【数据分析 —— 认识数据】
数据分析 —— 认识数据
文章目录
- 数据分析 —— 认识数据
- 数据基本统计描述 —— 集中趋势
-
- 均值
- 中位数
- 众数
- 数据的基本统计描述-离散趋势
-
- 极差
- 四分位数
- 五数概括
- 箱线图
- 多个箱线图
- 方差和标准差
- DataFrame 描述性统计
- 数据的基本统计描述 - 基本统计图
-
- 条形图
- 饼状图
- 折线图
- 直方图
- 散点图
- 分位数 - 分位数图
- 绘制词云
- 统计
-
- 次序统计量
- 平均值和方差
- 关联
- 直方图/柱状图
NumPy是Python中科学计算的基础包。它是一个Python库,提供多维数组对象、各种派生对象(例如掩码数组和矩阵)以及用于对数组进行快速操作的各种例程,包括数学、逻辑、形状操作、排序、选择、I/O 、离散傅里叶变换、基本线性代数、基本统计运算、随机模拟等等。
numpy官方网址
numpy官方文档地址
pandas是一个开源的、BSD 许可的库,为Python编程语言提供高性能、易于使用的数据结构和数据分析工具。
Pandas 官网
Pandas 官方文档
Pandas 中文网
以下为学习数据分析的一些笔记
数据基本统计描述 —— 集中趋势
均值
- 计算每个属性的均值
numpy模块下的mean()方法
import numpy as npfrom sklearn.datasets import load_irisiris_data = load_iris()print(iris_data.data)# 矩阵大小print(iris_data.data.shape)# 获取第一条数据print(iris_data.data[0,:])# 获取第一个维度的所有取值作为一维向量print(iris_data.data[:,0]) # 1行150列的一位数组# 获取第一个维度的所有取值, 作为二位数组print(iris_data.data[:,np.newaxis,0]) # 150行1列的二维数组# print(iris_data.data[:,np.newaxis,0].shape)# 求均值# 计算每个属性的均值mean1 = np.mean(iris_data.data,axis=0) # 当axis=0时, 按数组每列做均值, 即每一列的数相加除以行数, 得到4个每列的均值mean2 = np.mean(iris_data.data,axis=1) # 当axis=1时, 按数组每行做均值, 即每一行的数相加除以列数,得到150个每行的均值print(mean1)print(mean2)中位数
-
计算每个属性的中位数
-
numpy模块下的median()方法
import numpy as npfrom sklearn.datasets import load_irisiris_data = load_iris()print(iris_data.data)# 矩阵大小print(iris_data.data.shape)# 获取第一条数据print(iris_data.data[0,:])# 获取第一个维度的所有取值作为一维向量print(iris_data.data[:,0]) # 1行150列的一位数组# 获取第一个维度的所有取值, 作为二位数组print(iris_data.data[:,np.newaxis,0]) # 150行1列的二维数组# print(iris_data.data[:,np.newaxis,0].shape)# 求中位数# 计算每个属性的中位数median = np.median(iris_data.data,axis=0) # 即每列的中位数print(median)median2 = np.median(iris_data.data,axis=1) # 即每行的中位数print(median2)众数
- 计算出现次数最多的属性
# 求众数# 第一种使用numpy库import numpy as npimport randomdata = [random.choice(range(1,5)) for i in range(100)]print(data)# 使用bincount求众数counts = np.bincount(data)print(counts) # 统计相同的数出现的次数print(np.argmax(counts))'''举个栗子[ 0 25 26 27 22] # 表示0,1,2,3,4这5个数出现是次数, 其中3出现次数最多为27次, 则为众数3'''# 第二种使用scipy下的statis模块 【推荐使用】from scipy import statss1 = stats.mode(data) # ModeResult(mode=array([3]), count=array([27]))s2 = stats.mode(data)[0][0] # 求得众数# s3 = stats.mode(data)[:][:]# print(s1)print(s2)# print(s3)数据的基本统计描述-离散趋势
极差
