上课老师讲的经典贪心法问题:最小生成树
❤写在前面:有一说一哈夫曼有点厉害!
❤博客主页:努力的小鳴人
❤系列专栏:算法
❤欢迎小伙伴们,点赞👍关注🔎收藏🍔一起学习!
❤如有错误的地方,还请小伙伴们指正!🌹
上期热榜第三好文:🔥上课老师讲的经典贪心法问题:哈夫曼编码

目录
- 🚩最小生成树
- 1.问题描述
- 2.构造思想
-
- 🔥Prim算法
-
- 1.算法设计
- 2.构造实例
- 3.算法描述及分析
- 🔥Kruskal算法
-
- 1.算法设计
- 2.构造实例
- 3.算法描述及分析
- 3. 代码实现
-
- 🔥Prim算法 和 Kruskal算法 比较
🚩最小生成树
小科普:
一个有 n 个结点的连通图的生成树是原图的极小连通子图,且包含原图中的所有 n 个结点,并且有保持图连通的最少的边。最小生成树可以用kruskal(克鲁斯卡尔)算法或Prim(普里姆)算法求出
| 中文名 | 最小生成树 | 适用领域 | 应用图论知识的实际问题 |
|---|---|---|---|
| 外文名 | Minimum Spanning Tree,MST | 应用学科 | 计算机,数学(图论),数据结构 |
| 提出者 | Kruskal(克鲁斯卡尔)Prim(普里姆) | 算 法 | Kruskal算法,Prim算法 |
1.问题描述
🎁概述:
在一给定的无向图G = (V, E) 中,(u, v) 代表连接顶点 u 与顶点 v 的边(即),而 w(u, v) 代表此边的权重,若存在 T 为 E 的子集且为无循环图,使得联通所有结点的的 w(T) 最小,则此 T 为 G 的最小生成树
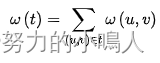
设G=(V,E)是无向连通带权图。E中每条边(v,w)的权为c[v][w]
生成树:如果G的子图G’是一棵包含G的所有顶点的树,则称G’为G的生成树
耗费:生成树上各边权的总和
最小生成树:在G的所有生成树中,耗费最小的生成树
2.构造思想
有Prim算法 和 Kruskal算法 两种解决最小生成树的算法思想
先来看一看 伪代码:
> GenerieMST(G){//求G的某棵MST
T〈-¢; //T初始为空,是指顶点集和边集均空
while T未形成G的生成树 do{
找出T的一条安全边(u,v);//即T∪{(u,v)}仍为MST的子集
T=T∪{(u,v)}; //加入安全边,扩充T
}
return T; //T为生成树且是G的一棵MST
}
注意:
下面给出的两种求MST的算法均是对上述的一般算法的求精,两算法的区别仅在于求安全边的方法不同。
为简单起见,下面用序号0,1,…,n-1来表示顶点集,即是:
V(G)={0,1,…,n-1},
G中边上的权解释为长度,并设T=(U,TE)
下面一一介绍:
🔥Prim算法
设G=(V,E)是无向连通带权图,V={1,2,…,n};设最小生成树T=(U,TE),算法结束时U=V,TE E。
首先,令U={u0},TE={}。然后,只要U是V的真子集,就做如下贪心选择:选取满足条件i U,j V-U,且边(i,j)是连接U和V-U的所有边中的最短边,即该边的权值最小。然后,将顶点j加入集合U,边(i,j)加入集合TE。继续上面的贪心选择一直进行到U=V为止,此时,选取到的所有边恰好构成G的一棵最小生成树T。需要注意的是,贪心选择这一步骤在算法中应执行多次,每执行一次,集合TE和U都将发生变化,即分别增加一条边和一个顶点
1.算法设计
实现Prim算法的关键
找到连接U和V-U的所有边中的最短边!为此必须知道V-U中的每一个顶点与它所连接的U中的每一个顶点的边的信息,该信息可通过设置两个数组closest和 lowcost来体现。中closest[j]表示V-U中的顶点j在集合U中最近邻接顶点,lowcost[j]表示V-U中的顶点j到U中的所有顶点的最短边的权值,即边(j,closest[j])的权值
