INTERSPEECH 2022|FS-CANet: 基于全带子带交叉注意力机制的语音增强
INTERSPEECH 2022
FS-CANet:

本文由清华大学与腾讯天籁实验室、香港中文大学合作,提出了一个全带-子带交叉注意力(FSCA)模块来交互融合全局信息和局部信息,并将其应用于FullSubNet,构建了一个新的语音增强模型FS-CANet。 FS-CANet在降低了 25% 的参数量的情况下进一步提升了原有语音增强模型在复杂声学环境下的降噪性能,在无混响的条件下SI-SDR达到了 18.08 dB ,有混响的条件下SI-SDR达到了 16.82 dB ,超越了现有的最好的方法。
01 背景动机
单通道语音增强方法从单通道带噪音频信号中去除背景噪声,旨在提高语音的质量和可懂度,在助听器、音频通信和自动语音识别中有着重要的应用。 近年来,基于深度学习的语音增强方法,在低信噪比、混响等挑战性条件下可以取得较好的效果,相关方法可以分为时域方法和频域方法。 时域方法直接从带噪语音波形预测干净的语音波形。 频域方法则一般以带噪频谱特征为输入,其学习目标是干净的频谱特征或掩模(包括理想二值掩模IBM、理想比掩模IRM、理想复比掩模cIRM等)。 总的来说,考虑到系统的鲁棒性和计算复杂度,频域方法更为人们所广泛使用。
