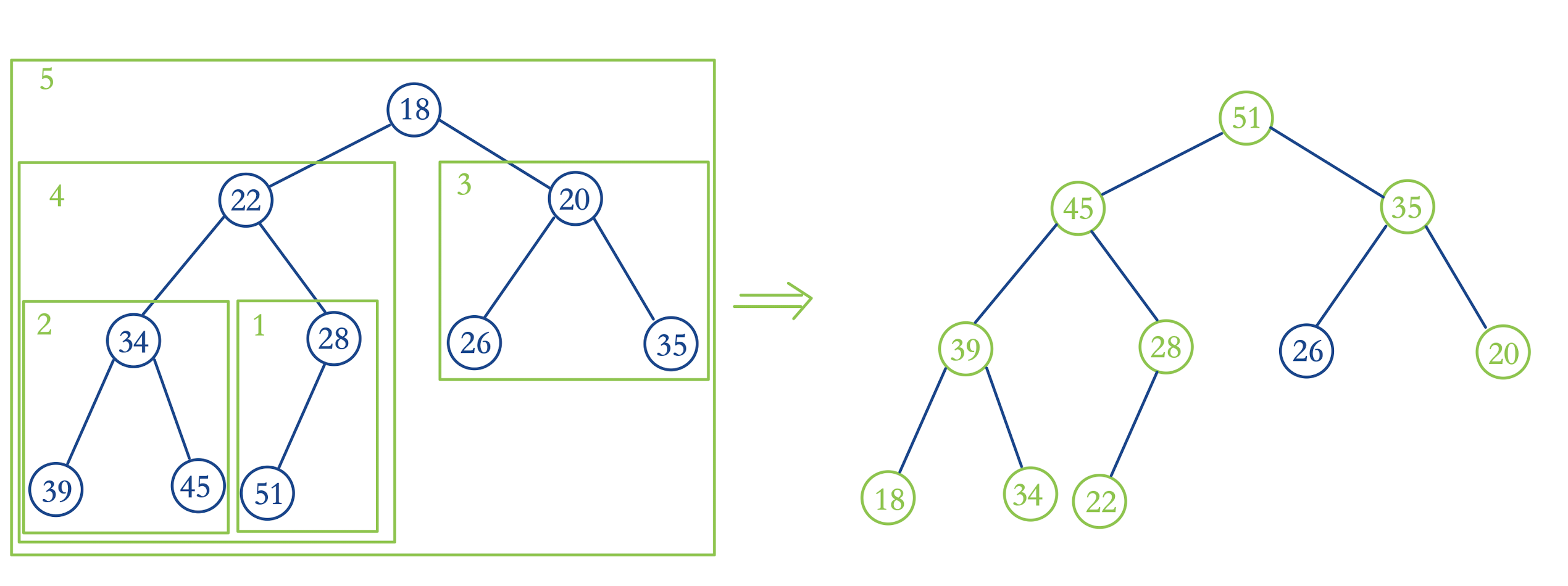
上图中,按照从1到5的顺序,对方框内的非叶子结点进行下沉操作,走完之后就是一个最大堆了
这种方法的核心在于:每对一个非叶子结点进行操作时,该结点的左右子树都已经满足最大堆的性质了,因此只需要将当前的非叶子结点下沉即可
代码实现:
//代码的实现,就是给构造方法传入一个整型数组public MaxHeap(int[] arr){ if(arr == null){ throw new NoSuchElementException("arr is empty! cannot MaxHeap!"); } //现将所有元素复制到优先级队列中 elementData = new ArrayList<>(); for(int i : arr){ elementData.add(i); size++; } //从最后一个非叶子结点开始执行下沉操作,逐步向前,直到根结点处理完 for (int i = parent(size - 1); i >= 0; i--) { siftDown(i); }}//测试public static void main(String[] args) { int[] arr = {18,22,20,34,28,26,35,39,45,51}; MaxHeap maxHeap = new MaxHeap(arr); System.out.println(maxHeap);// [51, 45, 35, 39, 28, 26, 20, 18, 34, 22]}测试结果同上图完全一致
优先级队列实现
自定义的Queue接口:
public interface Queue<E> { //入队 void offer(E e); //出队 E poll(); //查看当前队首元素 E peek(); boolean isEmpty();}优先级队列的实现:
public class PriorityQueue implements Queue<Integer> { private MaxHeap heap; public PriorityQueue(){ heap = new MaxHeap(); } @Override public void offer(Integer val) { heap.add(val); } @Override public Integer poll() { return heap.extractMax(); } @Override public Integer peek() { return heap.getMax(); } @Override public boolean isEmpty() { return heap.isEmpty(); }}对象之间的大小关系比较
Comparable接口
之前我们想让一个类具备比较大小的能力就需要用到Compareble接口,并覆写compareTo方法
若一个Student类实现了Compareble接口,这个Student就具备了可比较的能力,也就是说,可以直接对两个Student对象进行比较,比如student1.compareTo(student2)
compareTo的返回值:
- 如果返回值 > 0:当前对象大于传入对象
- 如果返回值 = 0:当前对象等于传入对象
