数据库相关概念与编程使用方式
数据库相关概念与编程使用方式
作者: 李俊才
邮箱 :291148484@163.com
CSDN主页(jcLee95):https://blog.csdn.net/qq_28550263?spm=1001.2101.3001.5343
目 录
1. 数据库基本术语
- 1.1 数据库(DB)
- 1.2. 数据库管理系统(DBMS)
- 1.3. 数据库系统(DBS)
- 1.4. 数据库技术
2. 数据库的常见分类
3. 概念设计中的数据描述
- 3.1 实体(entity)
- 3.2 实体集(entity set)
- 3.3 属性(attribute)
- 3.4 实体标识符(identifier)| 键/关键码(key)
4. 逻辑设计中的数据描述
- 4.1 字段(field)| 数据项
- 4.2 记录(record)
- 4.3 文件(file)
- 4.4 关键码(key)
- 4.5
概念设计与逻辑设计中术语的对应关系 - 4.6 一个例子
- 4.7 使用UML 类图描述数据关系
5. 数据联系的描述
- 5.1 一对一联系
- 5.2 一对多联系
- 5.3 多对多联系
6. 游标
- 6.1 游标的概念
- 6.2 使用PyMySQL
- 6.2.1 PyMySQL 安装
- 6.2.2 简单入门
- 6.2.3 PyMySQL连接对象
- 6.2.4 PyMySQL游标对象
7. 面向对象编程 与 对象关系映射(ORM)简介
8. 使用基于Python Django 中的 ORM 框架
- 8.1 预准备工作
- 8.2 建立Django数据模型
- 8.3 通过 Django ORM方式 添加数据
- 8.4 通过 Django ORM方式 查询数据
- 8.4.1 快速上手示例
- 8.4.2 区分查询条件
get和filter的不同
8.5 通过 Django ORM方式 删除数据
1. 数据库基本术语

1.1 数据库(DB)
是一个长期存储在计算机内的、有组织的、可共享的、统一管理的大量数据的集合。它能为各种用户共享,具有较小冗余度,数据间联系紧密而又有较高的数据独立性的特点。
1.2. 数据库管理系统(DBMS)
是位于用户(User)与操作系统(Operation System, OS)之间的一层数据库管理软件。

它为用户或者其它应用程序提供访问数据库(DB)的方法,包括DB的建立、查询、更新以及各种数据控制。
1.3. 数据库系统(DBS)
是实现有组织动态地存储大量关联数据,方便多用户访问的计算机软硬件和数据库资源组成的系统。也就是说,数据库系统是采用数据库技术的计算机系统。
1.4. 数据库技术
是研究数据的结构、存储、设计、管理和使用的一门软件学科。
2. 数据库的常见分类

3. 概念设计中的数据描述

3.1 实体(entity)
实体值得是客观存在的、可以相互区别的事务;- 实体可以是具体的
对象(object),如一辆汽车、一只大雁等等; - 实体也可以是抽象的对象,例如一场比赛,一次聚会等。
3.2 实体集(entity set)
实体集是 性质相同的、同类实体的 集合;- 例如,一群大雁是以大雁为实体的实体集。
3.3 属性(attribute)
- 实体有很多特性,每一个特性称之为
属性,即属性值得是实体的某一个特性; - 每个属性都有一个值域,其类型可以是 整数形、实数型、字符串型,以及我们通过一定方式定义的其它类型;
- 现实中上看,属性是我们描述或者认识一个实体的具体角度,而描述一个实体可以用到的角度方方面面,是不可能面面俱到的。因此在设计时我们需要有选择性的使用对我们的项目有价值的属性来表征某个实体。
3.4 实体标识符(identifier)| 键/关键码(key)
- 实体标识符(identifier)也称之为键(key)或者关键码;
- 实体标识符 用于唯一标识实体的属性或者属性集;
- 例如, 在一个国家中公民的身份证号码可以用来作为某一个公民的标识符。
4. 逻辑设计中的数据描述

4.1 字段(field)| 数据项
- 标记实体属性的 命名单位 成为
字段或者数据项; - 它可以是命名的最小信息单位,所以又称为
数据元素或者初等项。
4.2 记录(record)
记录是 字段的有序集合;- 记录 是 能完整地描述一个实体的字段集;
- 一般我们用一个记录描述一个实体;
- 例如,某一辆汽车的记录,包含“颜色”、“品牌”、“车系”、“生产年份”这几个字段;
- 记录所包含的字段是我们在设计时依据项目需求人为设计的。
4.3 文件(file)
文件,是同一类记录集合;- 文件是用来描述实体的;
- 例如所有的 汽车记录 组成了一个 汽车文件。
4.4 关键码(key)
关键码(key) 用于唯一标识文件中每个记录的字段或者字段集。
4.5 概念设计 与 逻辑设计中术语的对应关系
| 概念设计中的数据描述 | 逻辑设计中的数据描述 |
|---|---|
| 实体 | 记录 |
| 实体集 | 文件 |
| 属性 | 字段(数据项) |
| 实体标识符 | 关键码 |
4.6 一个例子

| id | 品牌 | 型号 | 类别 | 颜色 | 生产年份 | 人气值 | 报价 |
|---|---|---|---|---|---|---|---|
| 1 | 兰博基尼 | LP770-4 | 超跑 | 黑色 | 2016 | 95 | 700W |
