【数据结构】单链表
链表的种类有很多,这里只挑选其中的部分种类来实现
目录
1.链表概念
2.链表分类
3.链表的实现
3.1增加数据
3.1.1头部添加数据
3.1.2尾部添加数据
3.1.3任意位置加入数据
3.2删除数据
3.2.1删除第一次出现key值的位置的节点
3.2.2删除所有位置出现key值的节点
1.链表概念
链表同样是线性表的一种,其特点是物理存储结构不连续,逻辑顺序是通过链表中的引用链接次序来实现(具体可以想象下火车车厢是如何连接的)
具体结构如下图:
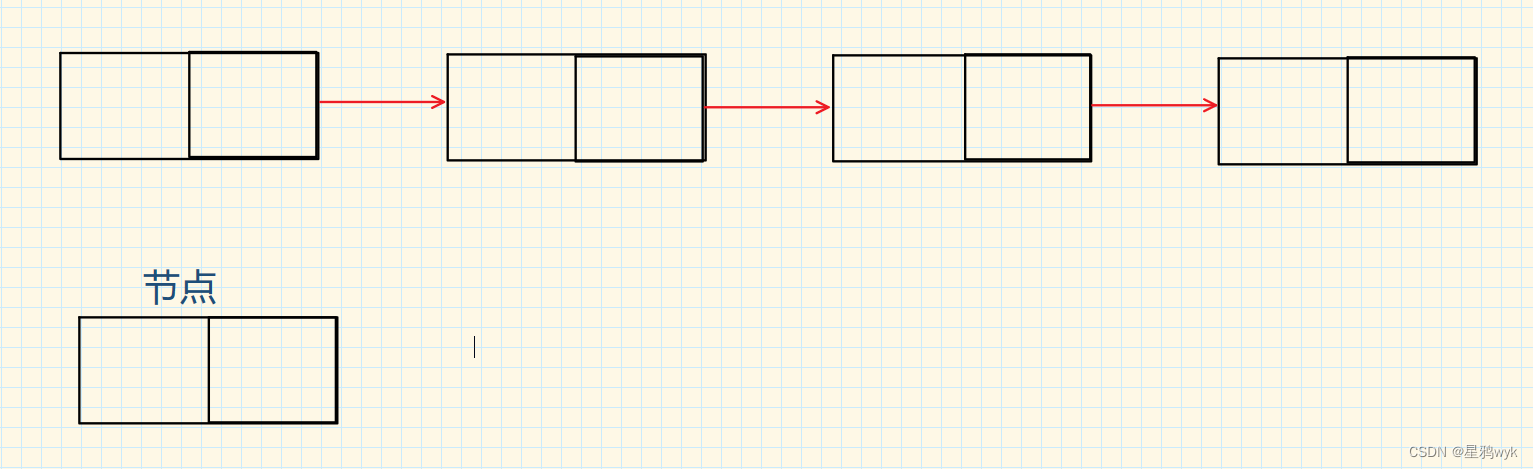
节点分为两个部分,一部分用来存放数据,另一部分存放下一节点的地址,第一个节点称为头结点
2.链表分类
链表的种类有很多,主要有3个特点
- 单向/双向
上图所示就是单向,双向的话节点就需要分成3部分,多出来的部分用来存放上一个节点的地址

- 循环/不循环
不循环就是最后一个节点指向null,循环则是指向头结点
- 带头/不带头
带头就是头结点不存放数据,只存放下一个节点的地址,不带头就是头结点也存放数据
带头的链表头节点是不变的
上述的特点进行排列组合的话就有8种链表结构,但是我们的重点只有两种
- 无头单向非循环链表:此链表结构最简单,在实际使用的时候多用于其它数据结构的子结构,并且在oj题中出现的最多的也是这种链表
- 无头双向循环链表:Java官方提供的链表就是此链表
本文实现的就是不带头单向不循环链表
3.链表的实现
首先链表是由节点组成,所以在链表类中定义一个节点的内部类
