Pytorch神经网络实战学习笔记_23 循环神经网络结构:LSTM结构+双向RNN结构
1 深层循环神经网络的构建
在深层网络结构中,会将简单的RNN模型从两个角度进行改造,具体如下。
- 使用更复杂的结构作为RNN模型的基本单元,使其在单层网络上提取更好的记忆特征。
- 将多个基本单元结合起来,组成不同的结构(多层RNN、双向RNN等)。有时还会配合全连接网络、卷积网络等多种模型结构,一起组成拟合能力更强的网络模型。其中,RNN模型的基本单元称为Cell,它是整个RNN的基础。
2 常见的cell结构:LSTM
长短记忆(Long Short Term Memory,LSTM)单元是一种使用了类似搭桥术结构的RNN单元。它可以学习长期序列信息,是RNN网络中最常使用的Cell之一。
2.1 了解LSTM结构
2.1.1 循环神经网络(RNNs)
通过不断将信息循环操作,保证信息持续存在,从而解决不能结合经验来理解当前问题的问题。
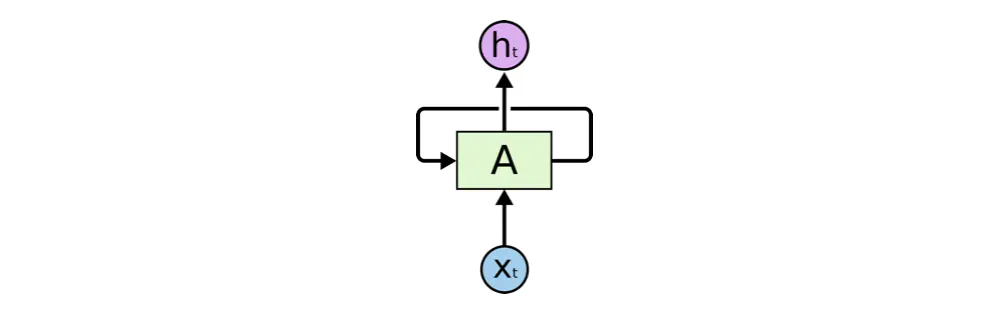
从图中可看出A允许将信息不断的在内部循环,这可以使其保证每一步的计算都能保存以前的信息。
2.1.1 循环神经网络(RNNs)在长序列上的弊端
把RNNs自循环结构展开,可以看成是同一个网络复制多次并连成一条线,把自身信息传递给下一时刻的自己。
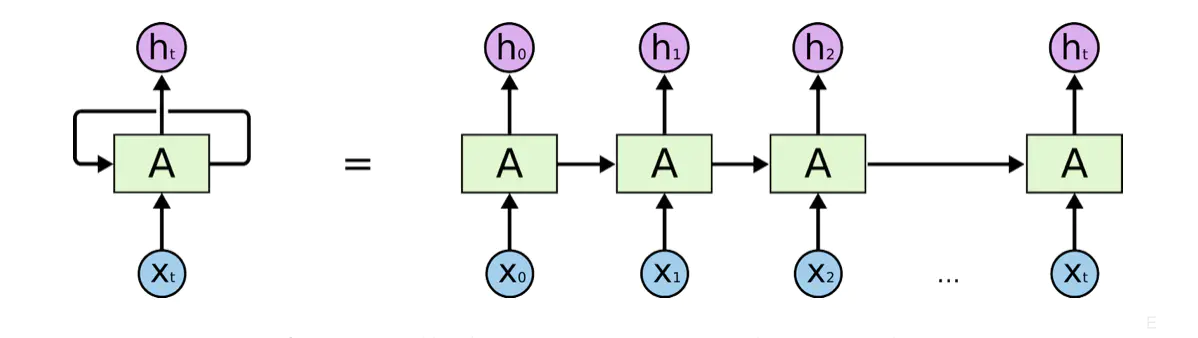
这种链式的结构揭示了RNNs与序列和列表类型的数据密切相关。好像他们生来就是为了处理序列类型数据的。
但是在处理长依赖问题时,RNNs虽然在理论上可行,但实践发现RNNs无法实现。
