MySQL看这一篇就够了--从入门到高级
🙋作者:爱编程的小贤
⛳知识点:MySQL
🥇:每天学一点,早日成大佬
💗文章目录
- 👊前言
- ☀️一、数据库介绍
-
- (一)数据库简介
- (二)数据库特点
- (三)能解决的问题
- (四)数据库分类
- (五)数据库设计
-
- 1.E-R模型
- 2.三个范式
- 3.数据完整性
- 4.字段类型
- 5.约束
- 6.使用命令连接
- ☀️二、数据库操作
-
- 1.创建数据库
- 2.查看数据库
- 3.删除数据库
- 4.切换数据库
- 5.注释
-
- (1)单行注释
- (2)多行注释
- ☀️三、表操作
-
- 1.查看当前数据库中所有表
- 2.创建表
- 3.查询表
- 4.删除表
- 5.更改表名称
- ☀️四、数据操作(增删改查)
-
- 1.新增操作
- 2.查询操作
- 3.修改操作
- 4.删除操作
- ☀️五、表关系
-
- 1.一对一
- 2.一对多
- 3.多对多
- ☀️六、MySQL查询
-
- 1.条件查询
-
- (1)比较运算符
- (2)逻辑运算符
- (3)模糊查询
- (4)范围查询
- (5)空判断
- (6)优先级
- 2.聚合查询
- 3.分组查询
-
- ->分组后的数据筛选
- ->对比where与having
- 4.分页查询
- 5.总结
- ☀️七、MySQL高级
-
- 1.数据类型
- 2.关系
- 3.外键
-
- 外键的级联操作
- 4.自关联
- 5.视图
- 6.事务
- ☀️总结
👊前言
💎 💎 💎
①首先要先下载MySQL然后进行环境变量配置
②可以私信我获取链接(有安装包和安装详细步骤及环境变量配置)
③也可以去官网下载
https://downloads.mysql.com/archives/installer/
🚀 🚀 🚀 如果你看完感觉对你有帮助,,,欢迎给个三连哦💗!!!您的支持是我创作的动力。🌹 🌹 🌹 🌹 🌹 🌹 感谢感谢!!!😘😘😘
☀️一、数据库介绍
(一)数据库简介
数据库 : 数据库是按照数据结构来组织、存储和管理数据的仓库。简单来说是本身可视为电子化的文件柜–存储电子文件的处所,用户可以对文件中的数据进行新增、查询、更新、删除等操作。
(二)数据库特点
特点 : 以一定方式储存在一起、能为多个用户共享、具有尽可能小的冗余度的特点、是与应用程序彼此独立的数据集合。
- 实现数据共享;
- 减少数据的冗余度;
- 数据的独立性;
- 数据实现集中控制;
- 数据一致性和可维护性,以确保数据的安全性和可靠性;
- 故障恢复;
(三)能解决的问题
数据库系统解决的问题:持久化存储,优化读写,保证数据的有效性
(四)数据库分类
当前使用的数据库,主要分为两类
- 关系型数据库:类似于表格有字段和字段对应的值
- 易于维护:格式一致
- 使用方便:sql语言通用
- 非关系型数据库:数据结构化存储方法的集合,可以是文档或者键值对
- 格式灵活:存储数据的格式可以是key,value形式、文档形式
- 速度快:可以使用内存
(五)数据库设计
1.E-R模型
- 当前物理的数据库都是按照E-R模型进行设计的
- E表示entry,实体
- R表示relationship,关系
- 一个实体转换为数据库中的一个表
- 关系描述两个实体之间的对应规则,包括
- 一对一
- 一对多
- 多对多
- 关系转换为数据库表中的一个列 *在关系型数据库中一行就是一个对象
2.三个范式
- 经过研究和对使用中问题的总结,对于设计数据库提出了一些规范,这些规范被称为范式
- 第一范式(1NF):列不可拆分
- 第二范式(2NF):唯一标识
- 第三范式(3NF):引用主键
- 说明:后一个范式,都是在前一个范式的基础上建立的
