程序部署与运行——基于Spark平台的协同过滤实时电影推荐系统项目系列博客(十)
系列文章目录
- 初识推荐系统——基于Spark平台的协同过滤实时电影推荐系统项目系列博客(一)
- 利用用户行为数据——基于Spark平台的协同过滤实时电影推荐系统项目系列博客(二)
- 项目主要效果展示——基于Spark平台的协同过滤实时电影推荐系统项目系列博客(三)
- 项目体系架构设计——基于Spark平台的协同过滤实时电影推荐系统项目系列博客(四)
- 基础环境搭建——基于Spark平台的协同过滤实时电影推荐系统项目系列博客(五)
- 创建项目并初始化业务数据——基于Spark平台的协同过滤实时电影推荐系统项目系列博客(六)
- 离线推荐服务建设——基于Spark平台的协同过滤实时电影推荐系统项目系列博客(七)
- 实时推荐服务建设——基于Spark平台的协同过滤实时电影推荐系统项目系列博客(八)
- 综合业务服务与用户可视化建设——基于Spark平台的协同过滤实时电影推荐系统项目系列博客(九)
- ……
项目资源下载
- 电影推荐系统网站项目源码Github地址(可Fork可Clone)
- 电影推荐系统网站项目源码Gitee地址(可Fork可Clone)
- 电影推荐系统网站项目源码压缩包下载(直接使用)
- 电影推荐系统网站项目源码所需全部工具合集打包下载(spark、kafka、flume、tomcat、azkaban、elasticsearch、zookeeper)
- 电影推荐系统网站项目源数据(可直接使用)
- 电影推荐系统网站项目个人原创论文
- 电影推荐系统网站项目前端代码
- 电影推荐系统网站项目前端css代码
文章目录
- 系列文章目录
- 项目资源下载
- 前言
- 一、发布项目
- 二、安装前端项目
- 三、安装业务服务器
- 四、Kafka配置与启动
- 五、Flume配置与启动
- 六、部署流式计算服务
- 七、Azkaban调度离线算法
- 总结
前言
今天给大家带来本系列的最后一篇博文,也意味着我们就要拜拜啦(不是,还有其他博文质量也不错,大家也可以关注哈哈),今天的主要内容就是我们的系统已经完全实现了,但是我们还差最后一步,就是给他部署到服务器上面,没有服务器的读者可以用自己的虚拟机部署,当然,本篇博文内容不是刚需,供有需要的读者阅读。下面就开始今天的学习吧!
一、发布项目
- 编译项目:执行root项目的clean package阶段
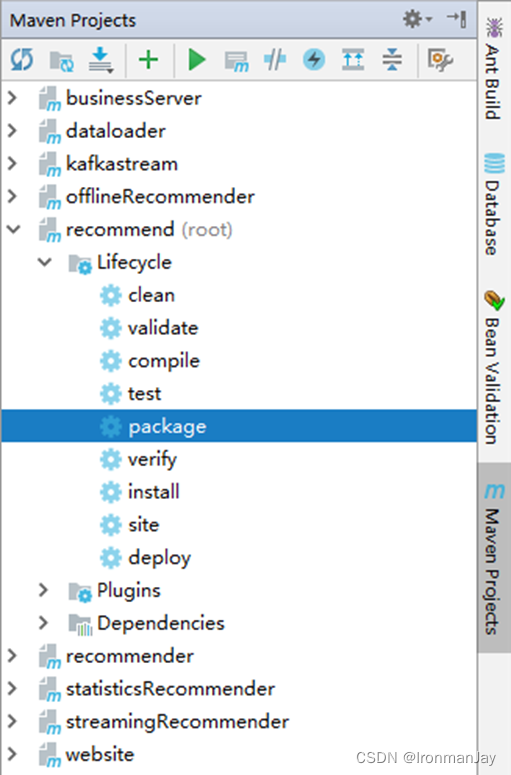
- 编译完成如下:
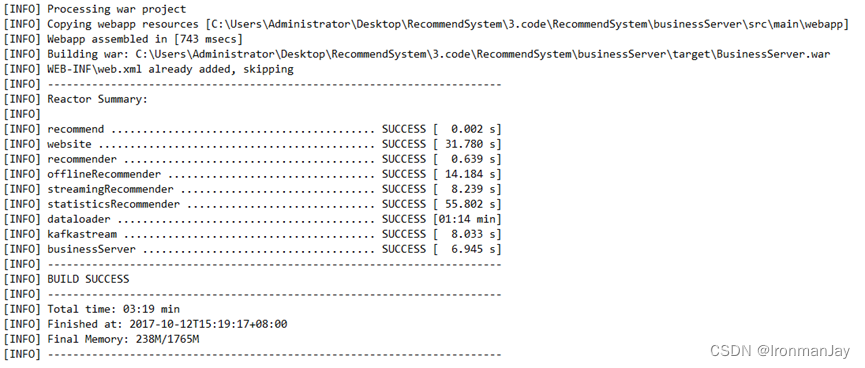
二、安装前端项目
- 将website-release.tar.gz解压到/var/www/html目录下,将里面的文件放在根目录,如下:
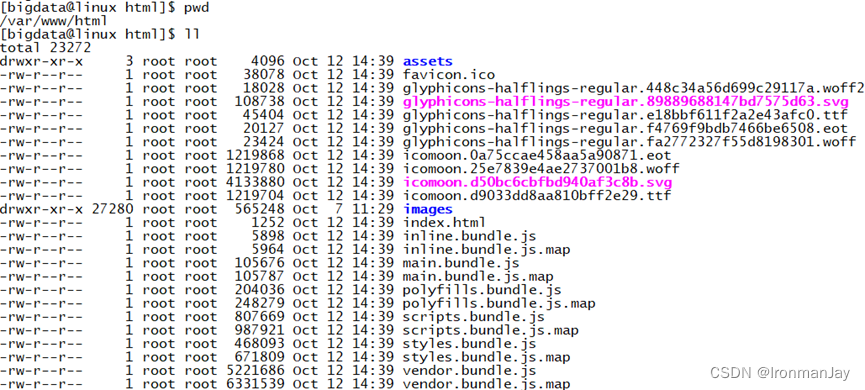
- 启动Apache服务器,访问http://你的IP地址:80
三、安装业务服务器
