腾讯云数据库TDSQL-学习心得与收获
文章目录
- 前言
-
- 🚀 1.初始TDSQL
- 🚀 2.TDSQL学习的必要性
-
- 🌈 2.1 去 IOE
- 🌈 2.1 TDSQL的优势
- 🌈 2.3 分布式主流
- 🚀 3.TDSQL介绍
-
- 🌈 3.1 什么是TDSQL ?
- 🌈 3.2 布式事务
- 🌈 3.3 智能运维
- 🚀 4.如何体系化学习TDSQL
前言
TDSQL是腾讯推出的一款兼容MySQL,自主可控,兼高一致性的分布式数据库,我来分享下学习心得与收获
🚀 1.初始TDSQL
在2020年12月24日,腾讯云数据库官宣TDSQL品牌整合升级计划,集中发力数据库技术创新突破。腾讯云原有的TDSQL、TBase、CynosDB三大产品线统一升级为“腾讯云企业级分布式数据库TDSQL”。
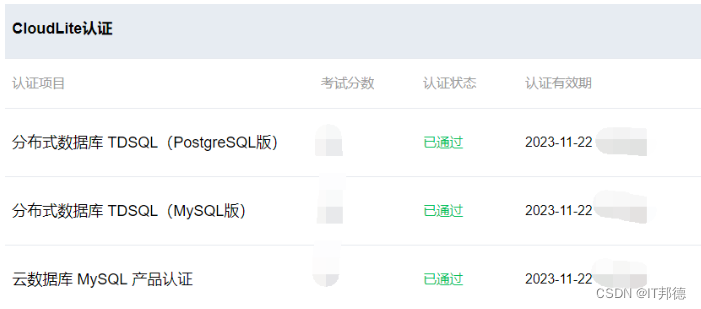
那一年我正好在负责银行的数据库维保工作,为了能够尽快满足客户的需求,我觉得要认证一下TDSQL,于是参加了腾讯云CloudLite认证, 这个认证是基于腾讯云产品的轻量级线上认证,为开发者提供在线课程,实验手册,线上考试等系列内容,助力开发者提升自身技术能力。

一共包括3个认证,如下所示,而且是免费哦,当时还参加了体系化的培训,收获很大
TDSQL认证:https://cloud.tencent.com/edu/cert/cloudlite/

🚀 2.TDSQL学习的必要性
🌈 2.1 去 IOE
2009 年,阿里巴巴提出了去“IOE”的口号。
所谓“IOE”,I 是指服务器提供商 IBM,O 是指数据库软件提供商 Oracle,E 则是指存储设备提供商 EMC,三者构成了一个从软件到硬件的企业数据库系统。
“去 IOE”就是要摆脱对这三家公司的过度依赖
TDSQL的发展,经过了漫长的时间。从2007年开始,腾讯从开源的MySQL中走上了自主研发的道路,在2012年TDSQL正式诞生,并且2年后正式在微众银行第一个对外商业使用。次年又放在公有云上,目标是替代传统银行的核心系统,众所周知,银行的核心业务用的是Oracle数据库,一直是被Oracle公司垄断,但是Oracle又贵又是国外的。虽然好用,但是我们应该有属于我们自己自主研发的核心技术才行,自主研发替代Oracle的数据库势在必行。 在2019年,张家港银行首次完成了核心业务的替换,使用了TDSQL。这一事件是TDSQL迈向银行业务的里程碑
🚩中国工商银行、中国建设银行…这样的知名大行都在其中,其中很多都是腾讯云数据库服务的客户哦!
