python+requests+BeautifulSoup实现对数据保存到mysql数据库
文章目录
-
- 前言
- 最终效果
- 下面开始正式教学!
- 思路分析
- 实现步骤
- 运行结果
- 以下是全部代码
前言
自己掌握python的一些知识后决定自己手动编写程序,就自己用Python编程实现scrape信息至MySQL数据库的过程整理了出来进行投稿,与大家一起分享,这里仅仅展视实现的过程,学会了这个,自己再去练习其他的就不成问题啦,好了下面进入正题

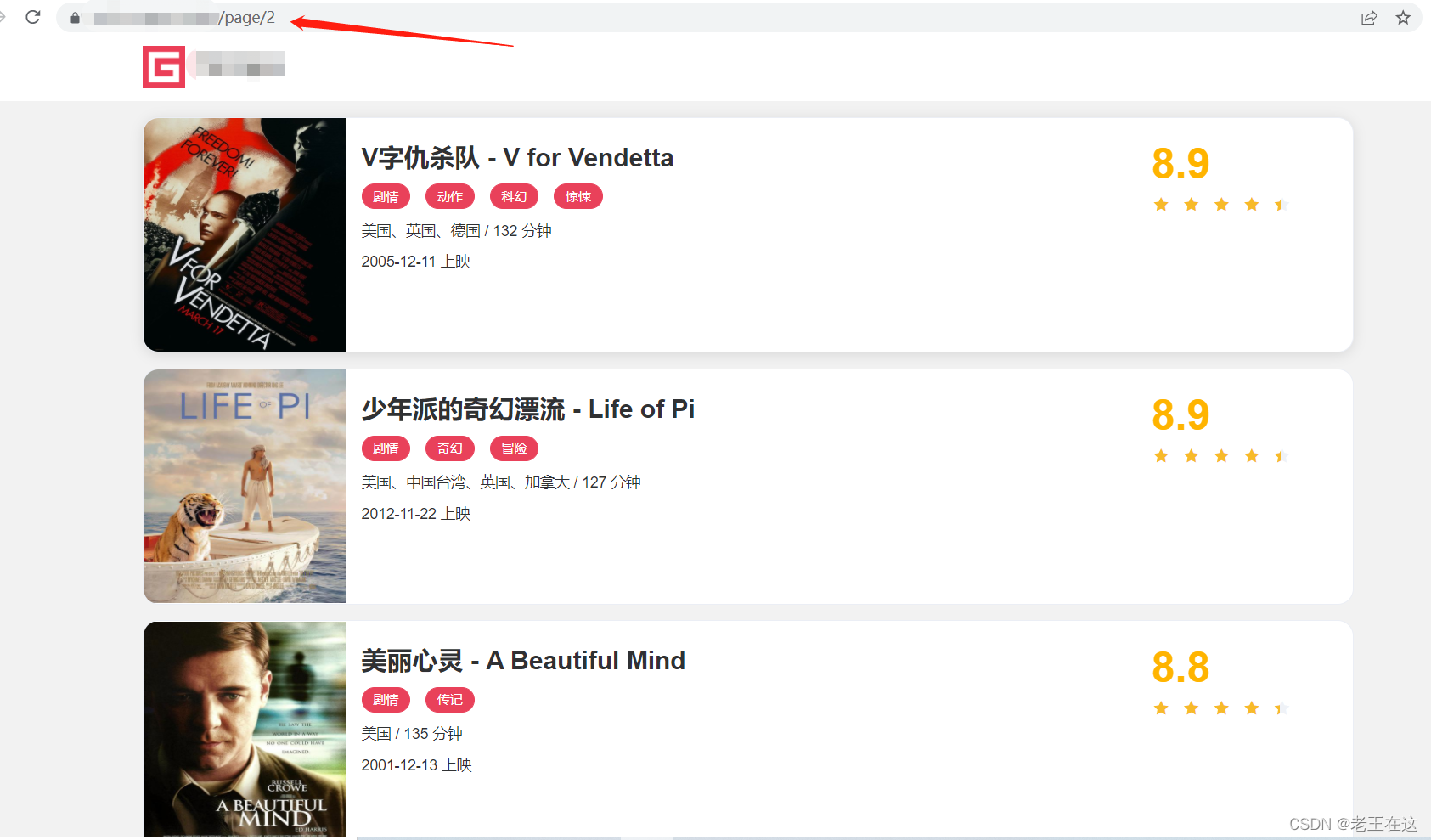