3.数据完整性
- 一个数据库就是一个完整的业务单元,可以包含多张表,数据被存储在表中
- 在表中为了更加准确的存储数据,保证数据的正确有效,可以在创建表的时候,为表添加一些强制性的验证, 包括数据字段的类型、约束
4.字段类型
- 在mysql中包含的数据类型很多,这里主要列出来常用的几种
- 数字:int,decimal
- 字符串:varchar,text
- 日期:datetime
- 布尔:bit
5.约束
- 主键primary key
- 非空not null
- 唯一unique
- 默认default
- 外键foreign key
6.使用命令连接
- 命令操作方式,在工作中使用的更多一些,所以要达到熟练的程度
- 打开终端,运行命令
命令:mysql -uroot -p 回车后输入密码,当前设置的密码为mysql
- 连接成功后如下图

- 退出登录
quit或exit
- 退出成功后如下图
- 登录成功后,输入如下命令查看效果:
查看版本:select version();
显示当前时间:select now();
- 注意:在每个语句结尾要使用分号;
☀️二、数据库操作
对数据库的操作 : 主要分为 创建数据库 ,查看数据库 , 删除数据库
1.创建数据库
create database 数据库名 charset=utf8;
create database Cara;
2.查看数据库
show databases;
- 查看当前选择的数据库
select database();
3.删除数据库
drop database 数据库名;
drop database Cara;
注意 : MySQL没有提供数据库名称的修改操作 , 通常在数据库里面存放着大量的数据表,而数据表的命名通常都是一个数据库名称的部分字母作为表的前缀 , 一旦修改数据库的名称那么表名称有需要修改,这个会非常麻烦。而数据库的删除操作也不要随意操作 , 因为删除是不可逆的。mysql不区分大小写
4.切换数据库
use 数据库名;
5.注释
(1)单行注释
- 单行注释可以使用 # 注释符, # 注释符后直接加注释内容。格式如下:
#注释内容
- 单行注释可以使用 – (两个杠)注释符, – 注释符后需要加一个空格,注释才能生效。格式如下:
–(两个杠)(空格) 注释内容
#和 -- 的区别就是: #后面直接加注释内容,而 --的第 2 个破折号后需要跟一个空格符在加注释内容。(2)多行注释
多行注释使用 /* */ 注释符。 /*用于注释内容的开头, */ 用于注释内容的结尾。多行注释格式如下:
/*
第一行注释内容
第二行注释内容
*/
注释内容写在 /* 和 */ 之间,可以跨多行。快捷注释:ctrl + / 取消注释 ctrl+shift☀️三、表操作
提示:在创建表之前 , 一定要确定是对哪个数据库的操作。
使用数据库:use 数据库名; – 每行代码结束后要写分号
1.查看当前数据库中所有表
show tables;
2.创建表
auto_increment表示自动增长
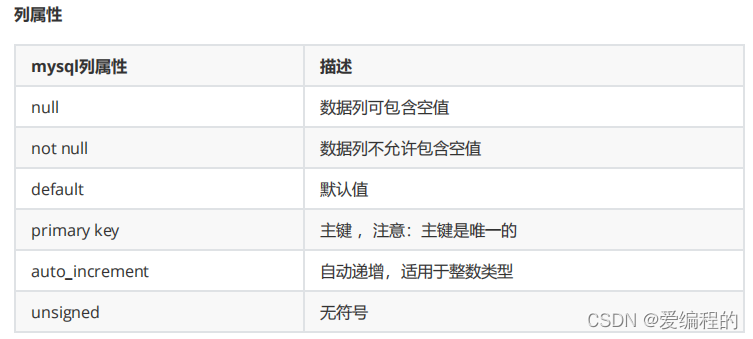
create table 表名(列及类型);Create table 表名(字段名称 数据类型 列属性,字段名称 数据类型 列属性 -- 最后一个字段 不需要加逗号)[表选项]; //charset = utf8;如:create table students(id int auto_increment primary key,sname varchar(10) not null);常用数据类型

3.查询表
