MySQL缓存策略(一致性问题、数据同步以及缓存故障)
MySQL缓存策略(一致性问题、数据同步以及缓存故障)
- 一、数据库有哪些提升读写性能的方式呢?
-
- 1、连接池和异步连接
- 2、读写分离
-
- 主从复制
- 二、为什么需要缓冲层?
-
- 1、前提
- 2、mysql
- 3、缓冲层
- 4、存储比较
- 5、几项重要的数据
- 6、总结
- 三、引入缓存
- 四、为什么有同步的问题?
- 五、尝试解决同步(一致性)
- 六、一致性问题以及如何解决
-
- 1、强一致性
- 2、最终一致性
- 七、如何实现数据同步呢?
-
- 1、数据同步方案
- 八、缓存故障
-
- 1、缓存穿透
- 2、缓存击穿
- 3、缓存雪崩
一、数据库有哪些提升读写性能的方式呢?
- 连接池:阻塞io+线程池
- 异步连接:非阻塞io
- 从sql执行出发:即时执行+预编译执行(可以直接跳过句法分析、优化器等步骤,执行速度更快)
- 读写分离
- 缓存方案
1、连接池和异步连接
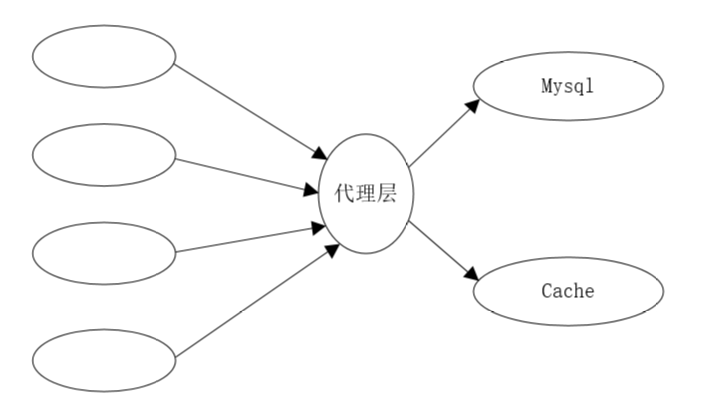
左边是多个线程来操作数据库和缓存,可以加上代理层proxy统一管理
或者使用dbserver(代理层)去代理访问数据库
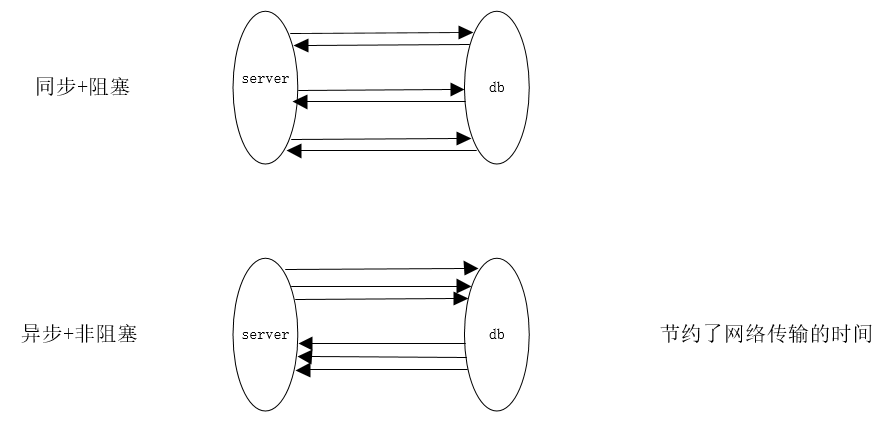
skynet采用异步连接的方式,节约了网络传输的时间。
openresty采用的是连接池的方式
2、读写分离

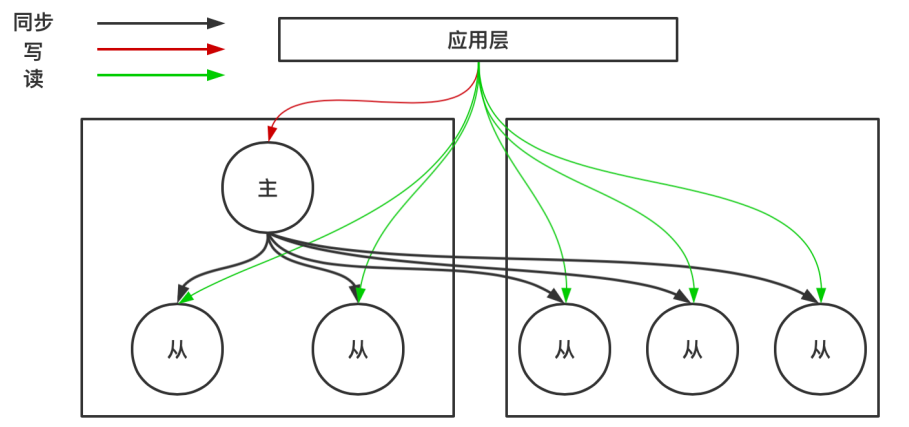
适用于读远比写多的场景,分摊服务器压力,提高机器的系统处理效率
主从复制这种集群方式:解决了单点故障问题(比如主数据库宕机了,就可以从 从数据库去获得备份)
主从复制还可以实现读写分离,将读写操作,分配到主从数据库中,分摊服务器压力
