MySQL备份作业导致的主从延时
问题:
最近处理一次生产MySQL主从延时的问题,碰到了比较奇怪的问题,同一个大事务在一主两从(本地+异地)的主从架构中,异地灾备花了30小时处理完,而本地灾备花了43小时都没处理完,最终人为介入才完成处理。
问题分析:
1 本地从库延时43小时,大事务update tmp20220427导致,而当前异地从库没有延时。
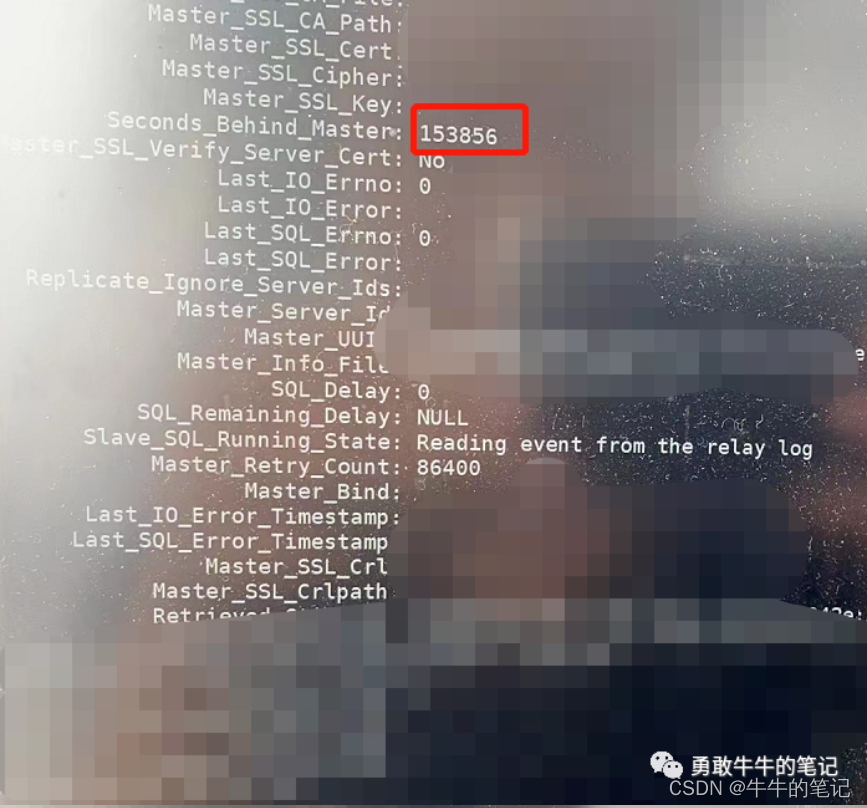

(本地从库信息)
2 解析本地以及异地从库binlog日志,两地都执行了差不多223W次的update tmp20220427操作,从2022-04-28 19:04:00开始。
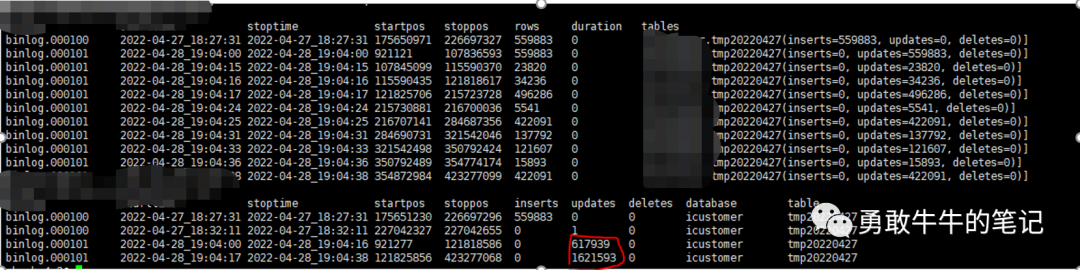
(本地从库信息)
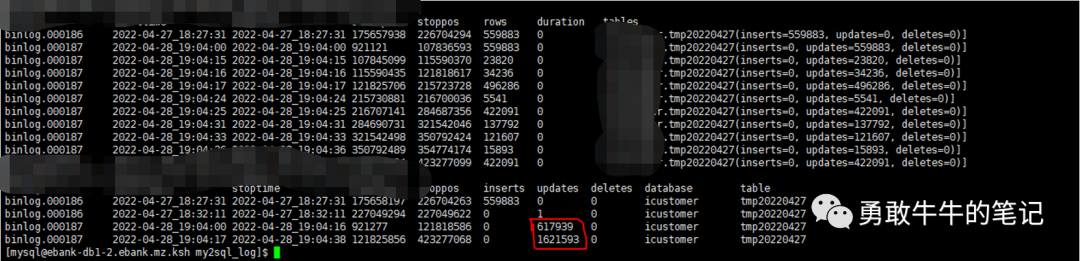
(异地从库信息)
3 由于环境没有主从延时的监控,所以只能从information_schema.tables里面的update_time字段去确认表最后一次修改的时间来大概确认当时的主从延时情况,本地为2022-04-30 