在Jetson Nano上编译onnxruntime
更新:
1)因为MS把onnxruntime从github迁移到一个独立的网址了,所以下面的一些链接都指向不对了,需要到ONNX Runtime (ORT) - onnxruntime里去找对应的内容,可能是MS自己都对自己的文档组织太乱看不下去了,迁移到独立网址后重新整理了一下,比原来有条理了,但是对于初学者可能还是感到发懵 ![]()
2)对于python版的onnxruntime,Links for onnxruntime 这里有whl安装文件下载。
因为做模型精度损失的对比需要,上个月用过了MS家的onnxruntime (GitHub - microsoft/onnxruntime: ONNX Runtime: cross-platform, high performance ML inferencing and training accelerator),一如MS的产品风格,要求不高的小项目用还凑合,不要指望有多高的性能能用在大规模项目上,不过它有个好处就是支持了多种OS和CPU,支持多种语言,常用的python和C/C++版都能很快用起来,用来在多个不同硬件平台上做模型推理的快速验证和做对比还是不错的,比如一个模型用python调用精度很好,改用onnxruntime调用它精度也差不多很好,但如果用NVIDIA的TensorRT解析后推理精度就降了很多,那就可以确认问题是在TensorRT里,可以信心十足向NVIDIA提bug了。
下面说说在Jetson Nano上如何从源码build出可以在Nano或者其他Jetson板子上使用的onnxruntime的so和wheel安装包,GitHub - microsoft/onnxruntime: ONNX Runtime: cross-platform, high performance ML inferencing and training accelerator文档感觉凌乱,一开始看感觉不好从哪里下手,看了上面多个build文档和API文档后才领会到要怎么它把build出来和怎么编程调用(编程方面另外写一篇)。
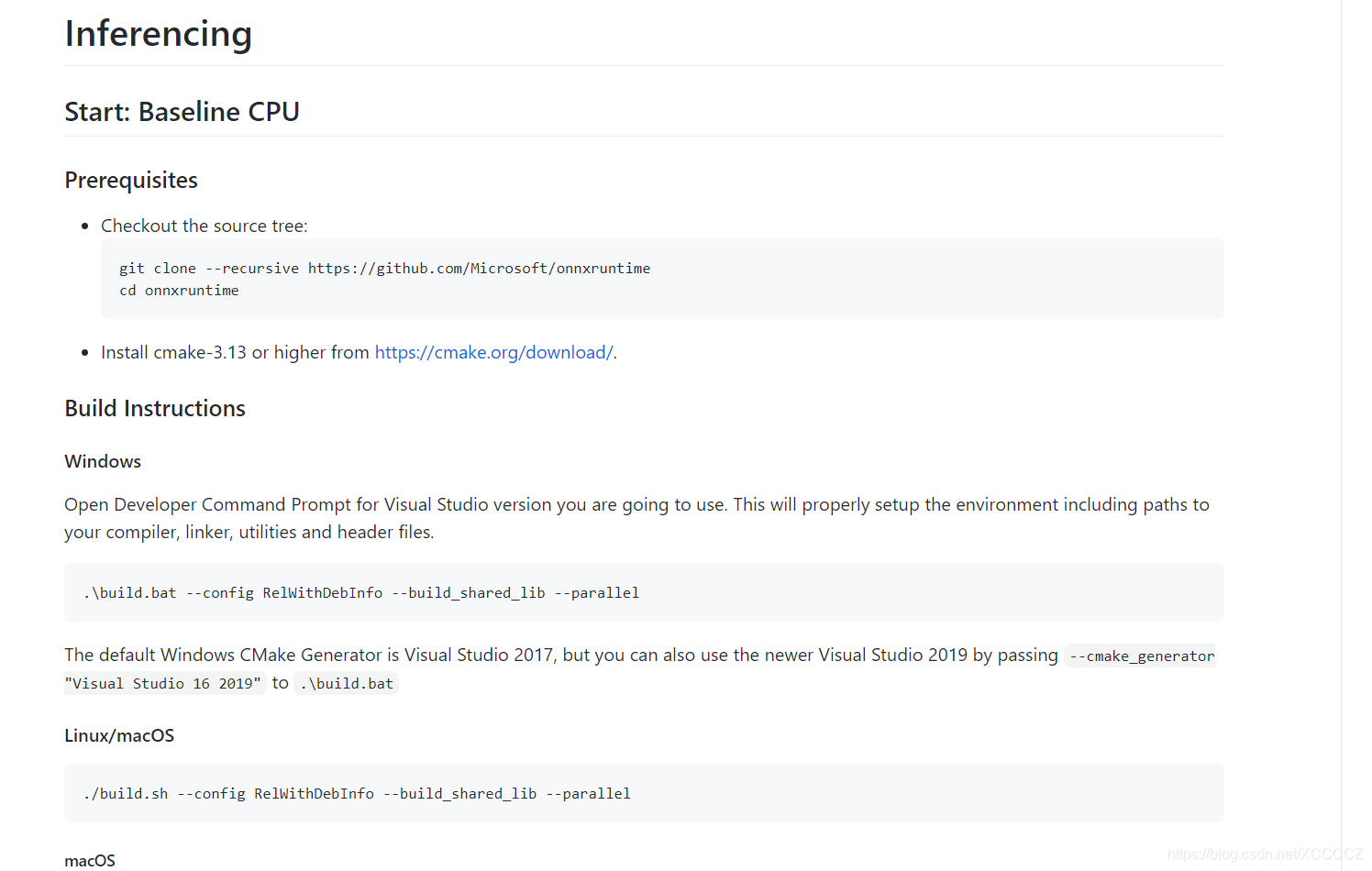
点这里的build from source里的Instructions for additional build flavors