show tables; -- 查询所有的表 desc 表名; -- 查看创建的表的字段(查看表结构)show create table 表名; -- 查看表的创建(创建表的语句)代码如下:
show tables;desc student;show create table student;4.删除表
drop table 表名; drop table if exists 表名; -- 如果存在则删除代码如下:
drop table student; drop table if exists student;5.更改表名称
rename table 原表名 to 新表名;代码如下:
rename table student to user;☀️四、数据操作(增删改查)
1.新增操作
全列插入:insert into 表名 values(...)缺省插入:insert into 表名(字段1,...) values(值1,...)同时插入多条数据:insert into 表名 values(...),(...)...;或insert into 表名(字段1,...) values(值1,...),(值1,...)...;注意:当表有自增长时,如果不手动插入数据,就需要把要插入的列名都写出来。。主键列是自动增长,但是在全列插入时需要占位,通常使用0,插入成功后以实际数据为准
代码如下:
insert into user values(2,'lisa',12,'2021-8-3') insert into user(name,age) values('lisa',12)注意 : 添加数据的时候 , 后面的值要和前面的字段一一对应。
2.查询操作
select */字段列表 from 表名 [where条件];代码如下:
select * from user; -- 查询所有数据 select * from user where name='lisa' -- 查询名字为lisa的所有信息 select age from user where name='lisa' -- 查询名字为lisade 年龄3.修改操作
update 表名 set 字段 = 值 [where条件] ; -- 如果没有where条件会修改所有的行代码如下:
update user set age=16 where name='lisa';注意 : 要在后面加上 where 限定修改的条件 , 否则修改的就是全部的数据。
4.删除操作
delete from 表名 [where条件]; -- where后不加条件默认删除的也是所有内容代码如下:
delete from user where id=1; -- 根据条件删除 delete from user; -- 删除表里面的所有内容-
逻辑删除, 用一个字段来表示 这条信息是否已经不能再使用了
alter table students add isdelete bit default 0;
如果需要删除则
update students set isdelete=1 where …;
☀️五、表关系
将表与表的关系 , 反应到最终数据库表的设计上来可以将关系分成三种:一对一 , 一对多(多对一)和多对多
1.一对一
一对一 : 一张表的一条记录一定只能与另外一张表的一条记录进行对应; 反之亦然。例 : 学员与坐位的关系 :
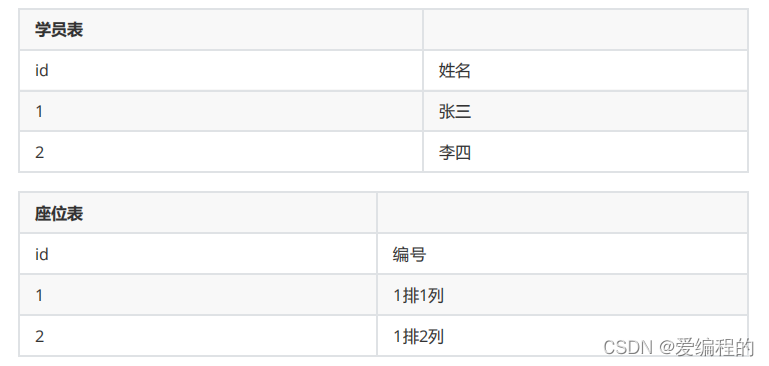
一个学员的坐位只有一个(张三的座位是一排一列 , 而李四的则是一排二列)。
2.一对多
一对多 : 一张表中有一条记录可以对应另外一张表中的多条记录; 但是返回过 , 另外一张表的一条记录只能对应第一张表的一条记录 , 这种关系就是一对多或者多对一。
例 : 地区和人员的关系 :