2.1.3 循环神经网络中cell的LSTM结构
RNNs中有一个特殊的网络结构,叫LSTMs,全称为Long Short Term Memory networks,可翻译为长短时记忆神经网络,这个网络的设计初衷就是为了解决长依赖问题。
所有循环神经网络都具有神经网络的重复模块链的形式。
LSTMs的结构如下:
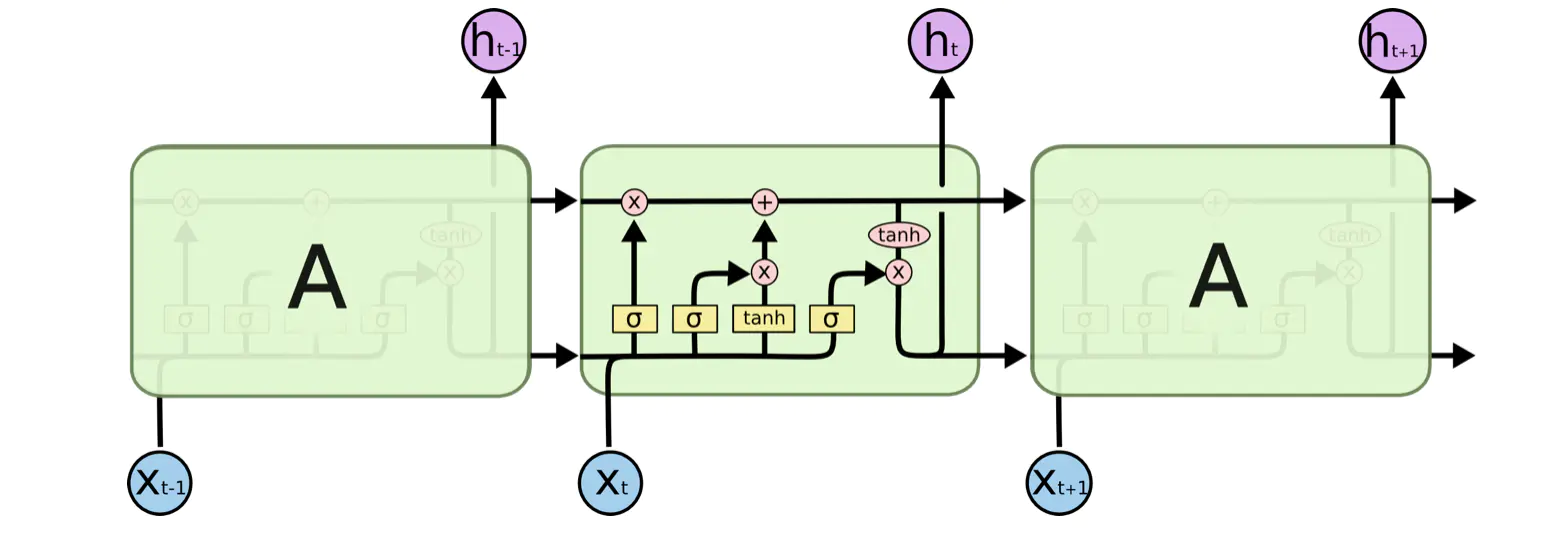
它内部有四个网络层,这不同于标准RNN网络里只有一个网络层的单元。

- Neural Network Layer:激活函数操作
- Pointwise Operation:点操作
- Vector Transfer:数据流向
- Concatenate:表示向量的合并(concat)操作
- Copy:向量的拷贝
LSTMs核心是细胞状态,用贯穿细胞的水平线表示。细胞状态像传送带一样,它贯穿整个细胞却只有很少的分支,这样能保证信息不变的流过整个RNNs,细胞状态如下图所示:
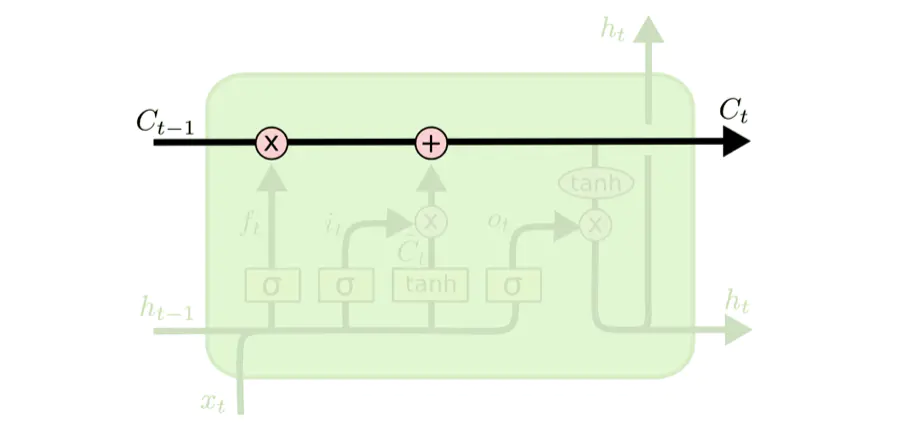
2.3 LSTM结构的门结构
LSTM网络能通过一种被称为门的结构对细胞状态进行删除或者添加信息。
门能够有选择性的决定让哪些信息通过。门的结构为一个sigmoid层和一个点乘操作的组合:
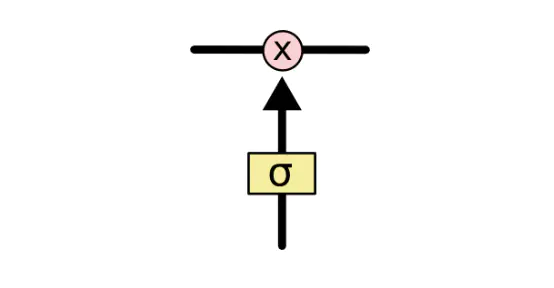
2.3.1 忘记门
忘记门决定模型会从细胞状态中丢弃什么信息。忘记门会读取前一序列模型的输出![]() ,和当前模型的输入
,和当前模型的输入![]() ,来控制细胞状态
