搜狗微信爬虫案例
案例地址:https://weixin.sogou.com/weixin?
搜狗微信目前还是可以检索文章,具有一定的采集价值。
接口分析
先分析接口,普通的GET请求。
经过测试,发现主要对cookies中的两个参数进行校验,SNUID 和 SUV 。
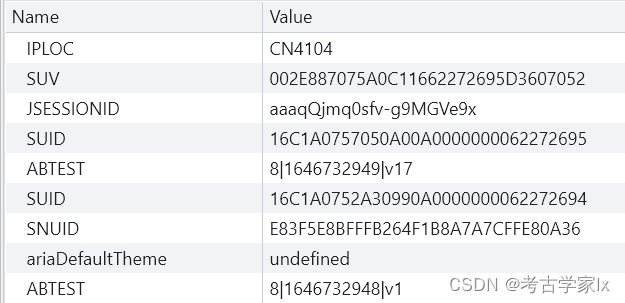
SNUID 和 SUV 都是由服务端返回,在初次访问时即可获取。
一般情况下,频繁访问后会出现图文验证码,当完成验证之后,会返回一个新的ID,该ID即是SNUID。
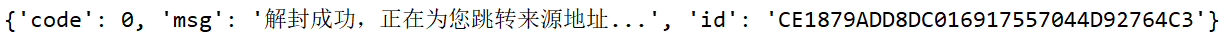
而服务端对 SUV 的来源并没有过多校验,只要是真实的参数即可。
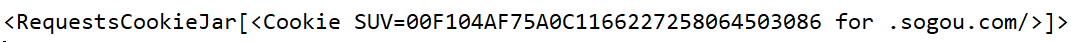
当大家可以生成 SNUID 和 SUV 时,就能畅通无阻的进行采集。
参数生成
SUV 相对简单,请求某些接口即可获取。
SUV = dict_from_cookiejar(requests.get('https://pb.sogou.com/cl.gif?').cookies)['SUV']SNUID 需要完成验证码校验。
验证码页面地址:https://www.sogou.com/antispider/?
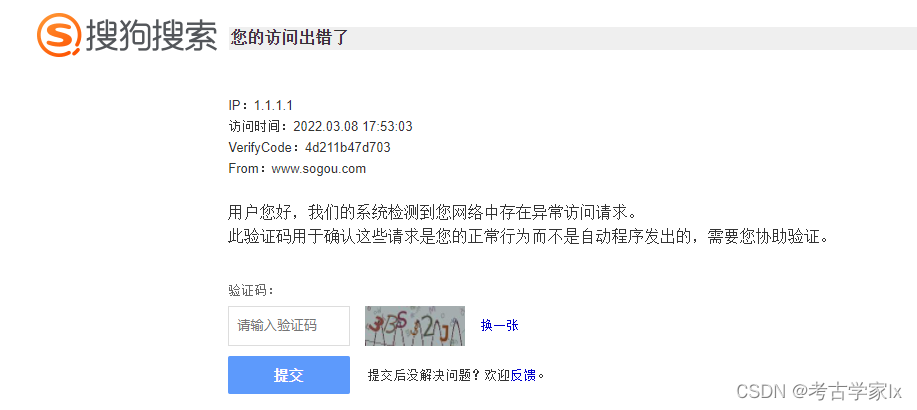
验证接口:
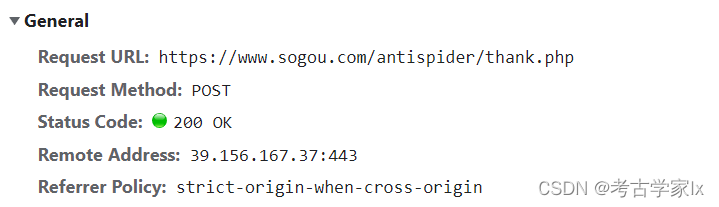
关于本部分的具体实施,是先请求该页面,提取出验证码图片,在本地识别后通过验证接口提交,进行校验。