- 将BusinessServer.war放在tomcat的webapp目录下,并将解压出来的文件,放到ROOT目录下:

- 启动Tomcat服务器
四、Kafka配置与启动
- 启动Kafka。在Kafka中创建两个Topic,一个为log,一个为recommender。启动kafkaStream程序,用于在log和recommender两个topic之间进行数据格式化
[bigdata@linux ~]$ java -cp kafkastream.jar com.IronmanJay.kafkastream.Application linux:9092 linux:2181 log recommender五、Flume配置与启动
- 在Flume安装目录下的conf文件夹下,创建log-kafka.properties
agent.sources = exectailagent.channels = memoryChannelagent.sinks = kafkasink# For each one of the sources, the type is definedagent.sources.exectail.type = exec# 下面这个路径是需要收集日志的绝对路径,改为自己的日志目录agent.sources.exectail.command = tail -f 自己的日志目录路径agent.sources.exectail.interceptors=i1agent.sources.exectail.interceptors.i1.type=regex_filter# 定义日志过滤前缀的正则agent.sources.exectail.interceptors.i1.regex=.+MOVIE_RATING_PREFIX.+# The channel can be defined as follows.agent.sources.exectail.channels = memoryChannel# Each sink's type must be definedagent.sinks.kafkasink.type = org.apache.flume.sink.kafka.KafkaSinkagent.sinks.kafkasink.kafka.topic = logagent.sinks.kafkasink.kafka.bootstrap.servers = linux:9092agent.sinks.kafkasink.kafka.producer.acks = 1agent.sinks.kafkasink.kafka.flumeBatchSize = 20#Specify the channel the sink should useagent.sinks.kafkasink.channel = memoryChannel# Each channel's type is defined.agent.channels.memoryChannel.type = memory# Other config values specific to each type of channel(sink or source)# can be defined as well# In this case, it specifies the capacity of the memory channelagent.channels.memoryChannel.capacity = 10000- 启动Flume
[bigdata@linux apache-flume-1.7.0-kafka]$ bin/flume-ng agent -c ./conf/ -f ./conf/log-kafka.properties -n agent六、部署流式计算服务
- 提交SparkStreaming程序:
[bigdata@linux spark-2.1.1-bin-hadoop2.7]$ bin/spark-submit --class com.IronmanJay.streamingRecommender.StreamingRecommender streamingRecommender-1.0-SNAPSHOT.jar七、Azkaban调度离线算法
- 创建调度项目
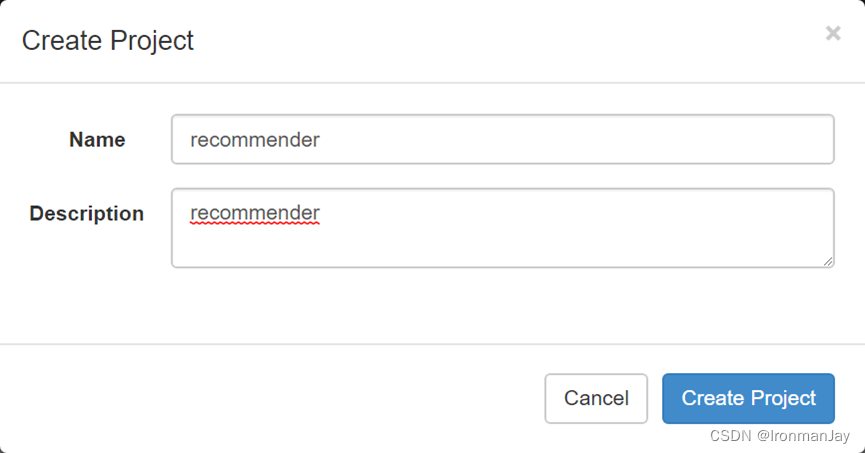
- 创建两个Job文件。Azkaban-stat.job和Azkaban-offline.job:
type=commandcommand=/home/bigdata/cluster/spark-2.1.1-bin-hadoop2.7/bin/spark-submit --class com.IronmanJay.offline.RecommenderTrainerApp offlineRecommender-1.0-SNAPSHOT.jartype=commandcommand=/home/bigdata/cluster/spark-2.1.1-bin-hadoop2.7/bin/spark-submit --class com.IronmanJay.statisticsRecommender.StatisticsApp statisticsRecommender-1.0-SNAPSHOT.jar- 将Job文件达成ZIP包上传到Azkaban:
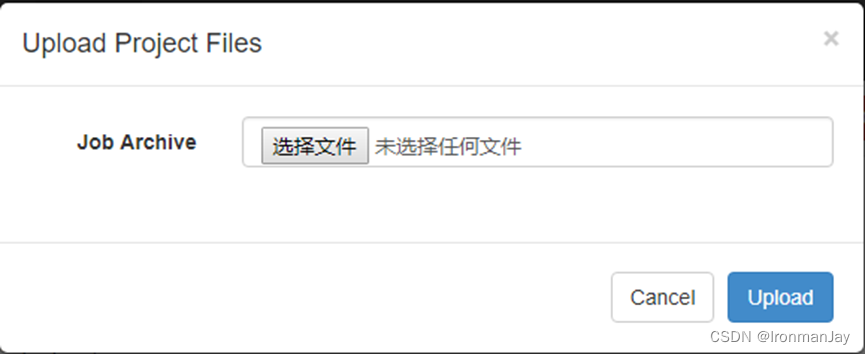
4.如下图所示:
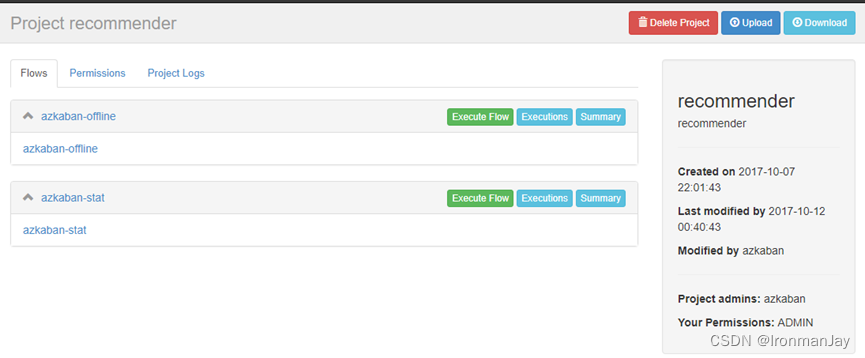
4. 分别为每一个任务指定时间即可,如下图所示:
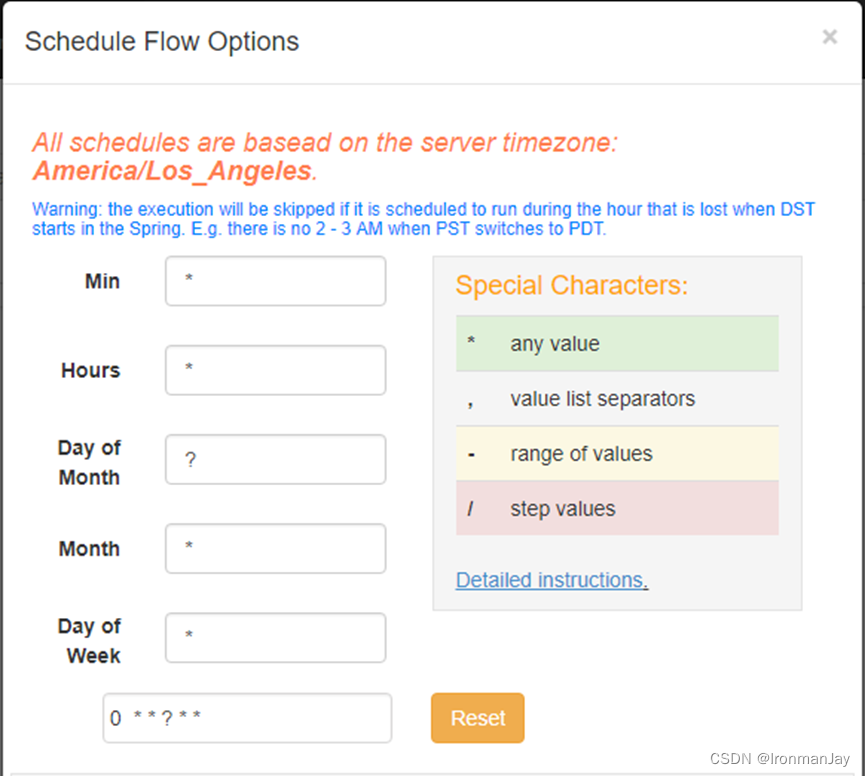
5. 定义完成之后,点击Scheduler即可
总结
这篇博文的结束也标志着整个基于Spark平台的协同过滤实时电影推荐系统项目系列博客完结啦,本篇博客对于有需要的读者可以阅读,部署到自己的服务器或虚拟机上面,按照我的步骤操作即可。就不再下篇博文见,而是下个系列见啦!