步骤:
- 步骤1:确定合适的数据结构。设置带权邻接矩阵C,bool数组s[],如果s[i]=true,说明顶点i已加入集合U;设置两个数组closest[]和lowcost[];
- 步骤2:初始化。令集合U={u0},TE={},并初始化数组closest、lowcost和s;
- 步骤3:在集合V-U中寻找使得lowcost具有最小值的顶点t,t就是集合V-U中连接集合U中的所有顶点中最近的邻接顶点;
- 步骤4:将顶点t加入集合U,边(t,closest[t])加入集合TE;
- 步骤5:如果集合V=U,算法结束,否则,转步骤6;
- 步骤6:对集合V-U中的所有顶点k,更新其lowcost和closest,用下面的公式更新:if
(C[t][k]<lowcost[k]) {lowcost[k]=C[t][k];closest[k]=t;},转步骤3
🎁最小生成树应用:
例:要在n个城市之间铺设光缆,主要目标是要使这 n 个城市的任意两个之间都可以通信,但铺设光缆的费用很高,且各个城市之间铺设光缆的费用不同,因此另一个目标是要使铺设光缆的总费用最低。这就需要找到带权的最小生成树
2.构造实例
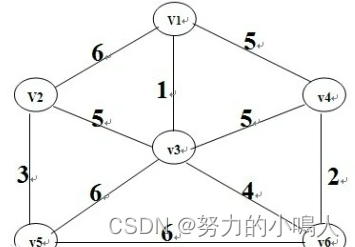
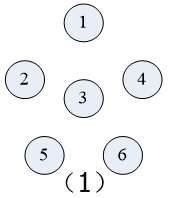
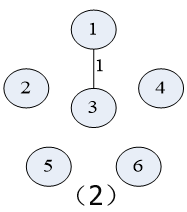
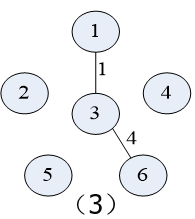
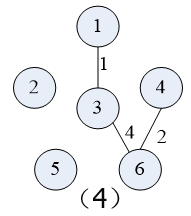
先按Prim算法对下图中的的 无向连通带权图 构造一棵 最小生成树
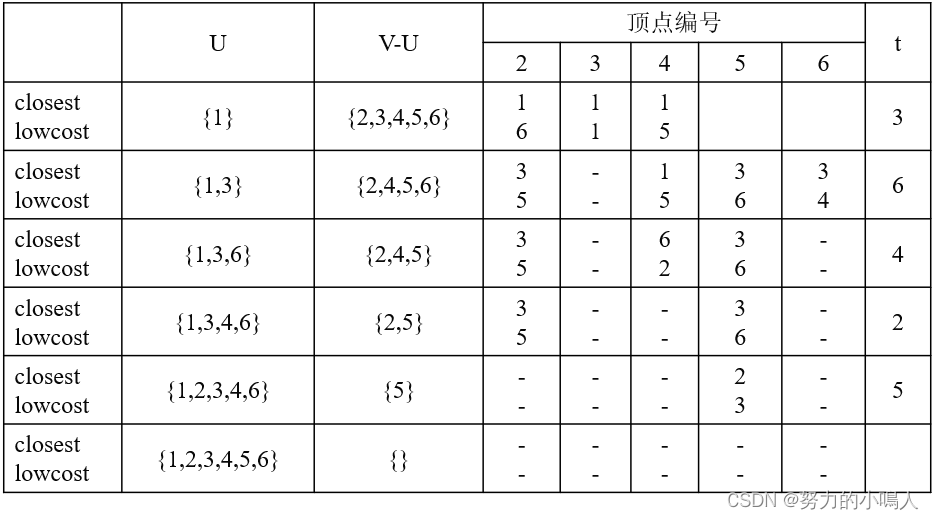
在构造实例的过程中辅助值的变化:
(假定初始顶点为顶点1,即U={1};t:集合V-U中距离集合U最近的顶点)
具体构造过程如下图示:
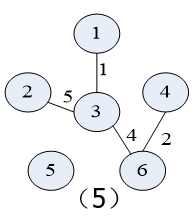
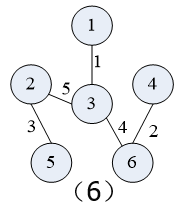
3.算法描述及分析
从算法Prim的描述可以看出,if((!s[j])&&(lowcost[j]<temp))是算法的基本语句,该语句的执行次数为n2,由此可得Prim算法的时间复杂度为O(n2)。显然该复杂性与图中的边数无关,因此,Prim算法适合于求边稠密的网的最小生成树
🎁补充:(Dijkstra算法 详情请见文章头部推荐热榜好文中有分析)
Prim算法和Dijkstra算法的用法非常相似,它们都是从余下的顶点集合中选择下一个顶点来构建一棵扩展树,但是千万不要把它们混淆了。由于解决的问题不同,计算的方式也有所不同,Dijkstra算法比较路径的长度,因此必须把边的权值相加,而Prim算法则直接比较给定的边的权值
🔥Kruskal算法
设G=(V,E)是无向连通带权图,V={1,2,…,n};设最小生成树T=(V,TE),该树的初始状态为只有n个顶点而无边的非连通图T=(V,{}),Kruskal算法将这n个顶点看成是n个孤立的连通分支。它首先将所有的边按权从小到大排序。然后,只要T中的连通分支数目不为1,就做如下的贪心选择:在边集E中选取权值最小的边(i,j),如果将边(i,j)加入集合TE中不产生回路(或环),则将边(i,j)加入边集TE中,即用边(i,j)将这两个连通分支合并连接成一个连通分支;否则继续选择下一条最短边。在这两种情况下,都把边(i,j)从集合E中删去。继续上面的贪心选择直到T中所有顶点都在同一个连通分支上为止。此时,选取到的n-1条边恰好构成G的一棵最小生成树T
1.算法设计
实现Kruskal算法的关键:
总结一下:避开环路