校验成功返回:{‘code’: 0, ‘msg’: ‘解封成功,正在为您跳转来源地址…’, ‘id’: ‘0ED9B76D171DC1A6E862079C1877D6B8’}
验证失败返回: {‘code’: 3, ‘msg’: ‘验证码输入错误, 请重新输入!’}
校验成功返回的id即是SNUID。
本部分代码过多,就不贴了。
链接转换
需要注意的是列表页中的链接并不是跳转后的链接,需要我们进行特殊处理。
我们请求列表页后,会返回一段script代码,可以发现该代码进行window.location的跳转工作。
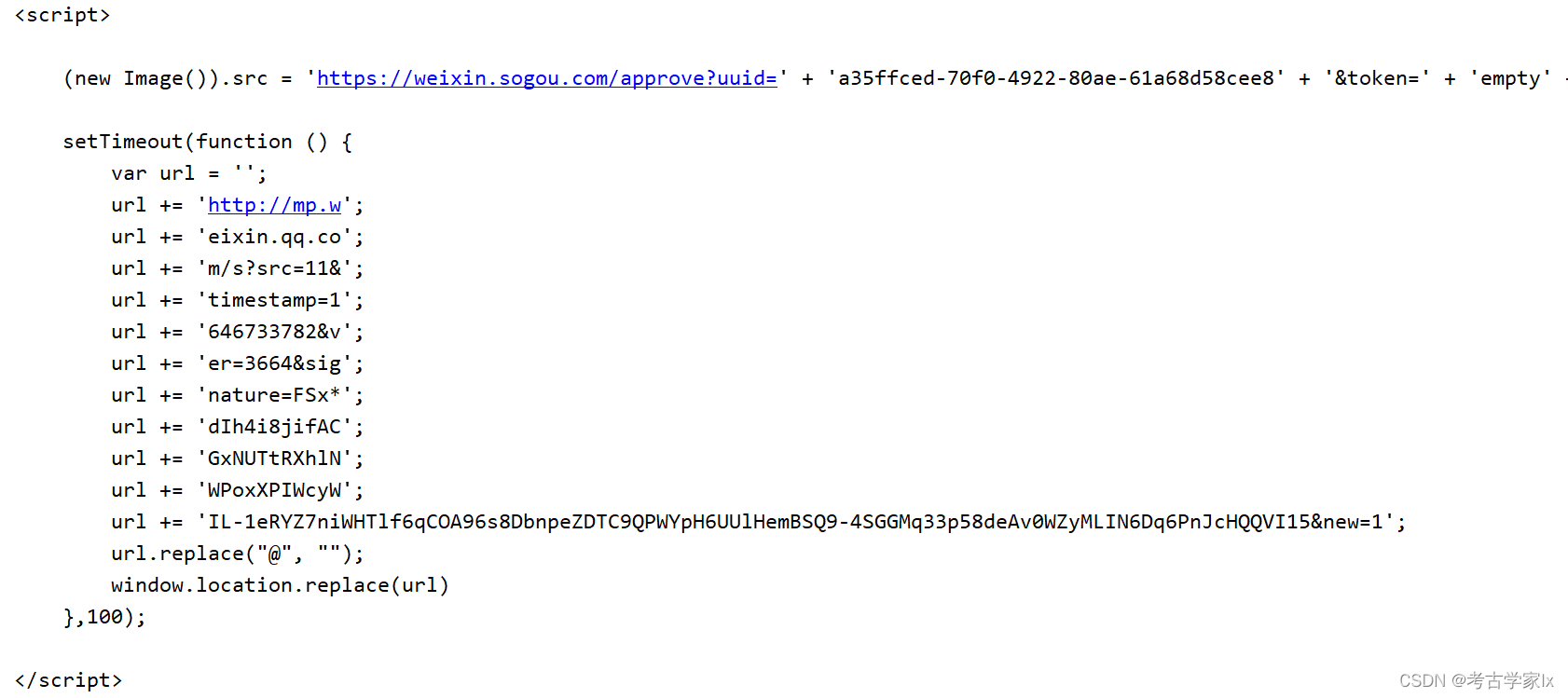
那么把这段代码提取出来,通过execjs在本地执行,即可返回新的URL地址。
import execjs,rehtml = ''js='function s() {'+''.join(re.findall('\{.*?url.replace\("@", ""\);',html,re.S))+'return url}}'new_url = execjs.compile(js).call('s')print(new_url)拿到weixin的链接后,即可进行采集。
备注
本案例难度并不高,需要大家仔细分析接口。
最终可以让采集程序在异常时获取新的cookies,达到一直运行的效果。
欢迎关注 《Pythonlx》 公众号,可获取群聊二维码!
原文地址:https://blog.csdn.net/weixin_43582101/article/details/123359110