最终效果
展视一下最终效果(数据存储到了MySQL数据库中,和保存到Exel中)
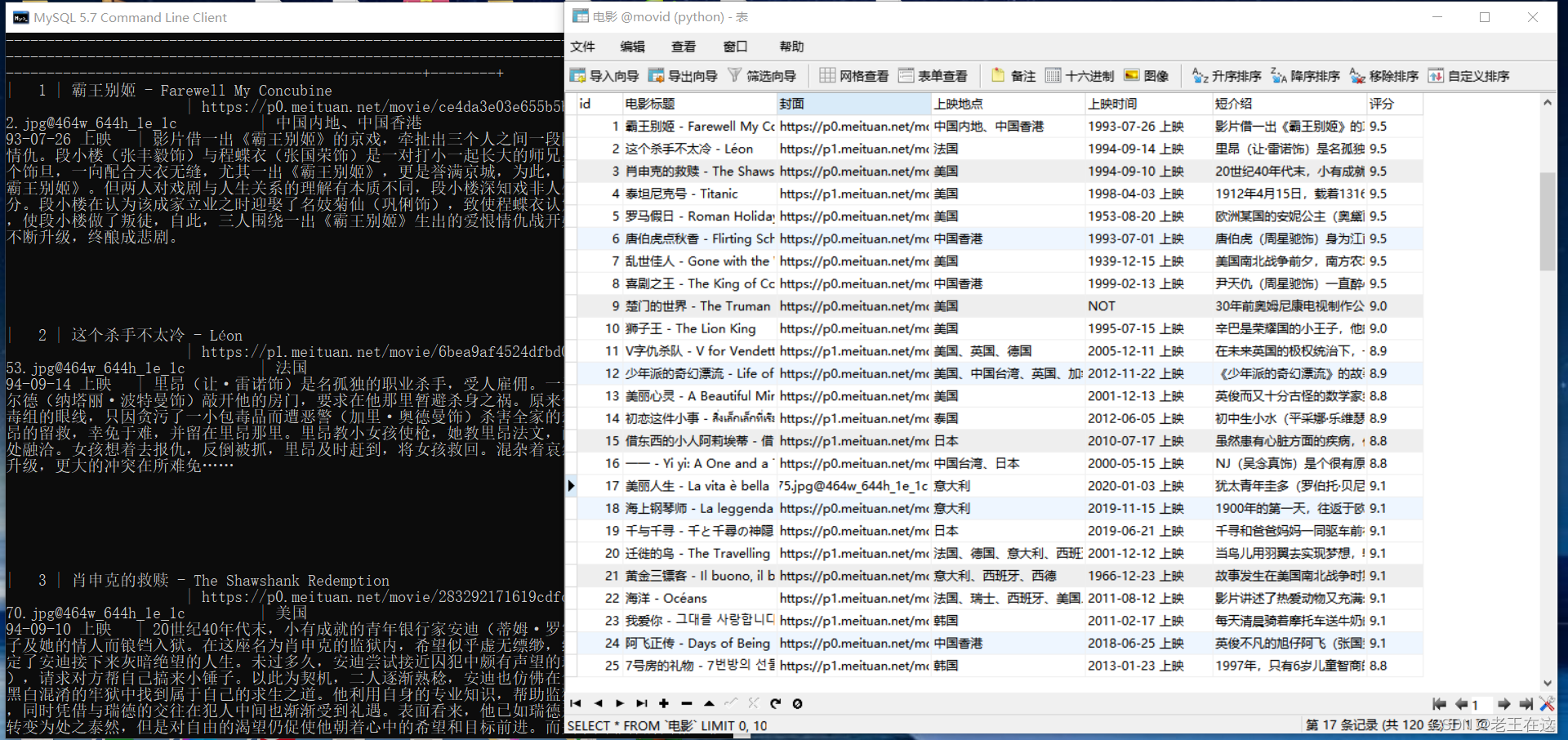
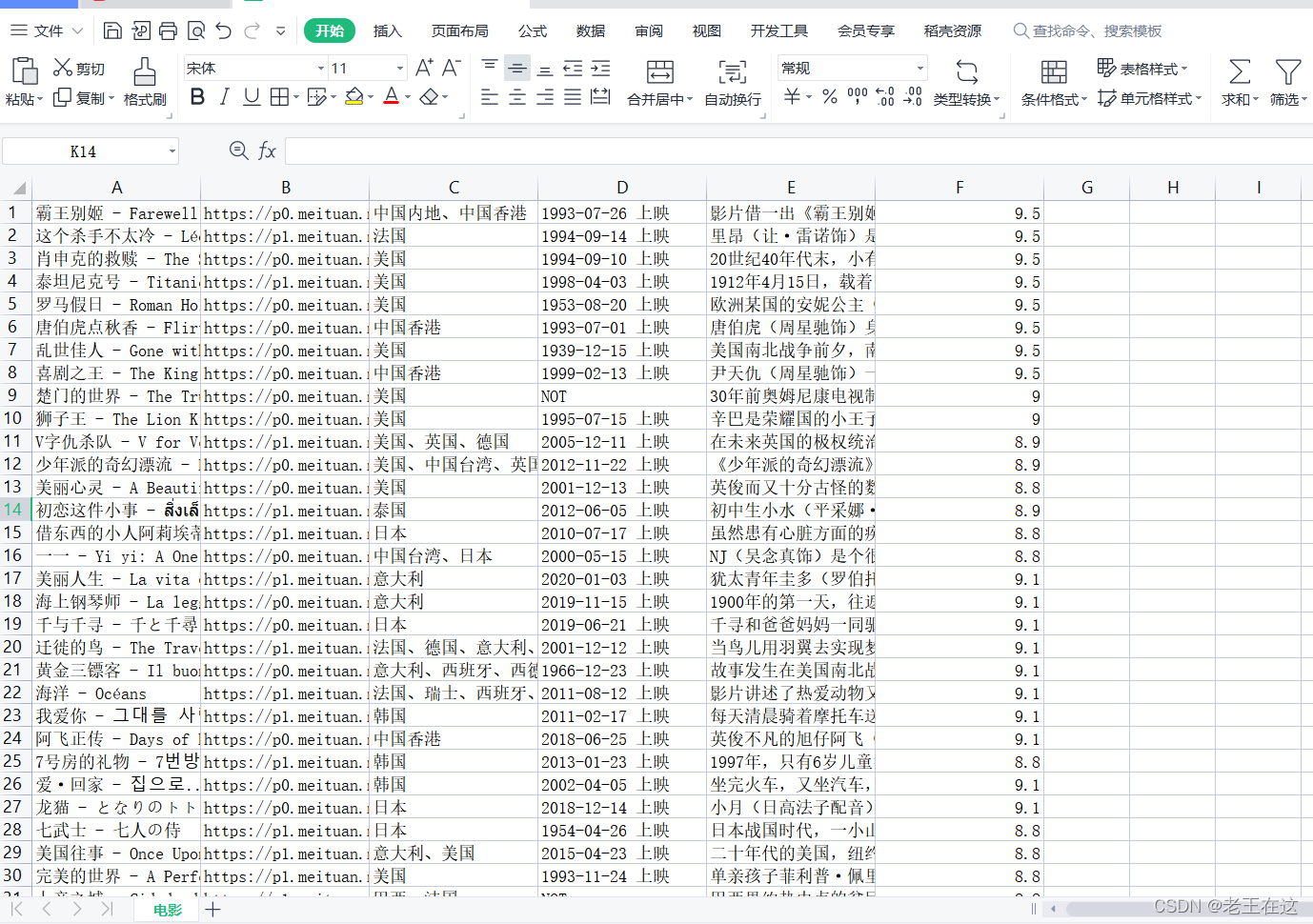
下面开始正式教学!