Kruskal算法用了一个非常聪明的方法,我也是研究好半天,就是运用集合的性质进行判断:如果所选择加入的边的起点和终点都在T的集合里,那么就可以断定一定会形成回路。因为集合的性质,如果两个点在一个集合里,就是包含的关系,那么反映到图上就一定是包含关系,咱就是说真的C
步骤:
- 步骤1:初始化。将图G的边集E中的所有边按权从小到大排序,边集TE={ },把每个顶点都初始化为一个孤立的分支,即一个顶点对应一个集合;
- 步骤2:在E中寻找权值最小的边(i,j);
- 步骤3:如果顶点 i和 j位于两个不同连通分支,则将边(i,j)加入边集TE,并执合并操作将两个连通分支进行合并;
- 步骤4:将边(i,j)从集合E中删去,即E=E-{(i,j)};
- 步骤5:如果连通分支数目不为1,转步骤2;否则,算法结束,生成最小生成树T
2.构造实例
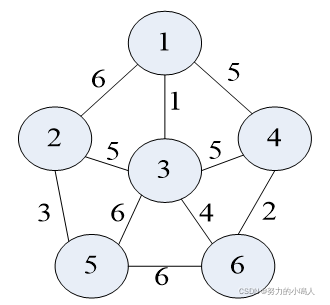
现在按Kruskal算法对下图中的的 无向连通带权图 构造一棵 最小生成树
首先将图的边集E中的所有边 按权从小到大排序 为:1(1,3)、2(4,6)、3(2,5)、4(3,6)、5(1,4) 和(2,3)和(3,4)、6(1,2)和(3,5)和(5,6)
其次依次构造即可:
(于Prim算法中的构造相同)
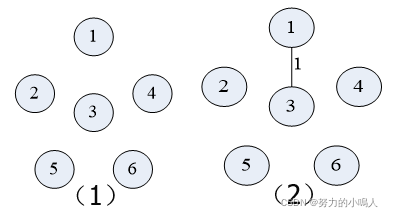
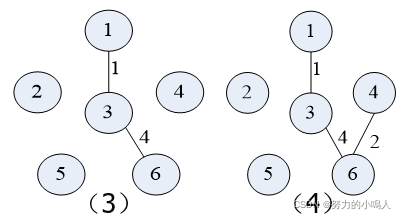
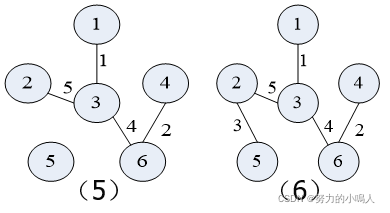
3.算法描述及分析
从算法设计思想和设计步骤可以看出,要实现Kruskal算法必须解决以下两个关键问题:
(1)选取权值最小的边的同时,要判断加入该条边后树中是否出现回路
(2)不同的连通分支如何进行合并
为了便于解决这两大问题,必须了解每条边的信息
在Kruskal算法中所设计的每条边的结点信息存储结构如下:
struct edge{
double weight; //边的权值
int u,v; // u为边的起点,v为边的终点。
}bian[];
sort函数耗时最大,为此算法的时间复杂性为O(eloge)
3. 代码实现
下面是完整代码实现:
(C/C++)
#include#include#include#define MAX_VERTEX_NUM 20#define OK 1#define ERROR 0#define MAX 1000typedef struct Arcell{double adj;}Arcell,AdjMatrix[MAX_VERTEX_NUM][MAX_VERTEX_NUM];typedef struct{char vexs[MAX_VERTEX_NUM]; //节点数组AdjMatrix arcs; //邻接矩阵int vexnum,arcnum; //图的当前节点数和弧数}MGraph;typedef struct Pnode //用于普利姆算法{char adjvex; //节点double lowcost; //权值}Pnode,Closedge[MAX_VERTEX_NUM]; //记录顶点集U到V-U的代价最小的边的辅助数组定义typedef struct Knode //用于克鲁斯卡尔算法中存储一条边及其对应的2个节点{char ch1; //节点1char ch2; //节点2double value;//权值}Knode,Dgevalue[MAX_VERTEX_NUM];//-----------------------------------------------------------------------------------int CreateUDG(MGraph & G,Dgevalue & dgevalue);int LocateVex(MGraph G,char ch);int