2022年语音合成(TTS)和语音识别(ASR)年度总结
论文统计每月更新一次,主要跟踪语音合成和语音识别的发展状况。很多文章都是在会议后才发出,但不影响统计。统计过程难免存在疏漏,因此统计结果仅供参考。
所有文章语音合成领域统计列表请访问:
http://yqli.tech/page/tts_paper.html
语音识别领域论文统计请访问:
http://yqli.tech/page/asr_paper.html
开源语音数据查询:
http://yqli.tech/page/data.html
如何查找语音资料请参考文章:
https://mp.weixin.qq.com/s/eJcpsfs3OuhrccJ7_BvKOg
文章统计excel :
https://docs.google.com/spreadsheets/d/11YYOg6i6UXw19_g1JRaXGNhvt1zhG24RgOXCzZlqZGE/edit?usp=sharing
AIGC统计:
http://yqli.tech/page/aigc.html
语音合成篇
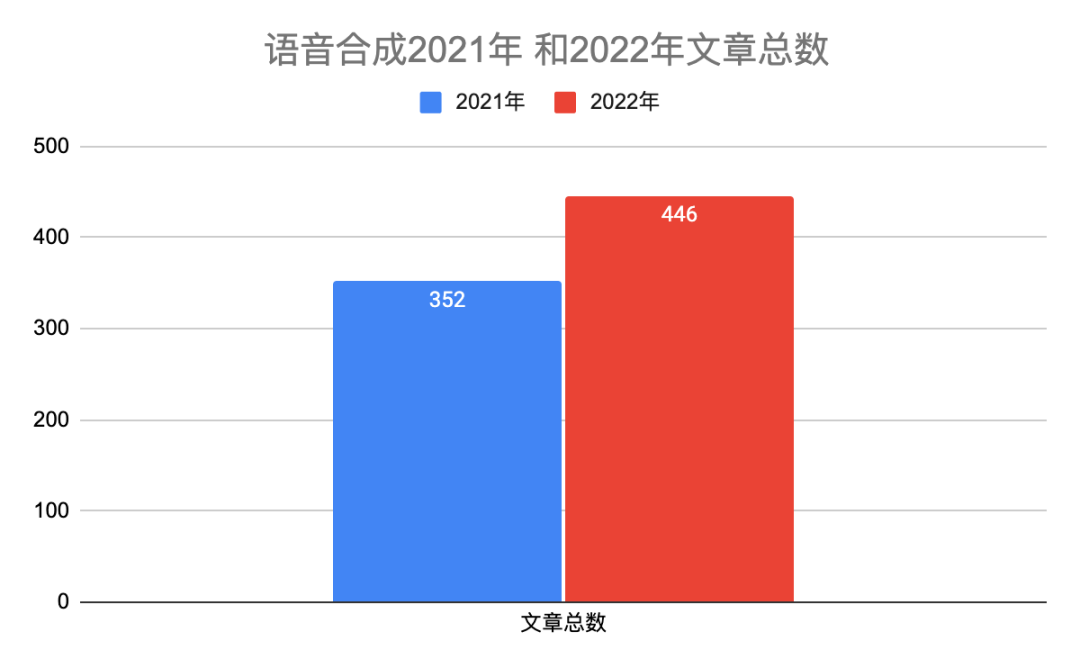
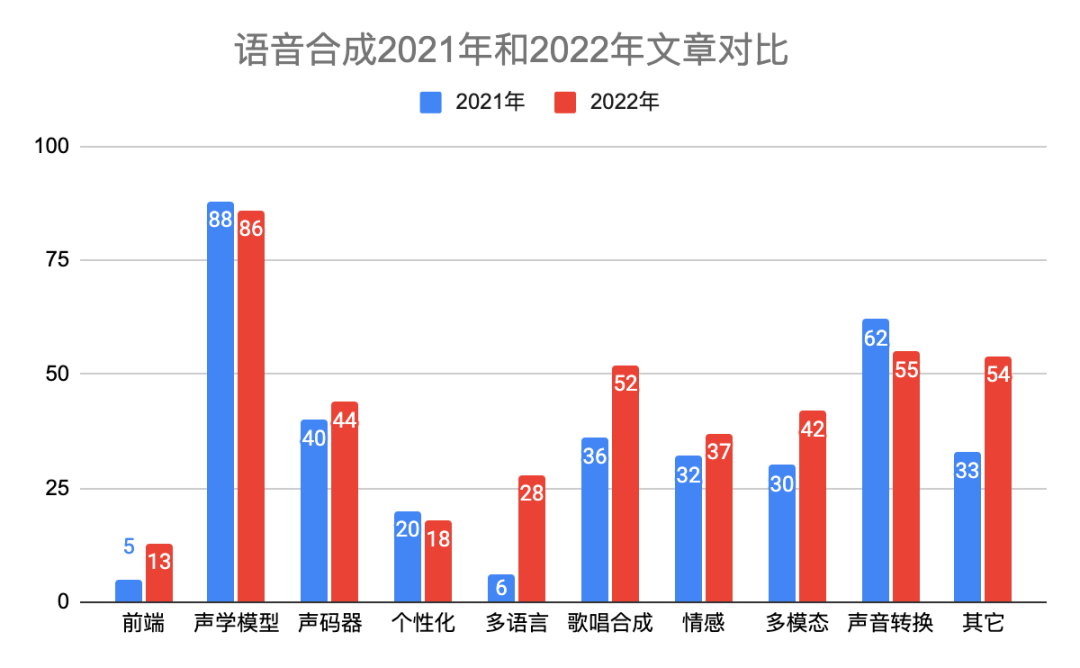
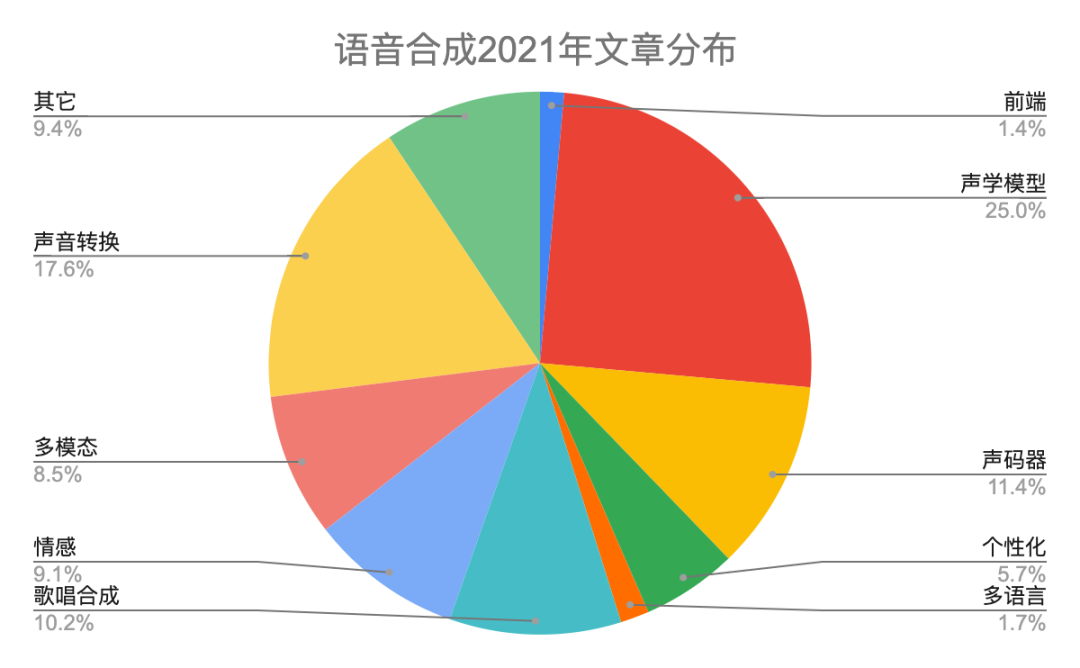
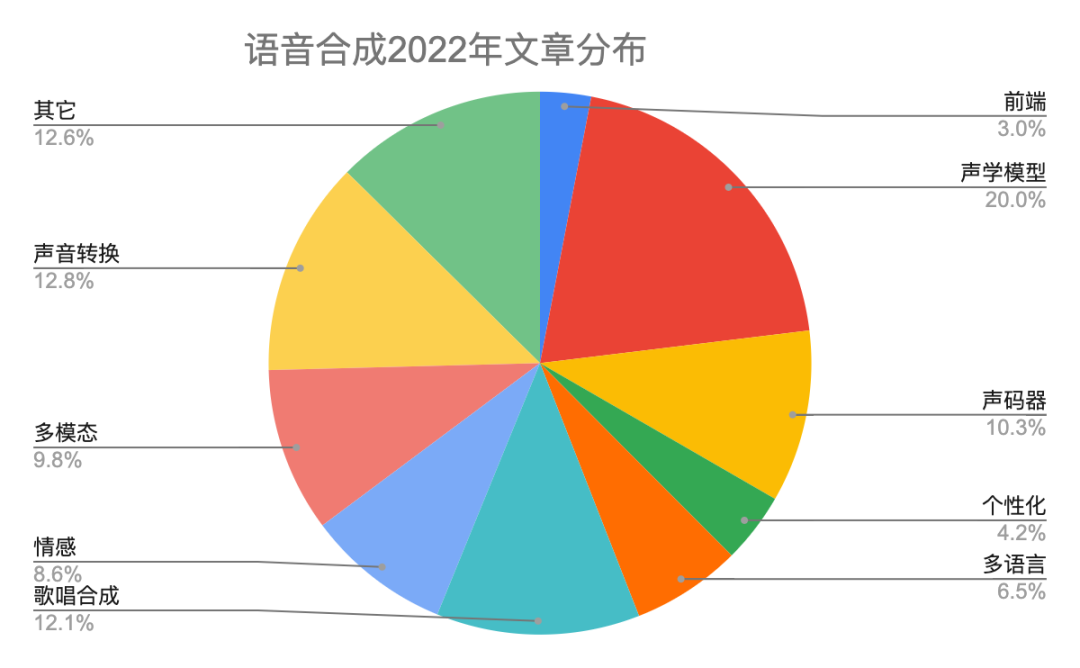
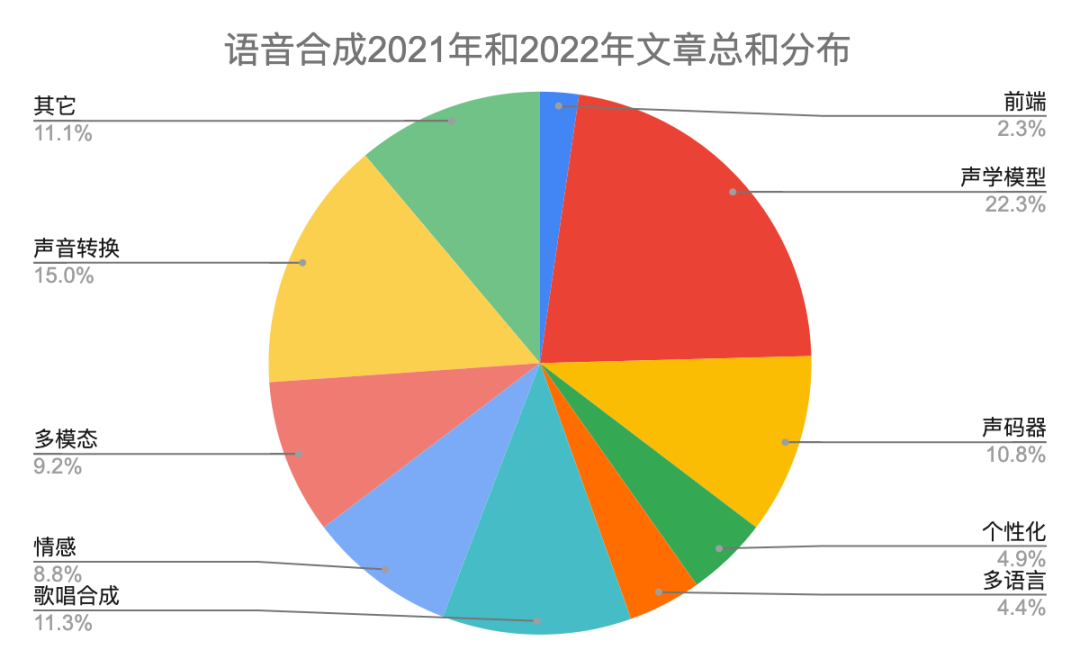
表一给出具体分类说明。2022年语音合成有446篇文章,比2021多一些。图二和图三是2022年和2021年在每个研究方向上对比柱状图和饼状图,除了声学模型网络结构和声音转换相对稍微下降,其它方向都有上升。本年度的热点主要分布在声学模型、声码器、歌唱合成、声音转换和多模态。我们知道Diffusion模型在图像领域很火,同样在语音合成领域有24篇文章采用该技术。最后,自从vits端到端以来,很多开源平台也都支持该网络,今年也有十来篇文章做端到端,比如trinitts naturalspeech等等,端到端依然会是接下来几年的研究热点。