FullSubNet作为一种单通道频域语音增强方法被提出,它由一个全带模型和一个子带模型组成,将两者串联后进行联合优化。 通过这种方式,FullSubNet可以捕捉到全局频谱的上下文信息,同时保留了关注局部频谱模式的能力,因此在降噪任务上取得了优异的效果。 然而,在FullSubNet中,全带模型和子带模型之间的关系是通过简单拼接全带模型的输出与子带单元而实现的,每一个子带单元最终只能见到一个维度的全带信息。 因此,这种方法只为子带单元补充了少量的全局频谱信息,它缺乏全带信息和子带信息之间的交互,这限制了模型降噪能力的上限。
02 贡献
本文针对上述的问题,提出了一个全带-子带交叉注意(fullband-subband cross-attention, FSCA)模块来交互融合全局信息和局部信息,并将其应用于FullSubNet,提出了新的语音增强方法FS-CANet。 通过FS-CANet,我们在全带-子带语音增强模型内有效交互融合全带与子带信息,在降低参数量的情况下进一步提升了原有语音增强模型在复杂声学环境下的降噪性能。
03 解决方案
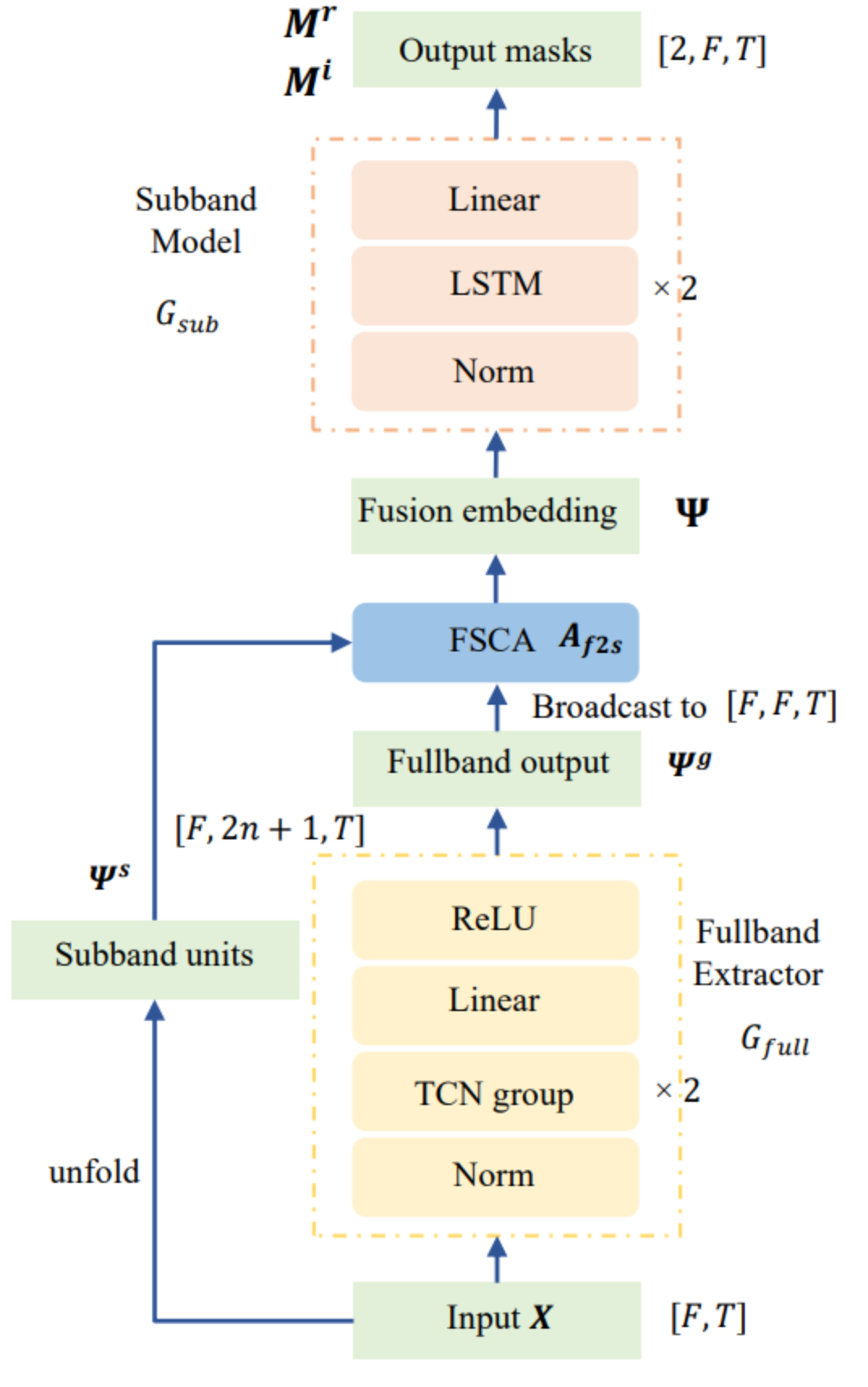
FS-CANet整体架构
FS-CANet的模型结构如图所示,其主要由三个部分组成: 一个高效的全频带提取器(Fullband Extractor),一个全带-子带交叉注意力机制模块在(FSCA module)和一个子带模型(Subband Model)。
全频带提取器(Fullband Extractor)
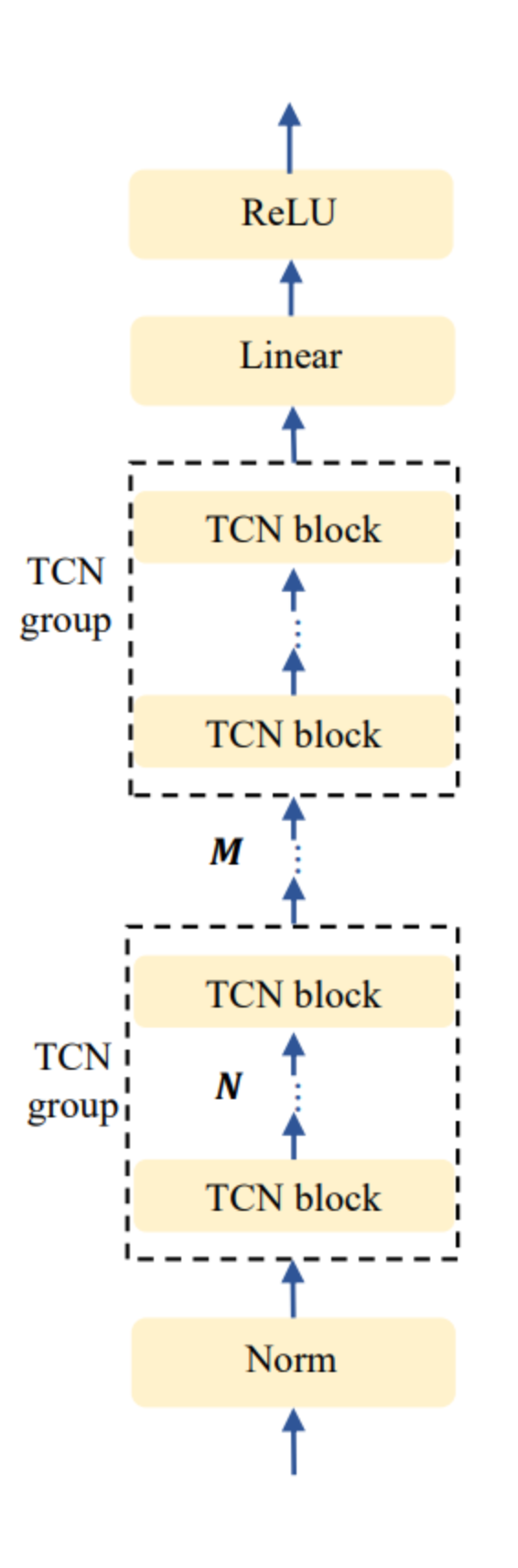
全频带提取器模块示意图
