Scrapy源码学习-Middleware
使用scrapy框架开发一款爬虫,或多或少都会用到中间件。常见的中间件有UserAgent中间件、代理中间件等等。其主要作用就是在爬虫请求的过程中,通过自定义内置的一些方法,来改变如请求的结构,从而伪装请求客户端。
比如,在UserAgent中间件中,通过编写process_request方法,将请求中的headers添加自定义ua,或者随机ua来实现动态UserAgent。
class UserAgentMiddleware: def process_request(self, request, spider): request.headers.setdefault('User-Agent', random_ua())当然,仅仅编写自定义中间件是不够的。还需要在配置文件中,开启该中间件。
DOWNLOADER_MIDDLEWARES = { ……, 'SpiderPorject.middlewares.UserAgentMiddleware': 1}通过两步走:1.编写中间件;2.开启中间件。即可实现简单的中间件开发。框架开发者已经足够精简业务编写的流程。接下来抱着学习的态度,看看到底是如何实现的。
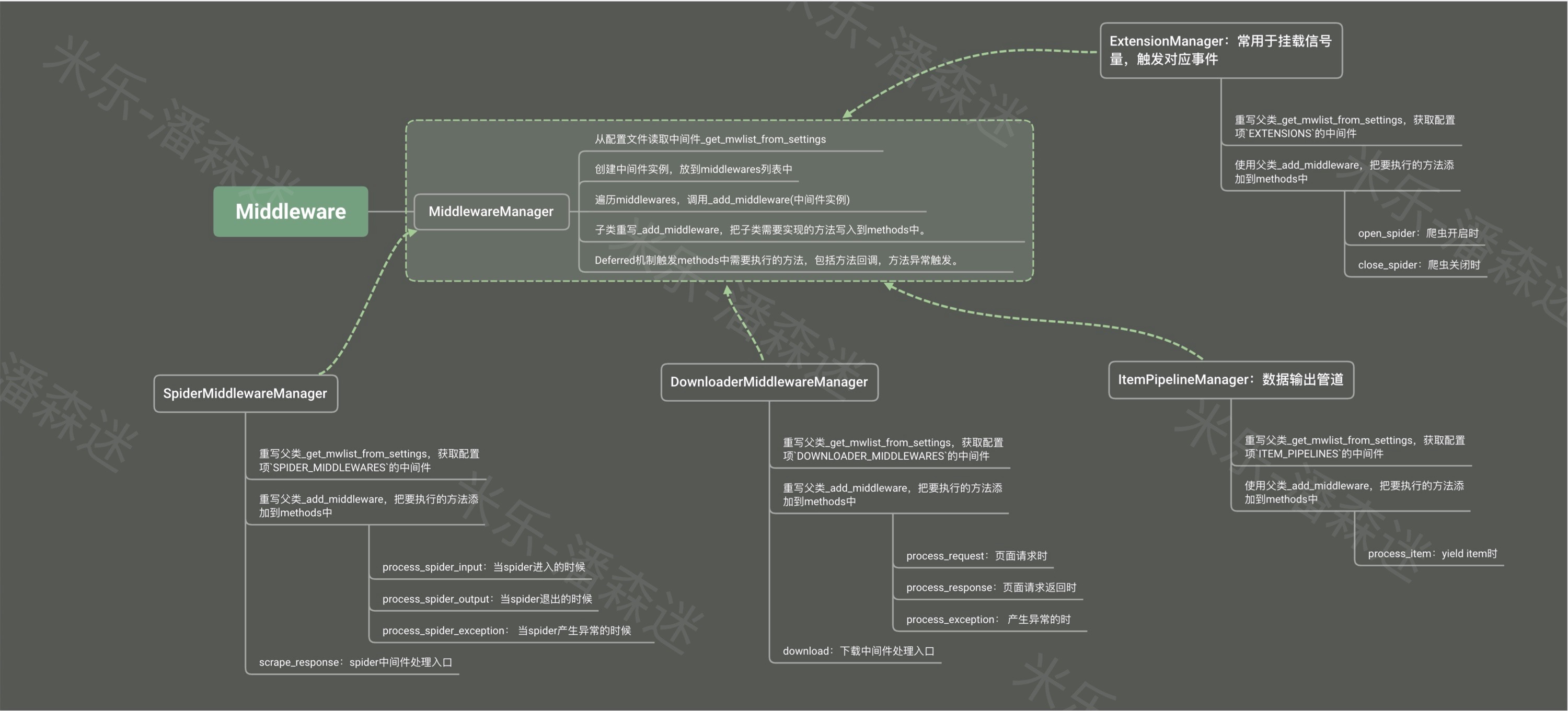
MiddlewareManager
MiddlewareManager是所有中间件的基类,所有中间件指的是:
- DownloaderMiddlewareManager:下载中间件
- SpiderMiddlewareManager:爬虫中间件
- ExtensionManager:扩展中间件
- ItemPipelineManager:数据管道中间件
我们先从最初的父类_MiddlewareManager_来看。
该类有一个静态方法from_settings来初始化这个类,在里面主要做一件事,就是获取配置文件中的中间件path。何为中间件path?看看上面,我们是如何启用UserAgent中间件的。在DOWNLOADER_MIDDLEWARES中SpiderPorject.middlewares.UserAgentMiddleware就是这个中间件的路径。通过方法load_object把路径映射成类,并通过create_instance实例化该类,存入数组middlewares中。最后把middlewares交给_MiddlewareManager_。然后类在初始化的时候遍历middlewares调用方法_add_middleware。
class MiddlewareManager: def __init__(self, *middlewares): self.middlewares = middlewares self.methods = defaultdict(deque) for mw in middlewares: self._add_middleware(mw) @classmethod def from_settings(cls, settings, crawler=None): mwlist = cls._get_mwlist_from_settings(settings) middlewares = [] enabled = [] for clspath in mwlist: try: mwcls = load_object(clspath) mw = create_instance(mwcls, settings, crawler) middlewares.append(mw) enabled.append(clspath) except NotConfigured as e: …… return cls(*middlewares)_add_middleware在父类默认做了哪些事?它就是在中间件类中把open_spider和close_spider(如有)放到methods里。
def _add_middleware(self, mw): if hasattr(mw, 'open_spider'): self.methods['open_spider'].append(mw.open_spider) if hasattr(mw, 'close_spider'): self.methods['close_spider'].appendleft(mw.close_spider)其他的中间件只需要基于父类,通过重写部分方法,即可达到其目的。
DownloaderMiddlewareManager
有了上面的经验,再看_DownloaderMiddlewareManager_就比较清晰了。它主要就是重写了父类的_get_mwlist_from_settings(从配置项中获取中间件路径),由于它是下载中间件,所以它只需要拿到DOWNLOADER_MIDDLEWARES中配置的中间件路径。
继续重写父类的_add_middleware,拿到自定义中间件中process_request、process_response、process_exception(如有)加入到methods中。通过download方法的Deferred机制触发methods中需要执行的方法,包括方法回调,方法异常触发。
def download(self, download_func, request, spider): @defer.inlineCallbacks def process_request(request): …… return (yield download_func(request=request, spider=spider)) @defer.inlineCallbacks def process_response(response): …… return response @defer.inlineCallbacks def process_exception(failure): …… return failure deferred = mustbe_deferred(process_request, request) deferred.addErrback(process_exception) deferred.addCallback(process_response) return deferred那download又是通过谁来执行的呢?熟悉的朋友都知道scrapy的一大组件叫下载器Downloader,在默认配置文件default_settings文件中:
DOWNLOADER = 'scrapy.core.downloader.Downloader'走进这个执行文件中观察,这个_Downloader_类在初始化时候同样声明了DownloaderMiddlewareManager,并有一个叫fetch的方法,调用了middleware.download()
