[KO机器学习] Day8 模型评估:ROC曲线


场景描述
二值分类器(Binary Classifier)是机器学习领域中最常见也是应用最广泛的分类器。评价二值分类器的指标有很多。比如精确率、召回率、F1 score、P-R曲线等。上一篇已经对这些指标做了一定的介绍,但也发现这些指标或多或少只能反映模型在某一方面的性能。相比而言,ROC曲线则有很多优点、经常作为评估二值分类器最重要的指标之一。下面我们一起来详细了解一下ROC曲线的绘制方法和特点
知识点:ROC曲线、曲线下的面积(Area Under Curve,AUC)、P - R曲线
问题1:什么是ROC曲线?
难度:★☆☆☆☆
ROC曲线是receiver operating characteristic curve 的简称,中文名称为 受试者工作特征曲线。ROC曲线源于军事领域,而后在医学领域应用最广。受试者工作特征曲线这一名称也正是来自于医学领域。
ROC曲线的横坐标为假阳性率(False Positive Rate,FPR);纵坐标为真阳性率(True Positive Rate,TPR)。计算方法分别为
P代表 真实的正样本的数量,N是真实的负样本的数量,TP是P个正样本中被分类器预测为正样本的个数,FP是N个负样本中被分类器预测为正样本的个数。
问题2: 如何绘制ROC曲线 ?
难度:★★☆☆☆
事实上,ROC 曲线是通过不断移动分类器的“截断点” 来生成曲线上的一组关键点的,通过下面的例子进一步来解释“截断点”的概念。
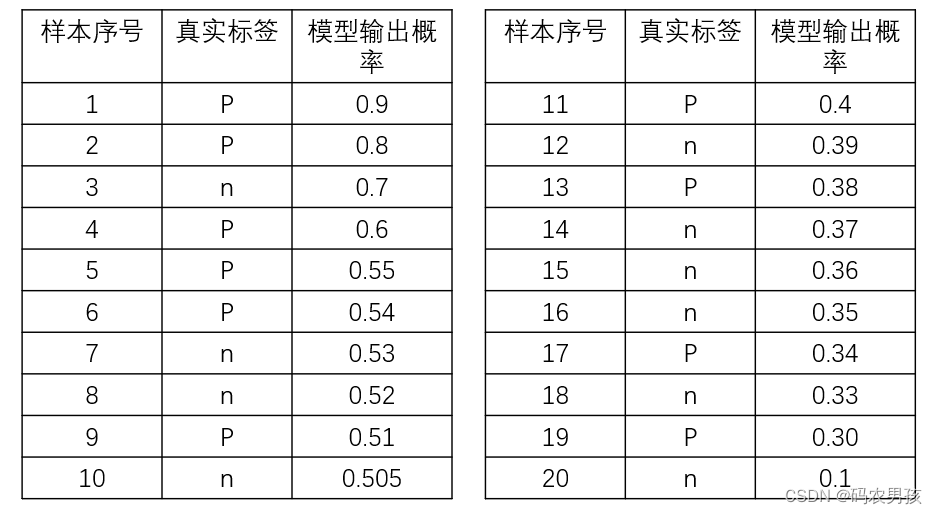
在二值分类问题中,模型的输出一般都是预测样本为正例的概率。假设测试集中有 20 个样本,下表所示是模型的输出结果。样本按照预测概率从高到低排序。在输出最终的正例、负例之前,我们需要指定一个阈值,预测概率大于该间值的样本会被判为正例,小于该國值的样本则会被判为负例。比如,指定阈值为 0.9,那么只有第一个样本会被预测为正例,其他全部都是负例。上面所说的“截断点” 指的就是区分正负预测结果的阈值。