全频带提取器(Fullband Extractor)是在FullSubNet+中设计的,它是一个高效的全带处理模型。 与FullSubNet中的全带模型相比,它在参数数量较少的情况下具有更好的性能。 因此,我们用全频带提取器来替代FullSubNet中的全带模型。 如图所示,全频带提取器中,一组堆叠的TCN块被用来替代一层LSTM。 我们通过指数级增加每组的扩张因子来堆叠TCN块,以捕捉全频段上具有长距离依赖性的语音信号的特征。 具体实现上,FS-CANet中的全频带提取器,其有2组4个TCN块。
全带-子带交叉注意力机制模块(FSCA Module)
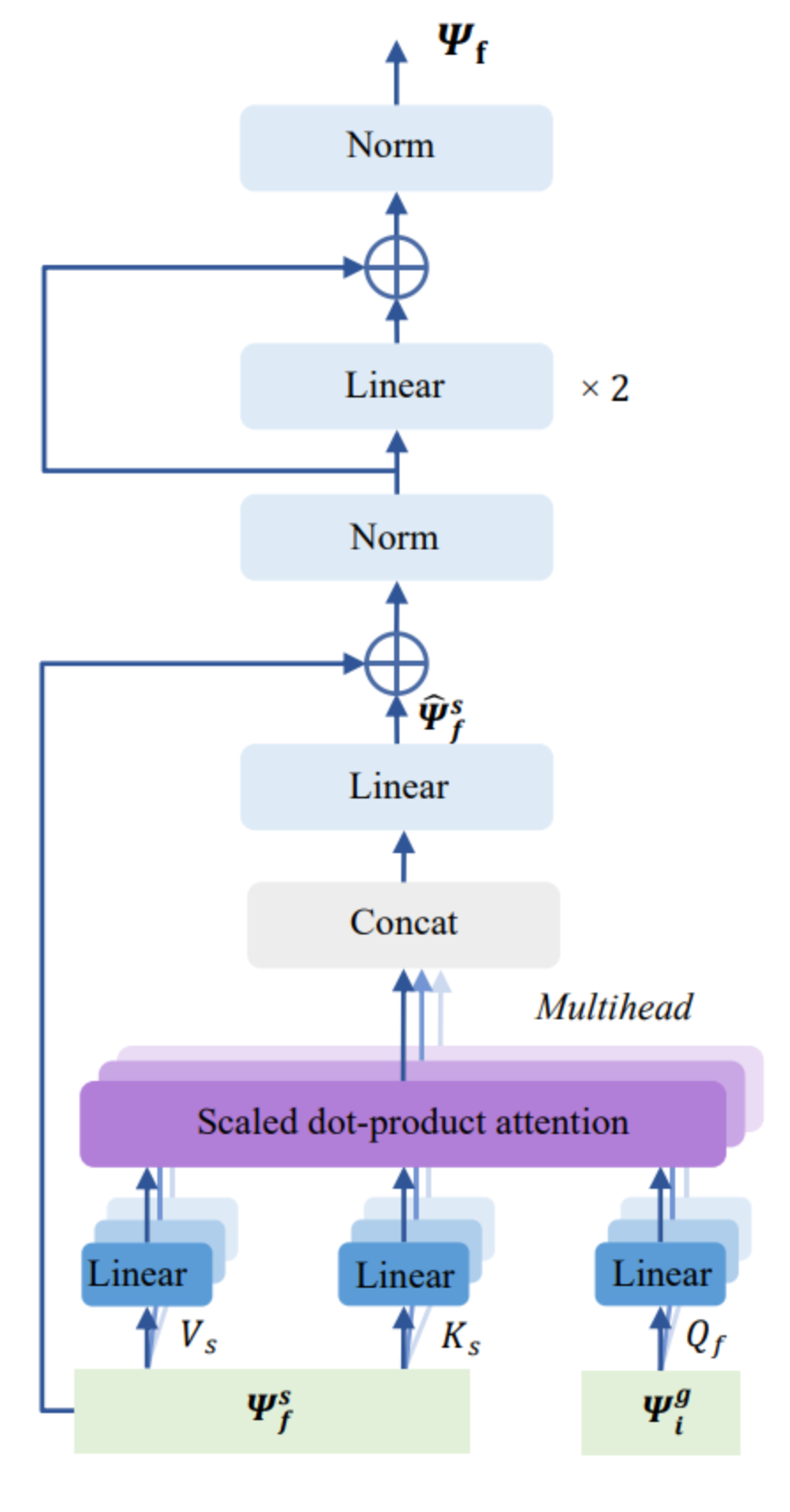
全带-子带交叉注意力机制模块示意图
在FS-CANet中,我们使用全带-子带交叉注意力机制模块来取代FullSubNet原有的简单拼接方法。 全带-子带交叉注意力机制模块的结构如图所示,它由用于交互融合全带子带信息的多头注意力机制模块以及用于进一步融合的全连接层所组成。 全带-子带交叉注意力机制模块以子带单元和全频带embedding作为输入,对于每个子带单元和全频带embedding,子带单元被线性地转换为注意力机制中的Key和Value。 全频带embedding而则被线性转换为注意力机制中的Query。 为了实现全带和子带信息的交互,我们使用了多头注意力机制:
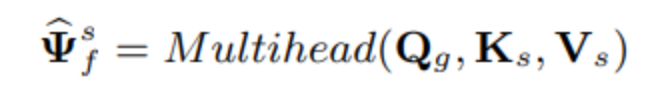