| 2 | 兰博基尼 | LP770-4 | 超跑 | 黄色 | 2017 | 98 | 730W |
| 这里有2条关于兰博基尼的记录的表,每个记录都有8个字段,分别是id、品牌、型号、类别、颜色、生产年份、人气值、报价他们所分别对应的列。这些字段从自己的角度描画了该条记录在某一个方面的属性,这个表就是一个同一类记录的集合即文件。而各列的标识字符串,如“品牌”、“型号”等等,用来唯一标识每条记录的字段,即关键码。 |
4.7 使用UML 类图描述数据关系
5. 数据联系的描述

【联系】(relationship):指的是 实体 之间的相互关系。
- 与一个联系有关的实体集个数称为联系的
元数; - 以联系的元数作为划分课将联系分为一元联系、二元联系、三元联系等等。
- 其中二元联系有
一对一联系、一对多联系、多对多联系,分别介绍如下:
5.1 一对一联系
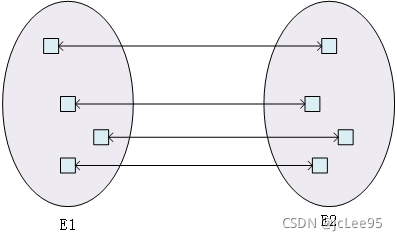
两个实体集E1和E2,它们中各自的任意一个实体对对方实体集中的有且仅有一个实体有联系。这种二元联系即“一对一联系”。
5.2 一对多联系

两个实体集E1和E2,如果E1中的一个实体与E2中的任意多个实体有联系,但E2中的实体之多只与E1中的一个实体有联系,这种二元联系即“一对多联系”。
5.3 多对多联系

两个实体集E1和E2,如果E1中的一个实体与E2中的任意多个实体有联系,同样E2中的一个实体与E1中的任意多个实体有联系,这种二元联系即“多对多联系”。
6. 游标
6.1 游标的概念
- 按照某种查询某数据库管理系统后返回的完整记录集称为结果集,比如使用SQL中的SELECT语句查询关系型数据库返回的记录集。
- 应用程序查询数据库时,往往并不将整个结果集作为一个单元来有效处理,这些应用程序需要一种机制每一次处理其中的一部分记录。
游标就是提供这种机制的载体,它是对结果集的一种扩展方案。其特点如下:- 允许定位结果集的特定行;
- 从结果集的当前位置检索一条记录或一部分记录;
- 支持对结果集中当前位置的行进记录修改;
- 为有其它用户对显示在结果集中的数据库数据所做的更改提供不同级别的可见性支持;
- 提供脚本、存储过程和触发器中用于访问结果集中的数据的SQL语句(对于支持SQL的数据库管理系统);
- 可以执行多个不相关的操作;
- 可以提供脚本的可读性;
- 可以建立命令字符串,可以传送表名,或者把变量传送到参数中,以便建立可执行的命令字符串。
6.2 使用PyMySQL
6.2.1 PyMySQL 安装
pip install pymysql6.2.2 简单入门
首先,创建名为’users’表的SQL语句如下:
create table `users` ( `id` int(11) NOT NULL auto_increment, `email` varchar(255) collate utf8_bin not null, `password` varchar(255) collate utf8_bin not null, primary key(`id`)) engine=InnoDB default charset=utf8 collate = utf8_binauto_increment=1;import pymysql# 连接到该数据库connection = pymysql.connect(host = 'localhost', # 指定主机名 user = 'user',# 指定用户名 password = 'passwd', # 指定用户密码 db = 'db', # 指定数据库名称 charset = 'utf8mb4', # 指定字符编码方式 cursorclass = pymysql.cursors.DictCursor)try: with connection.cursor() as cursor: # cursor()方法用于创建一个游标对象 # 创建一条新记录 sql = "INSERT INTO `users` (`email`, `password`) VALUES (%s, %s)" # SQL语句字符串(这是一个模板字符串) cursor.execute(sql, ('webmaster@python.org', 'very-secret'))# 通过打开一个游标查询 # execute()方法用于只从SQL查询 connection.commit() # 默认情况下,连接不会自动提交。所以你必须提交保存你的更改 with connection.cursor() as cursor: # 读取一条记录 sql = "SELECT `id`, `password` FROM `users` WHERE `email`=%s" # SQL语句字符串 cursor.execute(sql, ('webmaster@python.org',)) result = cursor.fetchone() # 返回的是一个json格式字符串 print(result)finally: connection.close()6.2.3 PyMySQL连接对象