-
import numpy as np#测试数据from sklearn.datasets import load_irisiris_data = load_iris()feature_1 = iris_data.data[:,0]print(feature_1)# 极差# 第一种直接用最大值减去最小值method1 = feature_1.max()-feature_1.min()# 第二种使用numpy中的方法method2 = np.max(feature_1)-np.min(feature_1)print(method1)print(method2)# 注 : 数据中若有nan空值, 则可以使用numpy模块中的nanmax和nanmin的方法# method2 = np.nanmax(feature_1)-np.nanmin(feature_1)
四分位数
-
import numpy as np#测试数据from sklearn.datasets import load_irisiris_data = load_iris()feature_1 = iris_data.data[:,0]print(feature_1)# 四分位数# 使用numpy中的percentile方法Q3 = np.percentile(feature_1,0.75)print(Q3)Q1 = np.percentile(feature_1,0.25)print(Q1)# 四分位数极差(四分位距)IQR = Q3-Q1print(IQR)# 注 : 若数据中有空值nan, 同样也可以使用 nanpercentile的方法
五数概括
-
import numpy as np#测试数据from sklearn.datasets import load_irisiris_data = load_iris()feature_1 = iris_data.data[:,0]print(feature_1)# 五数概括max_value = np.max(feature_1)Q3 = np.percentile(feature_1,0.75)median_value =np.median(feature_1)Q1 = np.percentile(feature_1,0.25)min_value = np.min(feature_1)print(min_value,Q1,median_value,Q3,max_value)
箱线图
-
#测试数据from sklearn.datasets import load_irisiris_data = load_iris()feature_1 = iris_data.data[:,0]print(feature_1)import matplotlib.pyplot as pltplt.boxplot(x=feature_1) plt.ylabel('values of ' + iris_data.feature_names[0]) # 纵轴标签plt.xlabel(iris_data.feature_names[0]) # 横轴标签plt.show() # 显示绘制图 -
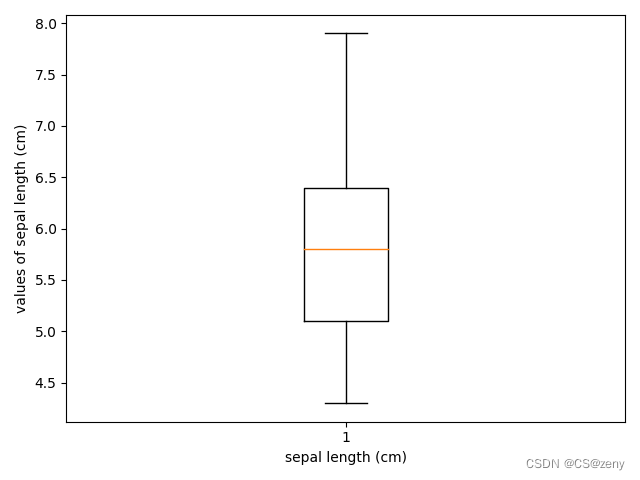
多个箱线图
-
# 测试数据from sklearn.datasets import load_irisiris_data = load_iris()feature_1 = iris_data.data[:,0]print(feature_1)# 多个箱线图from pandas import DataFrameiris_df = DataFrame(iris_data.data, columns=iris_data.feature_names)# fig, axes = plt.subplots(4,1) # 绘制四行一列的箱线图fig, axes = plt.subplots(1,4) # 绘制一行四列的箱线图iris_df.plot(kind='box', ax=axes, subplots=True, title='All feature boxplc')axes[0].set_ylabel(iris_df.columns[0]) #设置纵轴属性名axes[1].set_ylabel(iris_df.columns[1])axes[2].set_ylabel(iris_df.columns[2])axes[3].set_ylabel(iris_df.columns[3])fig.subplots_adjust(wspace=1, hspace=1)fig.show() #显示绘制的图形 -
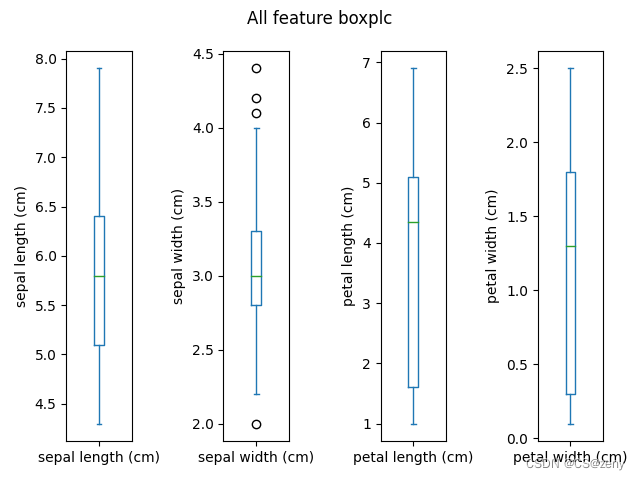