class Downloader: def __init__(self, crawler): …… self.middleware = DownloaderMiddlewareManager.from_crawler(crawler) def fetch(self, request, spider): def _deactivate(response): # 释放请求 self.active.remove(request) return response # 这里是为了记录同时并发请求数量的 self.active.add(request) dfd = self.middleware.download(self._enqueue_request, request, spider) return dfd.addBoth(_deactivate)SpiderMiddlewareManager
再看SpiderMiddlewareManager就更容易了,_get_mwlist_from_settings从配置项中拿到属性为SPIDER_MIDDLEWARES的中间件路径。_add_middleware提取自定义Spider中间件中的process_spider_input、process_start_requests、process_spider_output、process_spider_exception(如有)加入methods中。外部引擎(ExecutionEngine)通过调用scrape_response来执行工作流。
class SpiderMiddlewareManager(MiddlewareManager): component_name = 'spider middleware' @classmethod def _get_mwlist_from_settings(cls, settings): return build_component_list(settings.getwithbase('SPIDER_MIDDLEWARES')) def _add_middleware(self, mw): super()._add_middleware(mw) if hasattr(mw, 'process_spider_input'): self.methods['process_spider_input'].append(mw.process_spider_input) if hasattr(mw, 'process_start_requests'): self.methods['process_start_requests'].appendleft(mw.process_start_requests) process_spider_output = getattr(mw, 'process_spider_output', None) self.methods['process_spider_output'].appendleft(process_spider_output) process_spider_exception = getattr(mw, 'process_spider_exception', None) self.methods['process_spider_exception'].appendleft(process_spider_exception) def scrape_response(self, scrape_func, response, request, spider): def process_spider_input(response): …… return scrape_func(response, request, spider) def process_spider_exception(_failure, start_index=0): …… return _failure def process_spider_output(result, start_index=0): …… return MutableChain(result, recovered) def process_callback_output(result): …… return MutableChain(process_spider_output(result), recovered) dfd = mustbe_deferred(process_spider_input, response) dfd.addCallbacks(callback=process_callback_output, errback=process_spider_exception) return dfdExtensionManager
扩展,它其实也是个中间件。扩展的应用场景一般都是在爬虫启动和关闭的时候绑定信号量,触发对应的事件。
它的类实现及其简单:
class ExtensionManager(MiddlewareManager): @classmethod def _get_mwlist_from_settings(cls, settings): return build_component_list(settings.getwithbase('EXTENSIONS'))仅仅就是重写扩展中间件获取方式。
尽管这样,他一样拥有了父类自带的open_spider和close_spider。比如你可以在自定义扩展中,使用open_spider来open一个资源,在close_spider的时候销毁。
ItemPipelineManager
数据管道,它其实也是个中间件!它在重写_add_middleware的时候先运行了父类的_add_middleware(也就是增加了open_spider和close_spider方法),再增加了process_item方法。
class ItemPipelineManager(MiddlewareManager): @classmethod def _get_mwlist_from_settings(cls, settings): return build_component_list(settings.getwithbase('ITEM_PIPELINES')) def _add_middleware(self, pipe): super(ItemPipelineManager, self)._add_middleware(pipe) if hasattr(pipe, 'process_item'): self.methods['process_item'].append(deferred_f_from_coro_f(pipe.process_item))所以,往往我们在自己定义ItemPipeline的时候,必须实现方法process_item来拿到我们抓取的数据。
总结