表一 语音合成分类说明
|
分类 |
说明 |
|
前端 |
多音字,韵律,g2p等等。 |
|
声学模型 |
语言特征转声学特征,attention工作,多说话人以及双重学习 |
|
声码器 |
波形生成 |
|
个性化 |
少数据,脏数据应用等自适应 |
|
多语言和多说话人 |
多语言模型、多说话人模型 |
|
歌唱合成 |
歌唱和音乐合成 |
|
情感 |
风格和情感 |
|
多模态 |
主要搜集talking head文章 |
|
声音转换 |
基于GAN方案和特征解耦方案 |
|
S2S |
speech-to-speech |
|
其它 |
基于EEG合成,开源数据,MOS评测以及语音合成的应用 |
图一 2022和2021语音合成论文总量
图二 2022年和2021年语音合成各领域文章分布柱状图
图三 2022年和2021年语音合成各领域文章分布饼状图
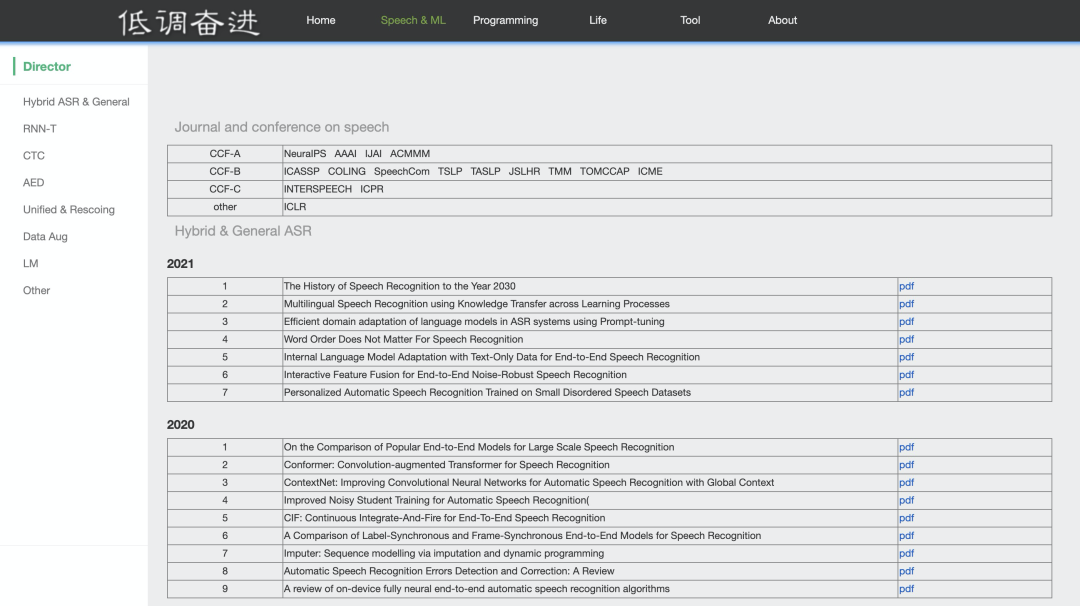
语音合成的文章列表请访问:
http://yqli.tech/page/tts_paper.html
语音识别篇
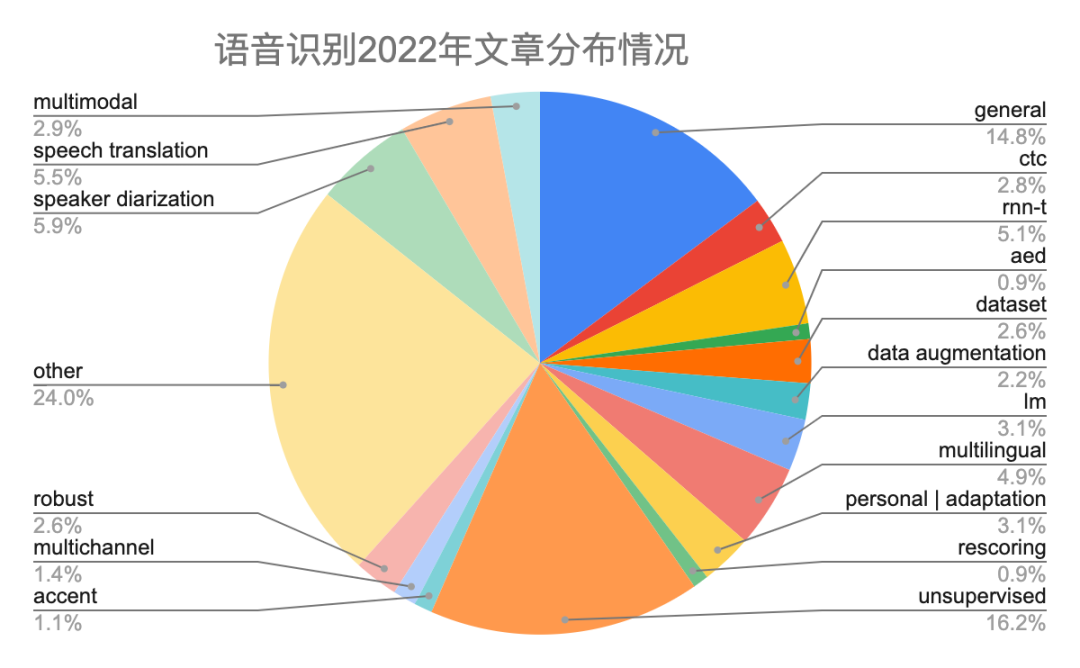
语音识别的文章分类参照表二说明。2022年语音识别文章有641篇,由于今年刚开始统计语音识别文章,所以没有对比2021年情况。由图四和图五可知,声学模型性能优化、无监督学习、多语言系统、个性化、speech translation以及speaker diarization等地方研究较多,其中开源工具espnet、wenet、k2、paddlespeech等都搞得如火如荼。
可参见煮酒论开源语音工具包:
https://mp.weixin.qq.com/s/ZFD2mUAC1B6ZH5JEf5yJmg
表二 语音识别分类说明
|
分类 |
说明 |
|
general |
包括传统、混合语音识别,以及对asr的优化 |
|
ctc |
ctc优化 |
|
rnn-t |
rnn-t的优化 |
|
aed |
aed优化 |
|
dataset |
开源数据库 |
|
data aug |
