VALL-E:微软全新语音合成模型可以在3秒内复制任何人的声音
近日,微软研究人员宣布了一种新的语音合成AI模型 VALL-E,给出3秒样音就可以精确地模拟一个人的声音。一旦它学会了一个特定的声音,VALL-E可以复制说话者的情绪和语气,即使说话者本人从未说过的单词也可以模仿。
论文地址:
https://arxiv.org/pdf/2301.02111.pdf

它的创建者推测,VALL-E可用于高质量的文本转语音应用程序、语音编辑,其中可以编辑一个人的录音并从文本转录中更改(让他们说出他们最初没有说的话),以及与其他生成AI模型(如GPT-3)结合使用时的音频内容创建。
GPT-3:
https://arstechnica.com/information-technology/2022/11/openai-conquers-rhyming-poetry-with-new-gpt-3-update/
微软称VALL-E为“神经编解码器语言模型”,它建立在Meta于2022年10月宣布的一项名为EnCodec的技术之上(https://arstechnica.com/information-technology/2022/11/metas-ai-powered-audio-codec-promises-10x-compression-over-mp3/)。与其他通常通过操作波形合成语音的文本转语音方法不同,VALL-E从文本和声学提示生成离散音频编解码器代码。它基本上分析一个人的声音,通过EnCodec将这些信息分解成离散的组件(称为“令牌”),并使用训练数据来匹配它“知道”的声音,如果它说的是三秒样本之外的其他短语,声音会是什么样子。或者,正如微软在VALL-E论文中所说的那样:
为了合成个性化语音(例如,zero-shot TTS),VALL-E生成相应的声学令牌,条件是3秒注册录音和音素提示的声学令牌,分别约束扬声器和内容信息。最后,使用生成的声学标记与相应的神经编解码器解码器合成最终波形。
微软在Meta组装的名为LibriLight的音频库上训练了VALL-E的语音合成能力。它包含来自7000多名演讲者的60000小时的英语演讲,其中大部分来自LibriVox公共领域的有声读物。为了使VALL-E生成良好的结果,三秒样本中的语音必须与训练数据中的语音紧密匹配。
在VALL-E示例网站上,微软提供了数十个AI模型的音频示例。在样本中,“Speaker Prompt”是提供给VALL-E的三秒音频,它必须模仿。“Ground Truth”是同一个说话者为了比较目的而说出特定短语的预先存在的录音(有点像实验中的“对照”)。“Baseline”是传统文本到语音合成方法提供的合成示例,“VALL-E”示例是VALL-E模型的输出。
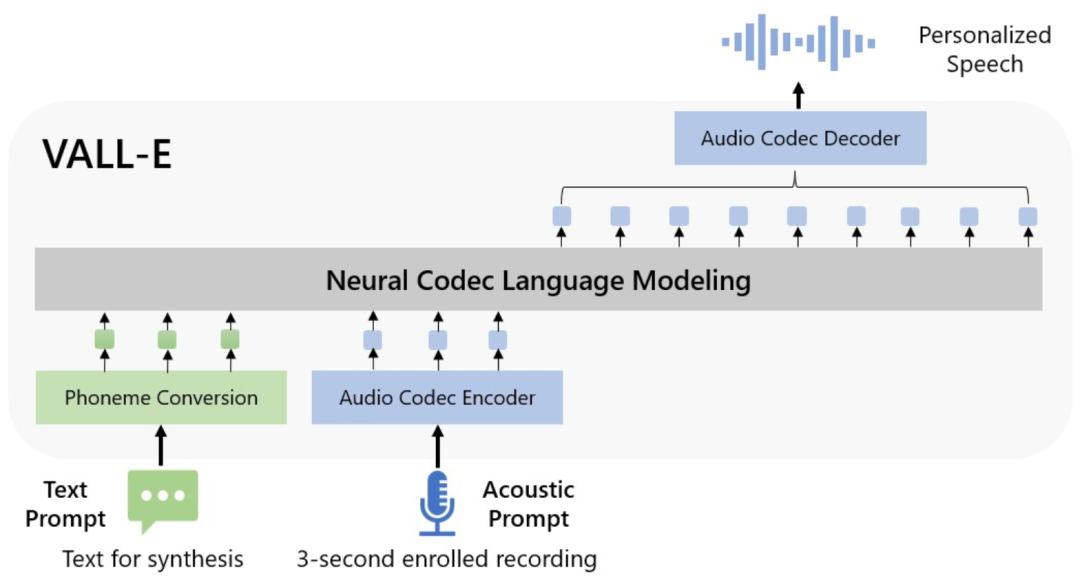
微软研究人员提供的VALL-E框图
该模型基于transformer,具有Dale-1外观。不要与基于扩散的Dalle-2混淆。下面是微软发布的该模型的几个实例,很明显这是TTS技术的一个重大进步。
在使用VALL-E生成这些结果时,研究人员只将三秒钟的“Speaker Prompt”样本和一个文本字符串(他们希望语音说的话)输入VALL-E。因此,将“Ground Truth”样本与“VALL-E”样本进行比较。在某些情况下,两个样本非常接近。一些VALL-E结果似乎是计算机生成的,但其他结果可能会被误认为是人类的语音,这是模型的目标。
除了保留说话者的人声音色和情感音调外,VALL-E还可以模仿样本音频的“声学环境”。例如,如果样本来自电话,则音频输出将在其合成输出中模拟电话呼叫的声学和频率属性(这是一种奇特的说法,听起来也像电话)。微软的样本(在“多样性合成”部分)表明,VALL-E可以通过改变生成过程中使用的随机种子来产生语音音调的变化。
也许是由于VALL-E可能助长恶作剧和欺骗的能力,微软没有提供VALL-E代码供其他人试验,所以我们无法测试VALL-E的功能。研究人员似乎意识到这项技术可能带来的潜在社会危害。对于论文的结论,他们写道:
“由于VALL-E可以合成符合说话人身份的语音,因此滥用模型可能会带来潜在风险,例如欺骗语音识别或冒充特定说话人。为了降低此类风险,可以构建一个检测模型来区分音频剪辑是否由VALL-E合成。在进一步开发模型时,我们还将把微软人工智能原则付诸实践。”
原文地址:
https://arstechnica.com/information-technology/2023/01/microsofts-new-ai-can-simulate-anyones-voice-with-3-seconds-of-audio/