【简简单单来个爬虫小案例吧】获取emoji表情包
🔝🔝🔝🔝🔝🔝🔝🔝🔝🔝🔝🔝
🥰 博客首页:knighthood2001
😗 欢迎点赞👍评论🗨️
❤️ 热爱python,期待与大家一同进步成长!!❤️


在平时写博客的时候,为了让博客内容更加丰富,会使用到各种各样的表情包。 如上,笔者也用了许多emoji表情包,有些表情包还挺不错的。
笔者想看一下emoji表情包放在一起的画面,因此写了一个爬虫爬取emoji表情包与标题名。最后发现其实挺震撼的。
因此我将获得的emoji表情已经放到【emoji大全宝典】中。
目录
一、实现过程
1.1网址获取
1.2文件创建
1.3emoji爬取讲解
1.3.1大致思路
1.3.2模块准备
1.3.3开干
1.3.4文件保存(md、txt)
拓展知识1
拓展知识2
1.3.5全部代码展示
1.4emoji口袋爬取
1.4.1emoji文案爬取
1.4.2全部代码展示
二、总结
一、实现过程
1.1网址获取
emoji网址:🤣 Emoji表情大全,颜文字百科 💌 - EmojiXD
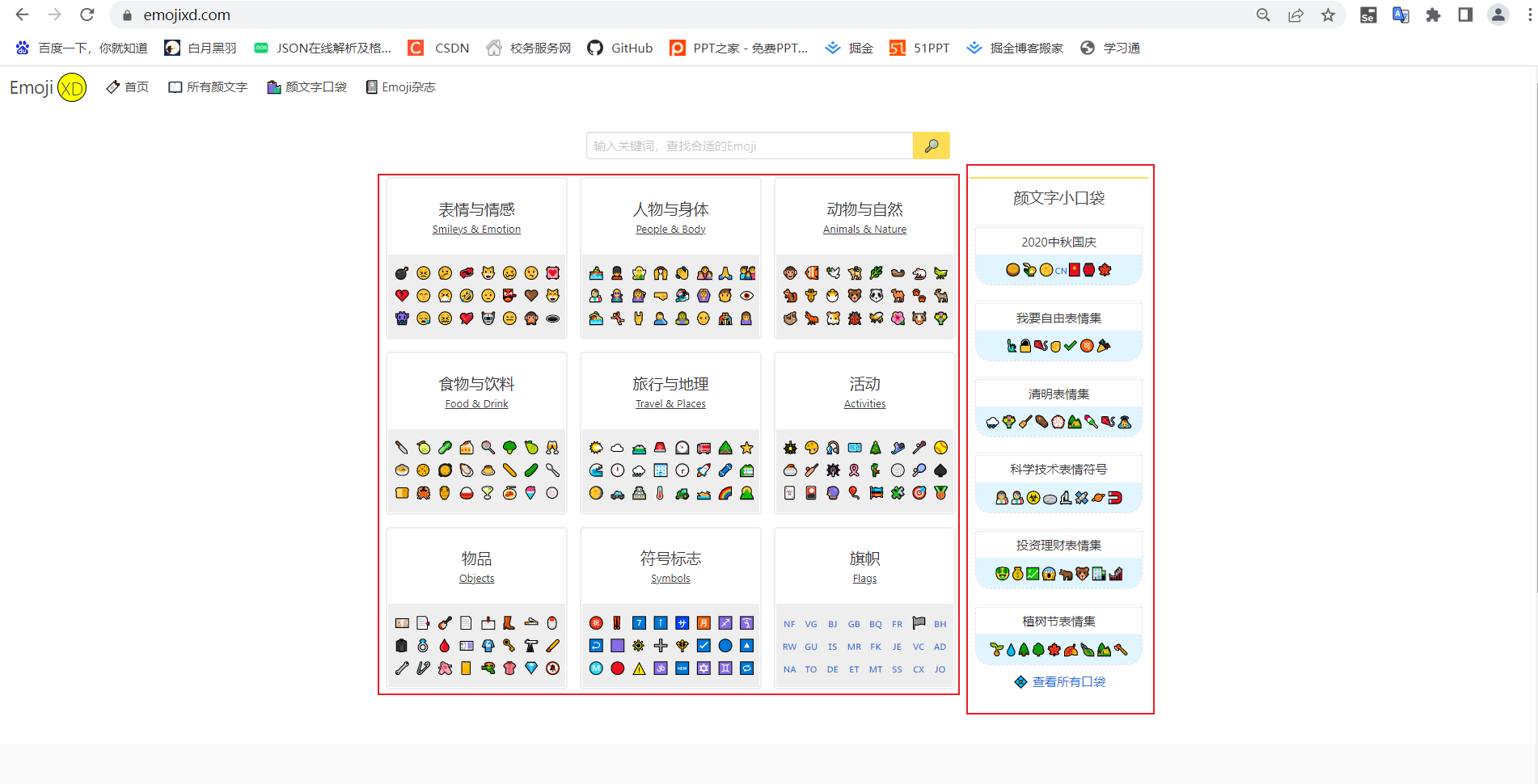
如图,该网址其中的表情包分类大致可以分为两类,点击右边查看所有口袋(如下图).

