有哪些并发队列?及ConcurrentLinkedQueue 源码分析

有哪些并发队列?说下某一个的实现?
ConcurrentLinkedQueue : 无界非阻塞队列,底层使用单向链表实现,对于出队和入队使用CAS来实现线程安全
LinkedBlockingQueue: 有界阻塞队列,使用单向链表实现,通过ReentrantLock实现线程安全,阻塞通过Condition实现,出队和入队各一把锁,不存在互相竞争
ArrayBlockingQueue: 有界数组方式实现的阻塞队列 , 通过ReentrantLock实现线程安全,阻塞通过Condition实现,出队和入队使用同一把锁
PriorityBlockingQueue: 带优先级的无界阻塞队列,内部使用平衡二叉树堆实现,遍历保证有序需要自定排序
DelayQueue: 无界阻塞延迟队列,队列中的每个元素都有个过期时间,当从队列获取元素时,只有过期元素才会出队列,队列头元素是最快要过期的元素
SynchronousQueue: 任何一个写需要等待一个读的操作,读操作也必须等待一个写操作,相当于数据交换
链接: 图解SynchronousQueue原理-公平模式 - BattleHeart - 博客园
LinkedTransferQueue: 由链表组成的无界阻塞队列,多了tryTransfer 和 transfer方法。transfer方法,能够把生产者元素立刻传输给消费者,如果没有消费者在等待,那就会放入队列的tail节点,并阻塞等待元素被消费了返回,可以使用带超时的方法。tryTransfer方法,会在没有消费者等待接收元素的时候马上返回false
LinkedBlockingDeque: 由链表组成的双向阻塞队列,可以从队列的两端插入和移除元素
ConcurrentLinkedQueue 源码分析
源码基于Java8
无界非阻塞队列,底层使用单向链表实现,对于出队和入队使用CAS来实现线程安全。

看一下ConcurrentLinkedQueue的UML类图结构
AbstractQueue 实现了Queue接口的基本方法
Node 静态内部类,表示队列的节点
内部类
Node
队列节点对象,ConcurrentLinkedQueue的静态内部类
private static class Node<E> { //节点值 volatile E item; //指向下一个节点 volatile Node<E> next; /** * node构造函数,将item值写入内存,宽松写入,因为只有在casNext成功后才可见 */ Node(E item) { UNSAFE.putObject(this, itemOffset, item); } //cas更新item值 boolean casItem(E cmp, E val) { return UNSAFE.compareAndSwapObject(this, itemOffset, cmp, val); } //防重排序更新next值 void lazySetNext(Node<E> val) { UNSAFE.putOrderedObject(this, nextOffset, val); } //cas更新next值 boolean casNext(Node<E> cmp, Node<E> val) { return UNSAFE.compareAndSwapObject(this, nextOffset, cmp, val); } private static final sun.misc.Unsafe UNSAFE; //item属性的偏移量 private static final long itemOffset //next属性的偏移量 private static final long nextOffset; static { try { UNSAFE = sun.misc.Unsafe.getUnsafe(); Class<?> k = Node.class; itemOffset = UNSAFE.objectFieldOffset (k.getDeclaredField("item")); nextOffset = UNSAFE.objectFieldOffset (k.getDeclaredField("next")); } catch (Exception e) { throw new Error(e); } }}CLQSpliterator
可拆分迭代器