没有安装相关库的先安装库
版本:Python 3.8
工具:pycharm
相关库: requests,BeautifulSoup,pymysql
了解对象,设计流程
在使用操作之前,先花一定时间对对象进行了解,是非常有必要的,这样可以帮助我们科学合理地设计流程,以避开难点,节约时间,这个网址我们用普通方法进行实现即可。
打开网址,按下F12或者鼠标右键检查点击Elements找到全部的div,我们所需要的信息都在这些div里面。
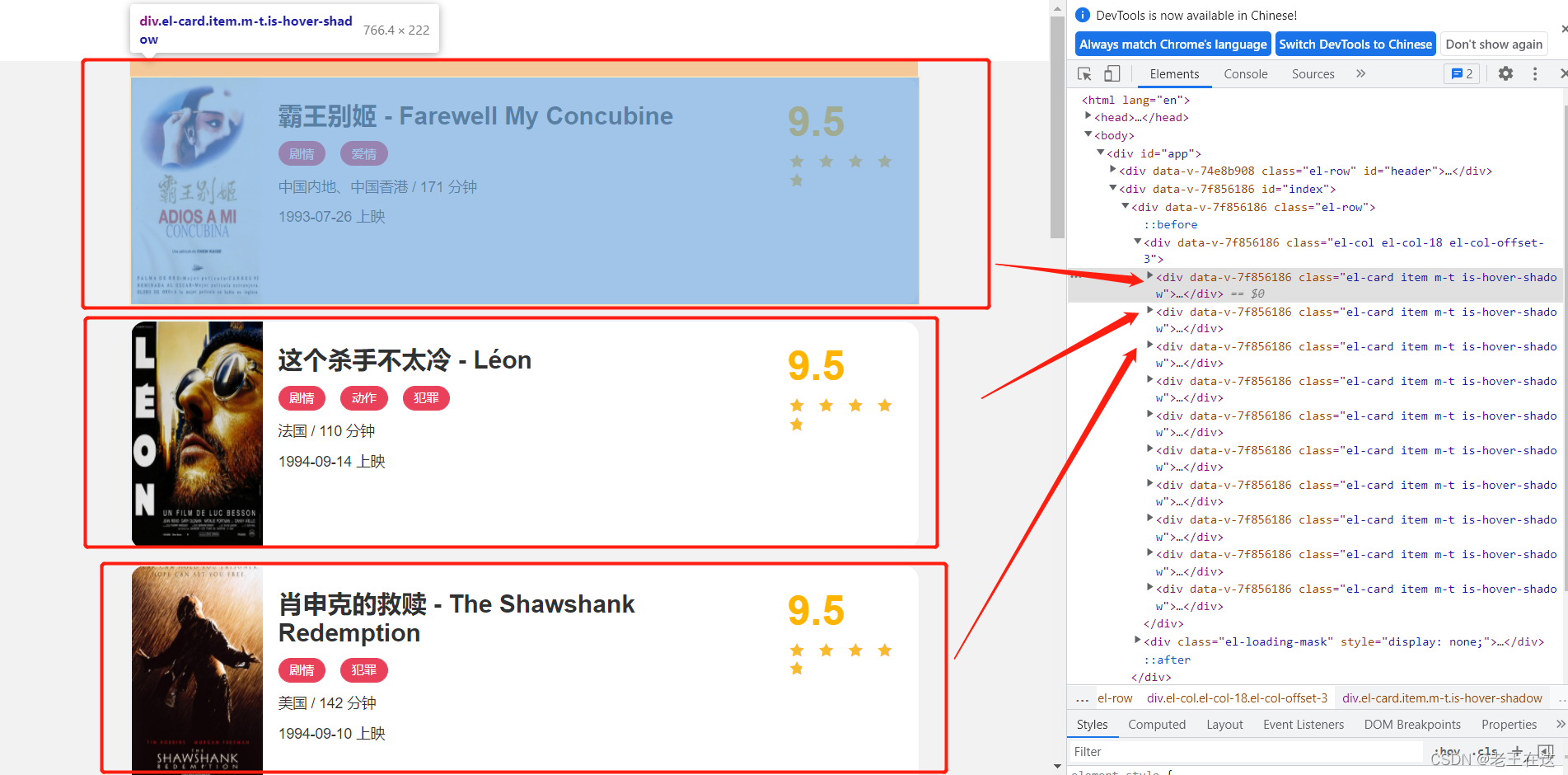
找到每个div再用,BeautifulSoup(解析库),对div里面需要的信息提取。
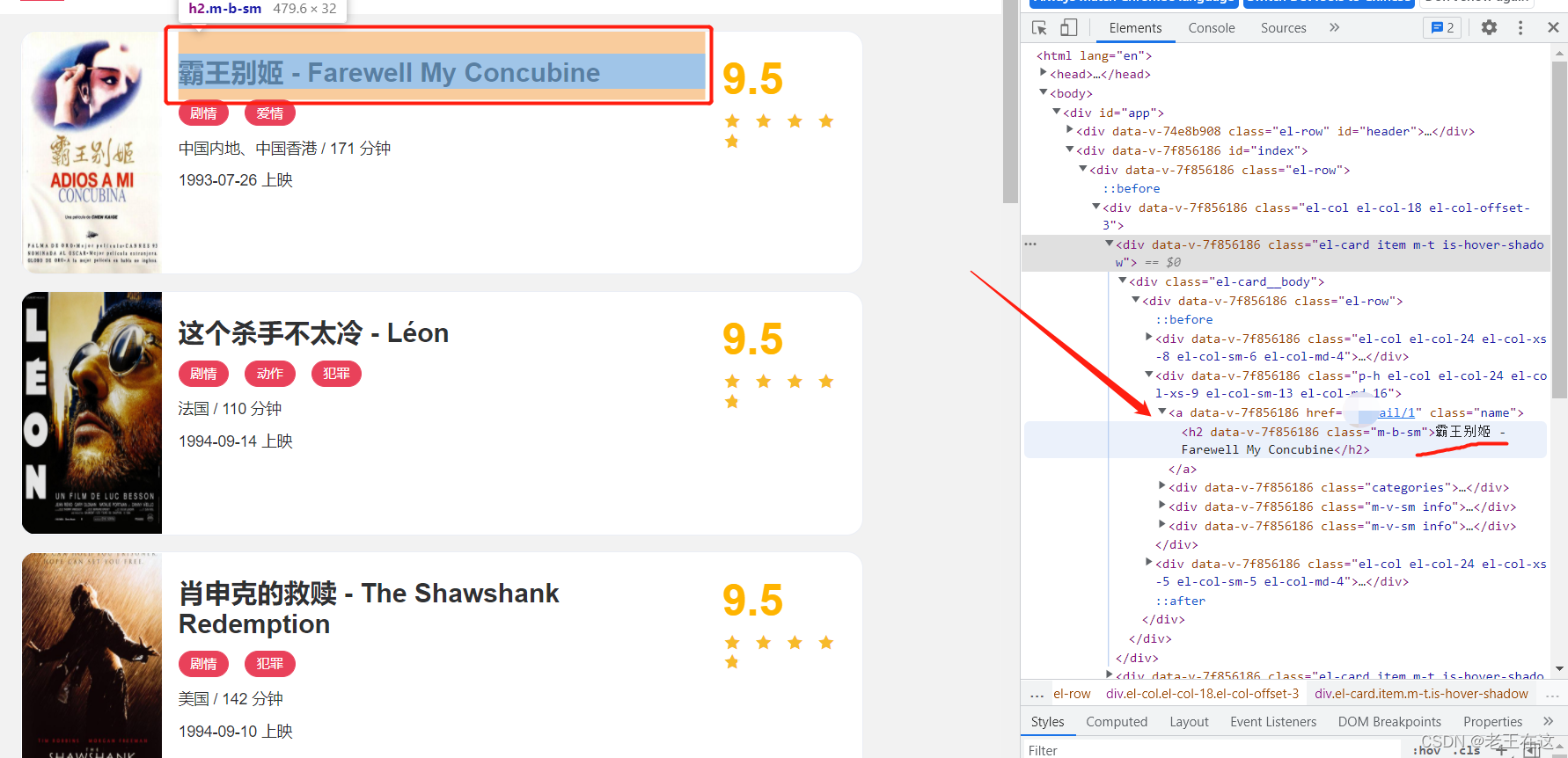
观察页面我们不难发现实现翻页的规律,只需循环改变数字即可。
page/2
page/3
page/4
思路分析
拿到每个div,用BeautifulSoup(解析库)对标题,详情页等信息进行提取,拿到详情页再对详情页进行字符串拼接,对详情页发起请求提取详情页信息等。

实现步骤
1.1 先打开MySQL创建一个数据库后面用来存储数据用到
建库相关语句
create database if not exists movid charset=utf8;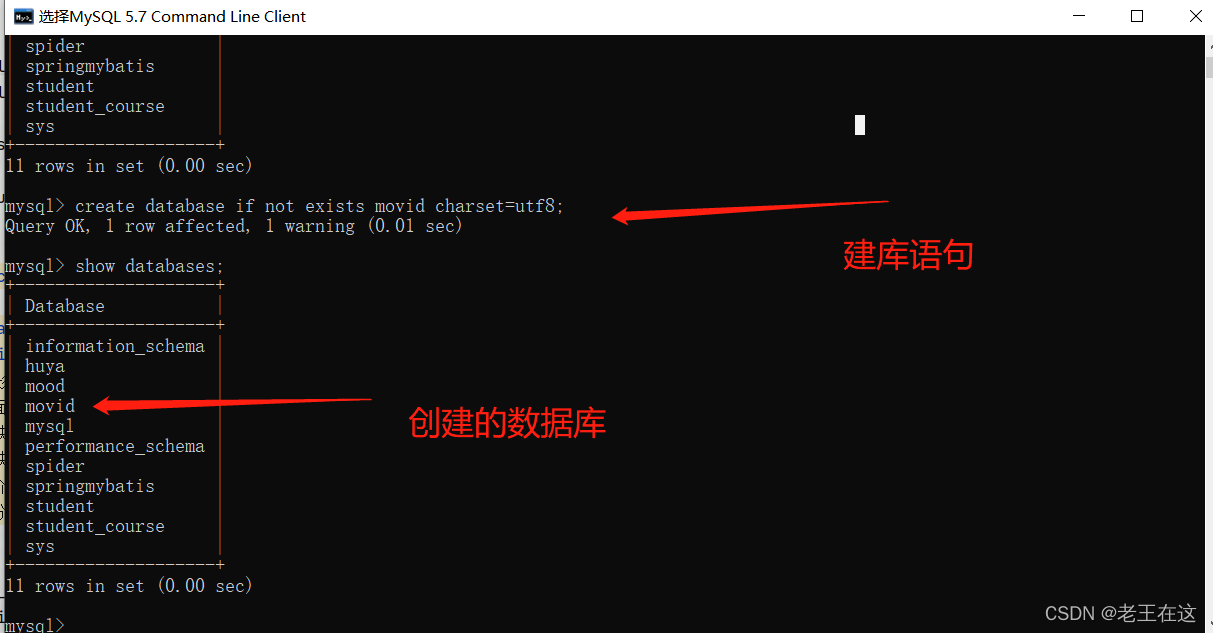
1.2 导入相关库,对网址发起请求,如果请求的请求的状态码等于200(成功访问)返回text文本,否则出现错误捕获异常。

1.3 请求成功后,定义空列表后面用来储存数据,用BeautifulSoup库实例化对象才能对内容进行提取,这里提取了标题和封面链接,详情页,由于详情页不是完整的还需要进行拼接,才能得到完整的详情页链接。

1.4 有详情页了就对详情页发起请求,实现提取详情页需要的信息(这里提取了地点,时间,简介,评分),接下来写一个字典存储提取到的内容,再把字典添加到列表中返回。

1.5 下图函数是实现对封面的保存

1.6 对数据进行保存至Exel