通过这种交互融合,多头注意力机制的输出embedding中包含了子带单元所关注的多个不同维度上的全局时域以及频域信息。 而后,多头注意力机制的输出embedding与子带单元进行相加,在后续的全连接层中进行进一步的融合,最终得到包含全局信息以及局部信息的融合embedding 。
子带模型(Subband Model)
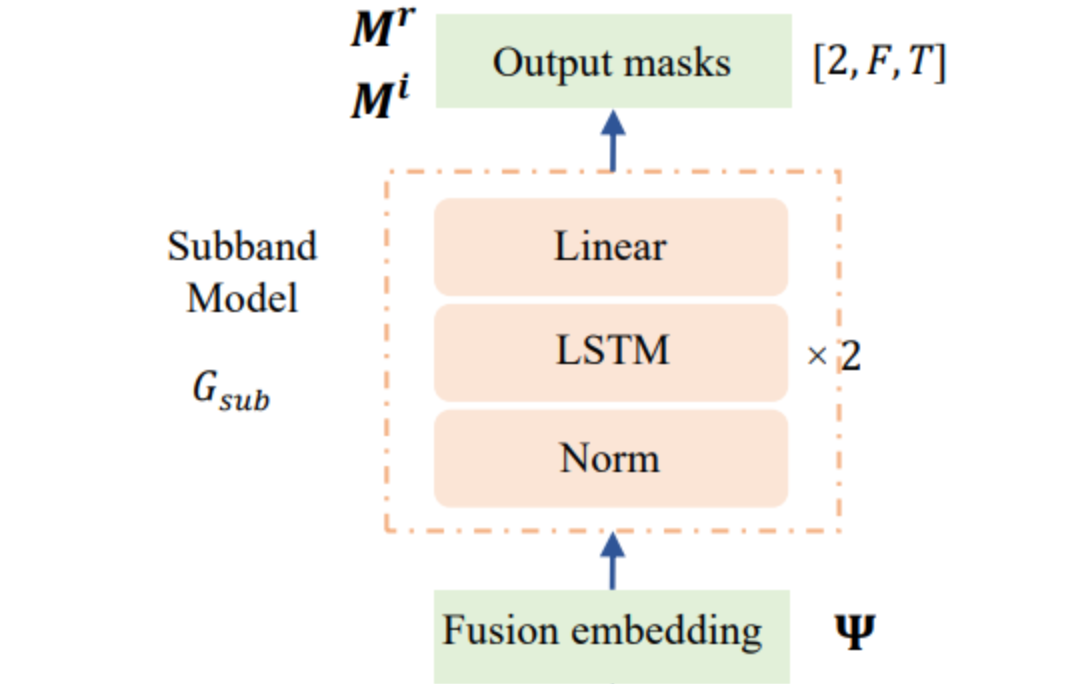
子带模型示意图
为了学习信号平稳性和保持模型训练中的稳定性,FS-CANet中的子带模型使用由两个堆叠的单向LSTM层和一个全连接层组成的网络结构。 子带模型以经过交互融合的融合embedding作为输入,这些融合embedding中包含了全局信息以及局部信息。 子带模型根据这些融合embedding来预测最终的学习目标cIRM。
04 实验验证
我们在InterSpeech 2021 DNS Challenge数据集的一个子集上训练和评测了FS-CANet。 干净数据集包括2150名说话人的562.72个小时的语音片段。 噪声数据集包括来自超过150个类别的181个小时的65302个音频。
在模型训练过程中,我们使用动态混合语音-噪声来模拟带噪语音。 具体而言,在每个训练周期开始之前,75%的干净语音与从OpenSLR26和OpenSLR28数据集随机选择的房间脉冲响应(RIR)混合。 之后,在-5到20分贝的随机信噪比下,通过混合干净的语音和噪声来动态地产生带噪语音。