static final class CLQSpliterator<E> implements Spliterator<E> { static final int MAX_BATCH = 1 << 25; //最大批处理大小 final ConcurrentLinkedQueue<E> queue; Node<E> current; //当前节点,初始化之前都为null int batch; //分割批次的大小 boolean exhausted; //如果没有元素了,为true CLQSpliterator(ConcurrentLinkedQueue<E> queue) { this.queue = queue; } //分割队列,返回的是ArraySpliterator public Spliterator<E> trySplit() { Node<E> p; final ConcurrentLinkedQueue<E> q = this.queue; int b = batch; //n表示数组长度 //分割批次长度<=0,数组长度为1; //分割批次长度>=最大批处理大小,数组长度为最大批处理大小;否则为分割批次长度+1 int n = (b <= 0) ? 1 : (b >= MAX_BATCH) ? MAX_BATCH : b + 1; //!exhausted 为true表示队列还有元素 //((p = current) != null || (p = q.first()) != null) 如果前部分为true表示已经运行过一次,后部分为true表 //示是第一次运行,将队列的头节点赋值给p //p.next != null 表示队列后面还有元素,p表示的节点不是最后一个 if (!exhausted && ((p = current) != null || (p = q.first()) != null) && p.next != null) { //临时存储需分割的元素 Object[] a = new Object[n]; //已分割的元素计数,只计数item不为null的元素 //对于ConcurrentLinkedQueue来说,这里不会有item值为null的情况 int i = 0; do { //节点item值赋值临时数组 if ((a[i] = p.item) != null) //计数 ++i; //当next也指向本身p的时候为true,也就是自引用,重新找头节点 if (p == (p = p.next)) p = q.first(); } while (p != null && i < n); //直到取完需要的元素数量 //如果p等于null了就说明没有元素了 if ((current = p) == null) exhausted = true; //有不为null的元素 if (i > 0) { batch = i; //创建Spliterator,数组从0-i不包括i,指定了迭代器的特性 return Spliterators.spliterator (a, 0, i, Spliterator.ORDERED | Spliterator.NONNULL |Spliterator.CONCURRENT); } } return null; } //循环每个节点并执行指定函数 public void forEachRemaining(Consumer<? super E> action) { Node<E> p; if (action == null) throw new NullPointerException(); final ConcurrentLinkedQueue<E> q = this.queue; if (!exhausted && ((p = current) != null || (p = q.first()) != null)) { exhausted = true; do { E e = p.item; if (p == (p = p.next)) p = q.first(); if (e != null) action.accept(e); } while (p != null); //循环每个节点,直到没有节点 } } //获取一个有效的节点,执行指定函数 public boolean tryAdvance(Consumer<? super E> action) { Node<E> p; if (action == null) throw new NullPointerException(); final ConcurrentLinkedQueue<E> q = this.queue; if (!exhausted && ((p = current) != null || (p = q.first()) != null)) { E e; //通过循环的方式直到节点item值不为null //item值为null时通过p.next继续寻找 do { e = p.item; //同样如果p是自引用就重新寻找头节点 if (p == (p = p.next)) p = q.first(); } while (e == null && p != null); if ((current = p) == null) exhausted = true; if (e != null) { action.accept(e); return true; } } return false; } //返回估计的元素数量,因为ConcurrentLinkedQueue是无限队列,返回MAX_VALUE public long estimateSize() { return Long.MAX_VALUE; } //返回特征值 public int characteristics() { return Spliterator.ORDERED | Spliterator.NONNULL | Spliterator.CONCURRENT; }}Itr