但是这个方案,由于主从复制并不能保证同时复制到从数据库中,因而可能在中途出现读取数据不一致的问题,但是最终是一致的(具体要看业务使用场景)。
下面介绍主从复制的原理
主从复制
原理图
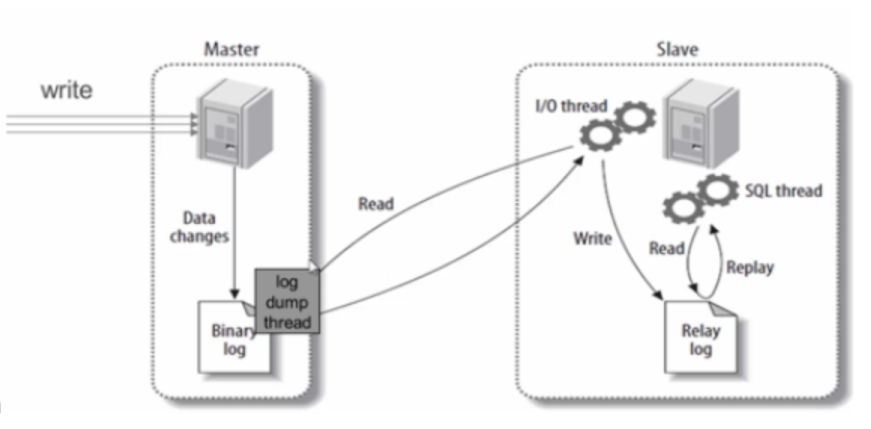
- 主库更新事件(update、insert、delete)通过 io-thread 写到binlog;
- 从库请求读取 binlog,通过 io-thread 写入(write)从库本地 relay log(中继日志);
- 从库通过sql-thread读取(read) relay log,并把更新事件在从库中执行(replay)一遍;
复制流程:
- Slave上面的IO进程连接上Master,并请求从指定日志文件的指定位置(或者从最开始的日
志)之后的日志内容。 - Master接收到来自Slave的IO进程的请求后,负责复制的IO进程会根据请求信息读取日志指
定位置之后的日志信息,返回给Slave的 IO进程。返回信息中除了日志所包含的信息之外,
还包括本次返回的信息已经到Master端的bin-log文件的名称以及bin-log的位置。 - Slave的IO进程接收到信息后,将接收到的日志内容依次添加到Slave端的relay-log文件的最
末端,并将读取到的Master端的 bin-log的文件名和位置记录到master-info文件中,以便在
下一次读取的时候能够清楚的告诉Master从何处开始读取日志。 - Slave的Sql进程检测到relay-log中新增加了内容后,会马上解析relay-log的内容成为在
Master端真实执行时候的那些可执行的内容,并在自身执行。
写的时候写主数据库,读的时候读从数据库
二、为什么需要缓冲层?
