【数据结构真不难】线性表——五一专属|向所有热爱分享的“技术劳动者”致敬
- 💂 个人主页: 陶然同学
- 🤟 版权: 本文由【陶然同学】原创、在CSDN首发、需要转载请联系博主
- 💬 如果文章对你有帮助、欢迎关注、点赞、收藏(一键三连)和订阅专栏哦
- 💅 想寻找共同成长的小伙伴,请点击【Java全栈开发社区】
目录
1.概述
2.顺序表
2.1定义
2.2地址公式
2.3顺序表特点
2.4算法:插入
2.5算法:删除
2.6算法:查找
2.7顺序表局限性
3.单链表
3.1定义
3.2术语
3.3类定义
3.4算法:【单链表的长度】
3.5算法:按索引号(位序号)查找
3.6算法:按值查找所以号
3.7算法:插入
3.8删除
3.9获得前驱
4.循环链表
4.1定义
4.2算法:循环链表合并
5.双向链表
5.1定义
5.2算法:插入
5.3算法:删除
6.最后
1.概述
-
线性表:是一种最常用、最简单,也是最基本的数据结构。
-
线性表由n个数据元素所构成的有限序列,且数据类型相同。
-
线性表可以用
顺序存储和链式存储两种存储结构来表示。-
使用
顺序存储的线性表称为顺序表,也称为静态线性表。 -
使用
链式存储的线性表称为链表,也称为动态线性表。
-
-
链表的分类:单链表、双向链表、循环链表。
2.顺序表
2.1定义
-
顺序表,就是顺序存储的线性表。
-
顺序存储是用一组地址连续的存储单元依次存放线性表中各个数据元素的存储结构。
-
在逻辑上,数据ABCD是连续
-
在物理上,地址也是连续的
-
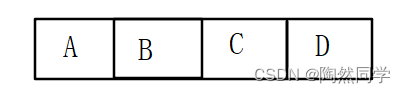
- 可以使用
数组来描述数据结构中的顺序存储结构。
2.2地址公式
地址公式
//第i的地址 = 第一个地址 + 第几个 * 存储单位Loc(ai) = Loc(a0) + i * c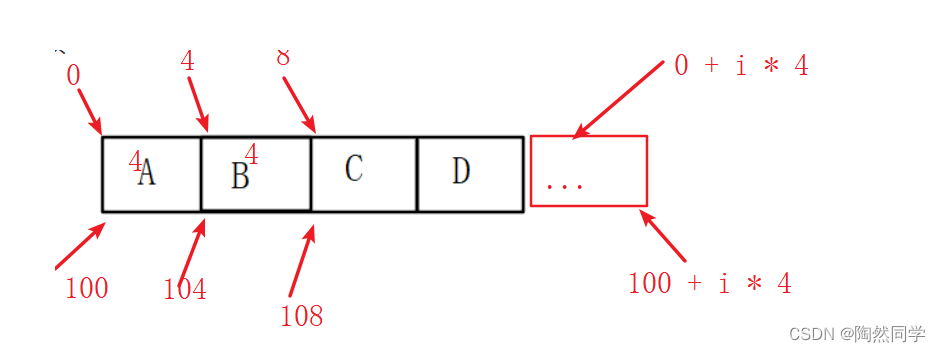
2.3顺序表特点
-
在线性表中逻辑上相邻的数据元素,在物理存储位置上也是相邻的。
-
存储密度高。但需要预先分配“足够”的存储空间。
存储密度 = 数据元素存储空间 / 数据元素实际占用空间
在顺序表中,存储密度为1。
-
便于随机存储。(数组中可以通过下标进行存储)
-
不便于插入和删除操作。两种操作都会引起大量的数据移动。
2.4算法:插入
-
需要:在顺序表第i个位置处插入一个新元素。
-
顺序表插入操作:将第i个数据元素及其之后的所有的数据元素,后移一个存储位置,再将新元素插入到i处。
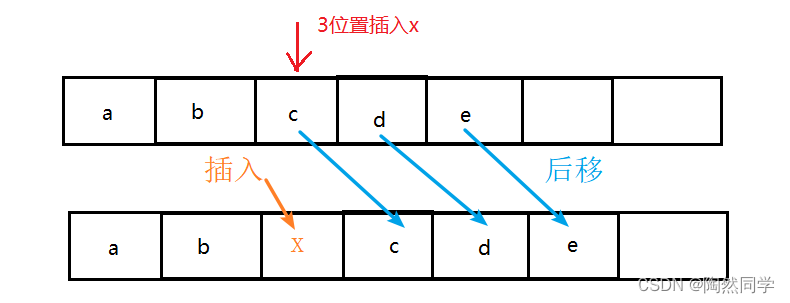
前置:类中成员
public class SqList { private Object[] listElem;//线性表的存储空间 private int curLen;//线性表的当前长度}插入操作算法