迭代器,从头节点到尾节点进行迭代,迭代器是弱一致性的,只是某一时刻的快照,因为同时有可能其他线程还在对队列进行修改
private class Itr implements Iterator<E> { /** * 返回下个项目的节点 */ private Node<E> nextNode; /** * 保存下一个节点的item字段 */ private E nextItem; /** * 最近一个返回的项目节点,支持删除 */ private Node<E> lastRet; Itr() { advance(); } /** * 移动到下一个有效节点,通过next()返回item或者null */ private E advance() { lastRet = nextNode; E x = nextItem; Node<E> pred, p; //nextNode为null是说明是第一次运行 if (nextNode == null) { //获取头节点 p = first(); pred = null; } else { //将上次获取的节点保存为此次的上一个节点 pred = nextNode; //获取下一个节点 p = succ(nextNode); } for (;;) { //p == null 的情况,可能是哨兵节点时,p=first()返回null //也可能是 p=succ(nextNode)到最后一个节点时,返回null if (p == null) { nextNode = null; nextItem = null; return x; } E item = p.item; if (item != null) { nextNode = p; nextItem = item; return x; } else { // 如果item=null时,即节点已被其他线程删除,那么继续获取下一个节点 Node<E> next = succ(p); if (pred != null && next != null) //跳过null节点,将上一个节点的next指向新的节点 pred.casNext(p, next); //将p赋值新节点,继续循环 p = next; } } } //通过下个项目节点不为null来判断是否还有下一个 public boolean hasNext() { return nextNode != null; } //下一个项目 public E next() { if (nextNode == null) throw new NoSuchElementException(); return advance(); } public void remove() { Node<E> l = lastRet; if (l == null) throw new IllegalStateException(); //将最近一个项目节点设置为null,在下一次执行advance时,该节点将被重新连接 l.item = null; lastRet = null; }}属性
先看下ConcurrentLinkedQueue有哪些基本属性
/** * 头节点(未删除的),到达时间复杂度O(1) * 不变性: * - 所有有效节点能够从头节点通过succ()方法到达 * - head != null * - (tmp = head).next != tmp || tmp != head,就是头节点不会自引用 * 可变性: * - head.item 可能是null也可能不是null * - 允许tail滞后于head,也就是不能从头节点通过succ()到达 * */private transient volatile Node<E> head;/** * 尾节点,唯一一个node.next==null的节点,到达时间复杂度O(1) * 不变性: * - tail 节点通过succ()方法一定到达队列中的最后一个节点 * - tail != null * 可变性: * - tail.item 可能是null也可能不是null. * - 允许tail滞后于head,也就是不能从头节点通过succ()到达 * - tail.next 可以指向自己,也可以不指向自己 * */private transient volatile Node<E> tail;Unsafe相关
private static final sun.misc.Unsafe UNSAFE;//头节点相对于对象的偏移量private static final long headOffset;//尾节点相对于对象的偏移量private static final long tailOffset;static { try { UNSAFE = sun.misc.Unsafe.getUnsafe(); Class<?> k = ConcurrentLinkedQueue.class; //使用Unsafe获取head属性相对于ConcurrentLinkedQueue对象的偏移量,可以使用该偏移量获取head属性的值 headOffset = UNSAFE.objectFieldOffset (k.getDeclaredField("head")); tailOffset = UNSAFE.objectFieldOffset (k.getDeclaredField("tail")); } catch (Exception e) { throw new Error(e); }}构造函数