1、前提
读多写少,单个主节点能支撑项目数据量;数据的主要依据是 mysql;
2、mysql
mysql 有缓冲层,它的作用也是用来缓存热点数据,这些数据包括数据文件、索引文件等;mysql
缓冲层是从自身出发,跟具体的业务无关;这里的缓冲策略主要是 lru,当然是经过优化的 lru;
mysql数据主要存储在磁盘当中,适合大量重要数据的存储;磁盘当中的数据一般是远大于内存当
中的数据;一般业务场景关系型数据库(mysql)作为主要数据库;
3、缓冲层
缓存数据库可以选用redis,memcached;它们所有数据都存储在内存当中,当然也可以将内存
当中的数据持久化到磁盘当中;内存的数据和磁盘的数据是一比一的;
4、存储比较
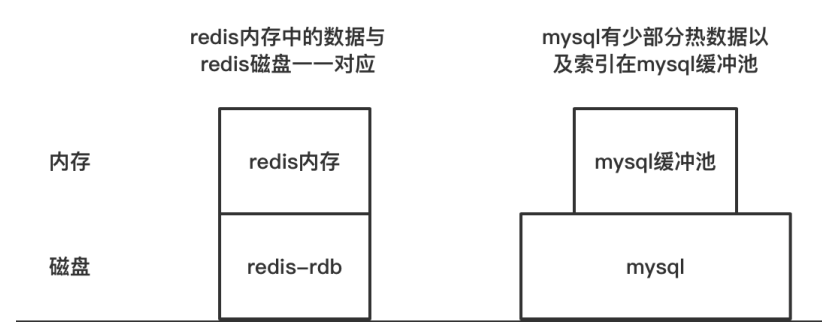
5、几项重要的数据
- 内存的访问速度是磁盘访问速度的10万倍(数量级倍率);内存的访问速度大约是100ns,
而一次磁盘访问大约是10ms;访问mysql时访问磁盘的次数跟b+树的高度相关; - 一般大部分项目中,数据库读操作是写操作的10倍左右;
6、总结
- 由于mysql的缓冲层不由用户来控制,也就是不能由用户来控制缓存具体数据;
- 访问磁盘的速度比较慢,尽量获取数据从内存中获取;
- 主要解决读的性能;因为写没必要优化,必须让数据正确的落盘;如果写性能出现问题,那
么请使用横向扩展集群方式来解决; - 项目中需要存储的数据应该远大于内存的容量,同时需要进行数据统计分析,所以数据存储
获取的依据应该是关系型数据库; - 缓存数据库可以存储用户自定义的热点数据;以下的讨论都是基于热点数据的同步问题;
三、引入缓存


在没有引入缓存前,是服务器直接访问mysql,由于mysql的读写性能(磁盘io较慢)问题,额外再使用一个缓存数据库
原理图
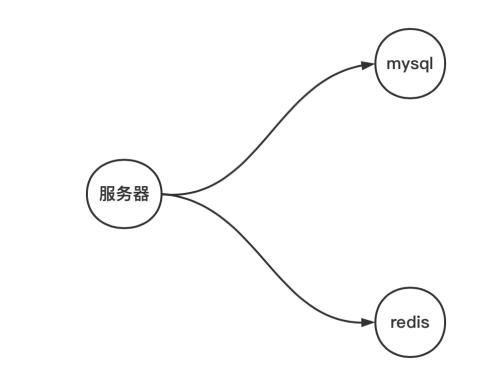
为了解决mysql的读写性能(磁盘io较慢)问题,增加了缓存数据库(cache,比如redis),主要用于缓存用户的热点数据(内存访问的速度相比磁盘快很多)。
mysql是主要数据库,数据主要依据
cache缓存用户的热点数据
mysql中的缓冲池和这里的缓存的区别?