class pymysql.connections.Connection(host=None, user=None, password='', database=None, port=0, unix_socket=None, charset='', sql_mode=None, read_default_file=None, conv=None, use_unicode=None, client_flag=0, cursorclass=<class 'pymysql.cursors.Cursor'>, init_command=None, connect_timeout=10, ssl=None, read_default_group=None, compress=None, named_pipe=None, autocommit=False, db=None, passwd=None, local_infile=False, max_allowed_packet=16777216, defer_connect=False, auth_plugin_map=None, read_timeout=None, write_timeout=None, bind_address=None, binary_prefix=False, program_name=None, server_public_key=None)- 带有mysql服务器的套接字的表示。
- 获取此类实例的正确方法是调用connect()。
- 建立与MySQL数据库的连接。
参数:
- host – 数据库服务器所在的主机
- user – 以以下身份登录的用户名
- password – 使用的密码。
- database – 要使用的数据库,无则不使用特定的数据库。
- port – 要使用的MySQL端口,默认通常是可以的。(预设值:3306)
- bind_address – 当客户端具有多个网络接口时,请指定从中连接到主机的接口。参数可以是主机名或IP地址。
- unix_socket – (可选)您可以使用unix套接字而不是TCP / IP。
- read_timeout – 从连接读取的超时(以秒为单位)(默认值:无-无超时)
- write_timeout – 写入连接的超时时间(以秒为单位)(默认值:无-无超时)
- charset – 您要使用的字符集。
- sql_mode – 要使用的默认SQL_MODE。
- read_default_file – 指定my.cnf文件以从[client]部分下读取这些参数。
- conv – 要使用的转换字典,而不是默认字典。这用于提供类型的自定义编组和解组。请参阅转换器。
- use_unicode – 是否默认为unicode字符串。对于Py3k,此选项默认为true。
- client_flag – 发送到MySQL的自定义标志。在常量中找到潜在值。
- cursorclass – 要使用的自定义光标类。
- init_command – 建立连接时要运行的初始SQL语句。
- connect_timeout – 连接时引发异常之前的超时。(默认值:10,最小值:1,最大值:31536000)
- ssl – 类似于mysql_ssl_set()参数的参数字典。
- read_default_group – 要从配置文件中读取的组。
- compress – (压缩)不支持
- named_pipe – 不支持
- autocommit – 自动提交模式。无表示使用服务器默认值。(默认值:False)
- local_infile – 布尔值,用于启用LOAD DATA LOCAL命令。(默认值:False)
- max_allowed_packet – 发送到服务器的数据包的最大大小(以字节为单位)。(默认值:16MB)仅用于限制“ LOAD LOCAL - INFILE”数据包的大小,使其小于默认值(16KB)。
- defer_connect – 不要在构造上显式连接-等待连接调用。(默认值:False)
- auth_plugin_map – 处理该插件的类的插件名称字典。该类将Connection对象作为构造函数的参数。该类需要使用身份验证数据包作为参数的身份验证方法。对于对话框插件,可以使用提示(回显,提示)方法(如果没有身份验证方法)从用户返回字符串。(实验性)
- server_public_key – SHA256身份验证插件公共密钥值。(默认值:无)
- db – 数据库的别名。(为了与MySQLdb兼容)
- passwd – 密码别名。(为了与MySQLdb兼容)
- binary_prefix – 在字节和字节数组上添加_binary前缀。(默认值:False)
方法
begin()开始转换。
close()- 发送退出消息并关闭套接字。
- 请参见规范中的Connection.close() 。
- 引发错误:如果连接已经关闭。
commit()- Commit changes to stable storage.提交对稳定存储的更改。
- 请参见规范中的Connection.commit()。
cursor(cursor=None)创建一个新的游标来执行查询。
参数:
- cursor - The type of cursor to create; one of Cursor, SSCursor, DictCursor, or SSDictCursor. None means use Cursor.
