第15篇:Elasticsearch——增删改查
背景:目前国内有大量的公司都在使用 Elasticsearch,包括阿里、京东、滴滴、今日头条、小米、vivo等诸多知名公司。除了搜索功能之外,Elasticsearch还结合Kibana、Logstash、Elastic Stack还被广泛运用在大数据近实时分析领域,包括日志分析、指标监控等多个领域。
本节内容:Elasticsearch基础能力-增删改查。
Elastcisearch 是分布式的文档存储。它能以近实时的方式存储和检索序列化为JSON的文档数据结构。 一旦某个文档被存储在Elasticsearch中,它就是可以被集群中的任意节点检索到。
除了要存储数据外,还需要成批且快速地查询。在Elasticsearch中, 每个字段的所有数据都是默认被索引的 。 每个字段都有为了快速检索而设置的专用倒排索引。而且,它能在同一个查询中使用所有这些倒排索引,并以极快的速度返回结果。
在本节内容中,我们展示了用来创建,检索,更新和删除文档的 API。了解 Elasticsearch 是如何安全存储文档,以及如何将文档再次返回。
说明:一下内容使用Elasticsearch版本为>= 7.x。建议大家也尽量使用7.x以上版本,这个版本也是目前在很多公司中被应用到生产环境当中去。
1、索引文档
通过使用 index API ,文档可以被存储和索引。 首先,我们要确定文档的位置。正如我们刚刚讨论的,一个文档的 _index 、 _type 和 _id 唯一标识一个文档。 我们可以提供自定义的 _id 值,或者让 index API 自动生成。
如果你需要自定义一个id,可以使用如下方式设置 _id :
创建索引模板:
PUT /{index}/{type}/{id}{ "field": "value", ...}说明:在7.x之后,type默认为_doc
例如,我们的索引称为student ,类型默认称为_doc ,并且选择 100 作为 ID ,那么索引请求应该是下面这样:
请求示例URL, 创建文档需要使用PUT操作命令。
http://localhost:9203/student/_doc/100/请求示例参数,
{ "name": "xiaoli", "age": 18, "love": "I like swimming.", "createTime":"2022-05-04 20:00:00"}响应示例返回,
{ "_index": "student", "_type": "_doc", "_id": "100", "_version": 1, "result": "created", "_shards": { "total": 2, "successful": 2, "failed": 0 }, "_seq_no": 20, "_primary_term": 1}该响应表明文档已经成功创建,该索引包括 _index 、 _type 和 _id 元数据, 以及一个新元素: _version 。
在 Elasticsearch 中每个文档都有一个版本号。当每次对文档进行修改时(包括删除), _version 的值会递增。 在 处理冲突 中,我们讨论了怎样使用 _version 号码确保你的应用程序中的一部分修改不会覆盖另一部分所做的修改。
说明:如果你的数据没有填写id, Elasticsearch会自动生成id的值。自动生成规则如下,
自动生成的 ID 是 URL-safe、 基于 Base64 编码且长度为20个字符的 GUID 字符串。 这些 GUID 字符串由可修改的 FlakeID 模式生成,这种模式允许多个节点并行生成唯一 ID ,且互相之间的冲突概率几乎为零。
2、查询单个文档全部字段
为了从 Elasticsearch 中检索出文档,我们仍然使用相同的 _index , _type , 和 _id ,此时需要将谓词更改为GET请求。
查询模板如下,
GET /index/_doc/id
http://localhost:9203/student/_doc/100响应体包括目前已经熟悉了的元数据元素,再加上 _source 字段,这个字段包含我们索引数据时发送给 Elasticsearch 的原始 JSON 文档:
{ "_index": "student", "_type": "_doc", "_id": "100", "_version": 1, "_seq_no": 20, "_primary_term": 1, "found": true, "_source": { "name": "xiaoli", "age": 18, "love": "I like swimming.", "createTime": "2022-05-04 20:00:00" }}GET 请求的响应体包括 {"found": true} ,这证实了文档已经被找到。 如果我们请求一个不存在的文档,我们仍旧会得到一个 JSON 响应体,但是 found 将会是 false 。 此外, HTTP 响应码将会是 404 Not Found ,而不是 200 OK 。
head请求方式:
{ "_index": "student", "_type": "_doc", "_id": "101", "found": false}
直接采用curl方式:
curl -i -XGET http://localhost:9203/student/_doc/101返回内容如下,

3、查询单个文档指定字段