mysql中也有缓冲池,但是它存储的mysql的索引等数据,是mysql内部的热点数据。
这里的缓存cache是为了缓存业务中用户的热点数据。
例子:
比如12点钟有个秒杀活动,12点会涌入大量用户,但是12点前几乎没什么人登入,从而mysql中没有相应的缓存热点数据,为了能使得12点用户正常登入,因此要提前缓存用户的热点数据,避免大量用户涌入,mysql磁盘读写的性能直接影响到的了整个系统的响应能力。
需要考虑的问题
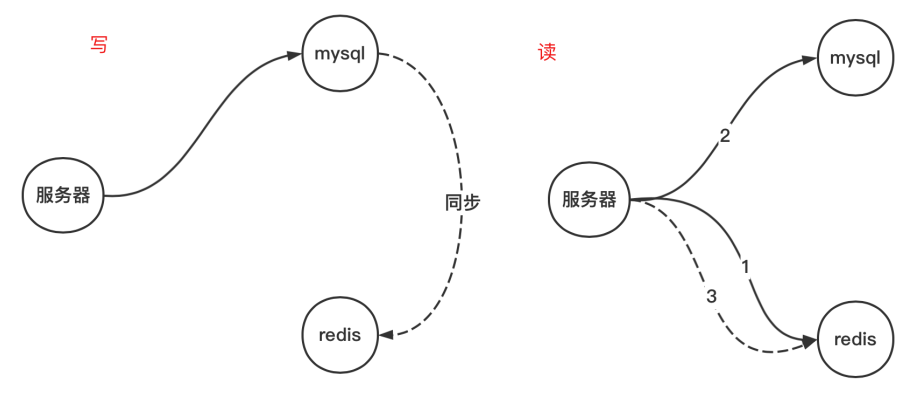
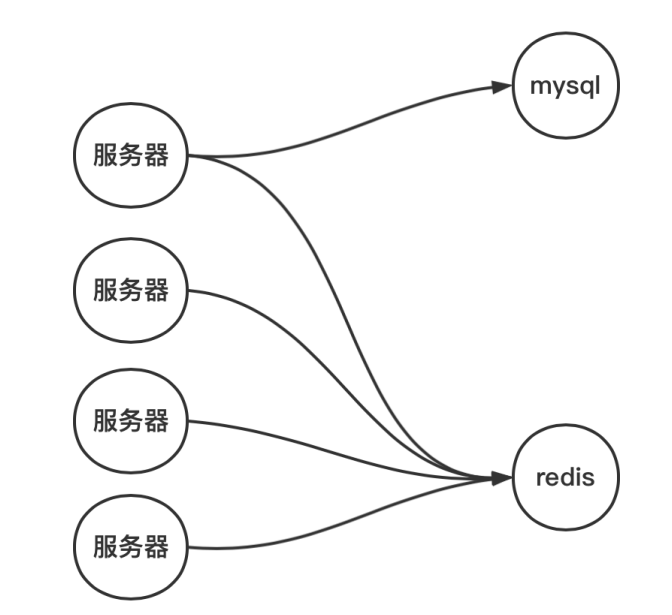
在没有缓存cache的时候,仅有一个mysql,(读:直接读mysql,写:直接写mysql)那么去访问很容易,现在有了mysql和cache,因此需要指定相应的缓存策略
四、为什么有同步的问题?