- Open - 如果连接打开了,则返回True。
ping(reconnect=True)检查服务器是否处于在线状态。
参数:reconnect – 若连接关闭则自动重新连接.
抛出: Error – 如果连接关闭过着 reconnect=False.
rollback()回滚当前事务。
请参见规范中的Connection.rollback()。
select_db(db)- 设置当前的 db.
- 参数: db – db 的名字。
show_warnings()发送“SHOW WARNINGS” SQL命令。
6.2.4 PyMySQL游标对象
class pymysql.cursors.Cursor(connection)-
这是你用于与数据库进行交互的对象。不要自己创建Cursor的实例,而是调用
connections.Connection.cursor()。 -
方法:
callproc(procname, args=())使用args执行存储过程procname
- procname – 字符串,要在服务器上执行的过程的名称
- args – 与过程一起使用的参数序列
- 返回原始参数。
兼容性警告:PEP-249指定必须返回所有修改后的参数。当前这是不可能的,因为仅通过将它们存储在服务器变量中然后通过查询进行检索就可以使用它们。由于存储过程返回零个或多个结果集,因此没有可靠的方法通过callproc获取OUT或INOUT参数。服务器变量的名称为@_procname_n,其中procname是上面的参数,n是参数的位置(从零开始)。一旦提取了该过程生成的所有结果集,就可以使用.execute()发出SELECT @ _procname_0,…查询以获取任何OUT或INOUT值。
兼容性警告:调用存储过程本身的行为将创建一个空结果集。这将在该过程生成的任何结果集之后出现。对于DB-API,这是非标准行为。确保使用nextset()前进所有结果集;否则您可能会断开连接。
close()关闭游标只会耗尽所有剩余数据。execute(query, args=None)执行查询
- query (str) – 执行查询。
- args (tuple, list or dict) – 与查询一起使用的参数。(可选的)
- 返回值: 受影响的行数
- 返回值类型: int
- 如果args是列表或元组,则%s可用作查询中的占位符。如果args是字典,则%(name)s可用作查询中的占位符。
executemany(query, args)针对一个查询运行多个数据
- query – 查询要在服务器上执行
- args – 序列或映射的序列。用作参数。
- 返回值: 受影响的行数(如果有)。
- 此方法提高了多行INSERT和REPLACE的性能。否则,这等效于使用execute()遍历args。
fetchall()获取所有行。
fetchmany(size=None)获取多行。
fetchone()获取下一行。
- max_stmt_length= 1024000
- 使用executemany()生成的最大语句大小。
- 允许的语句的最大大小为max_allowed_packet-packet_header_size。
- max_allowed_packet的默认值为1048576。
mogrify(query, args=None)通过调用
execute()方法返回发送到数据库的确切字符串。
此方法遵循对Psycopg的DB API 2.0的扩展setinputsizes(*args)什么都不做,只不过是DB API中要求的。
setoutputsizes(*args)什么都不做,只不过是DB API中要求的。