14:15:28,异地的为2022-04-30 00:49:06,即我们可以确认当时本地和异地都存在主从延时的情况,本地从库的延时至少为43小时以上(后面人工介入在从库添加主键进行干预后才恢复,这里不进行展开),而异地从库的延时为大概30小时,即花了30小时完成223W的update全表操作)。
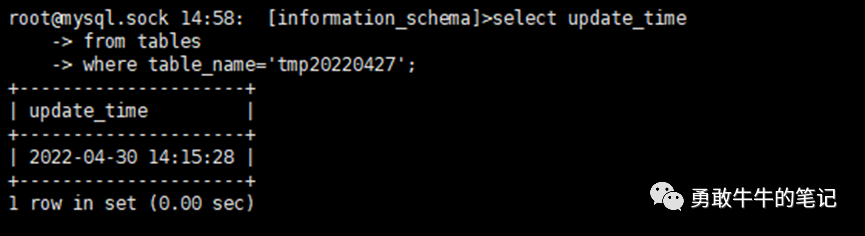
(本地从库信息)
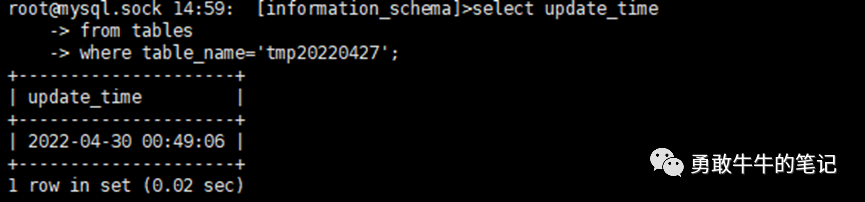
(异地从库信息)
4 到这里,其实我们可以初步确认,这是一个大事务导致的主从延时,处理的办法也很简单,在从库对表添加主键(记住设置sql_log_bin=0,不记录binlog,保持主从两边一致),加快大事务的执行速度,但还有另一个奇怪的问题,就是本地和异地从库完成大事务所消耗的时间不一样的问题,异地从库执行大事务大概花了30个小时,而本地从库执行大事务43小时还没完成。