这是emoji口袋的网址: 颜文字口袋 - Emoji收藏合集 - EmojiXD
以上两个网址就是我们需要进入的主网址。我们也是根据这两个网址进行获取具体emoji表情。
1.2文件创建

如上,emoji爬取创建两个目录emoji和emoji_pockets,其中有request_emoji.py和request_emoji_pockets.py两个python文件。
1.3emoji爬取讲解
https://emojixd.com/
以上就是我们要进行爬取的网址,
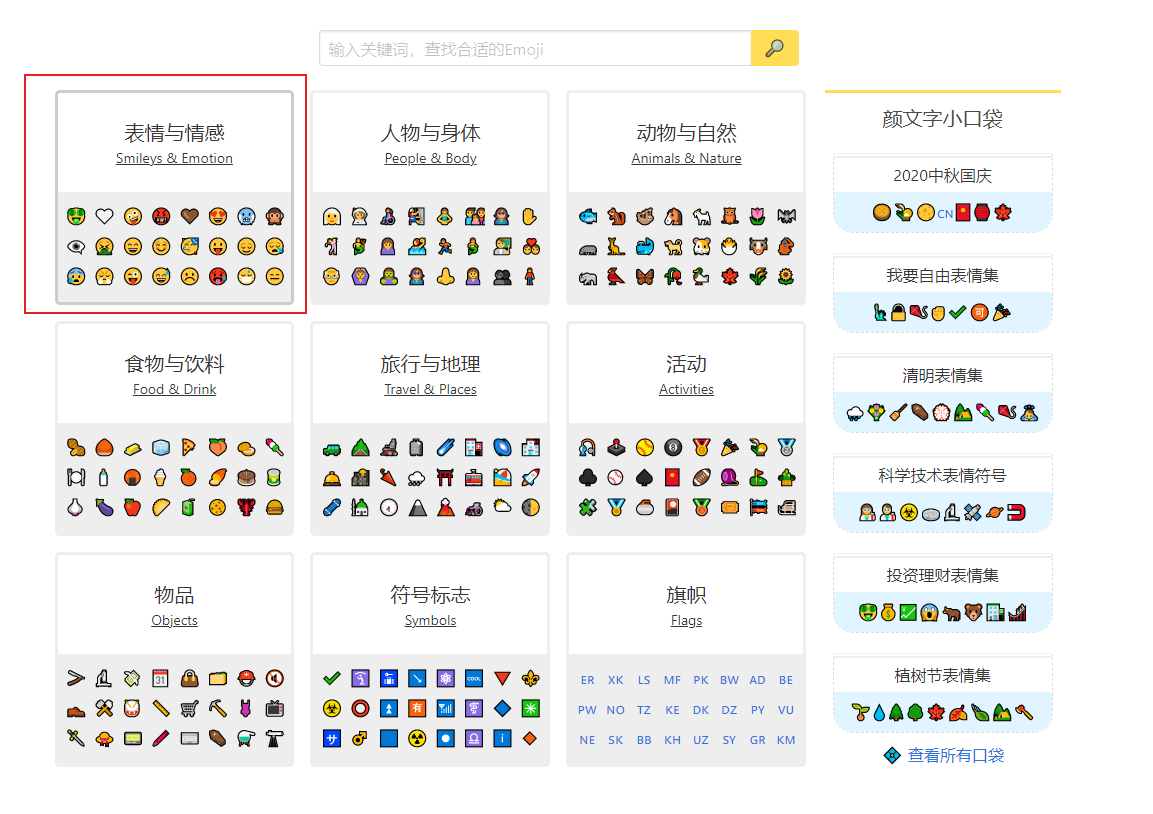
随意点击一块区域,进入新的网址
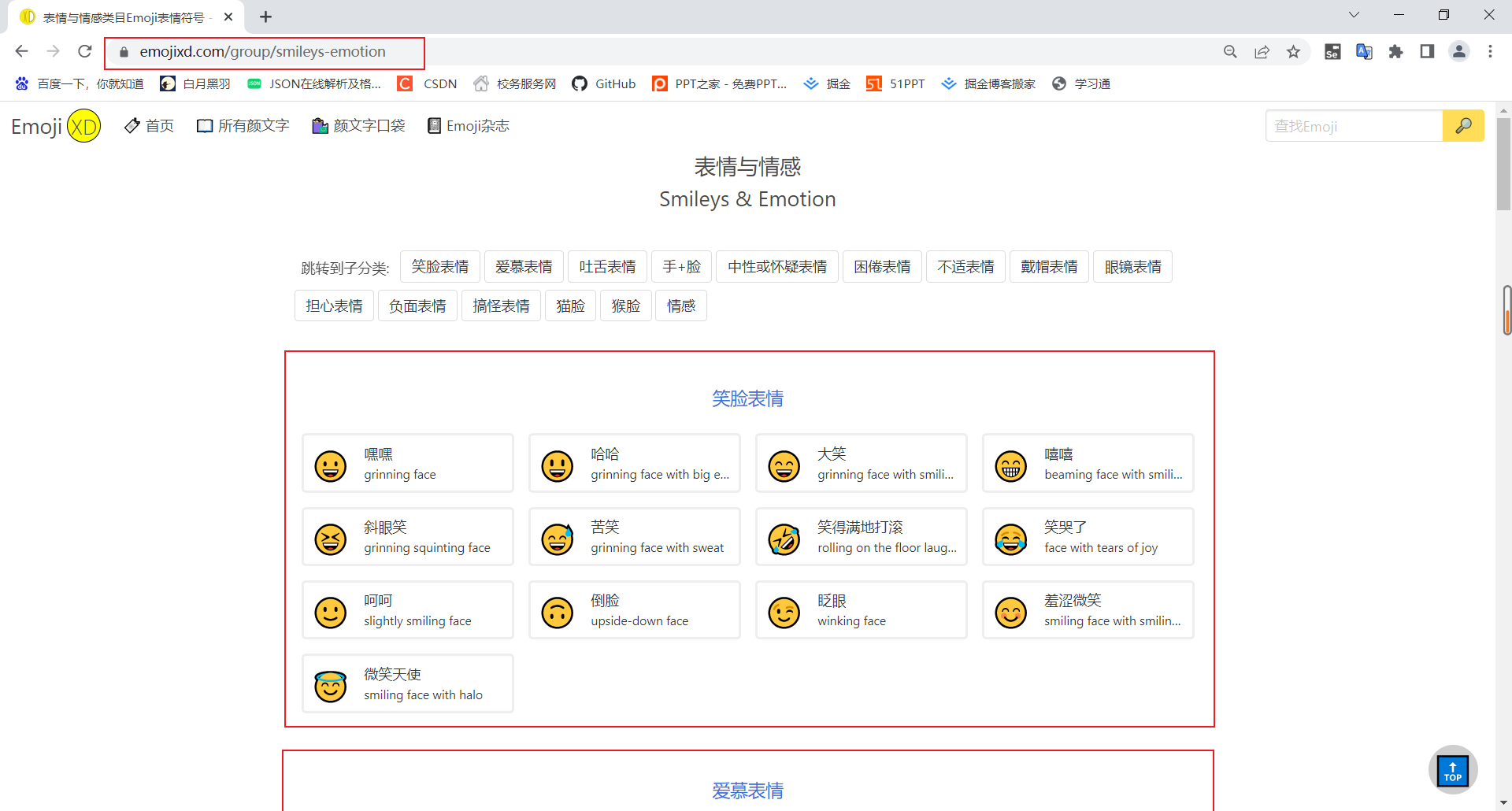

我们可以看到一类一类的emoji表情。
因此我们可以得出爬取emoji表情的大致思路。
1.3.1大致思路
我们首先获取到主网址中每一块区域所对应的网址,如上图中的表情与情感、人物与身体、动物与自然等,然后进入具体的区域,如进入表情与情感网页,爬取相关的表情!!