方差和标准差
-
方差 :
numpy模块中的var方法 -
标准差 :
numpy模块中的std方法 -
# 测试数据import numpy as npfrom sklearn.datasets import load_irisiris_data = load_iris()feature_1 = iris_data.data[:,0]print(feature_1)# 方差和标准差# 方差var = np.var(feature_1)print(var)# 所有维度的方差var_all = np.var(iris_data.data,axis=0)print(var_all)# 标准差std = np.std(feature_1)print(std)# 所有维度的标准差std_all = np.std(iris_data.data,axis=0)print(std_all)
DataFrame 描述性统计
DataFrame.describe(percentiles=None,include=None,exclude=None,datetime_is_numeric=False)
- 生成描述性统计数据。
- 描述性统计包括那些总结数据集分布的集中趋势、分散和形状的统计,不包括
NaN值。 - 分析数字和对象系列,以及
DataFrame混合数据类型的列集。
参数
-
percentiles : 列表,可选
要包含在输出中的百分位数。全部应介于 0 和 1 之间。默认值为 ,它返回第 25、第 50 和第 75 个百分位数。
[.25, .5, .75] -
include :
all,dtypes 或None(默认), 列表,可选要包含在结果中的数据类型白名单。忽略为
Series。以下是选项:all:输入的所有列都将包含在输出中。类似列表的 dtypes :将结果限制为提供的数据类型。将结果限制为数字类型 submitnumpy.number。要将其限制为对象列,请提交numpy.object数据类型。字符串也可以以select_dtypes(例如df.describe(include=['O']))的样式使用。要选择 pandas 分类列,请使用'category'无(默认):结果将包括所有数字列。 -
exclude : dtypes 或 None (默认)的类似列表,可选,
要从结果中省略的数据类型的黑名单。忽略为
Series。以下是选项:A list-like of dtypes :从结果中排除提供的数据类型。要排除数字类型,请提交numpy.number. 要排除对象列,请提交数据类型numpy.object。字符串也可以以select_dtypes(例如df.describe(exclude=['O']))的样式使用。要排除 pandas 分类列,请使用'category'无(默认):结果将不排除任何内容。 -
datetime_is_numeric :
bool,默认False是否将 datetime dtypes 视为数字。这会影响为列计算的统计信息。对于 DataFrame 输入,这还控制默认情况下是否包含日期时间列。
举个栗子 :
-
DataFrame描述性统计-
import numpy as npfrom sklearn.datasets import load_irisiris_data = load_iris()from pandas import DataFrameiris_df = DataFrame(iris_data.data, columns=iris_data.feature_names)# DataFrame 描述性统计de = iris_df.describe() # 生成描述性统计数据print(de) -
输出:sepal length (cm) sepal width (cm) petal length (cm) petal width (cm)count 150.000000 150.000000 150.000000 150.000000mean 5.843333 3.057333 3.758000 1.199333std 0.828066 0.435866 1.765298 0.762238min 4.300000 2.000000 1.000000 0.10000025% 5.100000 2.800000 1.600000 0.30000050% 5.800000 3.000000 4.350000 1.30000075% 6.400000 3.300000 5.100000 1.800000max 7.900000 4.400000 6.900000 2.500000
-
数据的基本统计描述 - 基本统计图