Minimum(MGraph G,Closedge closedge);void MiniSpanTree_PRIM(MGraph G,char u);void Sortdge(Dgevalue & dgevalue,MGraph G);//-----------------------------------------------------------------------------------int CreateUDG(MGraph & G,Dgevalue & dgevalue) //构造无向加权图的邻接矩阵{int i,j,k;cout<<"请输入图中节点个数和边/弧的条数:";cin>>G.vexnum>>G.arcnum;cout<<"请输入节点:";for(i=0;i<G.vexnum;++i)cin>>G.vexs;for(i=0;i<G.vexnum;++i)//初始化数组{for(j=0;j<G.vexnum;++j){G.arcs[j].adj=MAX;}}cout<<"请输入一条边依附的定点及边的权值:"<<endl;for(k=0;k<G.arcnum;++k){cin >> dgevalue[k].ch1 >> dgevalue[k].ch2 >> dgevalue[k].value;i = LocateVex(G,dgevalue[k].ch1);j = LocateVex(G,dgevalue[k].ch2);G.arcs[j].adj = dgevalue[k].value;G.arcs[j].adj = G.arcs[j].adj;}return OK;}int LocateVex(MGraph G,char ch) //确定节点ch在图G.vexs中的位置{int a ;for(int i=0; i<G.vexnum; i++){if(G.vexs == ch)a=i;}return a;}void MiniSpanTree_PRIM(MGraph G,char u)//普利姆算法求最小生成树{int i,j,k;Closedge closedge;k = LocateVex(G,u);for(j=0; j<G.vexnum; j++){if(j != k){closedge[j].adjvex = u;closedge[j].lowcost = G.arcs[k][j].adj;}}closedge[k].lowcost = 0;for(i=1; i<G.vexnum; i++){k = Minimum(G,closedge);cout<<"("<<closedge[k].adjvex<<","<<G.vexs[k]<<","<<closedge[k].lowcost<<")"<<endl;closedge[k].lowcost = 0;for(j=0; j<G.vexnum; ++j){if(G.arcs[k][j].adj < closedge[j].lowcost){closedge[j].adjvex = G.vexs[k];closedge[j].lowcost= G.arcs[k][j].adj;}}}}int Minimum(MGraph G,Closedge closedge) //求closedge中权值最小的边,并返回其顶点在vexs中的位置{int i,j;double k = 1000;for(i=0; i<G.vexnum; i++){if(closedge.lowcost != 0 && closedge.lowcost < k){k = closedge.lowcost;j = i;}}return j;}void MiniSpanTree_KRSL(MGraph G,Dgevalue & dgevalue)//克鲁斯卡尔算法求最小生成树{int p1,p2,i,j;int