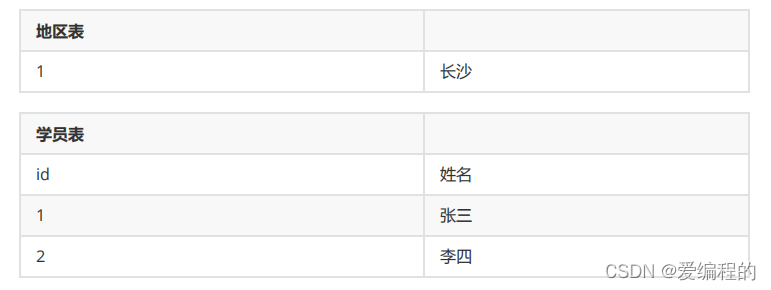
多个学员可能存在于同一个地区。
3.多对多
多对多 : 一张表中(A)的一条记录能够对应另外一张表(B)中的多条记录; 同时B表中的一条记录也能对应A表中的多条记录 , 这种关系就是多对多的关系。例 : 学员和老师的关系 :
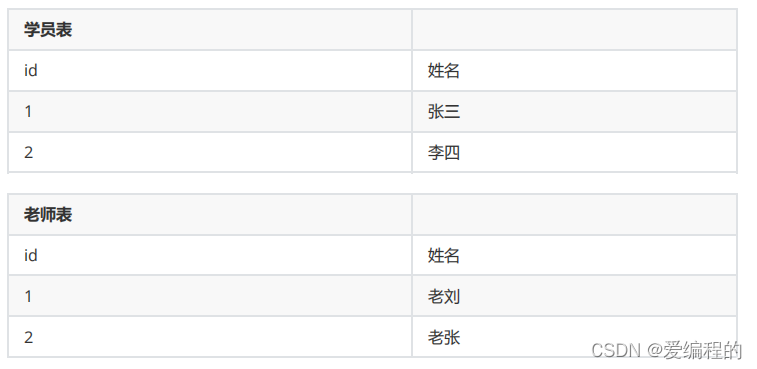
一个老师有多个学员 , 一个学员也会存在多个老师。
☀️六、MySQL查询
1.条件查询
使用where子句对表中的数据筛选,结果为true的行会出现在结果集中
select * from 表名 where 条件;(1)比较运算符
- 等于=
- 大于>
- 大于等于>=
- 小于<
- 小于等于<=
- 不等于!=或
查询编号大于3的学生
select * from students where id>3;查询编号不大于4的科目
select * from subjects where id<=4;查询姓名不是“黄蓉”的学生
select * from students where sname!='黄蓉';查询没被删除的学生
select * from students where isdelete=0;(2)逻辑运算符
- and
- or
- not
查询编号大于3的女同学
select * from students where id>3 and gender=0;查询编号小于4或没被删除的学生
select * from students where id<4 or isdelete=0;(3)模糊查询
- like
- %表示任意多个任意字符
- _表示一个任意字符
查询姓黄的学生
select * from students where sname like '黄%';查询姓黄的学生
select * from students where sname like '黄_';查询姓黄的学生
select * from students where sname like '黄%' or sname like '%靖%';(4)范围查询
- in表示在一个非连续的范围内
查询编号是1或3或8的学生
select * from students where id in(1,3,8);- between … and …表示在一个连续的范围内
查询学生是3至8的学生
select * from students where id between 3 and 8;查询学生是3至8的男生
select * from students where id between 3 and 8 and gender=1;查询学生是3至8的学生
(5)空判断
- 注意:null与" "是不同的
- 判空is null
查询没有填写地址的学生
select * from students where hometown is null;- 判非空is not null
查询填写了地址的学生
select * from students where hometown is not null;查询填写了地址的女生
select * from students where hometown is not null and gender=0;(6)优先级
- 小括号>not>比较运算符>逻辑运算符
- and比or先运算,如果同时出现并希望先算or,需要结合()使用
2.聚合查询
- 为了快速得到统计数据,提供了5个聚合函数
- count(*)表示计算总行数,括号中写星与列名,结果是相同的
查询学生总数
select count(*) from students;- max(列)表示求此列的最大值
查询女生的编号最大值