,来控制细胞状态![]() 中的每个数字是否保留。
中的每个数字是否保留。
例如,在一个语言模型的例子中,假设细胞状态会包会当前主语的性别,于是根据这个状便可以选择正确的代词。当我们看到新的主语时,应该把新的主语在记忆中更新。忘记]的功能就是先去记忆中找到以前的那个旧的主语,并没有真正执行忘掉操作,只是找到而己。
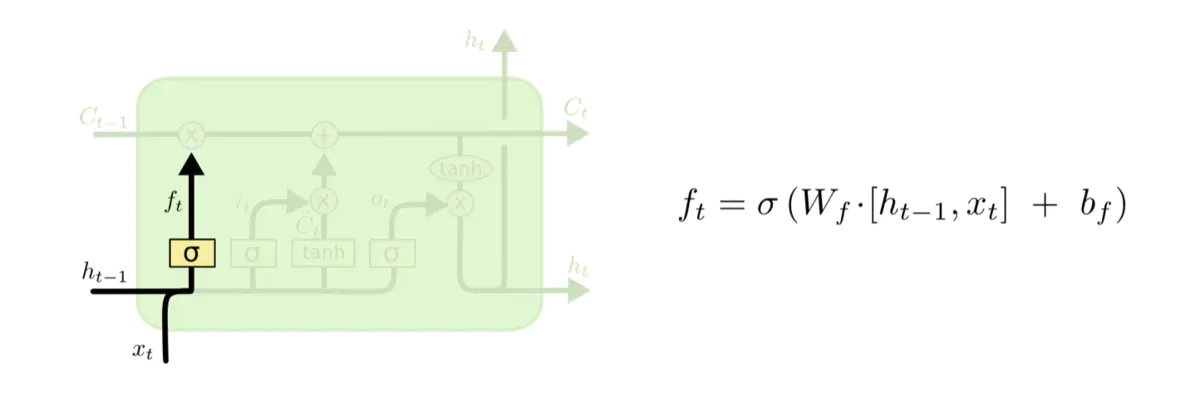
在图中,![]() 代表忘记门的输出结果,σ代表激活函数,
代表忘记门的输出结果,σ代表激活函数,![]() 代表忘记门的权重,
代表忘记门的权重,![]() 代表当前模型的输入,代表前一个序列模型的输出,
代表当前模型的输入,代表前一个序列模型的输出,![]() 代表忘记门的偏置。
代表忘记门的偏置。
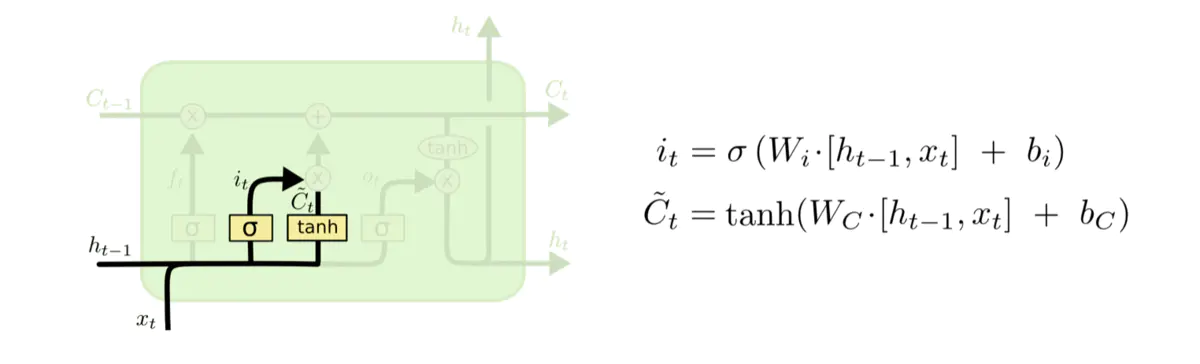
2.3.2 输入门
输入门其实可以分成两部分功能,一部分是找到那些需要更新的细胞状态,另一部分是把需要更新的信息更新到细胞状态里。
1、在下图1中,![]() 代表要更新的细胞状态,σ代表激活函数,
代表要更新的细胞状态,σ代表激活函数,![]() 代表当前模型的输入,
代表当前模型的输入,![]() 代表前一个序列模型的输出,
代表前一个序列模型的输出,![]() 所代表计算
所代表计算![]() 的权重,
的权重,![]() 代表计算it的偏置,
代表计算it的偏置,![]() 代表使用tanh所创建的新细胞状态,
代表使用tanh所创建的新细胞状态,![]() 代表计算
代表计算![]() 的权重,
的权重,![]() 代表计算
代表计算![]() 的偏置。