1.3.2模块准备
import requestsimport re项目比较简单,只需要用到requests模块和re模块即可
1.3.3开干
url = 'https://emojixd.com'response = requests.get(url)print(response.text)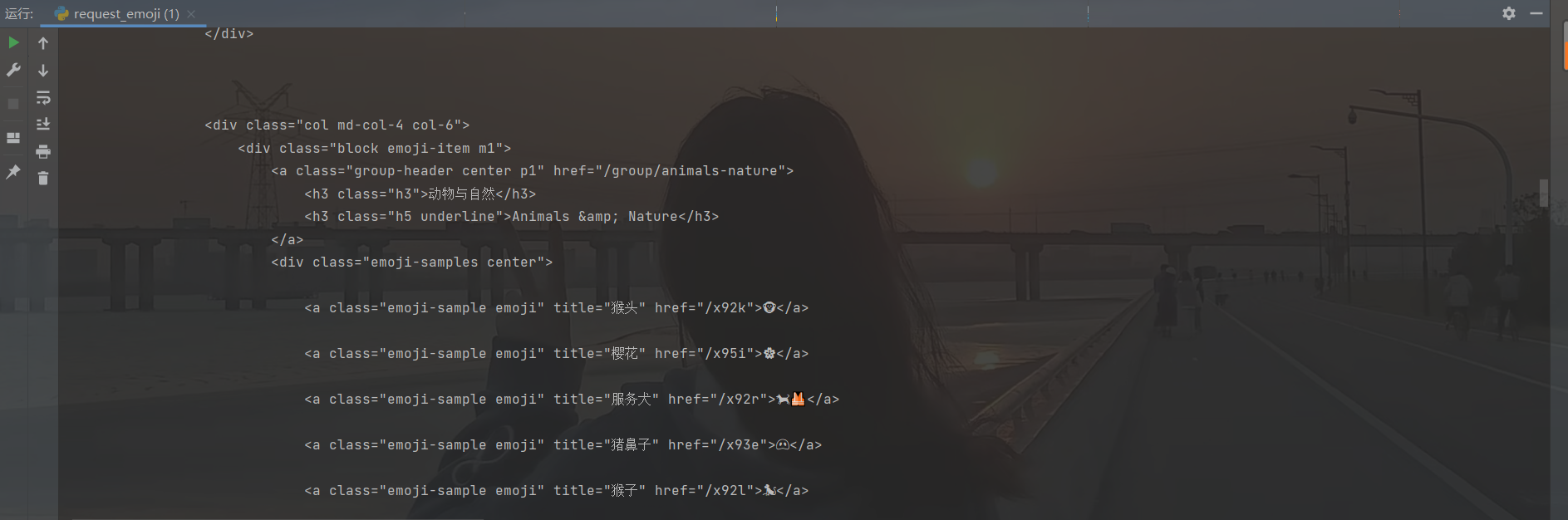
打印出来的就是网页源代码,要是觉得看这个不太方便买也可以在emoji网站右键,查看网页源代码
 注意:点的是查看网页源代码而不是检查,检查中的内容是经过css等渲染后的内容,与源代码还是有点区别的。
注意:点的是查看网页源代码而不是检查,检查中的内容是经过css等渲染后的内容,与源代码还是有点区别的。
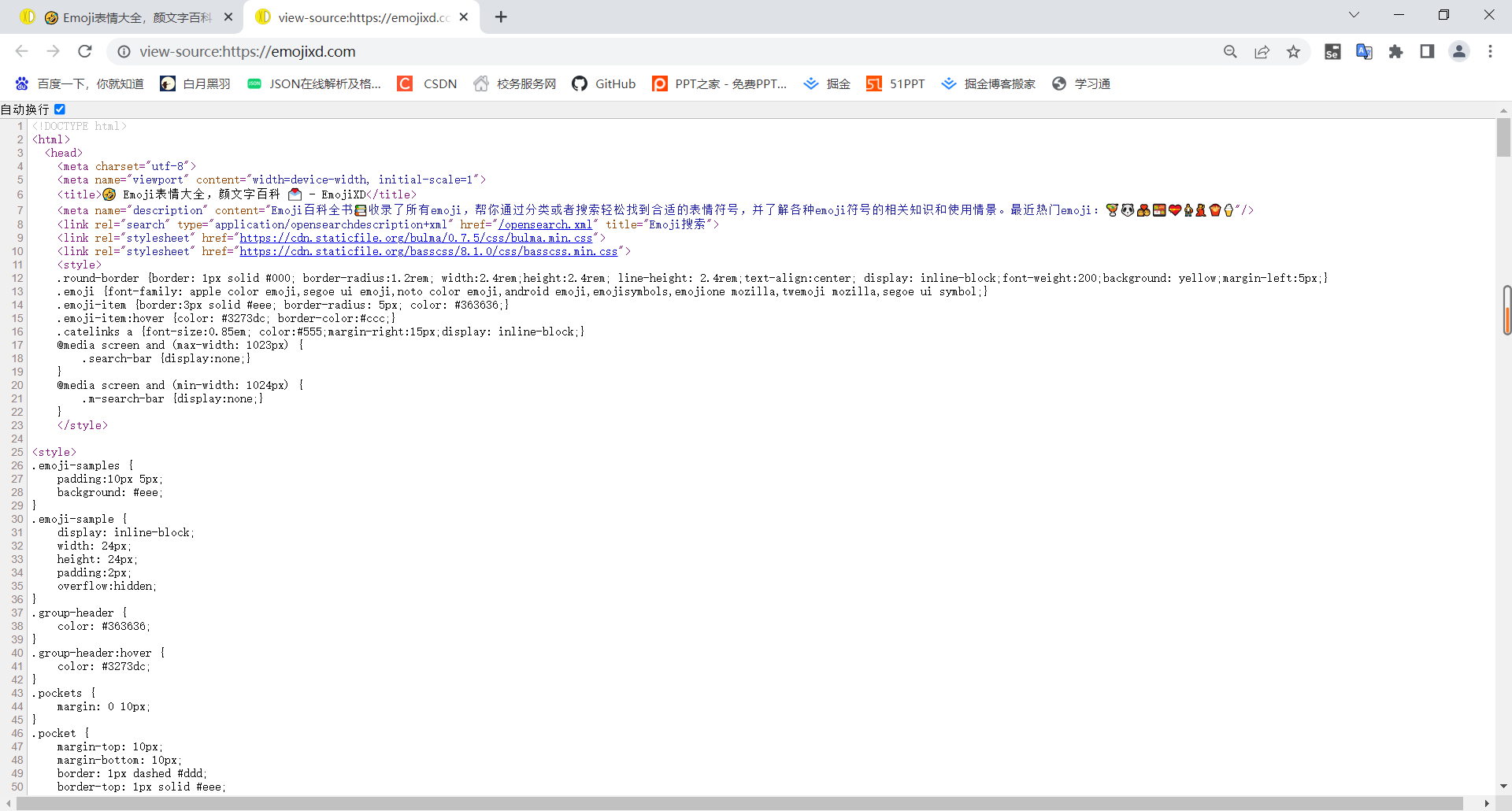
这里我选择查看网页源代码,我们可以发现每一块区域,都有相对应的网址(如下图)。
在爬虫中,我们可以采用正则表达式精准的找出匹配的内容,如果需要重温python正则表达式的,可以看一下我之前写的。
重识python正则表达式(re模块)![]() https://blog.csdn.net/knighthood2001/article/details/124539352?spm=1001.2014.3001.5502代码如下:
https://blog.csdn.net/knighthood2001/article/details/124539352?spm=1001.2014.3001.5502代码如下:
a = re.findall('', response.text)print(a)'''['/group/smileys-emotion', '/group/people-body', '/group/animals-nature', '/group/food-drink','/group/travel-places', '/group/activities', '/group/objects', '/group/symbols', '/group/flags']'''re.findall()返回的是列表的数据类型
由于旗帜区域中包含的几乎全是如下内容,因此我就不爬取这里的信息了
 旗帜板块在所要爬取区域的最后,而列表的最后元素从右往左数的位置为-1。
旗帜板块在所要爬取区域的最后,而列表的最后元素从右往左数的位置为-1。
代码如下:
for b in a[:-1]: # print(b) base_url = url + b # print(base_url) new_response = requests.get(base_url) # print(new_response.text) emoji = re.findall('(.*?) ', new_response.text) title = re.findall('(.*?)
', new_response.text) # print(emoji) # print(title)讲解:①a[:-1]表示包含开头到倒数第二个内容的列表。;
注意:这里的-1不取到
②接下来进行拼接url,将其拼接成包含具体emoji表情的网址;
③接下来对具体url进行查看网页源代码操作,然后进行找规律,
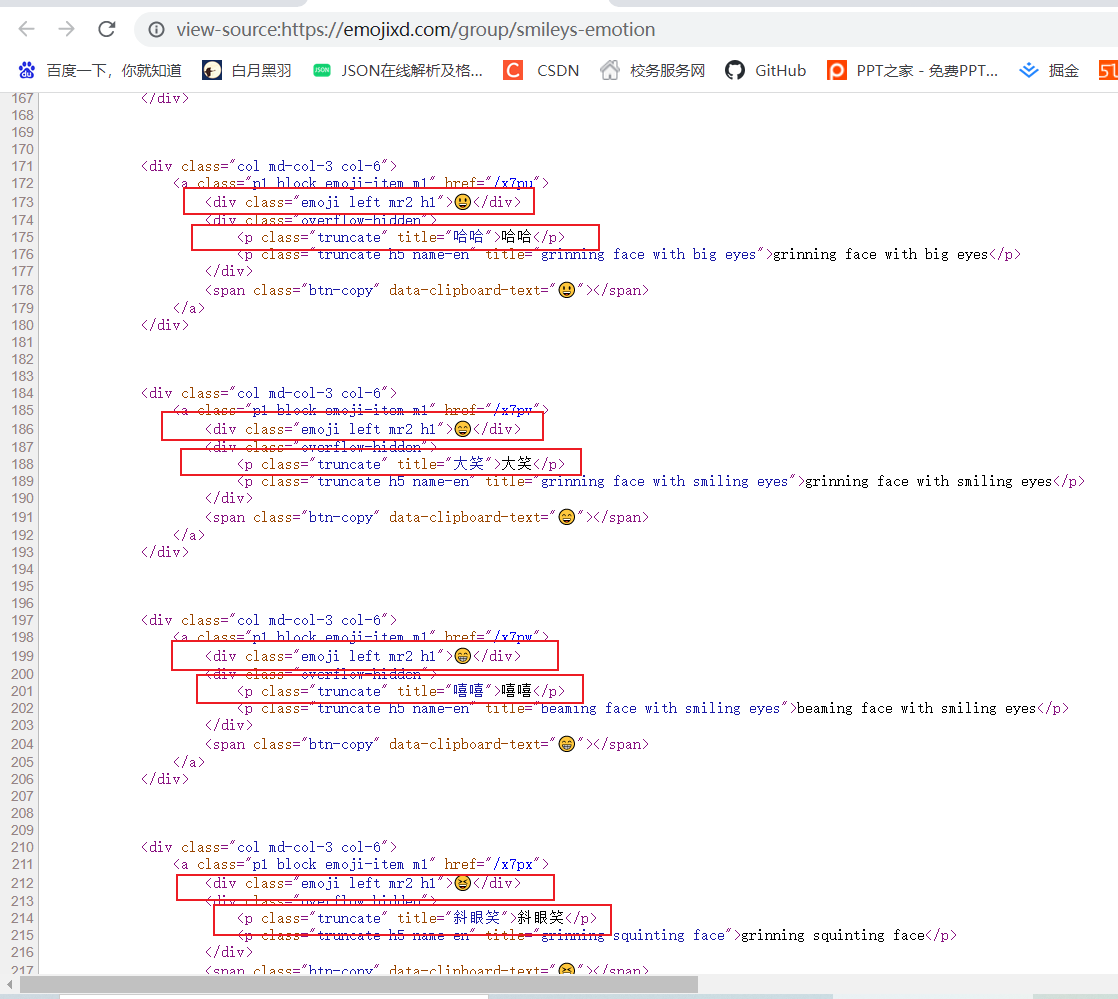
发现我们需要的表情和表情所对应的标题如下
😃哈哈
因此我们编写正则表达式进行提取。
打印出来如下图:
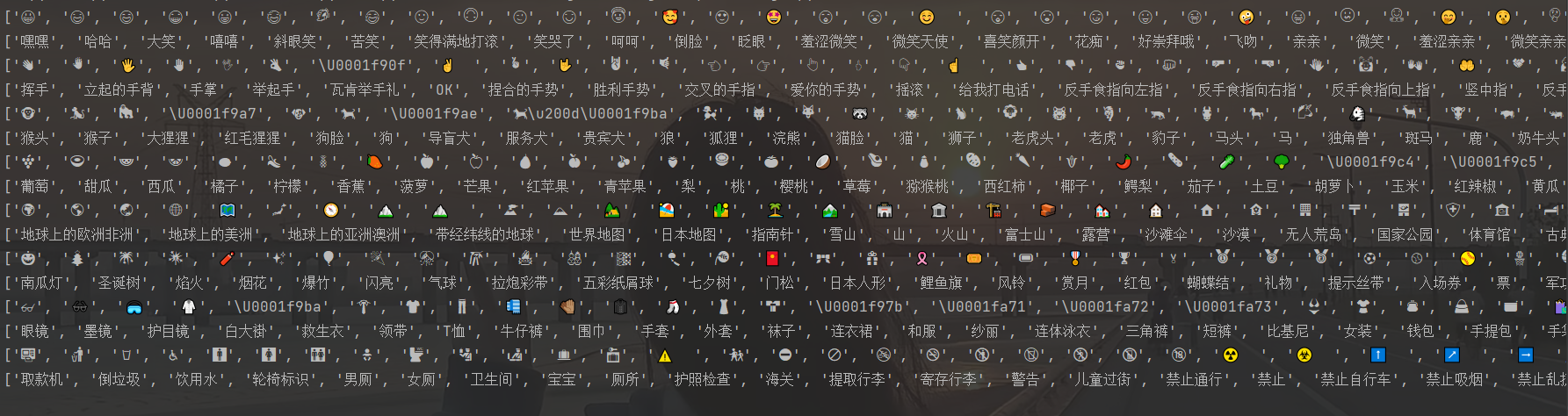
可以发现,有些emoji表情有色彩,有些则是镂空形态,有些则显示像'\U0001f9c4'这样的内容。
不过不用慌, 我们只要将它们保存到文件即可
1.3.4文件保存(md、txt)
①保存为txt文件
如下图所示,这里笔者分两个txt文件进行存储,一个文件中全是emoji表情,另一个文件中存储的是emoji表情及其对应的title。

 代码如下:
代码如下:
for i in emoji: with open('emoji.txt', 'a', encoding='utf-8') as f: f.write(i) for i, j in zip(emoji, title): # print(i+j) with open('title_emoji.txt', 'a', encoding='utf-8') as f: f.write(i + j)拓展知识1:
 由于爬取的emoji和title是用re.findall()函数获得的,因此其是一个列表,我们要是将它一一对应的排序,我们可以使用zip()函数,将其中的元素一一对应。
由于爬取的emoji和title是用re.findall()函数获得的,因此其是一个列表,我们要是将它一一对应的排序,我们可以使用zip()函数,将其中的元素一一对应。
拓展知识2:
今后大家在使用zip()的时候可能会遇到,
c = zip(emoji, title) print(c)返回结果如下

这不是我们想要的结果,查阅资料才知道,
原因是为了节约内存,python3基于此对此进行了优化,输出只输出对象的内存位置而不打印出来。而在python2中可以直接输出到屏幕