腾讯云分布式数据库TDSQL已服务近半国内TOP20的银行,其中TOP10银行中服务比例高达60%。

🌈 2.1 TDSQL的优势
🚩6个核心特性,完全满足了现代银行的核心业务。
这6个特性分别是
1.数据强一致性:
确保多副本架构下数据强一致性,避免故障后导致集群数据错乱和丢失
2.金融级高可用:
确保99.999%以上高可用,跨区容灾,同城双活;故障自动恢复
3.高性能低成本:
软硬结合,支持读写分离,对秒杀,红包,全球同服等超高性能场景。
4.企业级安全性:
数据库防火墙,透明加密,自动备份,快速恢复。减少用户误操作/或黑客带来的入侵的风险。
5.线性水平扩展:
在线无缝扩容,高效透明的分布式事务
6.便捷的运维:
完善的配套设施。包括智能DBA,自主化运营管理台。
🌈 2.3 分布式主流
分布式数据库进入人们的视野已经很久了。相对于传统的集中式数据库,分布式数据库在高性能、高可用、平滑拓展、高可靠、低成本等许多方面具有优势。
以金融领域为例,2020年10月31日,平安银行“A+信用卡核心系统”正式由腾讯云TDSQL分布式数据库承载。系统基于分布式架构,采用私有云和PssS平台建设,实现了应用微服务化,能够按客户维度进行分片,行方所有的客户的业务均可以在单个分片完成,包括交易授权、用卡业务,也包括行方的批量业务,通过shard-nothing分布式架构,可以实现透明水平扩容。
🚩🚩 分布式数据库发展趋势
目前,国内绝大部分数据库企业均推出了分布式数据库产品,我国分布式数据库发展基本与国际同步,在一些技术指标和应用层面甚至处于领先水平。在未来,分布式数据库可能会朝着这些方向发展。
1、分布式数据库的产品化日趋成熟
随着国产分布式数据库在金融、互联网等重点行业中的应用,促使产品技术不断迭代,兼容性、易用性、可扩展性等问题将一一克服。未来随着分布式数据库等的标准体系及评价体系的健全,分布式数据库产品的生态体系也将逐渐完善,在运维保障、数据迁移、运行监测等方面的配套工具也将逐步成熟。
2.、与人工智能等新技术融合实现高效运维
在数字经济的推动下,数据的全生命周期管理尤为重要,而分布式数据库数据通常由几十台至数千台服务器组成,数据库的运维显得尤为重要。随着人工智能技术的发展,将人工智能技术融入分布式数据库的全生命周期,实现自运维、自管理、自调优、故障自诊断和自愈,是未来发展的必然趋.势。另外,在交易、分析和混合负载场景下,可以通过人工智能的学习算法,实现数据库的自动调优。
3.、分布式数据库的服务方式将向云化发展