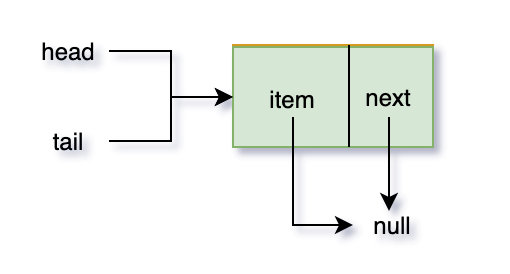
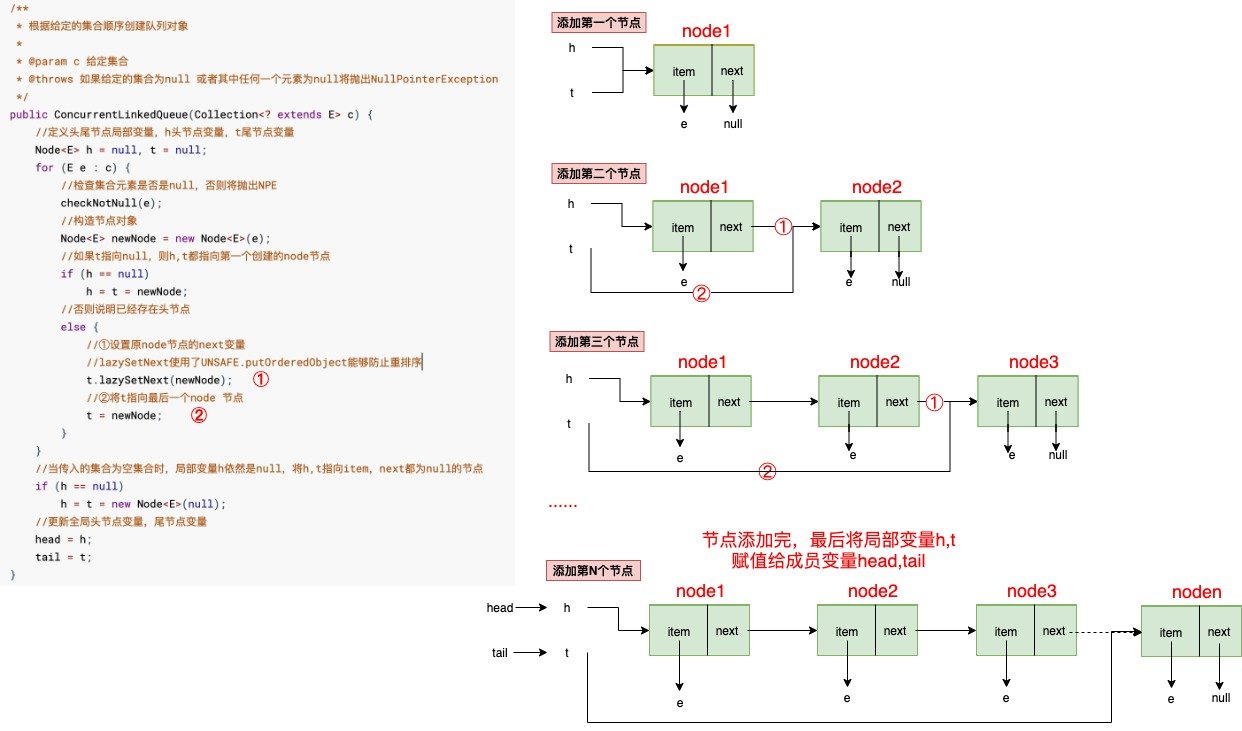
/** * 创建一个item,next都为null的Node节点 * head tail都指向该节点 */public ConcurrentLinkedQueue() { head = tail = new Node<E>(null);}/** * 根据给定的集合顺序创建队列对象 * * @param c 给定集合 * @throws 如果给定的集合为null 或者其中任何一个元素为null将抛出NullPointerException */public ConcurrentLinkedQueue(Collection<? extends E> c) { //定义头尾节点局部变量,h头节点变量,t尾节点变量 Node<E> h = null, t = null; for (E e : c) { //检查集合元素是否是null,否则将抛出NPE checkNotNull(e); //构造节点对象 Node<E> newNode = new Node<E>(e); //如果t指向null,则h,t都指向第一个创建的node节点 if (h == null) h = t = newNode; //否则说明已经存在头节点 else { //①设置原node节点的next变量 //lazySetNext使用了UNSAFE.putOrderedObject能够防止重排序 t.lazySetNext(newNode); //②将t指向最后一个node 节点 t = newNode; } } //当传入的集合为空集合时,局部变量h依然是null,将h,t指向item,next都为null的节点 if (h == null) h = t = new Node<E>(null); //更新全局头节点变量,尾节点变量 head = h; tail = t;}无参构造函数创建对象后的节点图
根据给定的集合顺序创建队列对象,给定集合不是空集合
add
在尾部插入元素,实际调用offer()
offer
在尾部插入元素
public boolean offer(E e) { //检查插入值不能为null checkNotNull(e); //构造node对象 final Node<E> newNode = new Node<E>(e); for (Node<E> t = tail, p = t;;) { Node<E> q = p.next; //q->p.next,也就是说p已经是最后一个节点,p.next指向null if (q == null) { //cas设置,如果cas失败,说明有其他线程竞争,等待下次循环再次尝试cas设置 if (p.casNext(null, newNode)) { //设置成功 //尾节点与当前节点相隔两个,设置尾节点tail指向最后一个节点,即newNode if (p != t)//允许失败,下次会继续处理 casTail(t, newNode); return true; } } //❓这里我在debug时有个奇怪问题 //测试用例只有简单的add()方法,有时候能够进入该代码内,有时候执行的else部分代码 //这个问题,见https://my.oschina.net/u/4311881/blog/3264783/print else if (p == q) //这种情况会发生在节点已经被删除的时候,即p.next -> p 本身 //如果tail没有发生变化,需要跳转到头节点head,从head节点能够到达任何存活节点 //否则说明tail已经重新指向,用新的tail p = (t != (t = tail)) ? t : head; else //(p != t) 说明执行过 p = q 操作(向后遍历操作) //(t != (t = tail))) 说明尾节点在其他的线程发生变化 //添加2次检查一次 p = (p != t && t != (t = tail)) ? t : q; }}remove
add、remove发生的bug
public static void main(String[] args) { ConcurrentLinkedQueue<Object> queue = new ConcurrentLinkedQueue<Object>(); queue.add(new Object()); Object object = new Object(); int loops = 0; Runtime rt = Runtime.getRuntime(); long last = System.currentTimeMillis(); while (true) { if (loops % 10000 == 0) { long now = System.currentTimeMillis(); long duration = now - last; last = now; System.out.printf("duration=%d q.size=%d memory max=%d free=%d total=%d%n", duration,queue.size(),rt.maxMemory(),rt.freeMemory(),rt.totalMemory()); } queue.add(object); queue.remove(object); ++loops; }}多次add,remove操作后,会有很多已经删除的null节点,本应该GC回收,但因为互相连接无法回收,导致长时间运行后内存泄漏。
