Nginx与TCP协议的关系
作为Web服务器的nginx,主要任务当然是处理好基于TCP的HTTP协议,本节将深入TCP协议的实现细节(linux下)以更好地理解Nginx事件处理机制。
TCP是一个面向连接的协议,它必须基于建立好的TCP连接来为通信的两方提供可靠的字节流服务。建立TCP连接是我们耳熟能详的三次握手:
- 客户端向服务器发起连接(SYN)。
- 服务器确认收到并向客户端也发起连接(ACK+SYN)。
- 客户端确认收到服务器发起的连接(ACK)。
这个建立连接的过程是在操作系统内核中完成的,而如Nginx这样的应用程序只是从内核中取出已经建立好的TCP连接。大多时候,Nginx是作为连接的服务器方存在的,我们看一看Linux内核是怎样处理TCP连接建立的,如图1所示。

图1简单地表达了一个观点:内核在我们调用listen方法时,就已经为这个监听端口建立了SYN队列和ACCEPT队列,当客户端使用connect方法向服务器发起TCP连接,随后图中1.1步骤客户端的SYN包到达了服务器后,内核会把这一信息放到SYN队列(即未完成握手队列)中,同时回一个SYN+ACK包给客户端。2.1步骤中客户端再次发来了针对服务器SYN包的ACK网络分组时,内核会把连接从SYN队列中取出,再把这个连接放到ACCEPT队列(即已完成握手队列)中。而服务器在第3步调用accept方法建立连接时,其实就是直接从ACCEPT队列中取出已经建好的连接而已。
这样,如果大量连接同时到来,而应用程序不能及时地调用accept方法,就会导致以上两个队列满(ACCEPT队列满,进而也会导致SYN队列满),从而导致连接无法建立。这其实很常见,比如Nginx的每个worker进程都负责调用accept方法,如果一个Nginx模块在处理请求时长时间陷入了某个方法的执行中(如执行计算或者等待IO),就有可能导致新连接无法建立。
建立好连接后,TCP提供了可靠的字节流服务。怎么理解所谓的“可靠”呢?可以简单概括为以下4点:
- TCP的send方法可以发送任意大的长度,但数据链路层不会允许一个报文太大的,当报文长度超过MTU大小时,它一定会把超大的报文切成小报文。这样的场景是不被TCP接受的,切分报文段既然不可避免,那么就只能发生在TCP协议内部,这才是最有效率的。
- 每一个报文在发出后都必须收到“回执”———ACK,确保对方收到,否则会在超时时达到后重发。相对的,接收到一个报文时也必须发送一个ACK告诉对方。
- 报文在网络中传输时会失序,TCP接收端需要重新排序失序的报文,组合成发送时原序再给到应用程序。当然,重复的报文也要丢弃。
- 当连接的两端处理速度不一致时,为防止TCP缓冲区溢出,还要有个流量控制,减速度更快一方的发送速度。
从以上4点可以看到,内核为每一个TCP连接都分配了内存分别充当发送、接收缓冲这与Nginx这种应用程序中的用户态缓存不同。搞清楚内核的TCP读写缓存区,对于我们断Nginx的处理能力很有帮助,毕竟无论内核还是应用程序都在抢物理内存。
先来看看调用send这样的方法发送TCP字节流时,内核到底做了哪些事。下图2是一个简的send方法调用时的流程示意图。