/ * @Param i 第i个位置 * @Param x 需要插入的数据 */public void insert(){ //0.1满校验:存放实际长度 和 数组长度一样 if(curLen == listEle.length){ throw new Exception("已满"); } //0.2非法校验 在已有的数据中插入[0,curLen]必须连续 中间不能空元素 if(i curLen){ throw new Exception("位置非法"); } //1 将i及其之后移 for(int j = curLen; j > i; j--){ listEle[j] = listEle[j - 1]; } //2 插入i处 listEle[i] = x; //3 记录长度 curLen++;}-
插入时间复杂度:O(n)
2.5算法:删除
-
需求:将第i位置处元素删除
-
删除操作:将第i个数据元素ai之后的所有数据元素向前一定一个存储位置。
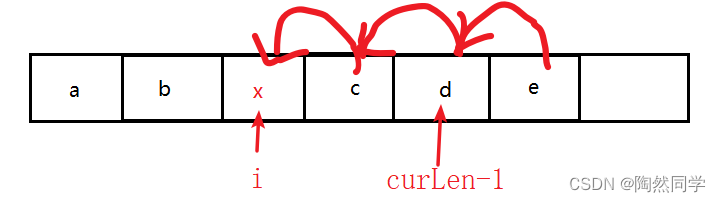
算法:
public void remove(int i){ //0.1校验非法数据 if(i curLen - 1){ throw new Exception("位置非法"); } //1 将i之后向前移动 for(int j = i; j < curLen - 1; j++){ listEle[j] = listEle[j+1]; } //2 长度-- curLen--;}-
删除时间复杂度:O(n)
2.6算法:查找
-
需求:查找指定数据的索引号
-
算法1:循环遍历已有数据,进行判断,如果有返回第一个索引号,如果没有返回-1
public int indexOf(Object x){ for(int i = 0; j < curLen; i++){ if(listEle[i].equals(x)){ return i; } } return -1;}-
算法2:使用变量记录没有匹配到索引
public int indexOf(Object x){ int j = 0; //用于记录索引信息 while(j < curLen && !listEle[j].equals(x)){ j++; } //j记录索引小于数量 if(j < curLen){ return j; }else{ return -1; } }-
查询时间复杂度:O(n)
2.7顺序表局限性
-
若要为线性表扩充存储空间,则需要重新创建一个地址连续的更大的存储空间,并把原有的数据元素都复制到新的存储空间中。(扩容)
-
因为顺序存储要求逻辑上相邻的数据元素,在物理存储位置上也是相邻的,这就使得要增删数据元素时,会引起平均一半的数据元素的移动。