bj[MAX_VERTEX_NUM]; //标记数组for(i=0; i<G.vexnum; i++) //标记数组初始化bj=i;Sortdge(dgevalue,G);//将所有权值按从小到大排序for(i=0; i<G.arcnum; i++){p1 = bj[LocateVex(G,dgevalue.ch1)];p2 = bj[LocateVex(G,dgevalue.ch2)];if(p1 != p2){cout<<"("<<dgevalue.ch1<<","<<dgevalue.ch2<<","<<dgevalue.value<<")"<<endl;for(j=0; j<G.vexnum; j++){if(bj[j] == p2)bj[j] = p1;}}}}void Sortdge(Dgevalue & dgevalue,MGraph G)//对dgevalue中各元素按权值按从小到大排序{int i,j;double temp;char ch1,ch2;for(i=0; i<G.arcnum; i++){for(j=i; j<G.arcnum; j++){if(dgevalue.value > dgevalue[j].value){temp = dgevalue.value;dgevalue.value = dgevalue[j].value;dgevalue[j].value = temp;ch1 = dgevalue.ch1;dgevalue.ch1 = dgevalue[j].ch1;dgevalue[j].ch1 = ch1;ch2 = dgevalue.ch2;dgevalue.ch2 = dgevalue[j].ch2;dgevalue[j].ch2 = ch2;}}}}void main(){int i,j;MGraph G;char u;Dgevalue dgevalue;CreateUDG(G,dgevalue);cout<<"图的邻接矩阵为:"<<endl;for(i=0; i<G.vexnum; i++){for(j=0; j<G.vexnum; j++)cout << G.arcs[j].adj<<" ";cout<<endl;}cout<<"=============普利姆算法===============\n";cout<<"请输入起始点:";cin>>u;cout<<"构成最小代价生成树的边集为:\n";MiniSpanTree_PRIM(G,u);cout<<"============克鲁斯科尔算法=============\n";cout<<"构成最小代价生成树的边集为:\n";MiniSpanTree_KRSL(G,dgevalue);}🔥Prim算法 和 Kruskal算法 比较
- 算法思想上:如果图G中的边数较小时,可采用Kruskal,因为Kruskal算法每次查找最短的边;
如果边数较多可用Prim算法,因为它是每次加一个顶点,推出:Kruskal适用于稀疏图,而Prim适用于稠密图 - 时间上:Prim算法的时间复杂度为O(n2),Kruskal算法的时间复杂度为O(eloge)
- 空间上:在Prim算法中,只需要很小的空间就可以完成算法,因为每一次都是从个别点开始出发进行扫描的,而且每一次扫描也只扫描与当前顶点集对应的边
但在Kruskal算法中,因为时刻都要知道当前边集中权值最小的边在哪里,这就需要对所有的边进行排序,对于很大的图而言,Kruskal算法需要占用比Prim算法大得多的空间
🎁总结:这俩算法真的难搞,懂了就行,用来锻炼自己,实现也太难了哈哈
👌 作者算是一名Java初学者,文章如有错误,欢迎评论私信指正,一起学习~~
😊如果文章对小伙伴们来说有用的话,点赞👍关注🔎收藏🍔就是我的最大动力!
🚩不积跬步,无以至千里,书接下回,欢迎再见🌹
 创作打卡挑战赛
创作打卡挑战赛  赢取流量/现金/CSDN周边激励大奖
赢取流量/现金/CSDN周边激励大奖