5 接下来继续分析本地和异地从库执行大事务的差异,首先我们想到的就是参数配置文件以及服务器性能的差异,本地从库的资源配置8c 32g,innodb buffer配置8g,异地从库的资源配置8c 16G,innodb buffer配置4g,其他MySQL参数一致,可以看到本地和异地从库的配置相差不大,异地从库的资源甚至还差于本地从库,而IO的性能,由于两台机器都是虚拟机,并且单个大事务的恢复都是单线程,所以,这里IO应该不是差异所在。
6 接下来,我们查看本地从库的后台错误日志error.log,发现在4月29,30号凌晨3点20分 slave的sql_thread进程都发生过重启,而重启之后binlog的执行位点又回到事务的初始位置925788,这导致从库正在执行的大事务不断发生重跑。
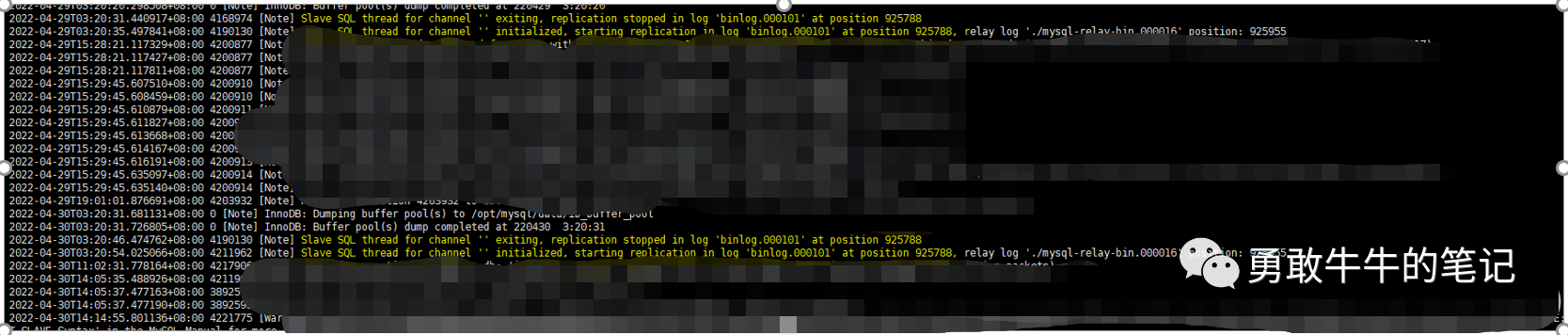
(本地从库信息)
7 现在我们可以确认,本地从库大事务执行了43个小时还没完成的有原因为slave的sql_thread进程不断发生重启,这导致从库正在执行的大事务不断发生重跑。
8 接下来,我们继续分析是什么触发了slave的sql_thread进程不断重启,从触发的时间来看,频率是非常固定的,每天凌晨3点20分左右,可以确认这是一个定时发起的