class pymysql.cursors.SSCursor(connection)- 无缓冲游标,主要用于返回大量数据的查询或通过慢速网络连接到远程服务器。
与其将每行数据复制到缓冲区中,不如将其按需获取行。这样做的好处是客户端使用的内存少得多,并且当通过慢速网络或结果集很大时,返回行的速度要快得多。 - 但是有局限性。MySQL协议不支持返回总行数,因此,要知道有多少行,唯一的方法是对返回的每一行进行迭代。另外,由于当前行仅保存在内存中,因此当前无法向后滚动。
- 方法:
close()关闭游标只会耗尽所有剩余数据。
fetchall()按照MySQLdb获取所有内容。对于大型查询而言,它几乎没有用,因为它是缓冲的。如果要使用此方法的无缓冲生成器版本,请参见fetchall_unbuffered()。
fetchall_unbuffered()提取所有内容,将其实现为生成器,这不是标准的方法,但是,返回列表中的所有内容都没有意义,因为这会对大型结果集使用可笑的内存。
fetchmany(size=None)读取多行。
fetchone()读取下一行。
read_next()读取下一行。
class pymysql.cursors.DictCursor(connection)游标将结果作为字典返回。
class pymysql.cursors.SSDictCursor(connection)无缓冲游标,将结果作为字典返回
7. 面向对象编程 与 对象关系映射(ORM)简介
对象关系映射(Object Relational Mapping,ORM)相当于创建了一个可在编程语言里使用的“虚拟对象数据库”,用于实现面向对象编程语言里不同类型系统的数据之间的转换。
8. 使用基于Python Django 中的 ORM 框架
8.1 预准备工作
安装Django
pip install django初始化一个Django项目:
django-admin startproject pro_name进入该项目的根目录:
cd pro_name
可以看到创建了这样一个项目:

其中与根目录同名的子目录中存放了一些项目全局的参数,里面有一个settings.py的文件,即项目的全局配置,找到并打开它:

其中有一个DATABASES字段,它用来指定使用的数据库:
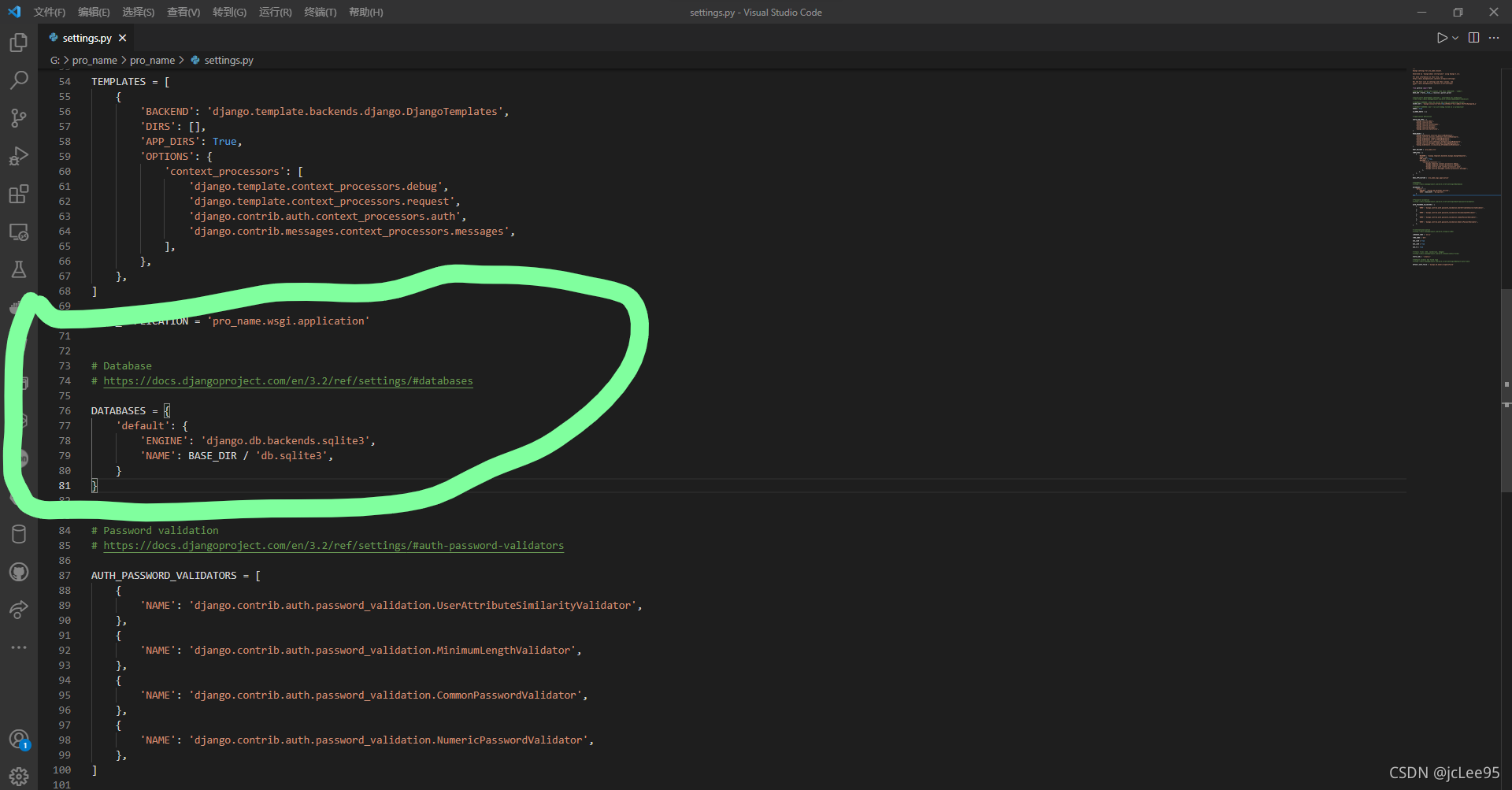
可以看到,默认使用的数据库是SQLite数据库。
你可以同时配置多个不同数据库,包括SQLite、MySQL、Qracle、Redis、MongoDB、PostgreSQL等等,并且允许同时配置多个数据库,但是一定需要有一个"default"数据库。当只配置有一个数据库时,只能是"default"。
如:
DATABASES = { 'SQLite': { 'ENGINE': 'django.db.backends.sqlite3', 'NAME': BASE_DIR / 'db.sqlite3', }, 'default': {'ENGINE': 'django.db.backends.mysql','NAME': 'report','USER':'root','PASSWORD':'123456','HOST':'localhost','PORT':'3306', }, 'oracle': { 'ENGINE': 'django.db.backends.oracle', 'NAME': 'report', 'USER': 'guest1', 'PASSWORD': '123456', 'HOST': '192.168.191.3', 'PORT': '1521', },}使用Django ORM操作MySQL时,底层也需要PyMySQL作为驱动来操作MySQL数据库。可以在项目配置文件同目录的"init.py"初始化文件中添加以下代码以使用PyMySQL作为Django ORM对MySQL的驱动:
import pymysqlpymysql.version_info = (1, 4, 13, "final", 0)pymysql.install_as_MySQLdb()8.2 建立Django数据模型
进入该Django项目更目录,先创建一个 django app,取该app的名字为“car”:
python manage.py startapp car可以看到生成了一个名为car的目录:
打开项目的设置文件(settings.py),将该项目名注册到 INSTALLED_APPS 字段:

进入应用“car”目录,其中有个 models.py文件,编辑以下内容以定义数据模型:
from django.db import models# Create your models here.class Car(models.Model): """家用小车数据模型 """ id = models.AutoField(primary_key=True) create_time = models.DateTimeField(auto_now_add=True, verbose_name='数据创建时间') brand_name = models.CharField(max_length=60, verbose_name='品牌') model = models.CharField(max_length=30, verbose_name='型号') productive_year = models.CharField(max_length=4, verbose_name='生产年份') color = models.CharField(max_length=20, verbose_name='颜色') price = models.IntegerField(verbose_name='价格')现在回到项目更目录,由模型生成数据迁移文件:
python manage.py makemigrations再执行数据迁移到数据库:
python manage.py migrate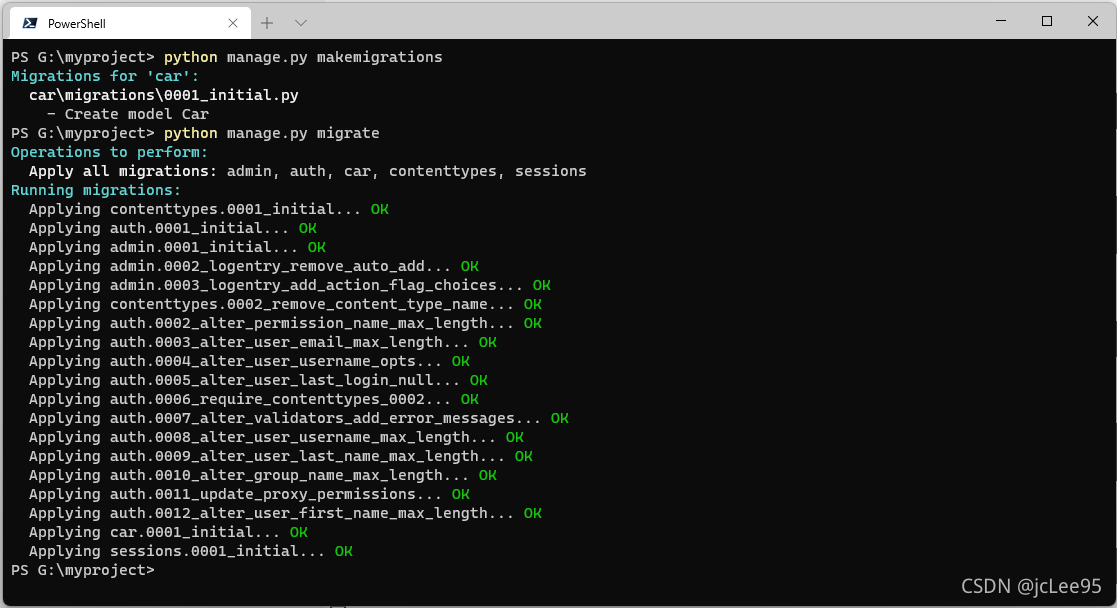
这时可以看到我们的项目根目录下生成了一个SQLite数据库文件(后缀sqlite3):
此时我们使用SQLite数据库管理软件(我这里使用的是SQLiteSpy,它和另一款软件sqliteadmin我已经上传到CSDN,可以点击这个链接 https://download.csdn.net/download/qq_28550263/25013485进行下载),可以看到生成了很多表,其中有一个叫做“ car_car”的表:
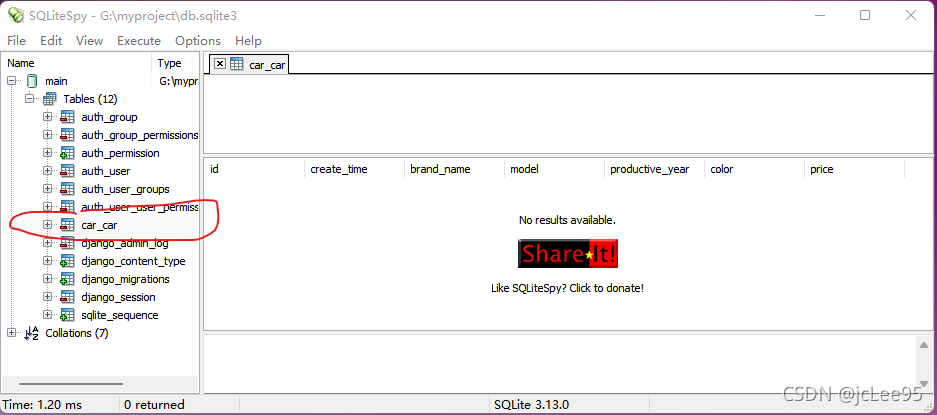
该表的表名“car_car”的下划线前的字符串"car"表示我们创建的应用名为car,而下划线后一个“car”为我们在“models.py”中定义数据模型类型时,汽车数据模型类“Car”的全小写形式。
说明(1):★Django数据模型中直接提供的字段类型:
| 表字段 | 含义 |
|---|---|
| models.AutoField | 默认回生成一个名为id的字段并为int类型 |
| models.CharField | 字符串类型 |
| models.TextField | 长文本类型 |