条形图
# 测试数据import numpy as npfrom sklearn.datasets import load_irisiris_data = load_iris()sample_1 = iris_data.data[0,:]import matplotlib.pyplot as plt# 条形图p1 = plt.bar(range(1, len(sample_1)+1),height = sample_1,tick_label = iris_data.feature_names,width=0.3)plt.ylabel('cm') # 纵轴标签plt.title('bar of first data') #标题plt.show() # 显示绘制的图形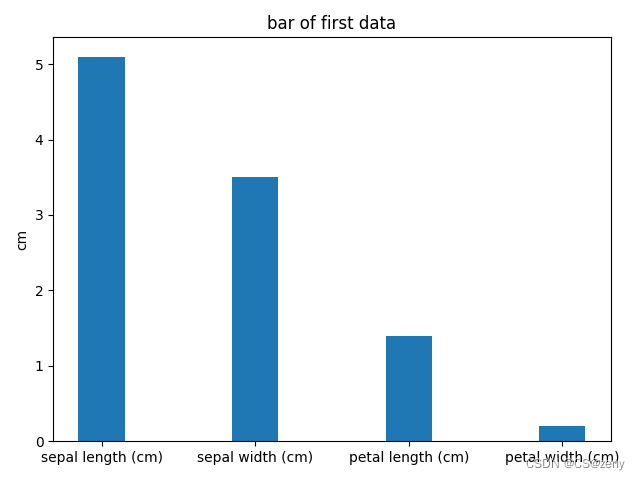
饼状图
import matplotlib.pyplot as plt# 饼状图labels = 'Sunny', 'Windy', 'Frogy', 'Snow' # 每部分的标签名sizes = [15, 30, 45, 10] # 占的比例explode = (0, 0.1, 0, 0) # 这⾥只弹出第⼆个天⽓ (Windy)fig1, ax1 = plt.subplots() # 绘制ax1.pie(sizes, explode=explode, labels=labels, autopct='%1.1f%%',shadow=True, startangle=90)ax1.axis('equal') # 相等的长宽比确保以cirr的形式绘制饼图plt.show() #展示绘制图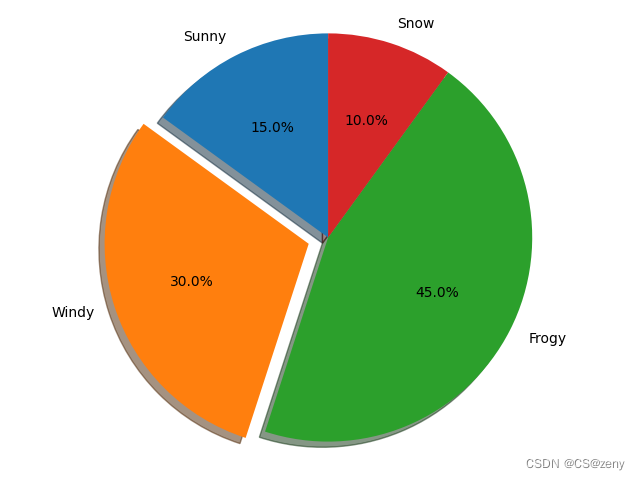
折线图
import numpy as npimport matplotlib.pyplot as pltx = np.arange(0, 5, 0.1) # x自变量的范围y = np.sin(x) # sin函数plt.plot(x, y) # 绘制折线图plt.show() #展示绘制图
直方图
import numpy as npfrom sklearn.datasets import load_irisimport matplotlib.pyplot as pltiris_data = load_iris()feature_2 = iris_data.data[:,1]plt.hist(feature_2, bins=10)plt.show()
散点图
from sklearn.datasets import load_irisimport matplotlib.pyplot as pltiris_data = load_iris()feature_1 = iris_data.data[:,0]feature_3 = iris_data.data[:,2]plt.scatter(feature_1,feature_3)plt.show()
分位数 - 分位数图
from sklearn.datasets import load_irisfrom scipy import statsiris_data = load_iris()import matplotlib.pyplot as pltfeature_3 = iris_data.data[:,2]res = stats.probplot(feature_3, plot=plt)plt.show()
绘制词云
import jiebafrom wordcloud import WordCloudimport PILimport osimport numpy as npdef chinese_jieba(txt): words = jieba.lcut(txt) # 将⽂本分割,返回列表 wordlist_jieba = [] for word in words: if len(word) == 1 or len(word) > 3: # 将大于3或等于1的字过滤掉 continue else: wordlist_jieba.append(word) txt_jieba = " ".join(wordlist_jieba) # 将列表拼接为以空格为间断的字符串 return txt_jiebastopwords = {'这些':0, '那些':0, '因为':0, '所以':0}alice_mask = np.array(PIL.Image.open('boji.jpg'))with open('data.txt', encoding='utf8') as fp: txt = fp.read() cutted_text = chinese_jieba(txt) # print(txt) wordcloud = WordCloud( font_path = r'simsun.ttc', # 字体文件 路径一般在`C:\Windows\Fonts` 将其中一个文件拷贝过来和代码放一起即可background_color = 'white', # 背景⾊max_words = 200, # 最⼤显示单词数max_font_size = 80, # 频率最⼤单词字体⼤⼩stopwords=stopwords, # 过滤停⽤词 width=800, height=600, mask=alice_mask, contour_width=1, contour_color='blue',).generate(cutted_text) image = wordcloud.to_image() image.show()wordcloud.to_file('词云图.png') # 生成图片文件具体使用可参考 python词云制作(最全最详细的教程)
官方提供的参考资料, 点击对应的方法即会跳转到官方的文档对应的内容
统计
次序统计量
| 方法 | 说明 |
|---|---|
ptp(a[, axis, out, overwrite_input, keepdims]) |
沿轴的值范围(最大值 - 最小值)。 |
percentile(a[, axis, weights, returned]) |
沿指定轴计算数据的第 q 个百分位数。 |
nanpercentile(a, q[, axis, out, …]) |
计算沿指定轴的数据的第 q 个百分位数,同时忽略 nan 值。 |
quantile(a, q[, axis, out, overwrite_input, …]) |
沿指定轴计算数据的第 q 个分位数。 |
nanquantile(a, q[, axis, out, …]) |
沿指定轴计算数据的第 q 个分位数,同时忽略 nan 值。 |
平均值和方差
| 方法 | 说明 |
|---|---|
median(a[, axis, out, overwrite_input, keepdims]) |
计算沿指定轴的中位数。 |
average(a[, axis, weights, returned]) |
计算沿指定轴的加权平均值。 |
mean(a[, axis, dtype, out, keepdims, where]) |
计算沿指定轴的算术平均值。 |
std(a[, axis, dtype, out, ddof, keepdims, where]) |
计算沿指定轴的标准偏差。 |
var(a[, axis, dtype, out, ddof, keepdims, where]) |
计算沿指定轴的方差。 |
nanmedian(a[, axis, out, overwrite_input, …]) |
计算沿指定轴的中位数,同时忽略 NaN。 |
nanmean(a[, axis, dtype, out, keepdims, where]) |
计算沿指定轴的算术平均值,忽略 NaN。 |
nanstd(a[, axis, dtype, out, ddof, …]) |
计算沿指定轴的标准偏差,同时忽略 NaN。 |
nanvar(a[, axis, dtype, out, ddof, …]) |
计算沿指定轴的方差,同时忽略 NaN。 |
关联
| 方法 | 说明 |
|---|---|
corrcoef(x[, y, rowvar, bias, ddof, dtype]) |
返回 Pearson 积矩相关系数。 |
correlate(a, v[, mode]) |
两个一维序列的互相关。 |
cov(m[, y, rowvar, bias, ddof, fweights, …]) |
给定数据和权重,估计协方差矩阵。 |
直方图/柱状图
| 方法 | 说明 |
|---|---|
histogram(a[, bins, range, normed, weights, …]) |
计算数据集的直方图。 |
histogram2d(x, y[, bins, range, normed, …]) |
计算两个数据样本的二维直方图。 |
histogramdd(sample[, bins, range, normed, …]) |
计算一些数据的多维直方图。 |
bincount(x, /[, weights, minlength]) |
计算非负整数数组中每个值的出现次数。 |
histogram_bin_edges(a[, bins, range, weights]) |
仅计算函数使用的 bin 边缘的histogram函数。 |
digitize(x, bins[, right]) |
返回输入数组中每个值所属的 bin 的索引。 |
 创作打卡挑战赛
创作打卡挑战赛  赢取流量/现金/CSDN周边激励大奖
赢取流量/现金/CSDN周边激励大奖