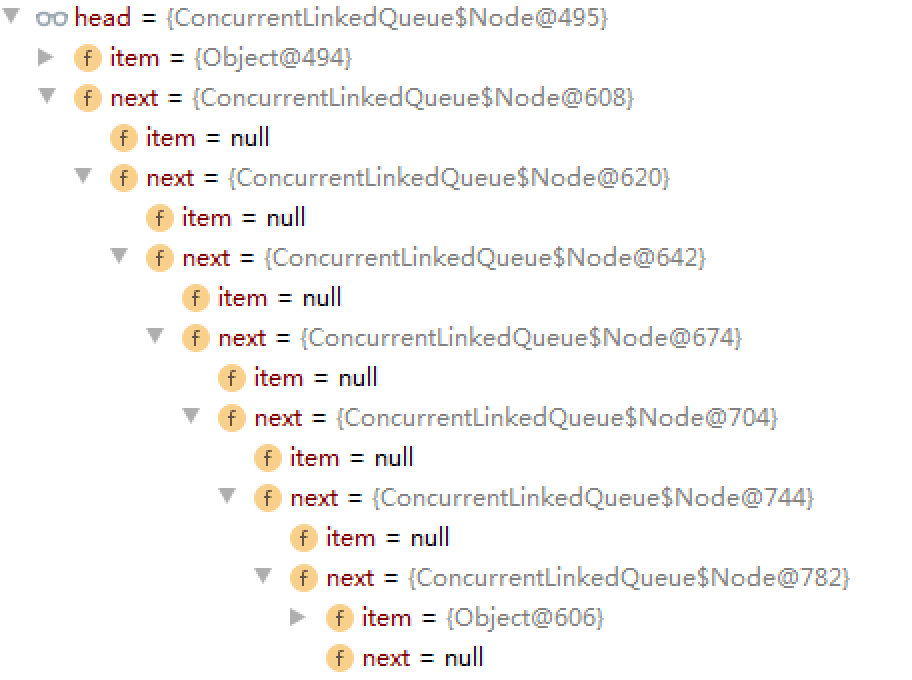
这种情况是jdk的一个bug,可见文章:https://mp.weixin.qq.com/s/ppZlpL5Ip7DHG1GG09uT6g
看看remove代码
public boolean remove(Object o) { //删除元素为null直接返回false if (o != null) { //pred上一个节点,next下一个节点 Node<E> next, pred = null; for (Node<E> p = first(); p != null; pred = p, p = next) { boolean removed = false; E item = p.item; //元素item值不为null,item=null都是被删除的节点 if (item != null) { //当前节点的item与希望删除值不相同,继续下一个节点 //通过equals判断值是否相同 if (!o.equals(item)) { //获取下一个节点 next = succ(p); //下一次循环 continue; } //相同将item置为null,cas设置成功返回true removed = p.casItem(item, null); } //如果item=null,获取下一个节点,用于下次循环 //如果节点casItem成功,判断下了节点是否有节点 next = succ(p); //当上一个节点,和下一个节点都存在时 //将上一个节点的next跳过当前节点,关联到下一个节点 //这就是产生上述bug的地方 if (pred != null && next != null) // unlink pred.casNext(p, next); if (removed) return true; } } return false;}poll
弹出头节点,会删除头节点,返回节点item值
public E poll() { restartFromHead: //这层循环能够起到在continue restartFromHead后,重新初始化第二个for for (;;) { for (Node<E> h = head, p = h, q;;) { E item = p.item; //头节点item不为null,那么设置头节点的item为null if (item != null && p.casItem(item, null)) { //cas设置成功后,由于h指向初始的head,p为当前节点,需要更新头节点head if (p != h)//(q = p.next) != null 为false时,即p为尾节点,那么head还是指向当前节点p //否则将head节点更新为p.next updateHead(h, ((q = p.next) != null) ? q : p); //返回 return item; } //(q = p.next) == null 为true,p.item=null //空队列,有可能当前节点要被删除(多线程下),或者是一个哨兵节点 else if ((q = p.next) == null) { //更新头节点 updateHead(h, p); return null; } //自引用节点,说明当前节点已被删除,跳到开头重新开始 else if (p == q) continue restartFromHead; else // q -> p进行下个节点判断 p = q; } }}peek
获取头节点元素,不删除元素,与poll()类似
public E peek() { restartFromHead: for (;;) { for (Node<E> h = head, p = h, q;;) { E item = p.item; //(q = p.next) == null 为true 说明是空队列 if (item != null || (q = p.next) == null) { updateHead(h, p); return item; } else if (p == q) continue restartFromHead; else p = q; } }}isEmpty
判断队列是否为空,通过头节点是否为null判断
public boolean isEmpty() { return first() == null;}size
返回队列中有效元素(item != null)长度