select max(id) from students where gender=0;- min(列)表示求此列的最小值
查询未删除的学生最小编号
select min(id) from students where isdelete=0;- sum(列)表示求此列的和
查询男生的编号之后
select sum(id) from students where gender=1;- avg(列)表示求此列的平均值
查询未删除女生的编号平均值
select avg(id) from students where isdelete=0 and gender=0;3.分组查询
- 按照字段分组,表示此字段相同的数据会被放到一个组中
- 分组后,只能查询出相同的数据列,对于有差异的数据列无法出现在结果集中
- 可以对分组后的数据进行统计,做聚合运算
select 列1,列2,聚合... from 表名 group by 列1,列2,列3...查询男女生总数
select gender as 性别,count(*)from studentsgroup by gender;查询各城市人数
select hometown as 家乡,count(*)from studentsgroup by hometown;->分组后的数据筛选
select 列1,列2,聚合... from 表名group by 列1,列2,列3...having 列1,...聚合...- having后面的条件运算符与where的相同
查询男生总人数
方案一select count(*)from studentswhere gender=1;-----------------------------------方案二:select gender as 性别,count(*)from studentsgroup by genderhaving gender=1;->对比where与having
- where是对from后面指定的表进行数据筛选,属于对原始数据的筛选
- having是对group by的结果进行筛选
4.分页查询
- 当数据量过大时,在一页中查看数据是一件非常麻烦的事情
select * from 表名limit start,count- 从start开始,获取count条数据
- start索引从0开始
5.总结
- 完整的select语句
select distinct *from 表名where ....group by ... having ...order by ...limit star,count- 执行顺序为:
from 表名where ....group by ...select distinct *having ...order by ...limit star,count☀️七、MySQL高级
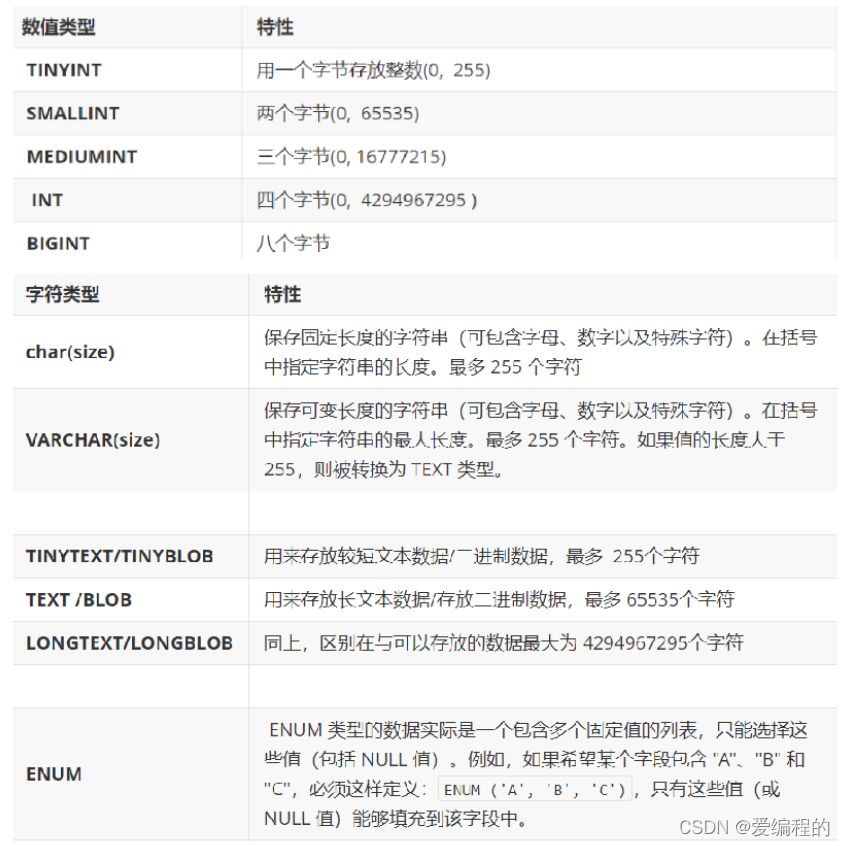
1.数据类型
2.关系
- 创建成绩表scores,结构如下
- id
- 学生
- 科目
- 成绩
- 思考:学生列应该存什么信息呢?
- 答:学生列的数据不是在这里新建的,而应该从学生表引用过来,关系也是一条数据;根据范式要求应该存储学生的编号,而不是学生的姓名等其它信息
同理,科目表也是关系列,引用科目表中的数据
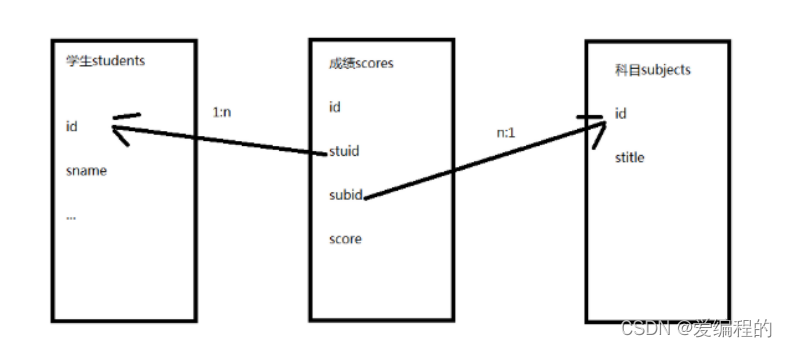
- 创建表的语句如下
create table scores(id int primary key auto_increment,stuid int,subid int,score decimal(5,2));3.外键
- 思考:怎么保证关系列数据的有效性呢?任何整数都可以吗?