DNS Challenge提供了一个公开可用的测试数据集,由无混响和有混响的带噪语音组成,其中每个类别有150个噪声片段,信噪比分布在0分贝到20分贝之间。 我们使用这个测试集来评估我们模型的有效性。
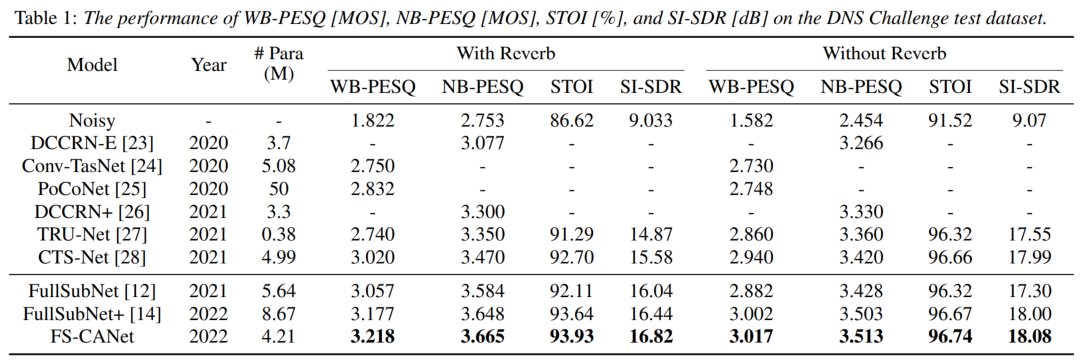
不同模型DNS Challenge测试集上的表现
与FullSubNet和FullSubNet+的对比实验
在上表的最后三行,我们比较了FS-CANet与FullSubNet和FullSubNet+的性能。 根据该表,FS-CANet在所有的评估指标上都优于基线FullSubNet,而且还具有更小的参数量。 此外,FullSubNet+作为FullSubNet的改进方法,具有复杂的模型结构,比FullSubNet有更好的性能。 然而,根据上图显示,FS-CANet以较少的参数量和较简单的结构,实现了优于FullSubNet+的性能。
与SOTA方法的对比实验
此外,我们将FS-CANet与当前一些最先进的方法进行比较。 我们提出的FS-CANet在没有混响的情况下显示出卓越的降噪性能,在有混响的情况下甚至有更突出的性能提升。 这表明,作为对FullSubNet的改进,FS-CANet继承了子带模型对混响效果的优秀建模能力,并在此基础上大大提高了降噪能力。
对全带-子带交叉注意力机制模块的探究实验
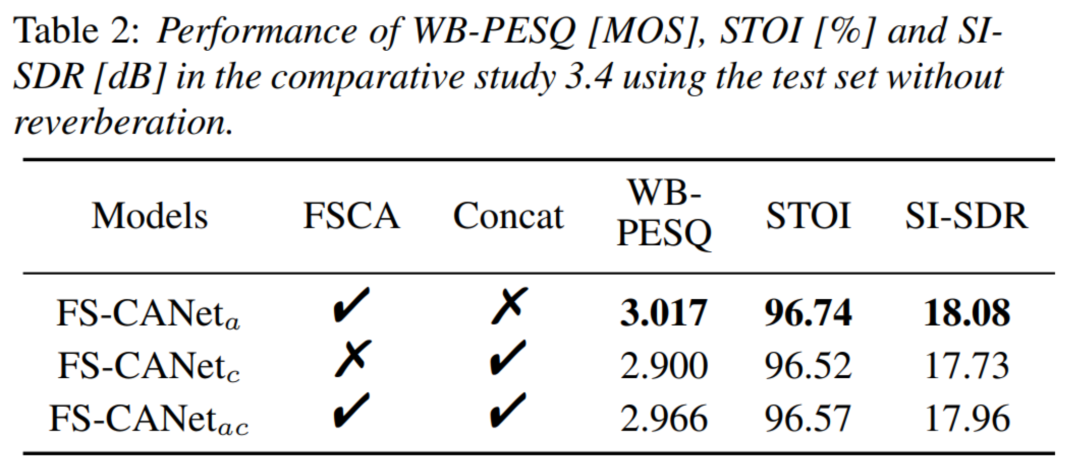
对全带-子带交叉注意力机模块的探究实验