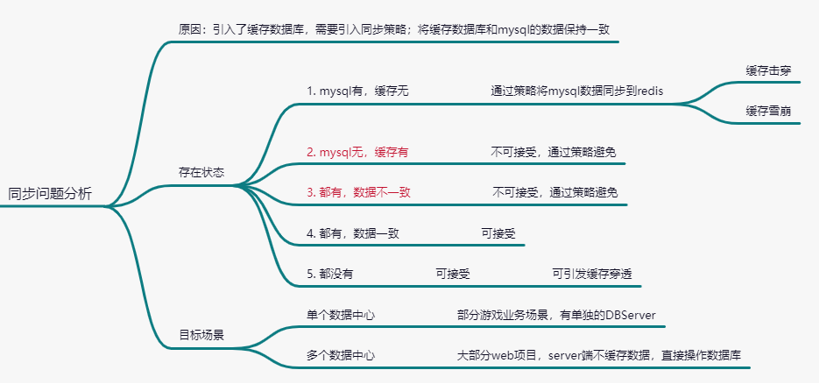
没有缓冲层之前,我们对数据的读写都是基于 mysql;所以不存在同步问题;这句话也不是必
然,比如读写分离就存在同步问题(数据一致性问题);
引入缓冲层后,我们对数据的获取需要分别操作缓存数据库和 mysql;那么这个时候数据可能存
在几个状态?
针对热点数据讨论,热点数据有以下几种状态
1.mysql有,cache没有(正常的情况下,可以通过策略去避免它)
2.mysql没有,cache有(不正常,避免)
3.mysql和cache都有,数据不一致(不正常,避免)
4.mysql和cache都有,数据一致(策略最终要实现的目的)
5.mysql和cache都没有(正常)
五、尝试解决同步(一致性)
制定读写策略
读策略:
1.先看cache是否有数据,如果有直接返回
2.如果没有,去访问mysql
3.如果mysql有,缓存数据传cache
4.如果mysql中没有,说明数据没有
写策略:
有 删除、修改、插入 这几种操作。
在写策略中,会出现一致性的问题
六、一致性问题以及如何解决
1、强一致性

强一致性(任何时候都要保证访问mysql和cache中对应数据的一致):当cache中数据不存在的时候,就会去访问mysql,也能保证强一致性。具体选择哪种一致性,跟业务逻辑有关)
也就是说,不能出现 1.mysql没有,cache有 2.mysql和cache都有,数据不一致
这种情况的出现
缓存和数据库一致性问题
实现强一致性的方案
删除:先去删除缓存(避免出现.mysql没有,cache有这种情况),
修改: 删除缓存,再去修改mysql(调换顺序,如果先修改mysql可能会出现,读到的可能是缓存中还没更新的数据,导致缓存和mysql中数据不一致问题)
插入:删除缓存,再去修改mysql(新数据避免缓存里已经有了这个数据,也是要先删除缓存)
上述这样操作后变成了(mysql有,cache没有)情况,cache中删除了,而我们最终要达到的目的是(mysql和cache都有,数据一致),因此要将mysql中的数据同步到cache(redis)当中。