- 答:必须是学生表中id列存在的数据,可以通过外键约束进行数据的有效性验证
- 为stuid添加外键约束
alter table scores add constraint stu_sco foreign key(stuid) references students(id);- 此时插入或者修改数据时,如果stuid的值在students表中不存在则会报错
- 在创建表时可以直接创建约束
create table scores(id int primary key auto_increment,stuid int,subid int,score decimal(5,2),foreign key(stuid) references students(id),foreign key(subid) references subjects(id));外键的级联操作
- 在删除students表的数据时,如果这个id值在scores中已经存在,则会抛异常
- 推荐使用逻辑删除,还可以解决这个问题
- 可以创建表时指定级联操作,也可以在创建表后再修改外键的级联操作
alter table scores add constraint stu_sco foreign key(stuid) references students(id) ondelete cascade;- 级联操作的类型包括:
restrict(限制):默认值,抛异常cascade(级联):如果主表的记录删掉,则从表中相关联的记录都将被删除set null:将外键设置为空no action:什么都不做4.自关联
- 设计省信息的表结构
- provinces
- id
- ptitle
- 设计市信息的表结构citys
- id
- ctitle
- proid
- citys表的proid表示城市所属的省,对应着provinces表的id值
- 问题:能不能将两个表合成一张表呢?
- 思考:观察两张表发现,citys表比provinces表多一个列proid,其它列的类型都是一样的
- 意义:存储的都是地区信息,而且每种信息的数据量有限,没必要增加一个新表,或者将来还要存储区、乡镇 信息,都增加新表的开销太大
- 答案:定义表areas,结构如下
- id
- atitle
- pid
- 因为省没有所属的省份,所以可以填写为null
- 城市所属的省份pid,填写省所对应的编号id
- 这就是自关联,表中的某一列,关联了这个表中的另外一列,但是它们的业务逻辑含义是不一样的,城市信息 的pid引用的是省信息的id
- 在这个表中,结构不变,可以添加区县、乡镇街道、村社区等信息
- 创建areas表的语句如下:
create table areas(id int primary key,atitle varchar(20),pid int,foreign key(pid) references areas(id));- 从sql文件中导入数据
source areas.sql;- 查询一共有多少个省
- 查询省的名称为“山西省”的所有城市
select city.* from areas as cityinner join areas as province on city.pid=province.idwhere province.atitle='山西省';- 查询市的名称为“广州市”的所有区县
select dis.*,dis2.* from areas as disinner join areas as city on city.id=dis.pidleft join areas as dis2 on dis.id=dis2.pidwhere city.atitle='广州市';5.视图
- 对于复杂的查询,在多次使用后,维护是一件非常麻烦的事情
- 解决:定义视图
- 视图本质就是对查询的一个封装
- 定义视图
create view stuscore asselect students.*,scores.score from scoresinner join students on scores.stuid=students.id;- 视图的用途就是查询
select * from stuscore;6.事务
- 当一个业务逻辑需要多个sql完成时,如果其中某条sql语句出错,则希望整个操作都退回
- 使用事务可以完成退回的功能,保证业务逻辑的正确性
- 事务四大特性(简称ACID)
- 原子性(Atomicity):事务中的全部操作在数据库中是不可分割的,要么全部完成,要么均不执行
- 一致性(Consistency):几个并行执行的事务,其执行结果必须与按某一顺序串行执行的结果相一致
- 隔离性(Isolation):事务的执行不受其他事务的干扰,事务执行的中间结果对其他事务必须是透明的
- 持久性(Durability):对于任意已提交事务,系统必须保证该事务对数据库的改变不被丢失,即使数据库出 现故障
- 要求:表的类型必须是innodb或bdb类型,才可以对此表使用事务
- 查看表的创建语句
show create table students;- 修改表的类型
alter table '表名' engine=innodb;- 事务语句
开启begin;提交commit;回滚rollback;☀️总结
本文经过自己所学加上参考一些资料整理而来,希望能帮助到大家,让各位兄弟姐妹们对数据库有一个深入的认识并能够熟练掌握,希望给个支持谢谢啦!!!❤️ 🌹 🌹 🌹