- 如果返回值 < 0:当前对象小于传入对象
public class Student implements Comparable<Student>{ private int age; private String name; public int getAge() { return age; } //Arrays.sort()方法默认是升序排列的,如果我们想要降序,将compareTo的返回值反过来即可 @Override public int compareTo(Student o) { return this.age - o.age; }}Comparator接口
可以发现,如果不同的用户有不同的需求,这可能要求compareTo得根据顾客的需求而做修改
但是程序最好要按照“开闭原则”来设计,即开放扩展,关闭修改
基于这种原则,引入了一种新的接口java.util.Comparator接口 - 比较器接口
若一个类实现了该接口,表示这个类天生就是为别的类的大小关系服务的
class StudentAsc implements Comparator<Student>{ @Override public int compare(Student o1, Student o2) { return o1.getAge() - o2.getAge(); }}主方法:
public static void main(String[] args) { Student[] stu = new Student[] { new Student(28, "Jack"), new Student(18, "Harley"), new Student(30, "John") }; //此时的Student没有实现Comparable接口,因此进行排序的时候我们传入该类的比较器对象 //根据我们写的比较器,Student类的对象是根据年龄升序排列的 Arrays.sort(stu, new StudentAsc());//sort的重载方法,可传入实现Comparator接口的对象 System.out.println(Arrays.toString(stu));}我们创建StudentAsc这个类,就是为了给Student这个对象排序而存在的,这里的覆写的compare方法的返回值同compareTo一样
如果现在有用户想要根据年龄降序来设计,我们只需要再写一个按照年龄降序的类即可
class StudentDesc implements Comparator<Student>{ @Override public int compare(Student o1, Student o2) { return o2.getAge() - o1.getAge(); }}调用排序方法:Arrays.sort(stu, new StudentDesc());
这样得到的结果就是按照年龄降序排列的:
[Student{age=30, name='John'}, Student{age=28, name='Jack'}, Student{age=18, name='Harley'}]
当把Student类的大小关系比较从Student类中“解耦”(即让关系比较和Student类的定义脱离关系)