默认情况下, GET 请求会返回整个文档,这个文档正如存储在 _source 字段中的一样。但是也许你只对其中的 title 字段感兴趣。单个字段能用 _source 参数请求得到,多个字段也能使用逗号分隔的列表来指定。
请求样例格式:
GET /student/_doc/100?_source=love,/
响应数据样例,
{ "_index": "student", "_type": "_doc", "_id": "100", "_version": 1, "_seq_no": 20, "_primary_term": 1, "found": true, "_source": { "love": "I like swimming." }}该 _source 字段现在包含的只是我们请求的那些字段,并且已经将其他字段过滤掉了。
如果我们仅需要source端点内容返回,不要其他元数据信息,此时可调整请求为,
GET /student/_doc/100/_source/
{ "name": "xiaoli", "age": 18, "love": "I like swimming.", "createTime": "2022-05-04 20:00:00"}4、检查文档是否存在
如果只想检查一个文档是否存在--根本不想关心内容—那么用 HEAD 方法来代替 GET 方法。
HEAD 请求没有返回体,只返回一个 HTTP 请求报头:
GET:/student/_doc/100如果文档存在, Elasticsearch 将返回一个 200 ok 的状态码:
HTTP/1.1 200 OK
Content-Type: text/plain; charset=UTF-8
Content-Length: 0
若文档不存在, Elasticsearch 将返回一个 404 Not Found 的状态码:
HTTP/1.1 404 Not Found
Content-Type: text/plain; charset=UTF-8
Content-Length: 0
说明:当然一个文档仅仅是在检查的时候不存在,并不意味着一毫秒之后它也不存在:也许同时正好另一个进程就创建了该文档。
5、更新文档
在 Elasticsearch 中文档是 不可改变 的,不能修改它们。相反,如果想要更新现有的文档,需要 重建索引 或者进行替换, 我们可以使用相同的 index API 进行实现,在 索引文档 中已经进行了讨论。与新增文档类似,知识返回结果会旅游不同。
请求示例URL, 创建文档需要使用PUT操作命令。
http://localhost:9203/student/_doc/100/请求示例参数,
{ "name": "xiaoli", "age": 19, "love": "I like swimming.", "createTime":"2022-05-04 20:00:00"}响应示例返回,
{ "_index": "student", "_type": "_doc", "_id": "100", "_version": 2, //版本号改变为2 "result": "updated", "_shards": { "total": 2, "successful": 2, "failed": 0 }, "_seq_no": 21, "_primary_term": 1}在响应体中,我们能看到 Elasticsearch 已经增加了 _version 字段值2 。另外 result 标志设置成 "update" ,是因为相同的索引、类型和 ID 的文档已经存在。
当做更新操作时,Elasticsearch 已将旧文档标记为已删除,并增加一个全新的文档。 尽管你不能再对旧版本的文档进行访问,但它并不会立即消失。当继续索引更多的数据, ES会在后台清理这些已删除文档。
ES update的执行过程如下:
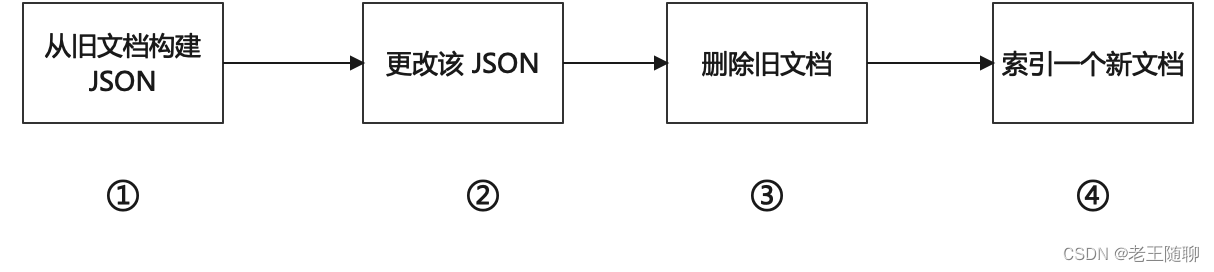
6、删除文档
除以上操作外,有时候我们也需要对数据进行删除操作。那在Elasticsearch中删除文档的语法格式如下:
DELETE /index/_doc/id
请求样例,
http://localhost:9203/student/_doc/100/ //Delete请求如果找到该文档,Elasticsearch 将要返回一个result为”deleteed“,和一个类似以下结构的响应体。注意,字段 _version 值已经增加:
{ "_index": "student", "_type": "_doc", "_id": "100", "_version": 3, "result": "deleted", "_shards": { "total": 2, "successful": 2, "failed": 0 }, "_seq_no": 22, "_primary_term": 1}如果文档没有找到,我们将得到 result为 not_found 的响应码和类似这样的响应体:
{ "_index": "student", "_type": "_doc", "_id": "100", "_version": 1, "result": "not_found", "_shards": { "total": 2, "successful": 2, "failed": 0 }, "_seq_no": 23, "_primary_term": 1}即使文档不存在( result 是 not_fount ), _version 值仍然会增加。这是 Elasticsearch 内部记录本的一部分,用来确保这些改变在跨多节点时以正确的顺序执行。