| models.BooleanField | 布尔类型 |
| models.NullBooleanField | 允许为空的布尔类型 |
| models.IntegerField | 整数类型 |
| models.FloatField | 浮点数类型 |
| models.DecimalField | 十进制小数类型 |
| models.BigIntegerField | 长整数类型 |
| models.PositiveIntegerField | 正整数的整数类型 |
| models.PositiveSmallIntegerField | 小正整数类型 |
| models.SmallIntegerField | 小整数类型(取值范围为:-32768~+32767) |
| models.ComaSeparatedIntegerField | 用逗号分隔的整数类型 |
| models.DateField | 日期类型 |
| models.DateTimeField | 日期时间类型 |
| models.TimeField | 时间类型,显示时分秒HH:MM[:ss[.uuuuuu]] |
| models.EmailField | 字符串类型(正则表达式邮箱) |
| models.IPAddressField | 字符串类型(IPv4正则表达式) |
| models.GebericIPAddressField | 字符串类型(参数protocol可以是:“both”、“IPv4”、“IPv6”,验证IP地址格式正确性) |
| models.URLField | 字符串类型,地址为正则表达式 |
| models.SlugField | 字符串类型,包含字母、数字、下划线和连字符的字符串,常用于URL |
| models.BinaryField | 二进制数据类型 |
这些Django提供的字段中,可以使用以下通用的参数:
| 参数 | 含义 |
|---|---|
| verbose_name | 在Admin站点管理设置字段的显示名称 |
| related_name | 关联对象反向引用描述符,用于多表查询,可以解决一个数据表有两个外键同时指向另一个数据表而出现重名的问题 |
| unique | 如果为 True ,字段将被设置为唯一值属性,默认为 False |
| db_index | 如果为 True ,将为字段添加数据库索引 |
| db_column | 设置数据库中的字段名称 |
| primary_key | 如果为 True ,字段将被设置为主键 |
| null | 如果为 True ,该字段的数值可以为空 |
| blank | 如果为 True ,设置在Admin站点管理中添加数据时可允许空值 |
| default | 用于设置默认值 |
说明(2):★Django ORM中数据表关系的实现
【一对一关系】
- 在模型中,可以通过
OneToOneField来构建数据表的一对一关系。
【一对多关系】
- 在模型中,可以通过
ForeignKey来构建数据表的一对多关系。
【多对多关系】
- 在模型中,可以通过
ManyToManyField来构建数据表的多对多关系。
8.3 通过 Django ORM方式 添加数据
一共有以下几个步骤:
- 导入数据模型,导入源为定义该数据模型的models.py;
- 创建数据模型的一个实例;
- 基于实例为数据模型实例对象的各个属性赋入数据值;
- 调用该实例的
save()方法以保存一条记录。
8.4 通过 Django ORM方式 查询数据
8.4.1 快速上手示例
注意:以下代码为示意的伪代码,只需根据你的实际项目修改相应名称即可。