为了研究全带-子带交叉注意力方法,我们以FS-CANet为骨干模型,进行不同融合方式的实验。 上表显示了三种融合方式在无混响测试集上的测试结果,其中 "FSCA "指的是使用FSCA模块,而 "Concat "指的是使用FullSubNet的简单拼接方法。 从表中可以看出,只使用全带-子带交叉注意力机制和同时使用全带-子带交叉注意力机制和拼接方法的FS-CANet的性能比只使用拼接方法的FS-CANet好。 这说明所提出的全带-子带交叉注意力机制模块可以有效地提高模型在PESQ和SNR方面的性能,而且全带-子带交叉注意力机制模块可以有效地取代拼接方法的作用,通过降低输入维度来减轻后续子带模型的负担。 此外,可以发现,同时使用全带-子带交叉注意力机制和拼接方法的FS-CANet的性能不如只使用全带-子带交叉注意力机制的FS-CANet,这可能是因为融合embedding与全频带embedding中包含的信息存在冲突。
05 结语
在本文中,我们提出了一个全带-子带交叉注意力(FSCA)模块来交互融合全局信息和局部信息,并将其应用于FullSubNet。 这个新方法被称为FS-CANet。 此外,与FullSubNet不同的是,我们所提出的的FS-CANet通过时域卷积网络(TCN)块来优化全带模型,以进一步减少模型大小。 在DNS Challenge - Interspeech 2021数据集上的实验结果表明,我们所提出的的FS-CANet优于其他最先进的语音增强方法,取得了最好(SOTA)的性能,说明了全带-子带交叉注意力机制的有效性。 在未来,我们会继续探究探索子带和全带信息的双向融合。