3.单链表
3.1定义
-
采用链式存储方式存储的线性表称为链表。
-
链表中每一个结点包含存放数据元素值的数据域和存放逻辑上相邻节点的指针域。
-
数据域 data:用于存放数据元素的值。
-
指针域 next:用于存放后继结点的地址。
-

3.2术语
非空表:

空表:空表的指针域为空指针null
3.3类定义
-
数据域 data:用于存放数据元素的值。
-
指针域 next:用于存放后继结点的地址。
public class Node{ public Object data;//数据域 public Node next;//指针域}3.4算法:【单链表的长度】
public int length(){ Node p = head.next; //获得第一个节点 int length = 0; //定义一个变量记录长度 while(p != null){ length++; //计数 p = p.next; //p指向下一个节点 } return length;}3.5算法:按索引号(位序号)查找
-
思路:
-
处理了所有的结点都没有数据,判断依据 null
-
处理到一部分就找到了,判断依据
-
public Object get(int i){ Node p = head.next; //获得头节点 int j = 0; while(p != null && j < i){ //已经处理的节点数 p = p.next;//链表没有下一个 && 处理有效部分 j++; } if(i < 0 || p == null){ throw new Exception("元素不存在"); } return p.data; //返回数据}3.6算法:按值查找所以号
//查询给定值的索引号 如果没有返回-1public int indexOf(Object x){ Node p = head.next; //获得头节点 int j = 0; //不匹配元素的个数 while(p != null && !p.data.equals(x)){ //循环依次找[不匹配]元素 p = p.next; j++; } //返回匹配索引 如果没有返回-1 if(p != null){ return j; }else{ return -1; }}3.7算法:插入
-
需求:向索引i前面插入一个新结点s
-
思路:获得i的前驱,结点P
public void insert(int i,Object x){ Node p = ......; //获得i前驱 Node s = new Node(x);//创建新节点s s.next = p.next; //必须先执行 p.next = s; //然后再执行}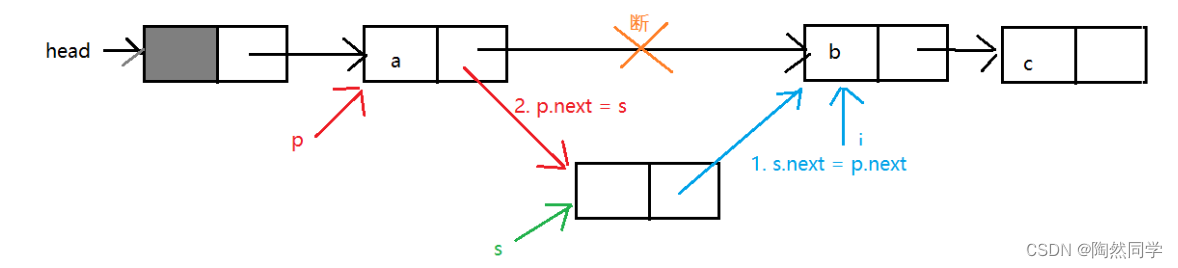
3.8删除
需求:删除i结点