数据增广 |
|
lm |
语言模型研究 |
|
multilingual |
多语音系统以及code-switch |
|
personal |
少数据量自适应以及个性化ASR |
|
rescoring |
多种模型联合打分 |
|
unsupervised |
无监督,半监督或者自监督学习 |
|
accent ,dialect |
口音和方言 |
|
other |
其它方向研究,包括系统评价标准等等 |
| robust | 鲁棒性 |
| speaker diarization | speaker diarization |
|
multichannel |
多通道 |
| speech translation | 语音翻译 |
| multi-modal | 多模态 |
图四 语音识别文章分布柱状图(单位:篇)
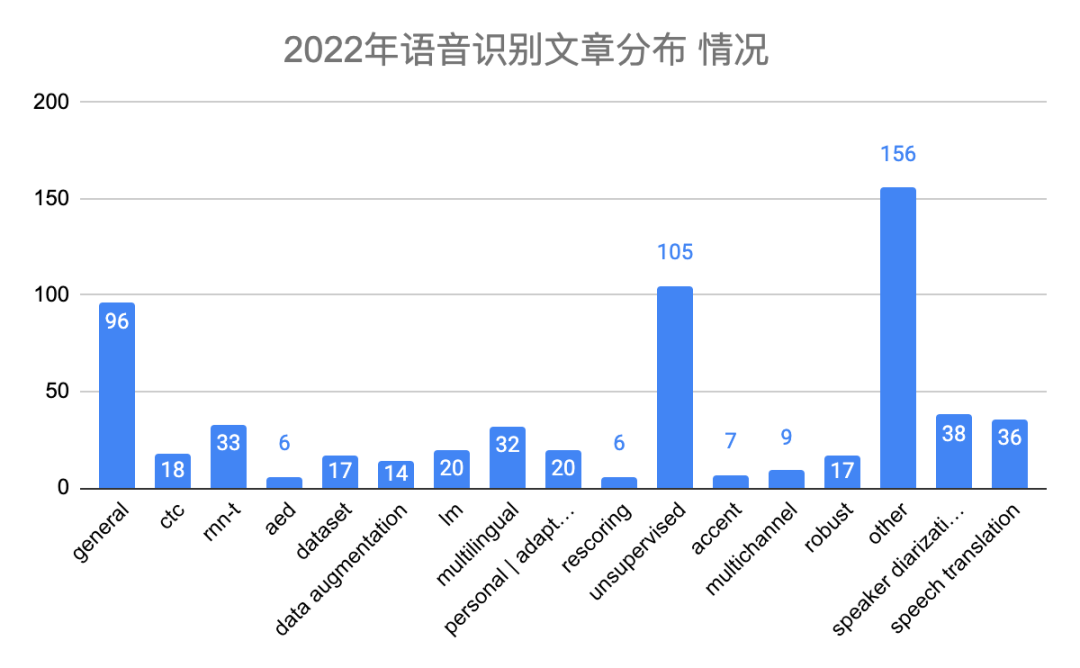
图五 语音识别文章分布饼状图
语音识别的文章列表请访问
http://yqli.tech/page/asr_paper.html