解决方法就是加个list()
c = zip(emoji, title) print(c) print(list(c))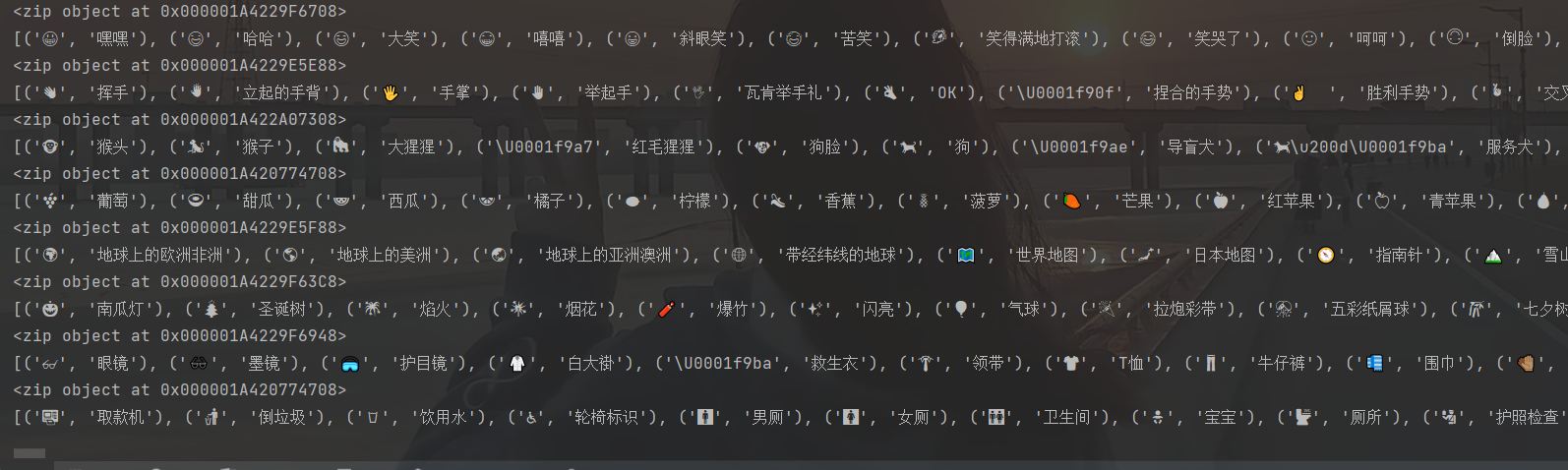 这样就得到了我们需要的内容。
这样就得到了我们需要的内容。
不过保存为txt文件,在阅读的时候是没有颜色的,虽然复制后,在聊天软件粘贴时显示了彩色。不过这不太方便。因此笔者尝试着将其保存为md文件。
②保存为md文件
代码和上面一样,只需将文件后缀改成.md即可
for i in emoji: with open('emoji.md', 'a', encoding='utf-8') as f: f.write(i) for i, j in zip(emoji, title): # print(i+j) with open('title_emoji.md', 'a', encoding='utf-8') as f: f.write(i + j) 编辑器在左,预览区在右。当然你也可以设置为仅预览区(如下图)。
编辑器在左,预览区在右。当然你也可以设置为仅预览区(如下图)。
至此,我才发现md文件这么强大。
1.3.5全部代码展示
# -*- coding: utf-8-*-import requestsimport reurl = 'https://emojixd.com'response = requests.get(url)# print(response.text)a = re.findall('', response.text)# print(a)'''['/group/smileys-emotion', '/group/people-body', '/group/animals-nature', '/group/food-drink','/group/travel-places', '/group/activities', '/group/objects', '/group/symbols', '/group/flags']'''for b in a[:-1]: # print(b) base_url = url + b # print(base_url) new_response = requests.get(base_url) # print(new_response.text) emoji = re.findall('(.*?) ', new_response.text) title = re.findall('(.*?)