说明:前面已经在更新整个文档中提到的,删除文档不会立即将文档从磁盘中删除,只是将文档标记为已删除状态。随着你不断的索引更多的数据,Elasticsearch 将会在后台清理标记为已删除的文档。
7、文档部分更新
我们前面介绍了update的全量更新,有时候实际业务场景也需要对部分字段进行更新。 uodate请求最简单的一种形式是接收文档的一部分作为 doc 的参数, 它只是与现有的文档进行合并。对象被合并到一起,覆盖现有的字段,增加新的字段。
http://localhost:9203/student/_doc/1/_update/ //POST请求参数样例, 例如,我们修改id为1的love值,如下所示:
{ "doc" : { "love": "1" }}响应参数样例,
{ "_index": "student", "_type": "_doc", "_id": "1", "_version": 2, "result": "updated", "_shards": { "total": 2, "successful": 2, "failed": 0 }, "_seq_no": 24, "_primary_term": 1}再次查询数据,
{ "_index": "student", "_type": "_doc", "_id": "1", "_version": 2, //版本号会发生变化 "_seq_no": 24, "_primary_term": 1, "found": true, "_source": { "love": "1", //love值已被修改 "createTime": "2022-06-03 17:37:16", "name": "test9", "id": "1", "age": 1 }}这里有一个地方需要注意,更新的时候会发生冲突吗?
我们知道,检索和重建索引步骤的间隔越小,变更冲突的机会越小。 但是它并不能完全消除冲突的可能性。 还是有可能在update设法重新索引之前,来自另一进程的请求修改了文档。
为了避免数据丢失, update API 在检索步骤时,会检索得到文档当前的 _version版本号,并传递版本号到重建索引步骤的index请求。 如果另一个进程修改了处于检索和重新索引步骤之间的文档,那么_version 号将不匹配,更新请求将会失败。
对于部分更新的很多使用场景,文档已经被改变也没有关系。 例如,如果两个进程都对页面访问量计数器进行递增操作,它们发生的先后顺序其实不太重要; 如果冲突发生了,我们唯一需要做的就是尝试再次更新。
这可以通过设置参数 retry_on_conflict 来自动完成, 这个参数规定了失败之前 update 应该重试的次数,它的默认值为 0 。
http://localhost:9203/student/_doc/1/_update?retry_on_conflict=3 //表示冲突时重试3次8、文档批量查询
Elasticsearch 的速度已经很快了,但甚至能更快。 将多个请求合并成一个,避免单独处理每个请求花费的网络延时和开销。 如果你需要从 Elasticsearch 检索很多文档,那么使用 multi-get 或者 mget API 来将这些检索请求放在一个请求中,将比逐个文档请求更快地检索到全部文档。
mget API 要求有一个 docs 数组作为参数,每个元素包含需要检索文档的元数据, 包括 _index 、 _type 和 _id 。如果你想检索一个或者多个特定的字段,那么你可以通过 _source 参数来指定这些字段的名字:
POST: http://localhost:9203/_mget查询请求示例,
{ "docs": [ { "_index": "student", //student index "_type": "_doc", "_id": 1, "_source": "love" }, { "_index": "student2", //student2 index "_type": "_doc", "_id": 1, "_source": "love" } ]}查询结果示例,
{ "docs": [ { "_index": "student", "_type": "_doc", "_id": "1", "_version": 3, "_seq_no": 25, "_primary_term": 1, "found": true, "_source": { "love": "2" } }, { "_index": "student2", "_type": "_doc", "_id": "1", "_version": 1, "_seq_no": 0, "_primary_term": 1, "found": true, "_source": { "love": "I like to collect rock albums" } } ]}9、代价较小的批量查询
与 mget 可以使我们一次取回多个文档同样的方式, bulk API 允许在单个步骤中进行多次 create 、 index 、 update 或 delete 请求。 如果你需要索引一个数据流比如日志事件,它可以排队和索引数百或数千批次。
bulk 与其他的请求体格式稍有不同,如下所示:
{ action: { metadata }}\n{ request body }\n{ action: { metadata }}\n{ request body }\n...