1.7 最后就是把保存数据到MySQL数据库中,在函数里写好连接MySQL的语句,创建游标对象,创建库(由于数据库我们一开头就创建有了,这里的创建数据库sql语句有也可以,没有可以),创建表添加字段,数据类型,约束。(password是MySQL登录密码,我这的密码是111111)

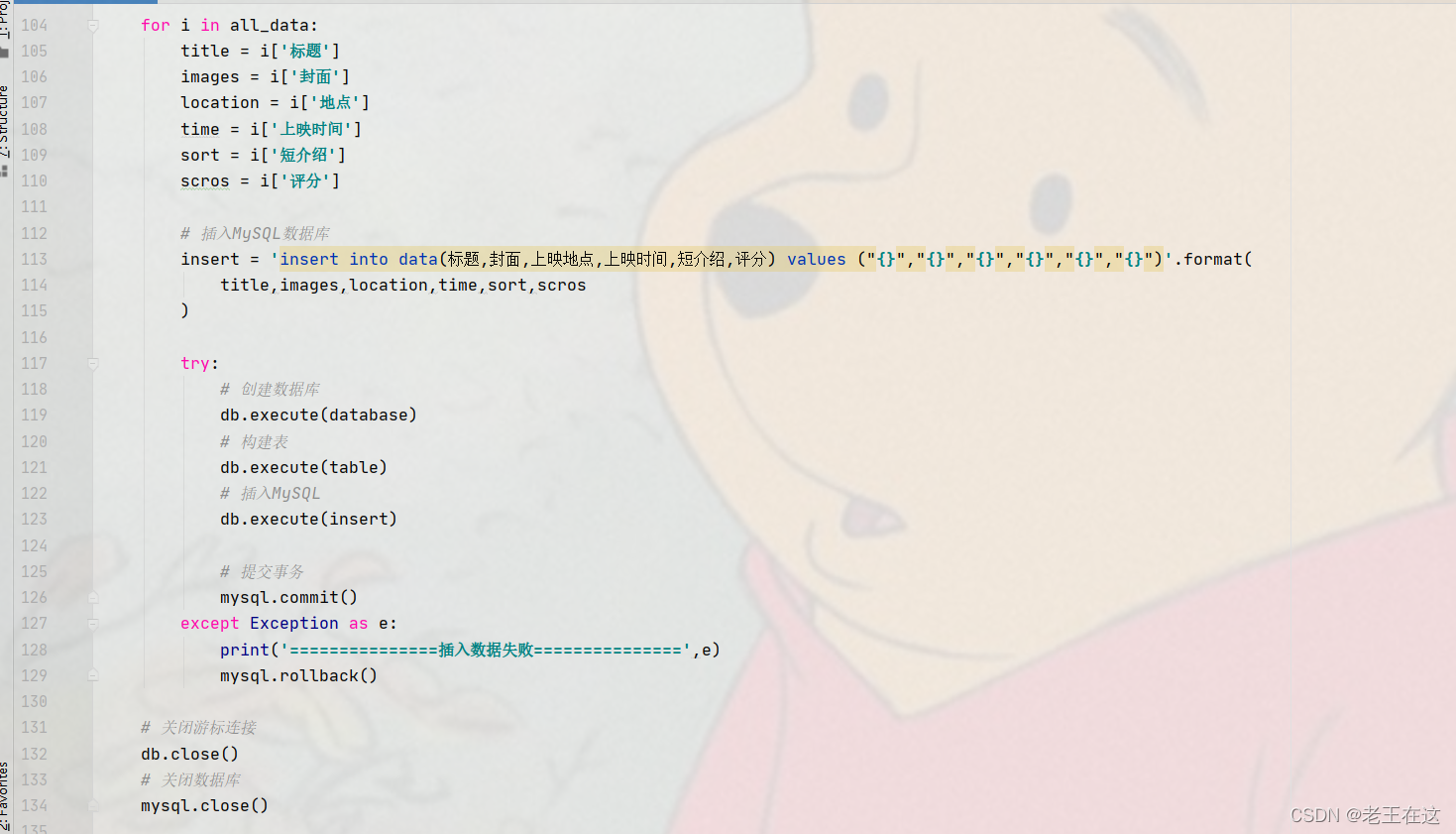
1.8 因为我们的数据在列表中,因此对列表遍历得到字典,再用键的方式取字典里面的值。
编写插入数据库的sql语句,交给游标去执行。
翻页实现
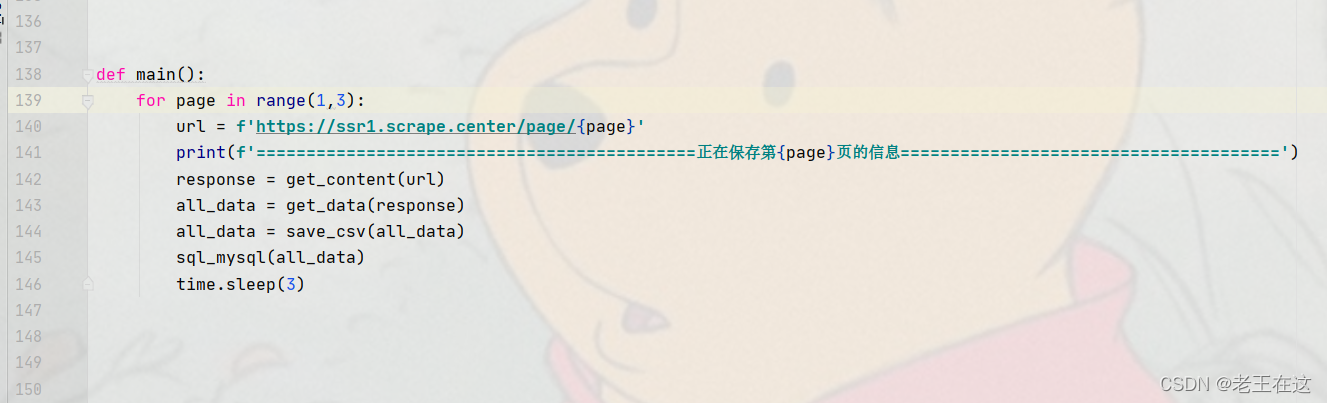
运行结果
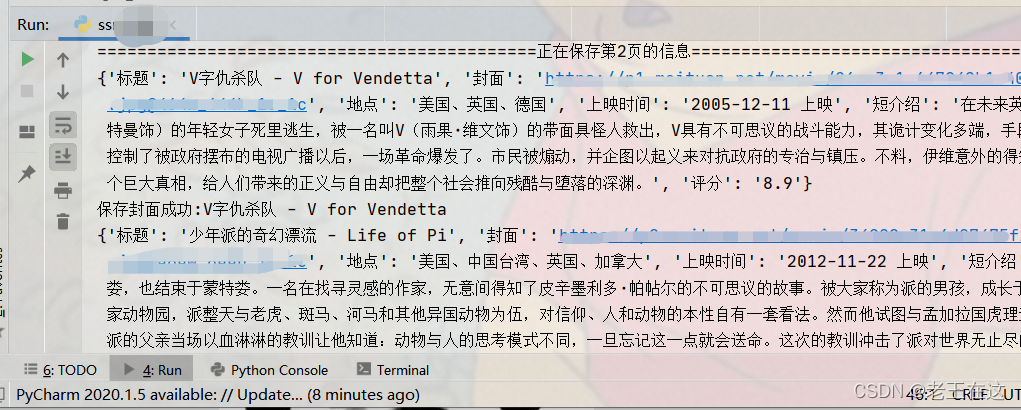
到这里程序就完成了,运行代码时注意保持网络畅通,如果网速太慢可能会失败,或者会出现请求过多被限制请求。

以下是全部代码
from bs4 import BeautifulSoup # 内容解析import requests # 发起请求import pandas as pd # 数据处理from fake_useragent import UserAgent # 伪造头import os.pathimport timeimport pymysql # MySQL操作import multiprocessing # 多进程def get_content(url): ua = UserAgent() headers = {'user-agent': ua.random} try: response = requests.get(url,headers=headers) if response.status_code == 200: return response.text except Exception as e: print('出现错误:',e)def get_data(response): all_data = [] # 空列表 # 实例化 soup = BeautifulSoup(response,'lxml') # 全部div