', new_response.text) # print(emoji) # print(title) for i in emoji: with open('emoji.txt', 'a', encoding='utf-8') as f: f.write(i) for i, j in zip(emoji, title): # print(i+j) with open('title_emoji.txt', 'a', encoding='utf-8') as f: f.write(i + j) for i in emoji: with open('emoji.md', 'a', encoding='utf-8') as f: f.write(i) for i, j in zip(emoji, title): # print(i+j) with open('title_emoji.md', 'a', encoding='utf-8') as f: f.write(i + j)1.4emoji口袋爬取
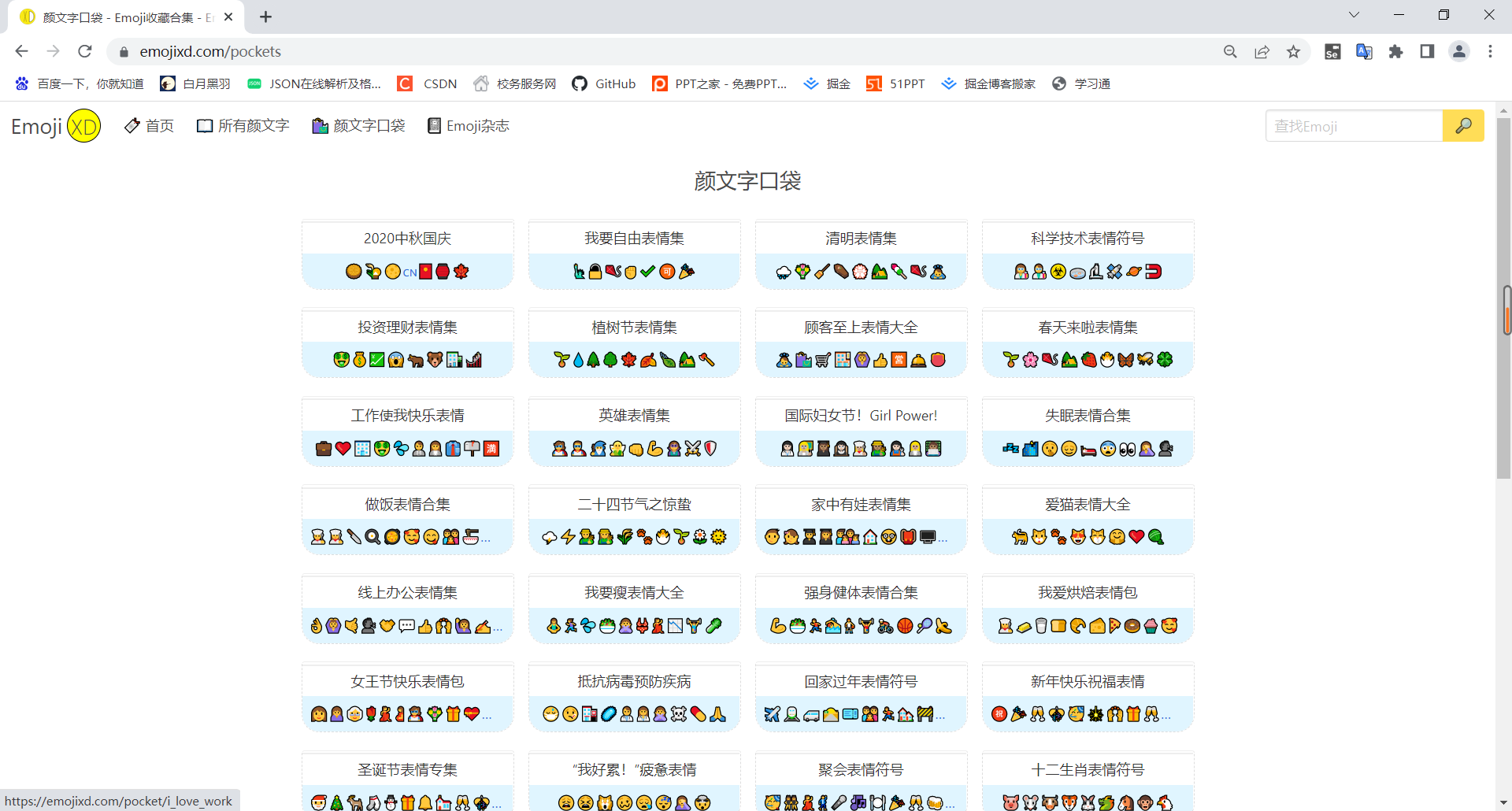
内容与1.3emoji爬取中的内容类似,代码如下
# -*- coding: utf-8-*-import requestsimport reurl = "https://emojixd.com/pockets"response = requests.get(url)# print(response.text)a = re.findall('', response.text)# print(a)'''['/pocket/mid-autumn-2020', '/pocket/freedom', '/pocket/qingming', '/pocket/science', '/pocket/invest', '/pocket/Arbor_Day', '/pocket/customer_first', '/pocket/spring', '/pocket/i_love_work', '/pocket/hero', '/pocket/womensday', '/pocket/insomnia', '/pocket/cooking', '/pocket/jingzhe', '/pocket/child_at_home', '/pocket/lovely_cat', '/pocket/online_work', '/pocket/keep_slim', '/pocket/keep_fit', '/pocket/baking', '/pocket/womens_day', '/pocket/control-disease', '/pocket/on_the_way', '/pocket/new-year', '/pocket/christmas', '/pocket/tired', '/pocket/party', '/pocket/chinese-zodiac', '/pocket/thanksgiving', '/pocket/halloween', '/pocket/love', '/pocket/congratulations', '/pocket/journey', '/pocket/holidays', '/pocket/hearts', '/pocket/zodiac']'''for b in a: base_url = 'https://emojixd.com' + b print(base_url) new_response = requests.get(base_url) emoji = re.findall('(.*?) ', new_response.text) title = re.findall('(.*?)