进入到https://github.com/microsoft/onnxruntime/blob/master/BUILD.md,如果你只是想在X86 PC或服务器上快速跑起来验证一下模型,不考虑性能什么的,简单的build一个CPU baseline版就行了:
按照https://github.com/microsoft/onnxruntime/blob/master/BUILD.md#start-baseline-cpu这里说的做:
如果是需要在Jetson板子上使用它,还是有些坑的,这么多Provider:

该按照哪个做好?如果是在Jetson板子上,其实要综合前面三个Provider的内容都得看看,然后根据自己的需要做合理的搭配,经过几次实验后,我在Jetson Nano上编译出了支持TensorRT和CUDA的支持多CPU核并行协同工作的build,下面说说步骤:
首先如果你的板子上之前没安装过常用的支持包,可能需要做下面的步骤:
sudo apt-get updatesudo apt-get install -y \ build-essential \ curl \ libcurl4-openssl-dev \ libssl-dev \ wget \ python3 \ python3-pip \ git \ tarpip3 install --upgrade pippip3 install --upgrade setuptoolspip3 install --upgrade wheelpip3 install numpysudo apt install -y --no-install-recommends \ build-essential software-properties-common \ libopenblas-dev libpython3.6-dev python3-pip python3-dev 其次,保证你的Jetson板子上用的cmake版本符合要求:

不符合则下载源码编译安装一个比较高的版本:
wget https://cmake.org/files/v3.17/cmake-3.17.3.tar.gz;tar zxf cmake-3.17.3.tar.gzcd /code/cmake-3.17.3./configure --system-curl #如果不嫌时间花的多,直接执行./configure也行makesudo make install然后:
sudo apt-get install protobuf-compiler libprotoc-devexport PATH=/usr/local/cuda/bin:${PATH}export CUDA_PATH=/usr/local/cudaexport cuDNN_PATH=/usr/lib/aarch64-linux-gnuexport CMAKE_ARGS="-DONNX_CUSTOM_PROTOC_EXECUTABLE=/usr/bin/protoc"mkdir /codecd /codegit clone --recursive https://github.com/Microsoft/onnxruntimegit submodule update --init --recursive --progresscd /code/onnxruntime./build.sh --update --config Release --enable_pybind --build_shared_lib --build --build_wheel \--use_openmp --use_tensorrt --tensorrt_home /usr/src/tensorrt --cuda_home /usr/local/cuda --cudnn_home /usr/lib/aarch64-linux-gnu注意加上--use_openmp这个选项,openmp用于单机上的多CPU/多核并行,Jetson板子上一般CPU都是多核的,加了这个选项才能用上多核,尤其是Provider设置为CPU时(默认,调用onnxruntim时不对Provider做任何设置,默认使用CPU推理)
如果要打印出模型网络的输入/输出节点,加上--cmake_extra_defines onnxruntime_DEBUG_NODE_INPUTS_OUTPUTS=1 ,不过不推荐,因为它这个不是在onnxruntime启动时打印,而是每次推理时都打印,稍有点影响性能。
在Jetson Nano上编译完大约需要5小时左右,编译完后,查看编译出来的so和wheel包:
ls -l /code/onnxruntime/build/Linux/MinSizeRel/*.sols -l /code/onnxruntime/build/Linux/MinSizeRel/dist/*.whl如果你只python调用python版的onnxruntime,直接安装这个wheel文件即可,如果是需要使用C/C++编程调用onnxruntime,则需要在编译你的应用程序时把/include/onnxruntime/core下的头文件包含到include路径里并且把这些so文件链接到你的应用程序。