的偏置。
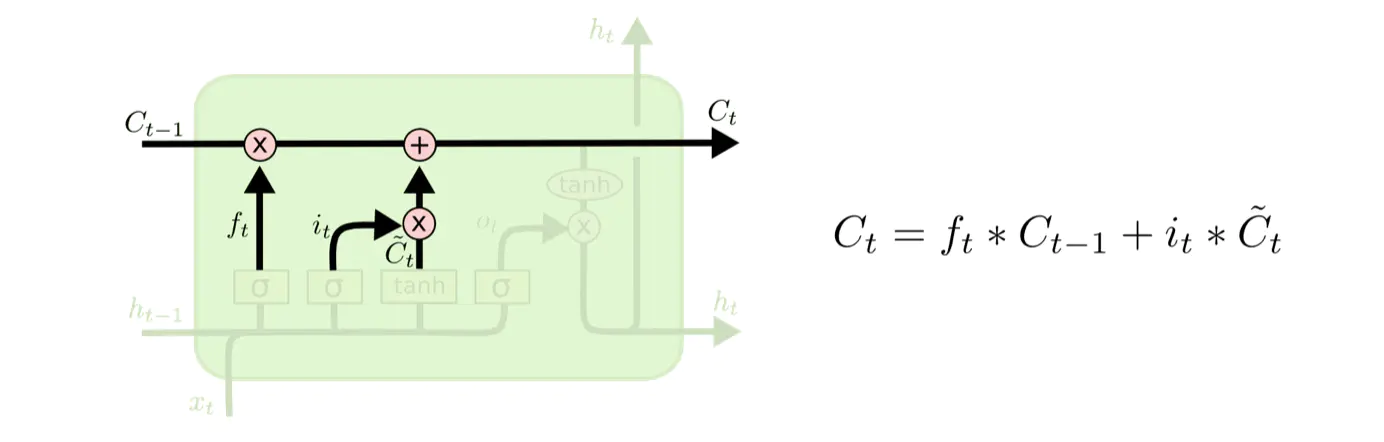
忘记门找到了需要忘掉的信息ft后,再将它与旧状态相乘,丢弃确定需要丢弃的信息。然后将结果加上![]() ×
×![]() 使细胞状态获得新的信息。这样就完成了细胞状态的更新,如图所示。
使细胞状态获得新的信息。这样就完成了细胞状态的更新,如图所示。
2、输入门更新在下图中,![]() 代表更新后的细胞状态,
代表更新后的细胞状态,![]() 代表忘记门的输出结果,
代表忘记门的输出结果,![]() 代表前一个序列模型的细胞状态,
代表前一个序列模型的细胞状态,![]() 代表要更新的细胞状态,
代表要更新的细胞状态,![]() 代表使用tanh所创建的新细胞状态。
代表使用tanh所创建的新细胞状态。
2.3.4 输出门
如图7-34所示,在输出中,通过一个激活函数层(实际使用的是Sigmoid激活函数)来确定哪个部分的信息将输出,接着把细胞状态通过tah进行处理(得到一个在-1~1的值),并将它和Sigmoid门的输出相乘,得出最终想要输出的那个部分,例如,在语言模型中,假设已经输入了一个代词,便会计算出需要输出一个与该代词相关的信息。
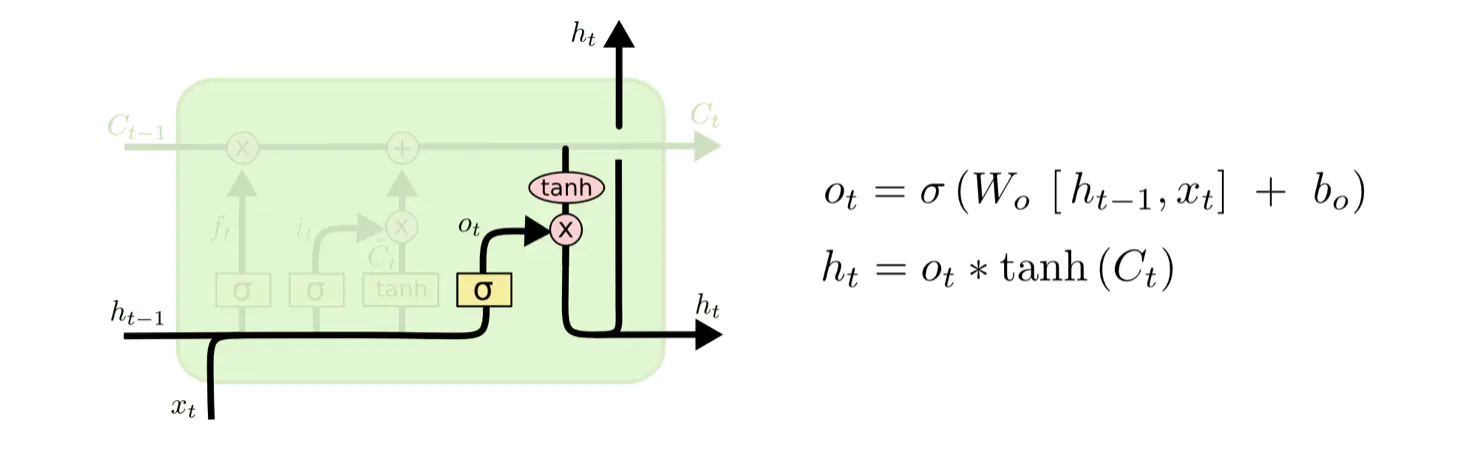
如图上,输出门在图7-34中,![]() 代表要输出的信息,σ代表激活函数,
代表要输出的信息,σ代表激活函数,![]() 代表计算
代表计算![]() 的权重,
的权重,![]() 代表计算
代表计算![]() 的偏置,
的偏置,![]() 代表更新后的细胞状态,