请求参数示例如下,
curl -X POST "localhost:9203/_bulk?pretty" -H 'Content-Type: application/json' -d'{ "delete": { "_index": "student", "_type": "_doc", "_id": "123" }}{ "create": { "_index": "student", "_type": "_doc", "_id": "123" }}{ "love": "My first blog post" }{ "index": { "_index": "student", "_type": "_doc" }}{ "love": "My second blog post" }{ "update": { "_index": "student", "_type": "_doc", "_id": "123", "retry_on_conflict" : 3} }{ "doc" : {"love" : "My updated blog post"}}'//说明:每个操作命令结束后需要加换行符响应结果如下,
{ "took": 191, "errors": false, "items": [ { "delete": { "_index": "student", "_type": "_doc", "_id": "123", "_version": 1, "result": "not_found", "_shards": { "total": 2, "successful": 2, "failed": 0 }, "_seq_no": 26, "_primary_term": 1, "status": 404 } }, { "create": { "_index": "student", "_type": "_doc", "_id": "123", "_version": 2, "result": "created", "_shards": { "total": 2, "successful": 2, "failed": 0 }, "_seq_no": 27, "_primary_term": 1, "status": 201 } }, { "index": { "_index": "student", "_type": "_doc", "_id": "DdehLYEBJi7Pb6zIX3Fa", "_version": 1, "result": "created", "_shards": { "total": 2, "successful": 2, "failed": 0 }, "_seq_no": 28, "_primary_term": 1, "status": 201 } }, { "update": { "_index": "student", "_type": "_doc", "_id": "123", "_version": 3, "result": "updated", "_shards": { "total": 2, "successful": 2, "failed": 0 }, "_seq_no": 29, "_primary_term": 1, "status": 200 } } ]}每个子请求都是独立执行,因此某个子请求的失败不会对其他子请求的成功与否造成影响。 如果其中任何子请求失败,最顶层的 error 标志被设置为 true ,否则为false。
说明:bulk 请求不是原子操作,所以不能用它来实现事务控制。每个请求是单独处理的,因此一个请求的成功或失败不会影响其他的请求。
最后,说明一下bluk请求的限制条件。
整个批量请求都需要由接收到请求的节点加载到内存中,因此该请求越大,其他请求所能获得的内存就越少。 批量请求的大小有一个最佳值,大于这个值,性能将不再提升,甚至会下降。 但是最佳值不是一个固定的值。它完全取决于硬件、文档的大小和复杂度、索引和搜索的负载的整体情况。
那我们如何找到这个最佳点呢?
通过批量索引文档,不断增加批量大小进行尝试。 当性能开始下降时,那么你的批量大小就太大了。官方建议:一个好的办法是开始时将 1,000 到 5,000 个文档作为一个批次, 如果你的文档非常大,那么就减少批量的文档个数。
同时,密切关注批量请求的物理大小。一千个 1KB 的文档是完全不同于一千个 1MB 文档所占的物理大小。 建议一个比合理的批量查询大小所占用物理大小约为 5-15 MB较佳。