任务,查看mysql用户下面的crontab定时任务,我们发现了一个每天凌晨3点10分开始的mysqlbackup备份job,通过备份的日志,我们可以发现3点20分左右mysqlbackup加了全局读锁,开始备份非innodb全表以及最后一个binlog,relaylog。
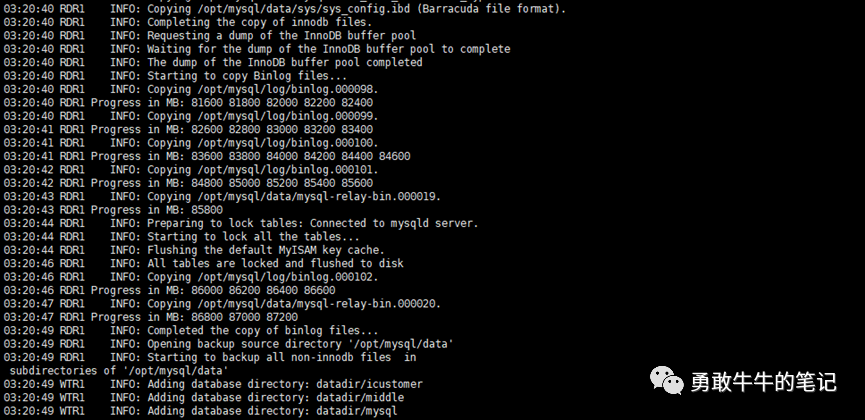
(本地从库信息)
9 而在加全局读锁之前,mysqlbackup会stop sql_thread,从而确保从库不再读写。
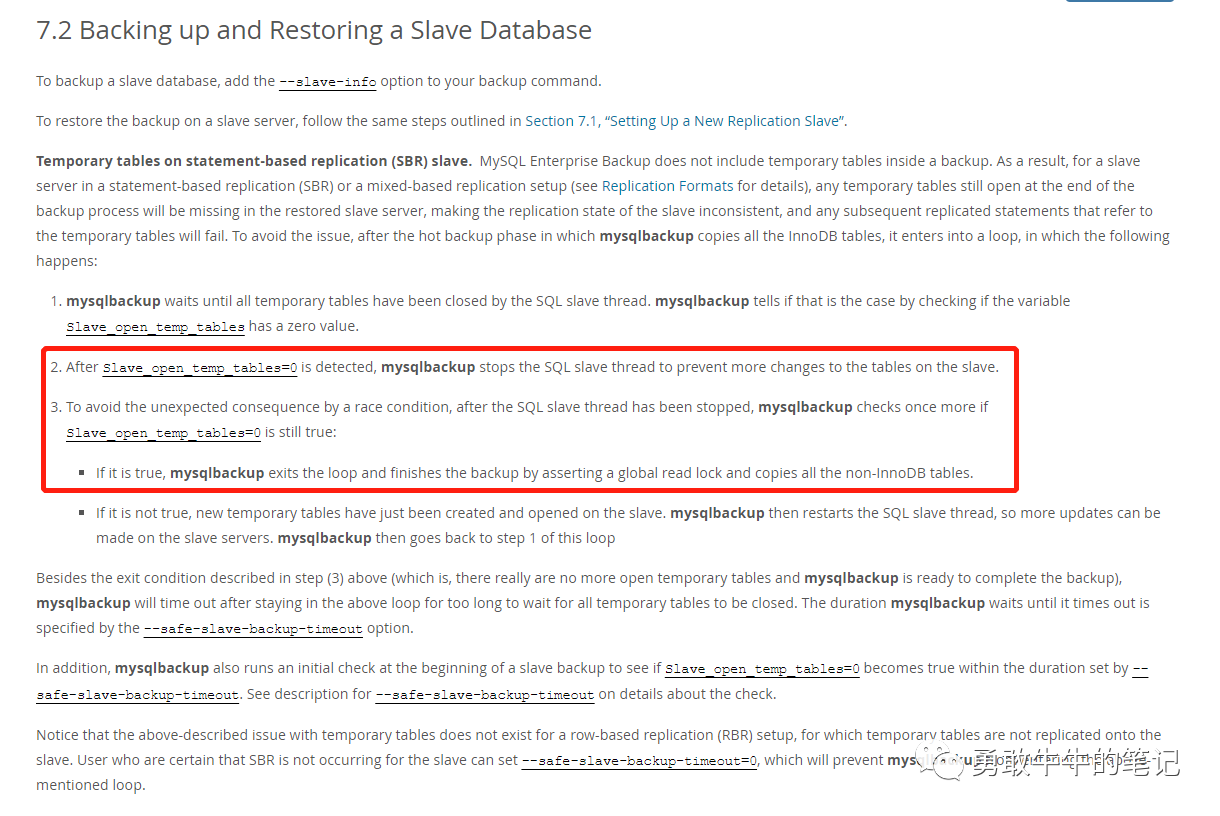
(MySQL官方信息)
问题总结:
1 主从延时的原因为执行大事务并且表没有主键导致
2 本地从库的大事务执行了43小时还没执行完的原因为:本地从库每日凌晨3点10分的mysqlbackup备份,触发slave的sql_thread进程发生重启,这导致从库正在执行的大事务不断发生重跑。
建议:
1 对于进行大事务操作的表,一定要对表创建主键
2 大事务尽量拆成多个小事务执行
3 数据库主从环境要配置监控,以及时告警主从延时等其他问题。