即使是mysql中数据同步到cache中,有时间延迟,但是顺序是一致的,如下方的黑色(mysql中数据)和红色时间线(cache中数据),如果有数据还未到达cache,那么会直接访问mysql,能保证强一致性。
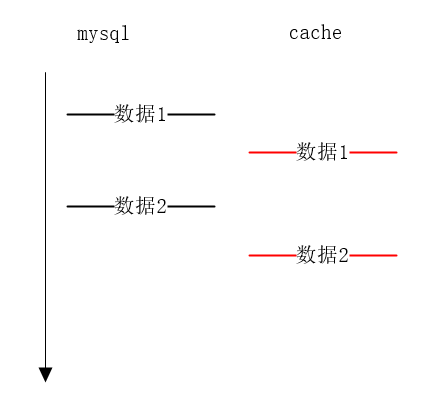
Redis缓存和MySQL数据一致性的后端高并发架构解决方案
2、最终一致性

读写分离,主库将数据同步到从库,是需要时间,那么在同步期间,主从之间数据有差异;
这里有写两种方案:
第一种:直接写mysql,等待mysql同步数据到redis;
第二种:先写redis,设置key的过期时间为200ms(经验值),等待mysql回写redis,覆盖key,
设置更长的过期时间;
200ms 默认的是 写mysql到mysql同步到redis的时长;这个需要根据实际环境进行设置;
最终一致性(开始不一致,最终访问mysql和cache中对应数据达成一致):在修改过程中,读取数据可能会出现mysql和cache中数据不一致的问题
如果读写分离,一致性要求高
第一种:主从半同步辅助
第二种:直接去主数据读取
实现最终一致性的方案:给缓存设置失效时间
1)先更新缓存,后更新数据库
写的时候往缓存中写,同时设置缓存的失效时间,失效后再刷入数据库
在性能方面,比方案一的性能要高。(这是先更新缓存,后更新数据库的情况,但是可能会出现问题)
2)先更新数据库,后更新缓存
写的时候只往数据库mysql写,刷新(同步)到cache中,同时,写入缓存中的数据,都设置失效时间(这样后续更新该数据的时候,不需要删除这一步骤了,缓存中失效删除后,会直接访问mysql从而保证强一致性)

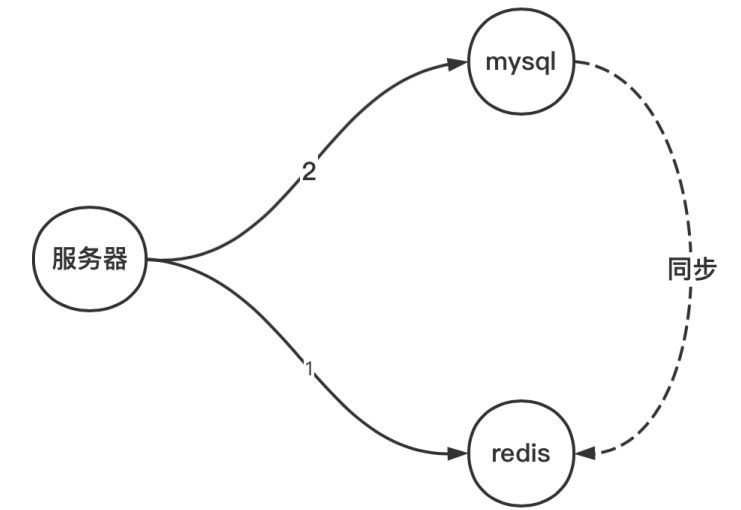
七、如何实现数据同步呢?
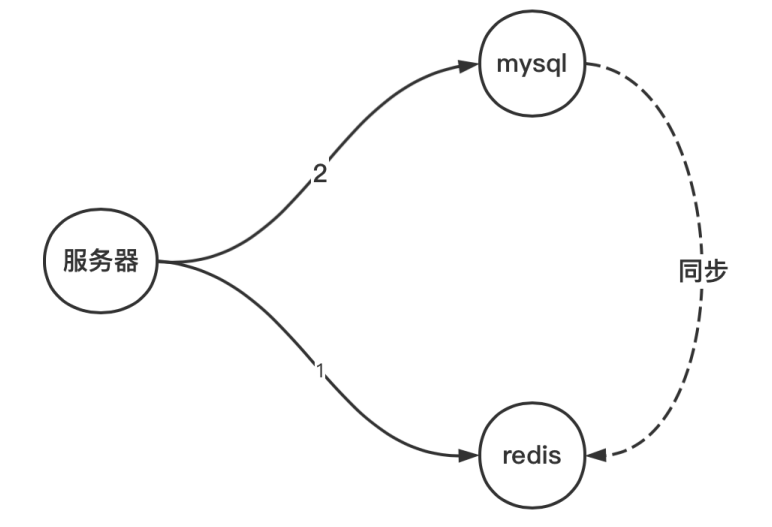
在读取数据的时候,如果redis中没有相应的数据,就会将mysql中的数据同步到redis中,那么如何实现这个数据同步呢?