all_div = soup.find_all(class_="el-card item m-t is-hover-shadow") for i in all_div: title = i.find(class_="m-b-sm").text images = i.find('a').find('img').get('src') # 详情页 details = 'https://ssr1.scrape.center' + i.find('a').get('href') # 请求详情页 driver = requests.get(details).text # 实例化 new_soup = BeautifulSoup(driver,'lxml') lacation = new_soup.find_all(class_="m-v-sm info")[0].find('span').text # 地区 try: time = new_soup.find_all(class_="m-v-sm info")[1].find('span').text # 上映时间 except: time = 'NOT' sort = new_soup.find(class_="drama").find('p').text.replace('\n','').replace(' ','') # 简介 scros = new_soup.find(class_="el-col el-col-24 el-col-xs-8 el-col-sm-4").find('p').text.replace(' ','').replace('\n','') # 评分 item = { '标题': title, '封面': images, '地点': lacation, '上映时间': time, '短介绍': sort, '评分': scros } print(item) all_data.append(item) # 空列表末尾增添字典 save_images(title,images) # 调用函数对封面进行保存 return all_data #返回值 返回列表def save_images(title,images): # 创建文件夹 if not os.path.exists('./ssrl/'): os.mkdir('./ssrl/') resp = requests.get(url=images).content with open('./ssrl/' + title + '.jpg',mode='wb')as f: f.write(resp) print('保存封面成功:'+title)def save_csv(all_data): # 表头 headers = ['标题','封面','地点','上映时间','短介绍','评分'] filt = pd.DataFrame(all_data) filt.to_csv('ssrl.csv',mode='a+',header=False,encoding='utf-8',index=False) return all_datadef sql_mysql(all_data): # 连接MySQL mysql = pymysql.connect(host='localhost',user='root',password='111111',port=3306,charset='utf8',database='movid') # 创建游标对象 db = mysql.cursor() # 创建数据库 database = 'create database if not exists movid charset=utf8;' # 创建表 table = 'create table if not exists data(' \ 'id int not null primary key auto_increment' \ ',标题 varchar(250)' \ ',封面 varchar(250)' \ ',上映地点 varchar(250)' \ ',上映时间 varchar(250)' \ ',短介绍 varchar(5000)' \ ',评分 varchar(250)' \ ');' for i in all_data: title = i['标题'] images = i['封面'] location = i['地点'] time = i['上映时间'] sort = i['短介绍'] scros = i['评分'] # 插入MySQL数据库 insert = 'insert into data(标题,封面,上映地点,上映时间,短介绍,评分) values ("{}","{}","{}","{}","{}","{}")'.format( title,images,location,time,sort,scros ) try: # 创建数据库 db.execute(database) # 构建表 db.execute(table) # 插入MySQL db.execute(insert) # 提交事务 mysql.commit() except Exception as e: print('===============插入数据失败===============',e) mysql.rollback() # 关闭游标连接 db.close() # 关闭数据库 mysql.close()def main(): for page in range(1,3): url = f'https://ssr1.scrape.center/page/{page}' print(f'============================================正在保存第{page}页的信息======================================') response = get_content(url) all_data = get_data(response) all_data = save_csv(all_data) sql_mysql(all_data) time.sleep(3)if __name__ == '__main__': muti = multiprocessing.Process(target=main) muti.start()