通过动态地调整截断点,从最高的得分开始(实际上是从正无穷开始,对应着 ROC 曲线的零点),逐渐调整到最低得分,每一个截断点都会对应一个FPR和TPR,在ROC 图上绘制出每个截断点对应的位置,再连接所有点就得到最终的ROC 曲线。
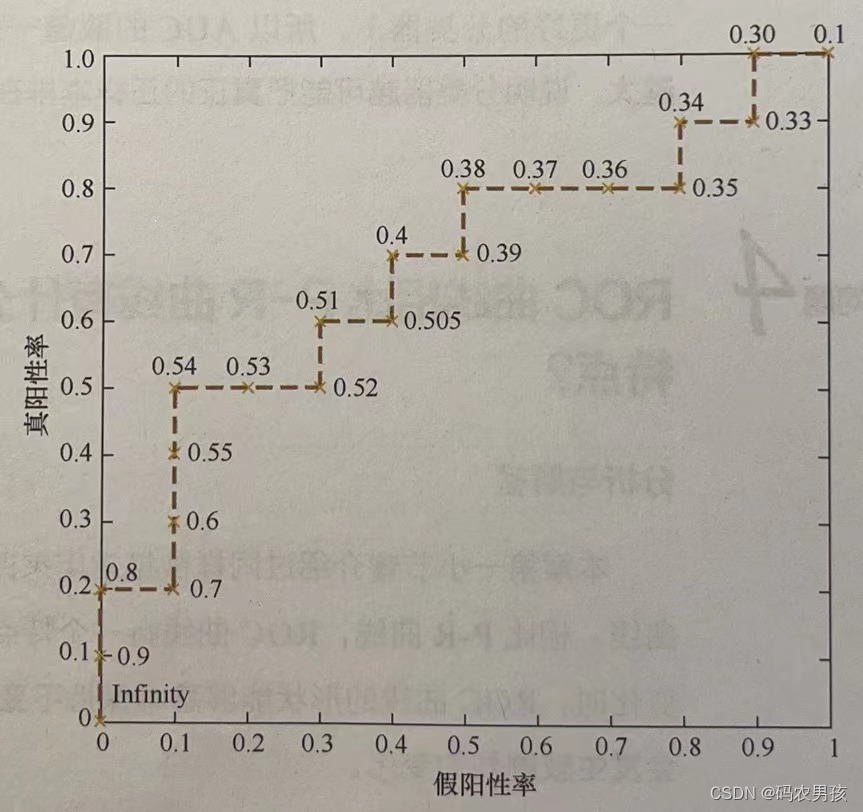
就本例来说,当截断点选择为正无穷时,模型把全部样本预测为负例,那么FP和TP必然都为 0,FPR和TPR也都为 0,因此曲线的第1个点的坐标就是(0.0)。当把截断点调整为 0.9时,模型预测 1号样本为正样本,并且该样本确实是正样本,因此,TP=1,20个样本中,所有正例数量为 P-10,故TPR=TP/P=1/10;这里没有预测错的正样本,即FP-0,负样本总数N=10,故FPR=FP/N=0/10=0,对应 ROC曲线上的点(0,0.1)。依次调整截断点,直到画出全部的关键点,再连接关键点即得到最终的ROC 曲线,如下图所示。
其实,还有一种更直观地绘制ROC 曲线的方法。首先,根据样本标签统计出正负样本的数量,假设正样本数量为 P,负样本数量为 N:接下来,把横轴的刻度间隔设置为 1/N,纵轴的刻度间隔设置为 1/P;再根据模型输出的预测概率对样本进行排序(从高到低);依次遍历样本,同时从零点开始绘制ROC 曲线,每遇到一个正样本就沿纵轴方向绘制一个刻度间隔的曲线,每遇到一个负样本就沿横轴方向绘制一个刻度间隔的曲线,直到遍历完所有样本,曲线最终停在(1,1)这个点,整个ROC 曲线绘制完成。
问题3: 如何计算AUC?
难度:★★☆☆☆
顾名思义,AUC指的是 ROC 曲线下的面积大小,该值能够量化地反映基于 ROC 曲线衡量出的模型性能。计算 AUC 值只需要沿着ROC 横轴做积分 就可以了。由于ROC 曲线一般都处于 了=x这条直线的上方(如果不是的话,只要把模型预测的概率反转成 1一p就可以得到一个更好的分类器),所以 AUC的取值一般在 0.5 ~ 1之间。AUC越大,说明分类器越可能把真正的正样本排在前面,分类性能越好。