也就是下图中,虚线那个过程
数据同步方案
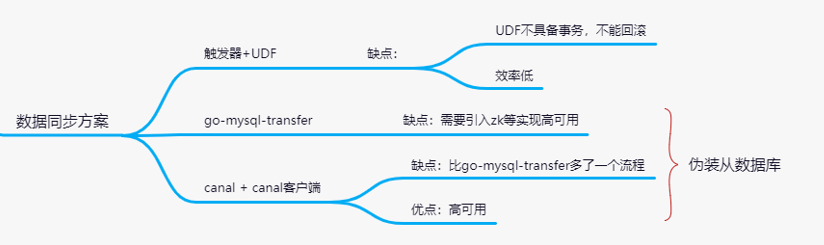
对于 触发器+UDF(user define function),不建议使用,会出现异常数据,效率非常低
1、数据同步方案
中间采用 一个组件 使得数据同步
mysql发送数据给canel
然后redis从canel客户端取数据
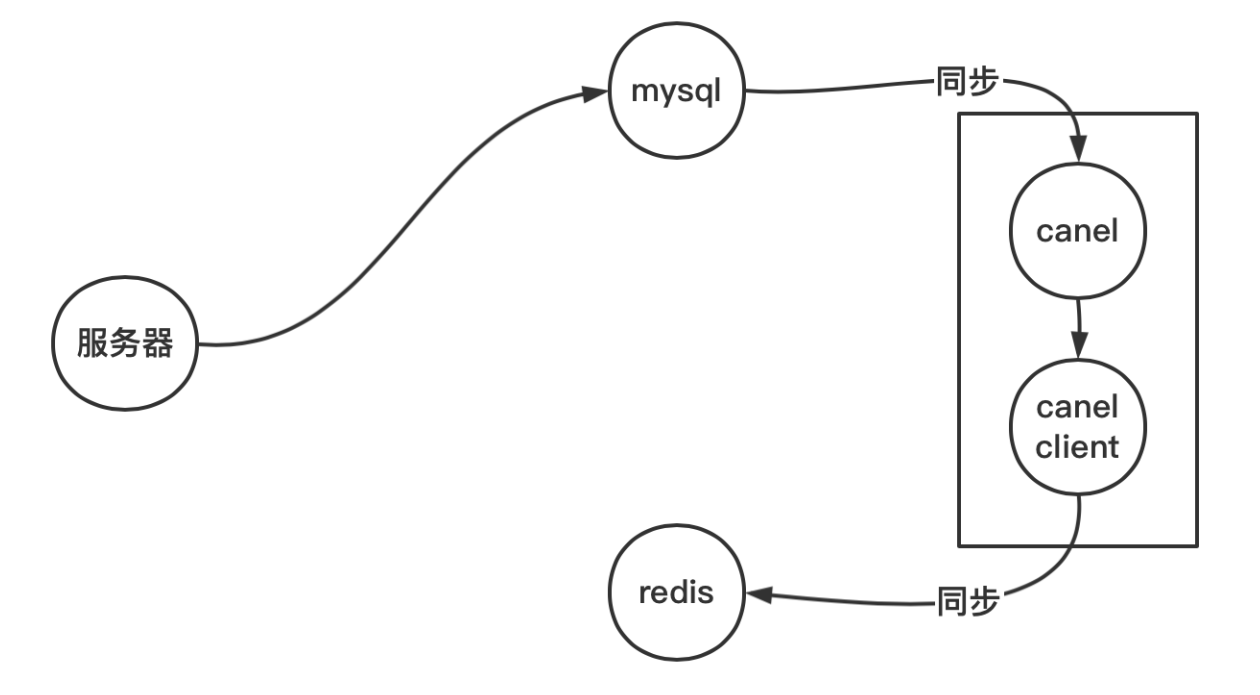
还有一种方案是
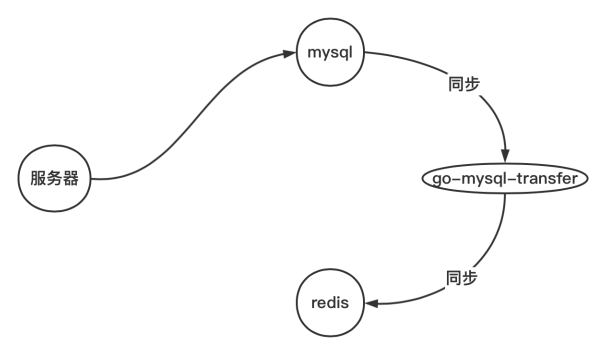
实现的原理就是,将中间件(go-mysql-transfer)伪装成一个从数据库,通过主从复制数据,然后再用中间件同步给redis
既然已经复制到 从数据库了
那么如果将数据通过 从数据库(中间件) 同步到redis呢?