public int size() { int count = 0; //从头节点开始循环 for (Node<E> p = first(); p != null; p = succ(p)) if (p.item != null) // 如果超过最大值,提前结束 if (++count == Integer.MAX_VALUE) break; return count;}contains
判断队列中是否包含指定值的节点
public boolean contains(Object o) { //由于队列中不包含null的节点(哨兵节点不算),直接返回false if (o == null) return false; for (Node<E> p = first(); p != null; p = succ(p)) { E item = p.item; //通过equals判断 if (item != null && o.equals(item)) return true; } return false;}addAll
将给定集合添加到队列中,返回是否成功
public boolean addAll(Collection<? extends E> c) { if (c == this) //不能自己添加自己 throw new IllegalArgumentException(); //循环设置队列 Node<E> beginningOfTheEnd = null, last = null; for (E e : c) { checkNotNull(e); Node<E> newNode = new Node<E>(e); //beginningOfTheEnd = null 表示第一次循环,将beginningOfTheEnd,last都指向第一个节点 if (beginningOfTheEnd == null) beginningOfTheEnd = last = newNode; else { //beginningOfTheEnd != null 设置后续节点 last.lazySetNext(newNode); last = newNode; } } //为ture说明c是一个空集合 if (beginningOfTheEnd == null) return false; //更新head,和tail变量 for (Node<E> t = tail, p = t;;) { //一直获取下一个节点 Node<E> q = p.next; //直到最后一个 if (q == null) { //beginningOfTheEnd已经在前面设置完成,形成了链表 这里通过cas将新链表链接到原来链表的最后一个节点 if (p.casNext(null, beginningOfTheEnd)) { // 更新tail指向链表最后一个节点 if (!casTail(t, last)) { // 如果失败了,说明有竞争,再次尝试 t = tail; if (last.next == null) casTail(t, last); } return true; } } else if (p == q) //在多线程的情况下会发生节点被删除的情况,需要重新赋值头部,并重新寻找最后的节点 p = (t != (t = tail)) ? t : head; else //检查tail节点 p = (p != t && t != (t = tail)) ? t : q; }}toArray
//将队列元素循环赋值给ArrayList,再输出数组//由于返回新数组,所以对数组的修改不会影响原队列,但如果元素是对象,对对象的修改,会影响到原队列中的元素public Object[] toArray() { ArrayList<E> al = new ArrayList<E>(); for (Node<E> p = first(); p != null; p = succ(p)) { E item = p.item; if (item != null) al.add(item); } return al.toArray();}例子:
@Testpublic void test1 { concurrentLinkedQueue2.add(new Person()); concurrentLinkedQueue2.add(new Person()); concurrentLinkedQueue2.add(new Person()); //对数组中的对象进行修改 Object[] objects = concurrentLinkedQueue2.toArray(); Person person = (Person) objects[0]; Person person1 = concurrentLinkedQueue2.peek(); assert person == person1;}//将队列元素输出到指定的数组中public <T> T[] toArray(T[] a) { //将元素输出到指定数组中 int k = 0; Node<E> p; for (p = first(); p != null && k < a.length; p = succ(p)) { E item = p.item; if (item != null) a[k++] = (T)item; } //p == null 为true 表示队列后面没有节点了 //为false 表示后面还有节点,将采用ArrayList方法输出数组 //所以始终会将队列中的所有有效元素输出 if (p == null) { //k < a.length为true 表明给定数组长度比较大 if (k < a.length) //为什么要设值一下呢? a[k] = null; return a; } //使用ArrayList输出 ArrayList<E> al = new ArrayList<E>(); for (Node<E> q = first(); q != null; q = succ(q)) { E item = q.item; if (item != null) al.add(item); } return al.toArray(a);}iterator、spliterator
//创建迭代器public Iterator<E> iterator() { return new Itr();}//创建可拆分迭代器public Spliterator<E> spliterator() { return new CLQSpliterator<E>(this);}updateHead
更新头节点head,主要作用就是将h节点变为自引用,并更新head头节点,变为自引用的节点将被GC回收
//更新头节点headfinal void updateHead(Node<E> h, Node<E> p) { if (h != p && casHead(h, p)) //将h节点变为自引用 h.lazySetNext(h);}succ
//获取下一个节点final Node<E> succ(Node<E> p) { Node<E> next = p.next; //p == next 表示p是自引用节点,需要从head头开始,返回头节点 return (p == next) ? head : next;}first
//获取队列的第一个元素Node<E> first() { restartFromHead: for (;;) { for (Node<E> h = head, p = h, q;;) { boolean hasItem = (p.item != null); //hasItem 为true,就返回 //为false 执行 q=p.next 获取下个节点,当下个节点也不存在时,说明该节点p已经被删除 //此时就相当于初始化时候的哨兵节点item = null, next = null if (hasItem || (q = p.next) == null) { //更新头 updateHead(h, p); return hasItem ? p : null; } else if (p == q) continue restartFromHead; else p = q; } }}writeObject、readObject
//将队列写入输出流中private void writeObject(java.io.ObjectOutputStream s) throws java.io.IOException { // Write out any hidden stuff s.defaultWriteObject(); // Write out all elements in the proper order. for (Node<E> p = first(); p != null; p = succ(p)) { Object item = p.item; if (item != null) s.writeObject(item); } // Use trailing null as sentinel s.writeObject(null);}//从输入流中读取并转换为队列private void readObject(java.io.ObjectInputStream s) throws java.io.IOException, ClassNotFoundException { s.defaultReadObject(); // Read in elements until trailing null sentinel found Node<E> h = null, t = null; Object item; while ((item = s.readObject()) != null) { @SuppressWarnings("unchecked") Node<E> newNode = new Node<E>((E) item); if (h == null) h = t = newNode; else { t.lazySetNext(newNode); t = newNode; } } if (h == null) h = t = new Node<E>(null); head = h; tail = t; }参考文章:
https://www.jianshu.com/p/08e8b0c424c0