(1)导入相应模块
from appName.models import *(2)全表查询:select * from MyDataObj
p = MyDataObj.object.all() # 查询整个表,返回python列表p[3].first_name # 筛选第4条数据的first_name字段(3)表中前n条数据:select * from MyDataObj LIMIT 5
p = MyDataObj.objects.all()[:5]# 不含最后一条(4)指定字段查询:select field_name from MyDataObj
p = MyDataObj.objects.value('field_name')p[2]['field_name'](5)使用values_list方法
p = MyDataObj.objects.value_list('field_name')[:3] # 获取field_name字段前3条数据该方法返回一个QuerySet,其每条数据回呈现为一个元组进行表示。
(6)使用get方法筛选字段select * from MyDataObj where field_name = field_name_value
p = MyDataObj.objects.get(field_name = field_name_value) # 筛选某个字段满足字段值的数据p.field_name2 # 获取其中另外一个字段的数据(7)使用filter方法筛选字段
p = MyDataObj.objects.filter(field_name = field_name_value) # 是一个QuerySetp[0].field_name # 赛选第一条数据的field_name字段(8)使用filter方法可以添加多个查询条件:and逻辑
p = MyDataObj.objects.filter(field_name1 = field_name_value1, field_name2 = field_name_value2) # 是一个QuerySet(9)使用filter方法可以添加多个查询条件:or逻辑
import django.db.models import Qp = MyDataObj.objects.filter(Q(field1=value1)|(field2=value2))(10)去重查询
p = MyDataObj.objects.values(field_name).filter(field_name=field_value).distinct() # 返回一个QuerySet(11)聚合查询——统计
import django.db.models import countp = MyDataObj.objects.filter(namevalue).count()(12)聚合查询——数据值求和
import django.db.models import Sump = MyDataObj.objects.values(field_name).annotate(Sum(field_value))p.query8.4.2 区分查询条件 get 和 filter 的不同
| get | filter |
|---|---|
查询字段必须是 主键 或者 唯一约束的字段,并且 查询的数据必须存在 。如果查询的字段有重复或者查询的数据不存在,程序将抛出异常信息。 |
查询的字段没有限制,只要该字段是数据表的某一存在的字段即可。 查询的结果 以列表的形式返回 如果查询结果为空(即数据库中无满足相应查询条件的数据),则返回一个空的列表。 |