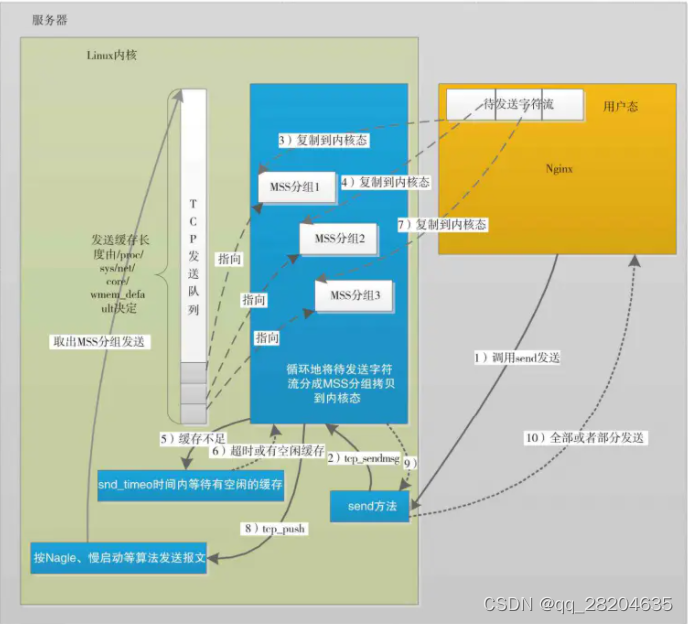
TCP连接建立时,就可以判断出双方的网络间最适宜的、不会被再次切分的报文大小,TCP层把它叫做MSS最大报文段长度(当然,MSS是可变的)。在图2的场景中,假定待发送的内存将按照MSS被切分为3个报文,应用程序在第1步调用send方法、第10步send方法返回之间,内核的主要任务是把用户态的内存内容拷贝到内核态的TCP缓冲区上,在第5步时假定内核缓存区暂时不足,在超时时间内又等到了足够的空闲空间。从图中可以看到,send方法成功返回并不等于就把报文发送出去了(当然更不等于对方接收到了报文)。
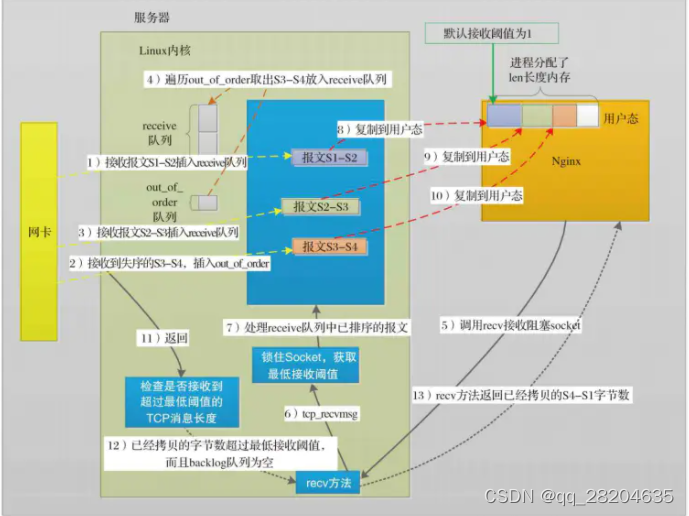
当调用recv这样的方法接收报文时,Nginx是基于事件驱动的,也就是说只有epoll通知worker进程收到了网络报文,recv才会被调用(socket也被设为非阻塞模式〉。图3就是一个这样的场景,在第1~4步表示接收到了无序的报文后,内核是怎样重新排序的。第5步开始,应用程序调用了recv方法,内核开始把TCP读缓冲区的内容拷贝到应用程序的用户态内存中,第13步recv方法返回拷贝的字节数。图中用到了linux内核中为TCP准备的2个队列:receive队列是允许用户进程直接读取的,它是将已经接收到的TCP报文,去除了TCP头部、排好序放入的、用户进程可以直接按序读取的队列; out_of_order队列存放乱序的报文。
回过头来看,Nginx使用好TCP协议主要在于如何有效率地使用CPU和内存。只在必要时才调用TCP的sendrecv方法,这样就避免了无谓的CPU浪费。例如,只有接收到报文,甚至只有接收到足够多的报文(SO_RCVLOWAT阙值〉,worker进程才有可能调用recv方法。同样,只在发送缓冲区有空闲空间时才去调用send方法。这样的调用才是有效率的。Nginx对内存的分配是很节俭的,但Linux内核使用的内存又如何控制呢?
首先,我们可以控制内存缓存的上限,例如基于setsockopt方法实现的SO_SNDBUF、SO_RCVBUF (Nginx的listen配置里的sndbuf和rcvbuf也是在改它们)。
So_SNDBUF表示这个连接上的内核写缓存上限(事实上SO_SNDBUF也并不是精确的上限,在内核中会把这个值翻一倍再作为写缓存上限使用)。它受制于系统级配置的上下限net.core.wmem_max()。SO_RCVBUF同理。读写缓存的实际内存大小与场景有关。对读缓存来说,接收到一个来自连接对端的TCP报文时,会导致读缓存增加,如果超过了读缓存上限,那么这个报文会被丢弃。当进程调用read、recv这样的方法读取字节流时,读缓存就会减少。因此,读缓存是一个动态变化的、实际用到多少才分配多少的缓冲内存。当用户进程调用send方法发送TCP字节流时,就会造成写缓存增大。当然,如果写缓存已经到达上限,那么写缓存维持不变,向用户进程返回失败。而每当接收到连接对端发来的ACK,确认了报文的成功发送时,写缓存就会减少。可见缓存上限所起作用为:丢弃新报文,防止这个TCP连接消耗太多的内存。