', new_response.text) print(emoji) print(title) for i in emoji: with open('emoji_pockets.md', 'a', encoding='utf-8') as f: f.write(i) for i, j in zip(emoji, title): print(i+j) with open('title_emoji_pockets.md', 'a', encoding='utf-8') as f: f.write(i + j)
1.4.1emoji文案爬取
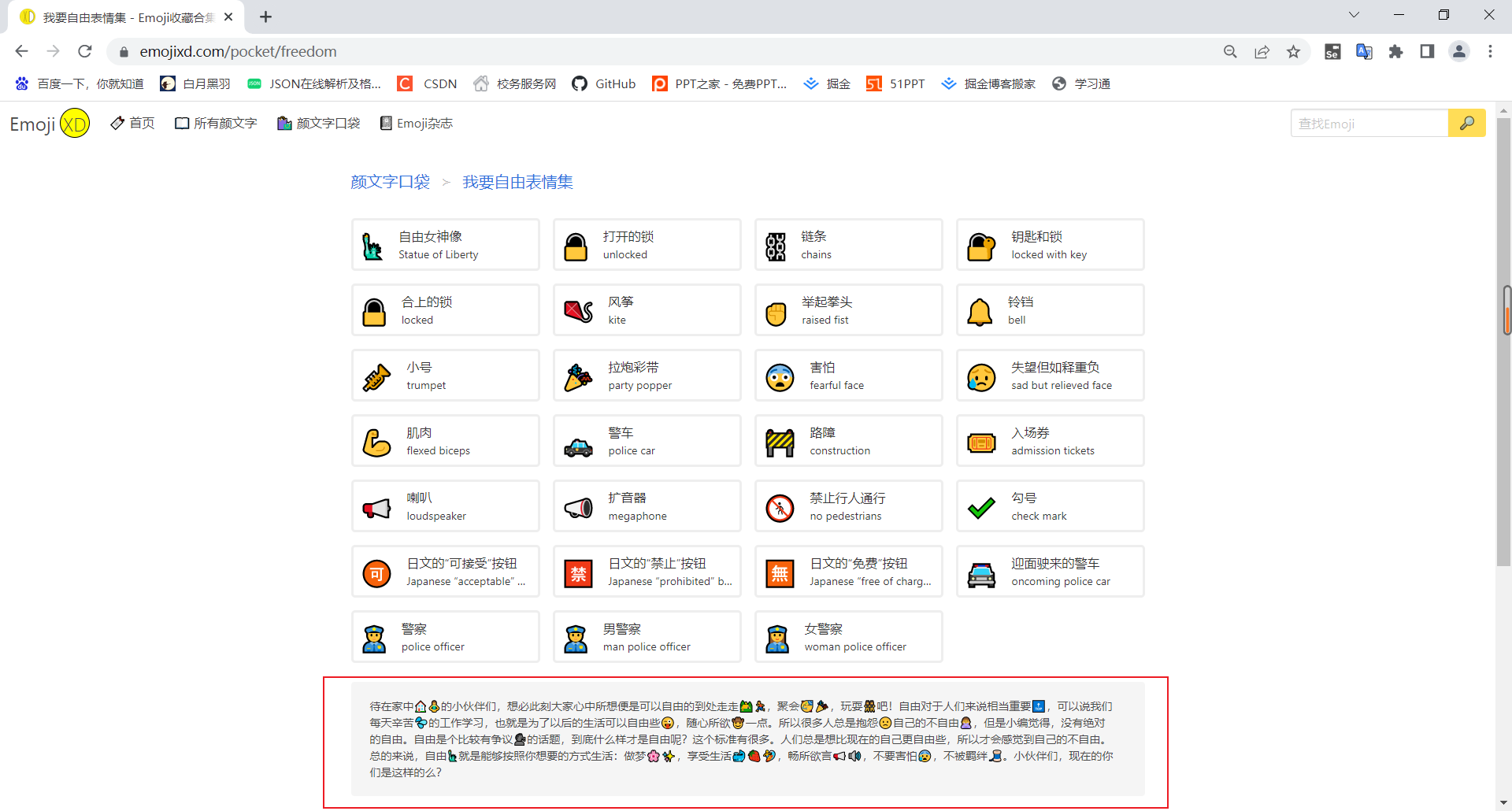 不过我在一些板块中发现了emoji文案,觉得有趣,也爬取下来了。
不过我在一些板块中发现了emoji文案,觉得有趣,也爬取下来了。
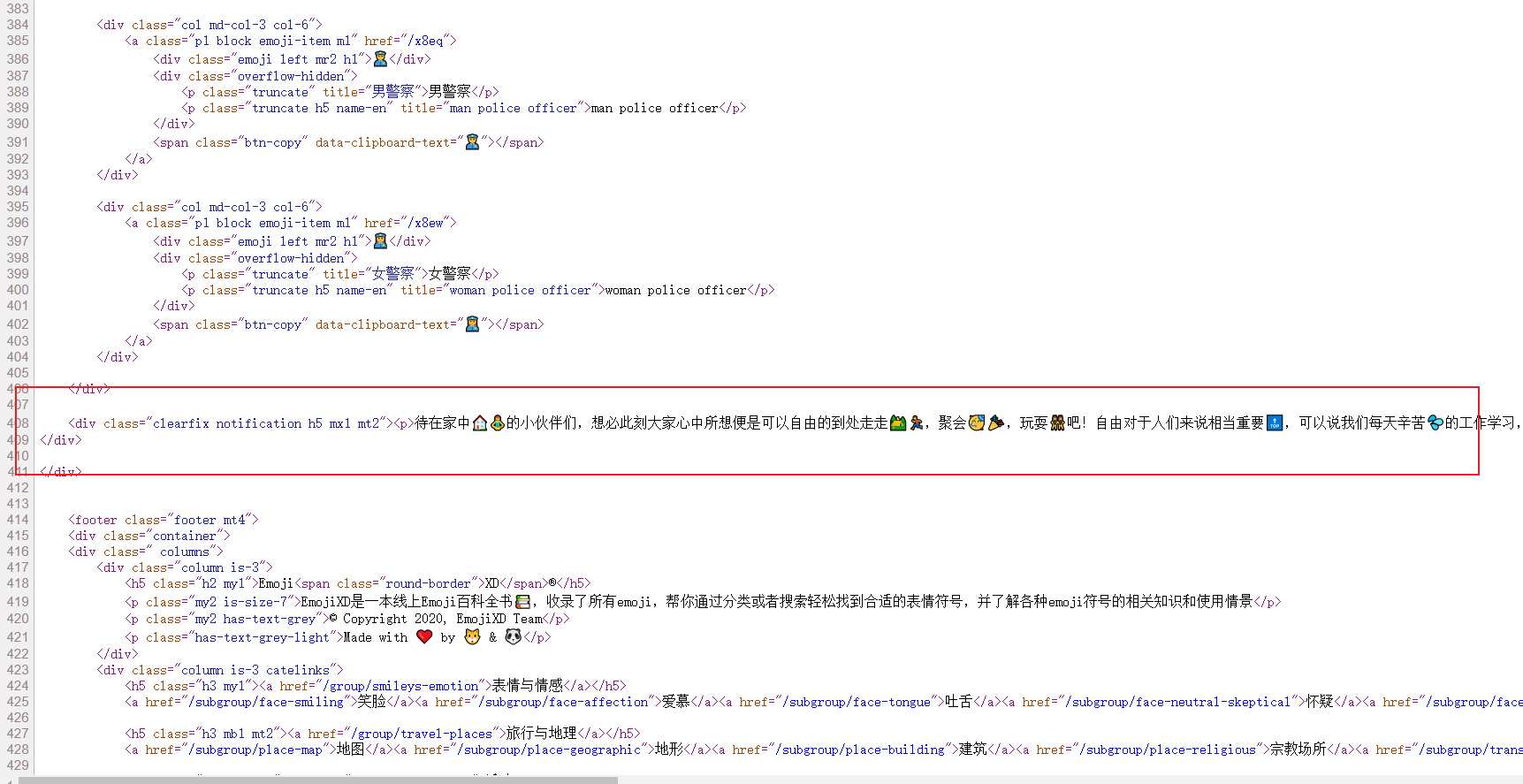
查看网页源代码,文案在这里。因此编写正则表达式。并保存文件为md。
text = re.findall('(.*?)
', new_response.text, re.S) print(text) for j in text: with open('text.md', 'a', encoding='utf-8') as f: f.write(j)

爬下来的文案看着非常乱,因为全部连在一起。
因此我们加两个换行(具体markdown的写法笔者也不是太熟悉,自己也是尝试出来的)
text = re.findall('(.*?)
', new_response.text, re.S) print(text) for j in text: with open('text.md', 'a', encoding='utf-8') as f: f.write(j) f.write('\n') f.write('\n')

这样就显得比较有序了。
至此,爬取emoji表情全部大功告成。
1.4.2全部代码展示
# -*- coding: utf-8-*-import requestsimport reurl = "https://emojixd.com/pockets"response = requests.get(url)# print(response.text)a = re.findall('', response.text)# print(a)'''['/pocket/mid-autumn-2020', '/pocket/freedom', '/pocket/qingming', '/pocket/science', '/pocket/invest', '/pocket/Arbor_Day', '/pocket/customer_first', '/pocket/spring', '/pocket/i_love_work', '/pocket/hero', '/pocket/womensday', '/pocket/insomnia', '/pocket/cooking', '/pocket/jingzhe', '/pocket/child_at_home', '/pocket/lovely_cat', '/pocket/online_work', '/pocket/keep_slim', '/pocket/keep_fit', '/pocket/baking', '/pocket/womens_day', '/pocket/control-disease', '/pocket/on_the_way', '/pocket/new-year', '/pocket/christmas', '/pocket/tired', '/pocket/party', '/pocket/chinese-zodiac', '/pocket/thanksgiving', '/pocket/halloween', '/pocket/love', '/pocket/congratulations', '/pocket/journey', '/pocket/holidays', '/pocket/hearts', '/pocket/zodiac']'''for b in a: base_url = 'https://emojixd.com' + b # print(base_url) new_response = requests.get(base_url) emoji = re.findall('(.*?) ', new_response.text) title = re.findall('(.*?)
', new_response.text) # print(emoji) # print(title) for i in emoji: with open('emoji_pockets.md', 'a', encoding='utf-8') as f: f.write(i) for i, j in zip(emoji, title): # print(i+j) with open('title_emoji_pockets.md', 'a', encoding='utf-8') as f: f.write(i + j) text = re.findall('(.*?)
', new_response.text, re.S) print(text) for j in text: with open('text.md', 'a', encoding='utf-8') as f: f.write(j) f.write('\n') f.write('\n')
二、总结
①本次爬虫案例比较简单,不涉及到cookie、headers等知识。大家可以自己去试试。该网址当python爬虫案例挺不错的。
②在学习爬虫的时候,还可以巩固一下正则表达式的相关知识(遇事不会,.*?无敌)。
③❤️❤️❤️觉得笔者写的不错的,希望三连支持一下!!❤️❤️❤️