代表更新后的细胞状态,![]() 代表当前序列模型的输出结果。
代表当前序列模型的输出结果。
2.3 门控循环单元(GRU)
门控循环单元(Gated Recurrent Unit,GRU)是与LSTM功能几乎一样的另一个常用的网络结构,它将忘记门和输入门合成了一个单一的更新门,同时又将细胞状态和隐藏状态进行混合,以及一些其他的改动。最终的模型比标准的LSTM模型要简单。
当然,基于LSTM的变体不止GRU一个,经过测试发现,这些搭桥术类的Cell在性能和准确度上几乎没有什么差别,只是在具体的某些业务上会有略微不同。
由于GRU比LSTM少一个状态输出,但效果几乎与LSTM一样,因此在编码时使用GRU可以让代码更为简单一些。
2.4 只有忘记门的LSTM(JANET)单元
JANET(Just Another NETwork)单元也是LSTM单元的个变种,发布于2018年,实验表明,只有忘记门的网络的性能居然优于标准LSTM单元。同样,该优化方式他以被用在GRU中。
3 独立循环单元
独立循环单元是一种新的循环神经网络单元结构,其效果和速度均优于LSTM单元
IndRNN单元不但可以有效解决传统RNN模型存在的梯度消失和梯度“爆炸”问题,而且能够更好地学习样本中的长期依赖关系。
在搭建模型时:
- 可以用堆叠、残差、全连接的方式使用IndRNN单元,搭建更深的网络结构:
- 将IndRNN单元配合RLU等非饱和激活函数一起使用,会使模型表现出更好的鲁棒性。
3.1 原始的RNN模型结构

3.2 indRNN单元的结构

4 双向RNN结构
双向RNN又称Bi-RNN,是采用了两个方向的RNN模型。