云计算技术已在我国各行业信息化建设中大规模应用,为适应未来信创领域信息化建设技术方向,降低数据库运维成本,灵活调度资源,国内数据库厂商积极布局云数据库产品及服务。阿里云、腾讯云、华为等已经发布了基于自有云平台的云数据库产品,传统数据库厂商达梦也推出云数据库产品。总体上,国内云数据库与国际先进水平基本持平,为未来信创云数据库发展提供良好基础。
🚀 3.TDSQL介绍
🌈 3.1 什么是TDSQL ?
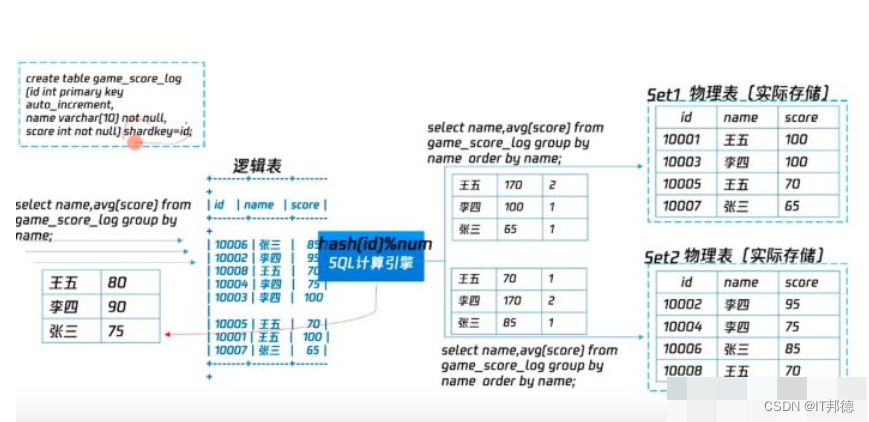
TDSQL是腾讯推出的一款兼容MySQL,自主可控,兼高一致性的分布式数据库。它支持水平自动拆分,有完整的业务逻辑表,而且数据被均匀拆分到多个物理分片中,有效的解决超大并发,超高性能,超大容量的OLTP类场景。
补充知识:OLTP类场景是针对线上购物节,发红包,秒杀等商业活动需要用到高频次交易,超高频次的数据读写场景。
TDSQL的每个分片默认采用主从高可用架构,提供弹性扩展,备份,恢复,监控等全套解决方案,有效解决业务发展时面临的各种需求和挑战。
🌈 3.2 布式事务
当业务访问时,首先通过负载均衡LVS转发流量,负载均衡是基于TCP/IP协议高性能的连接,然后通过SQL引擎解析路由信息,解析其中的SQL语句,读写分离判断,产生全局唯一值。SQL引擎通常设置3台,且没有主备之分全是对等的。解析完之后的SQL语句分发到对应的set上的MySQL底层,再由MySQL去执行。MySQL上有一个agent,通过agent与zookeeper关联。在部署的时候,agent和MySQL部署在一起。整个架构的核心是SQL引擎,MySQL存储引擎和zookeeper管理节点。
Zookeeper分布式协调系统管理维护整个集群元数据管理和通知作用。Hadoop负责备份,数据库的数据。Kafka主要是负责SQL的审计、多源同步。操作整个系统则是通过前台赤兔管理平台,通过赤兔平台设置任务,监控,采集,备份以完成日常基本的运维服务。
🚩🚩 我们看一下一条SQL在TDSQL上执行的过程
当执行完提交之后,保证主库和备库一致。就会进行强同步,而强同步至少要1主1备的架构,当主库从一个备库返回的之后,主库再返回到事务协调,等所有的分片执行完操作之后会进行确定,如果出现数据错误,这时候就会做回滚处理。
🌈 3.3 智能运维
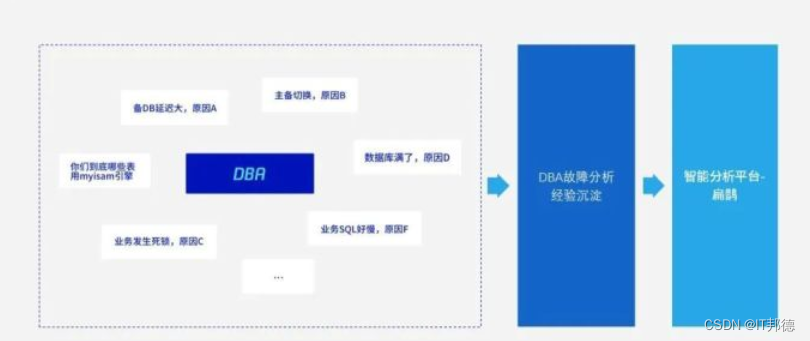
“赤兔”平台是TDSQL提供的产品服务之一,
它从管理员视角提供TDSQL的全部运维功能和上百项数据库状态监控指标的展示,