此时的比较策略就非常灵活,需要哪种方式,只需要创建一个新的类实现Comparator接口即可
然后根据大小关系比较的需要传入比较器对象
TopK问题
TopK问题是堆的实际应用,面试题特别爱考
面试题17.14.最小K个数
找出数组中最小的k个数,一般来说k远小于元素个数
方法一:
排序取出前k个元素即可,时间复杂度O(nlogn)
代码实现:
public int[] smallestK(int[] arr, int k) { Arrays.sort(arr); int[] ret = new int[k]; for(int i = 0; i < k; i++){ ret[i] = arr[i]; } return ret;}方法二:
如果要求时间复杂度优于O(nlogn)的算法,方法一是行不通的
TopK问题都可以使用优先级队列的解题思路:
- 若要取出前k个最大元素构造最小堆,即取大用小
- 若要取出前k个最小元素构造最大堆,即取小用大
思路图解:
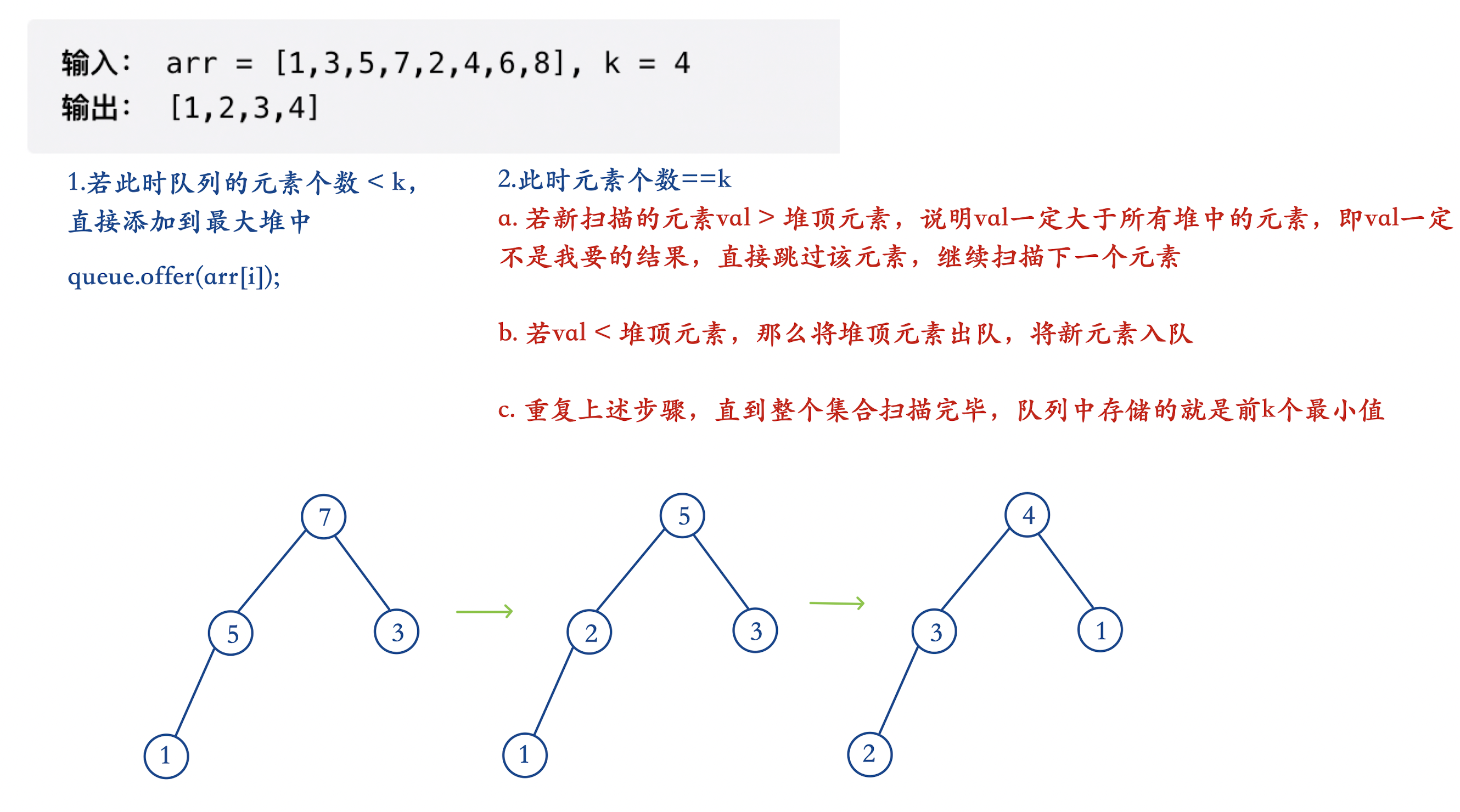
当然也可以先替换堆顶元素,然后让其下沉
这种方法的核心在于:
随着堆顶元素不断的交换,会把堆顶元素不断变小,最终队列扫描结束就存放了最小的k个数
该方法的时间复杂度是O(nlogk),O(n)是元素的遍历,O(logk)是堆的交换,如果k远小于n的话,O(nlogk)与O(nlogn)相比就有较为明显的差距,可以说O(nlogk)近乎于O(n)
代码实现:
class IntegerReverse implements Comparator<Integer> { @Override public int compare(Integer o1, Integer o2) { return o2 - o1; }}public class Num17_14_SmallestK { public int[] smallestK(int[] arr, int k) { int[] ret = new int[k]; if(arr == null || arr.length == 0 || k == 0){ return ret; } //由于JDK提供的是一个最小堆,因此需要改造成一个最大堆 Queue<Integer> queue = new PriorityQueue<>(new IntegerReverse()); //遍历原数组 for (int i = 0; i < arr.length; i++) { if(i < k){ queue.offer(arr[i]); }else{ if(arr[i] < queue.peek()){ queue.poll(); queue.offer(arr[i]); } } } int i = 0; while(!queue.isEmpty()){ ret[i] = queue.poll(); i++; } return ret; }}这里的写法是有待优化的,我们在主类外定义了一个比较器,实际上,这一步操作在主类中就能完成
这个方法同内部类有关,所谓的内部类,就是一个类嵌套到另一个类的内部的操作
这么我们只看匿名内部类:
Queue<Integer> queue = new PriorityQueue<>(new Comparator<Integer>() { @Override public int compare(Integer o1, Integer o2) { return o2 - o1; }});根据接口的定义来说,我们是不能将接口实例化为对象的,必须要有子类向上转型为接口实例化
但是这里的new Comparator 并不是实例化了一个接口对象,而是一种简化后的写法
相当于class NoName implements Comparator{} ,只不过我们把这个匿名类放在方法内定义
还有一种简化写法,称为函数式写法,他甚至可以简化为:
Queue queue = new PriorityQueue((o1, o2) -> o2 - o1); //Lambda表达式
原地堆排序
给定一个任意数组,只在这个数组上进行堆排序,不创建任何额外空间
- 任意数组其实就可以看作是一个完全二叉树,然后将这个数组调整为最大堆
即将一个任意数组进行heapify堆化 -> 从最后一个非叶子结点开始不断向前进行siftDown操作
- 不断交换堆顶元素和最后一个元素的位置,然后让新的堆顶元素继续做
siftDwon操作,直到数组只剩下一个未排序的元素位为止
这一步骤的核心在于,先将最大值放在最终位置(从队尾开始,逐个向前),每一次siftDwon又让下一个最大元素走到队首,然后循环上述过程,最终就得到了一排好序的数组
代码实现:
public static void heapSort(int[] arr){ //先把数组堆化,构建为一个最大堆 for (int i = (arr.length - 1 - 1) / 2; i >= 0; i--) { siftDown(arr, i, arr.length); } //此时数组已经构建为一个最大堆,我们不断将队首元素和末尾元素进行交换,然后让新队首元素不断下沉 for (int i = arr.length - 1; i > 0; i--) { swap(arr, 0, i);//交换队首元素放到最终位置 siftDown(arr, 0, i);//将新的队首元素下沉 } //走到这里堆排序就完成了}/** * * @param arr // 需要排序的数组 * @param i // 需要下沉的元素的下标 * @param length // 需要排序的数组的长度 */private static void siftDown(int[] arr, int i, int length) { while(2 * i + 1 < length){ int j = 2 * i + 1; if(j + 1 < length && arr[j + 1] > arr[j]){ //如果待下沉元素有右结点,且右结点大于左结点,则让j指向右结点 j++; } //走到这里j一定是左右子树中较大者 if(arr[i] < arr[j]){ //如果子树结点值大于根结点的就交换 swap(arr, i, j); i = j; }else{ //如果根结点已经大于子结点,说明该优先级队列仍然满足最大堆 //因此直接退出siftDown操作即可,否则死循环 break; } }}private static void swap(int[] arr, int i, int j) { int tmp = arr[i]; arr[i] = arr[j]; arr[j] = tmp;}