首要对于中间件部分,它需要知道
1.mysql和redis的连接地址
2.热点数据是什么?定义热点数据
3.定义热点数据同步
八、缓存故障
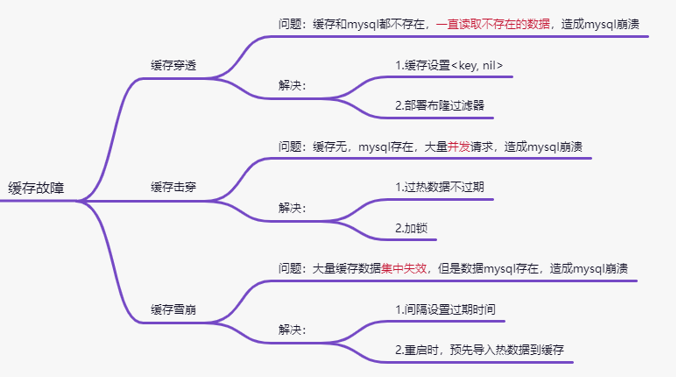
1、缓存穿透
假设某个数据redis不存在,mysql也不存在,而且一直尝试读怎么办?缓存穿透,数据最终压力
依然堆积在mysql,可能造成mysql不堪重负而崩溃;
解决
- 发现mysql不存在,将redis设置为 设置过期时间 下次访问key的时候 不再访问
mysql 容易造成redis缓存很多无效数据; - 布隆过滤器,将mysql当中已经存在的key,写入布隆过滤器,不存在的直接pass掉;
2、缓存击穿
缓存击穿 某些数据redis没有,但是mysql有;此时当大量这类数据的并发请求,同样造成mysql
过大
解决
- 加锁
请求数据的时候获取锁,如果获取成功,则操作,获取失败,则休眠一段时间(200ms)再去获
取;获取成功,则释放锁
首先读redis,不存在,读mysql,存在,写redis key的锁
整个流程走完,才让后面的服务器访问
(给其他并发的访问要去获取锁,让没有获得锁的进行阻塞,让获得锁的去访问mysql,然后将数据同步入redis中,这样其他访问就就可以直接去访问redis,而不必都去访问mysql,从而减轻mysql的压力) - 将很热的key,设置不过期
3、缓存雪崩
表示一段时间内,缓存集中失效(redis无 mysql 有),导致请求全部走mysql,有可能搞垮数据库,
使整个服务失效;
解决
缓存数据库在整个系统不是必须的,也就是缓存宕机不会影响整个系统提供服务;
- 如果因为缓存数据库宕机,造成所有数据涌向mysql;
采用高可用的集群方案,如哨兵模式、cluster模式; - 如果因为设置了相同的过期时间,造成缓存集中失效;
设置随机过期值或者其他机制错开失效时间; - 如果因为系统重启的时候,造成缓存数据消失;
重启时间短,redis开启持久化(过期信息也会持久化)就行了; 重启时间长提前将热数据导
入redis当中;
缓存雪崩和缓存击穿的区别?
缓存雪崩和缓存击穿 都是数据在 mysql有,redis无 的情况,
缓存击穿是指1个key并发访问mysql
缓存雪崩是指大量或者全部的key并发访问mysql
相关链接:
推荐一个零声学院免费公开课程,个人觉得老师讲得不错,分享给大家:Linux,Nginx,ZeroMQ,MySQL,Redis,fastdfs,MongoDB,ZK,流媒体,CDN,P2P,K8S,Docker,TCP/IP,协程,DPDK等技术内容,立即学习