让数据库管理员日常90%以上的操作均可通过界面化完成,同时更方便定位排查问题。

扁鹊系统是TDSQL面向云市场推出的一款针对数据库性能/故障等问题的自动化分析并为用户提供优化/解决的产品,
它提供包括数据采集、实时检测、自动处理、性能检测与健康评估、SQL性能分析、业务诊断等多种智能工具的集合。
“赤兔”和“扁鹊”这一套组合拳既满足高星级业务的精细化运维,
又能轻松应对大量的普通数据库运维需求,
更好地帮助用户降低运维成本。
🚀 4.如何体系化学习TDSQL
我们要学分布式数据库的另一个原因在于,你可以通过学习它的设计思想,提高自己的架构设计水平和代码能力。分布式数据库是学术研究与工业实践的完美结合,深入其中你会看到很多极致的设计方法。通过学习分布式数据库的架构设计,形成内化的设计能力,一定是架构师的要诀之一。
TiDB也在努力培育市场,技术社区做得有声有色,在互联网领域有了大量实施案例
我猜你可能会觉得分布式数据库很复杂,学起来太难。其实完全不用担心,我们这门课的使命就是要破除神秘感,找出分布式数据库的学习路径,帮你抓住它的核心内容。
那怎么找到这条学习路径呢,这就得从数据库说起了。数据库其实就做了两个操作,读和写。但就这两件事,有时也会冲突,写入快、读取可能就会慢,另外还得考虑存储空间的成本。有个RUM猜想就是说这个事情,读放大、写放大、存储空间放大,最多只能避免两个,三选二。这是第一个部分,存储的设计。
系统总是要多人使用吧,这就带来并发的问题,出现写写冲突和读写冲突时采用什么策略,这是第二部分事务模型。
数据库的操作接口是SQL,基于关系模型来定义数据结构和操作原语,而且还有各种索引、优化措施,让SQL执行得更快,这是第三个部分查询引擎。
任何架构都要避免单点故障,所以数据库会有一个复制机制,多个节点形成主备关系,主备之间同步数据,这样可靠性就有了保障,这是第四部分复制。
最后,还有一些必备的辅助工作,客户端接入、权限控制、元数据存储。这样一个基本的数据库就可以运行了。
归纳一下,数据库就是要做好五件事,存储、事务、查询、复制和其他。对分布式数据库来说,不仅要继续做这五件事,还要多出一件事,分片。在这六件事中,存储和其他这两件事与单体数据库差不多,难点就在事务、查询、复制和分片这四件。
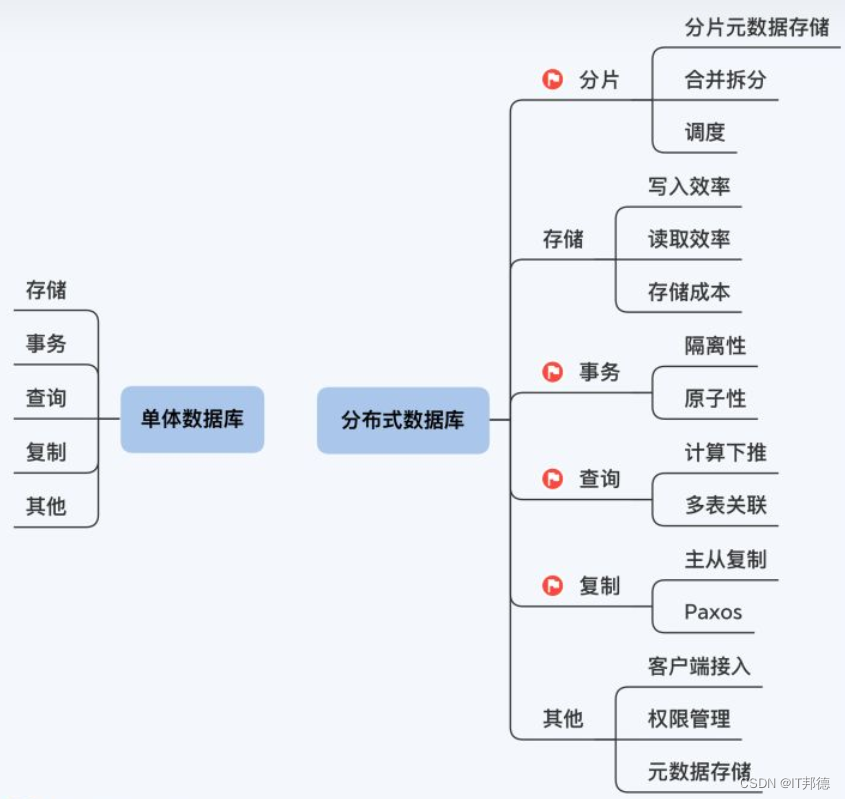
分布式数据库就是用分布式架构实现的关系型数据库,不知道你对这一点的理解是否透彻。目前各大厂商都开始使用分布式数据库处理核心业务,如果你对这部分技术感兴趣,一起来交流学习哈。