RNN模型擅长的是对连续数据的处理,既然是连续的数据,那么模型不但可以学习它的正向特征,而且可以学习它的反向特征。这种将正向和反向结合的结构,会比单向的循环网络更高的拟合度。例如,预测一个语句中缺失的词语,则需要根据上下文来进行预测。
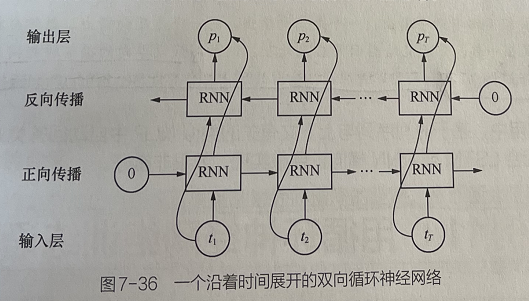
双向RNN的处理过程就是在正向传播的基础上再进行一次反向传播。正向传播和反向传播都连接着一个输出层。这个结构提供给输出层输入序列中每二个点的完整的过去和未来的上下文信息。图所示是一个沿着时间展开的双向循环神经网络。
双向RNN会比单向RNN多一个隐藏层,6个独特的权值在每一个时步被重复利用,6个权值分别对应:输入到向前和向后隐含层,隐含层到隐含层自身,向前和向后隐含层到输出层。
双向RNN在神经网络里的时序如图7-37所示。
在按照时间序列正向运算之后,网络又从时间的最后一项反向地运算一遍,即把时刻的输入与默认值0一起生戒反向的0u3,把反向ou3当成2时刻的输入与原来的时刻输人一起生成反向Qu2,依此类推,直到第一个时序数据
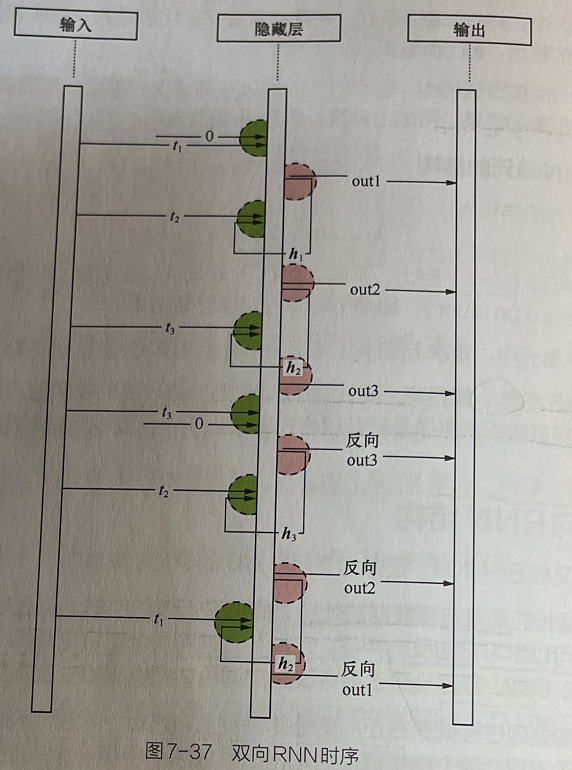
双向循环神经网络有两个输出:一个是正向输出,另一个是反向输出。最终会把输出结果通过concat并联在一起,然后交给后面的层来处理。
假设单向的循环神经网络输出的形状为[seq,batch,nhidden],则双向循环神经网络输出的形状就会交成[seq,batch,nhidden×2]
在大多数应用中,基于时间序列与上下文有关的类似NLP中自动回答类的问题,一般使用双向LSTM配合LSTM或RNN横向扩展来实现,效果非常好。