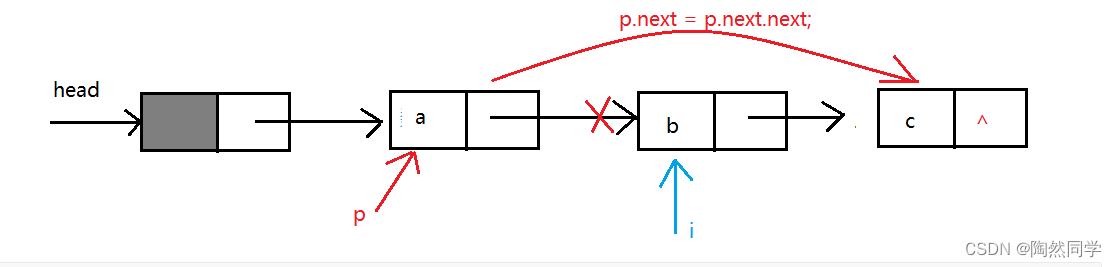
public void remove(int i){ //获得i的前驱节点p p.next = p.next.next;}3.9获得前驱
// i最小值0,表示获得头结点head// 算法内部,使用-1表示头结点head,结点移动从头结点head开始。public void previous(int i){ Node p = head; int j = -1; while(p != null && j < i - 1){ p = p.next; j++; } if(p != null || i < 0){ throw new RuntimeException("i不合法"); }}4.循环链表
4.1定义
循环链表也称为环形链表,其结构与单链表相似,只是将单链表的首尾相连。

// p结点是尾结点p.next = head;4.2算法:循环链表合并
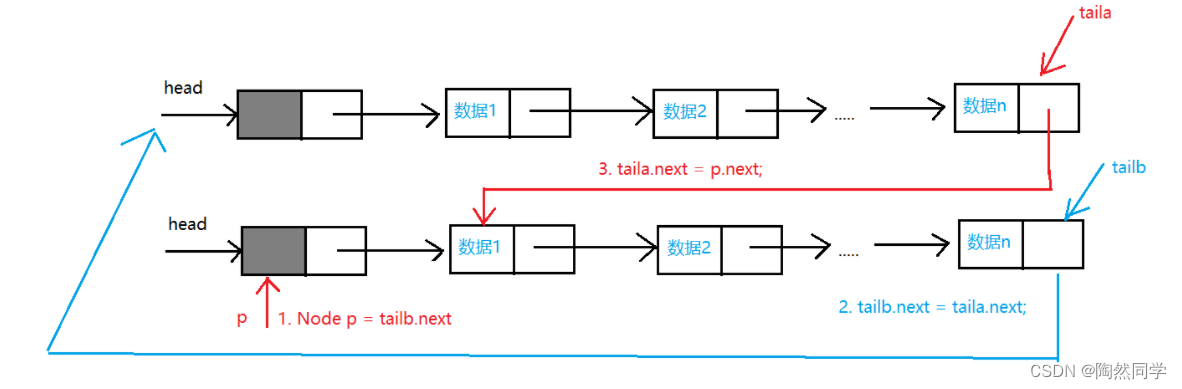
-
分析
-
核心算法
/* 变量a尾: tailaa头:taila.nextb尾:tailbb头:tailb.next*/// 先将b尾指向a的头,需要定义p记录b尾原来的值// 再将a的尾指向b的头Node p = tailb.next;//记录b尾的指向,也就是b头tailb.next = taila.next;//b尾指向a头taila.next = p.next;//a尾执行b头5.双向链表
5.1定义
-
一个结点由两个指针域,一个指针域指向前驱结点,另一个指针域指向后继结点,这种链表称为双向链表
-
数据域 data
-
前驱结点指针域:prior
-
后继结点指针域:next
-

5.2算法:插入
-
需求:向结点p前面插入新结点s
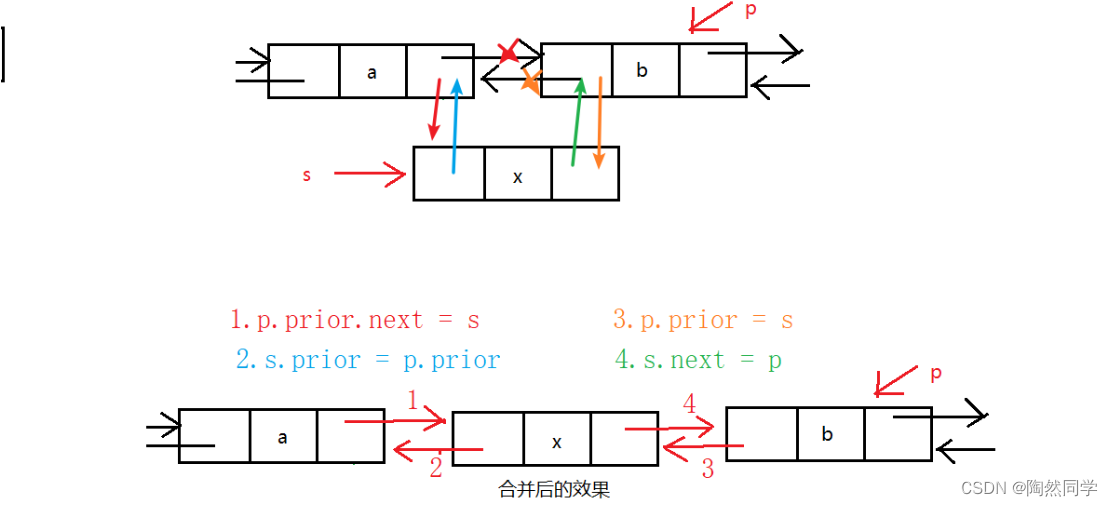
/* 变量结点a:p.prior*/p.prior.next = s;//结点a指向结点ss.prior = p.prior;// 结点s指向结点ap.prior = s;//结点p指向结点ss.next = p;//结点s执行结点p//注意:必须先处理结点a,否则无法获得结点a5.3算法:删除
-
需求:删除p结点
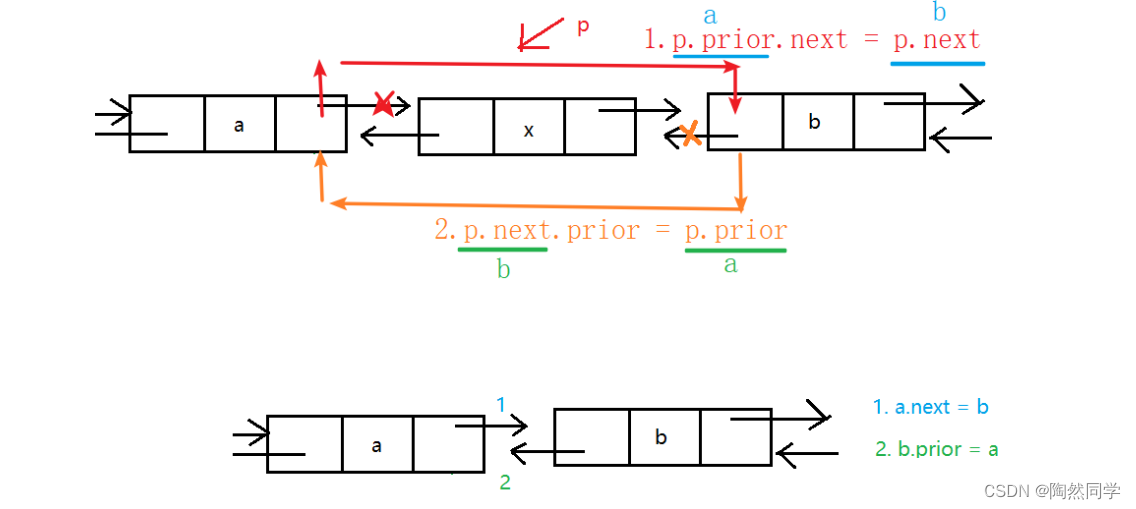
// a.next = bp.prior.next = p.next;// b.prior = ap.next.prior = p.prior6.最后
我们的数据结构就结束了 欢迎大家添加博主交流 练习过程中遇到问题也可以提供支持 如果需要学习资料 博主也可以推荐
最后 如果觉得文章对您有帮助 请给博主点赞、收藏、关注 博主会不断推出更多优质文章