public class LinkList { static class ListNode { public int data; public ListNode next; public ListNode(int i) { this.data = i; } }}由于链表的结构,链表的增删改查等操作都需要头节点,所以在类里面再定义一个头节点,而且我想在实例化的时候可以直接在后面写数据,所以再加一个构造方法
public class LinkList {static class ListNode { public int data; public ListNode next; public ListNode(int i) { this.data = i; } } public ListNode head; public LinkList(int val) { ListNode listNode = new ListNode(val); this.head = listNode; }}接下来就是链表的操作,这里只讲增和删,这两个掌握,查和改也就不需要过多讲了
3.1增加数据
3.1.1头部添加数据
既然是头部添加数据,那么这个添加进来的节点就是新的头节点
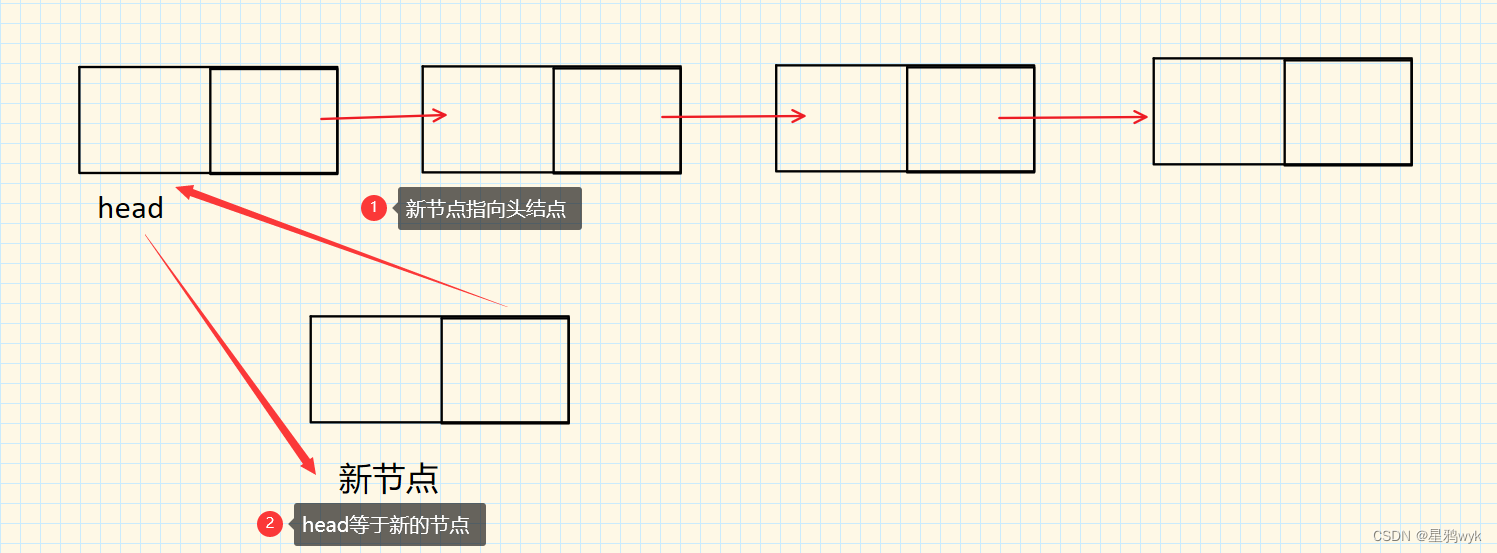
代码如下:
public void addFirst(int val) { ListNode node = new ListNode(val); node.next = this.head; this.head = node; }3.1.2尾部添加数据
在尾部添加数据的话,我们需要找到链表的最后一个节点,但找到最后一个节点要找到前一个节点,以此类推就是需要遍历整个链表,最后一个节点指向null就是循环结束的依据,将其指向的地址改为新加入的节点的地址即可
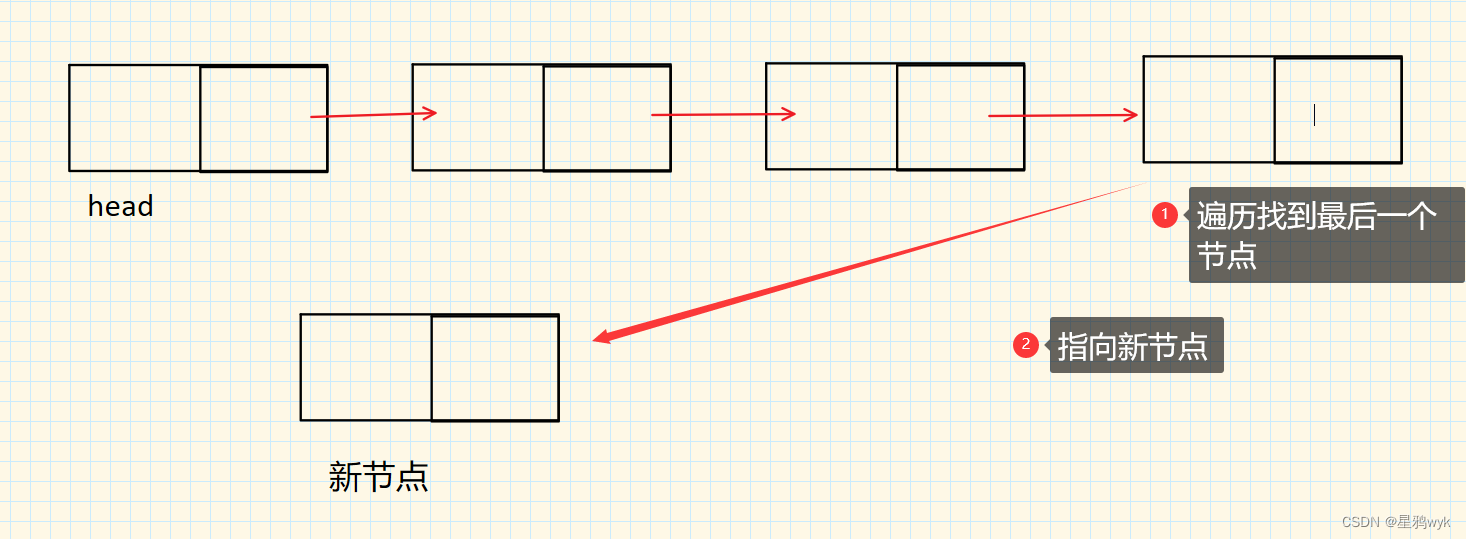
代码如下:
public void addLast(int val) { ListNode node = new ListNode(val); ListNode cur = this.head; while (cur.next != null) { cur = cur.next; } cur.next = node; }3.1.3任意位置加入数据
首先要判断给的位置是否合法,合法的话我们才能进行后面的操作
所以需要一个方法来获取链表的长度
public int size() { ListNode cur = this.head; int count = 0; while (cur != null) { ++count; cur = cur.next; } return count; }通常情况下我们需要找到此位置前一个位置的节点,先将前一个节点存储的地址给新节点存储,然后再让前一个节点指向新的节点
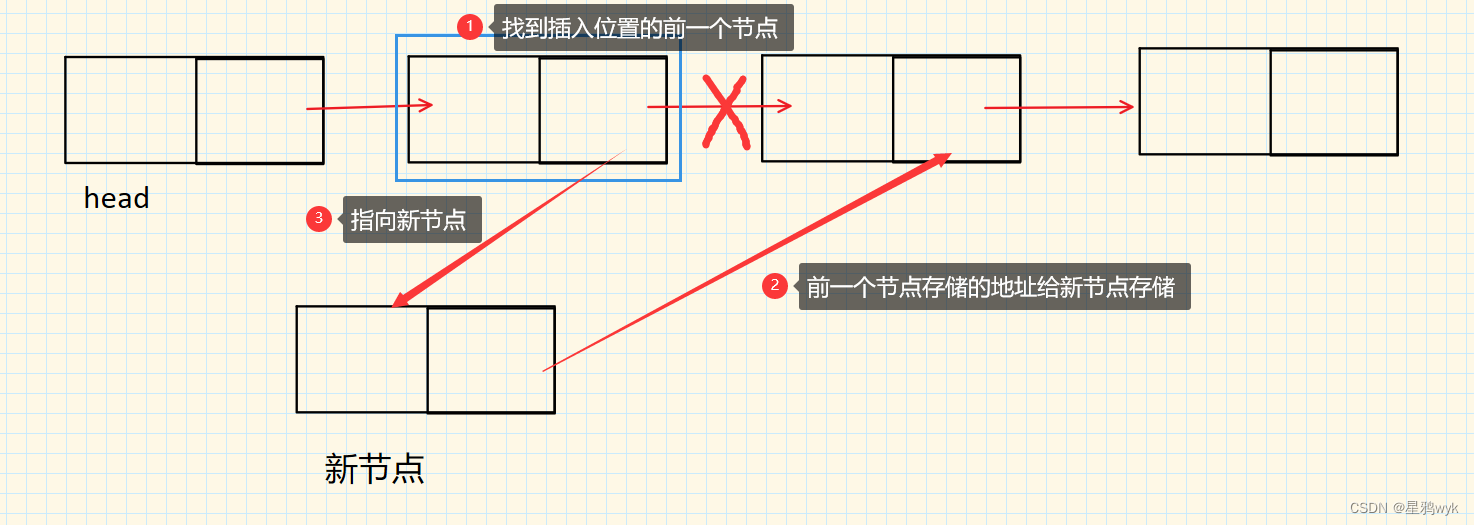
因为要找到前一个位置的节点,所以需要一个查找方法:
private ListNode findIndex(int i) { ListNode cur = this.head; while (i - 1 != 0) { cur = cur.next; i--; } return cur; }代码如下:
//头结点的位置为0public void add(int index, int val) { if (index this.size()) { throw new ArrayIndexOutOfBoundsException("index位置非法"); } if (index == 0) { addFirst(val); return; } if (index == this.size()) { addLast(val); return; } ListNode node = new ListNode(val); ListNode cur = findIndex(index - 1); node.next = cur.next; cur.next = node; }3.2删除数据
这里写两个方法,给定一个值,一个是删除这个值第一次出现位置的节点,另一个是删除所有位置出现此方法的节点
3.2.1删除第一次出现key值的位置的节点
首先判断链表是否为空链表,不是再继续往下
如果要删除的节点恰好是头结点的话让头结点汪后面移动一位即可,其它位置则是将前一个位置的节点存储的地址改为要删除的节点存储的地址
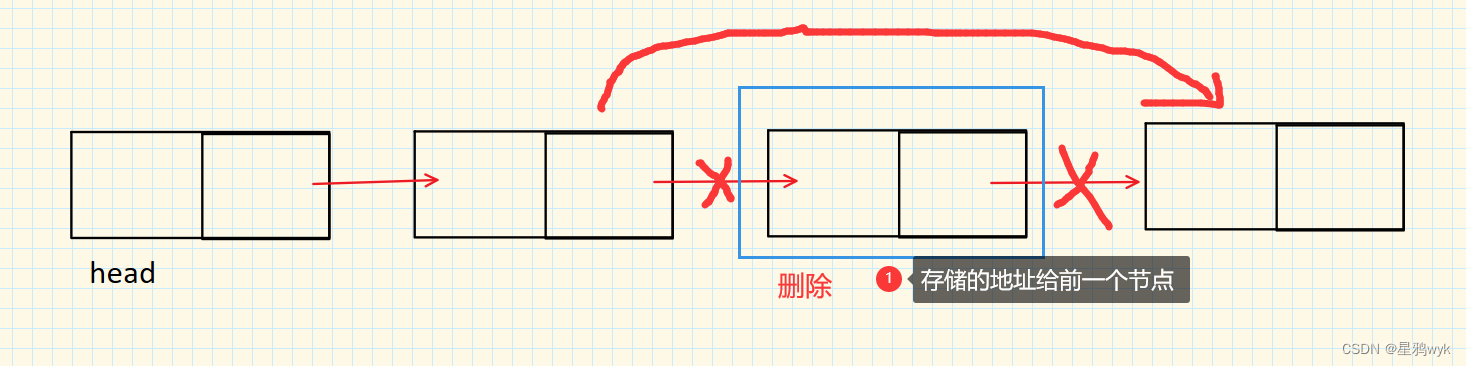
代码如下:
public void del(int key) { ListNode cur = this.head; if (this.head == null) { //链表为空 System.out.println("空链表"); } if (this.head.data == key) { //头删,将头结点后移 this.head = cur.next; return; } while (cur.next != null) { if (cur.next.data == key) { ListNode del = cur.next; cur.next = del.next; return; } cur = cur.next; } }3.2.2删除所有位置出现key值的节点
按照上面的思路,我们在遍历链表的时候依旧需要找到前一个节点,所以定义两个节点,一个从头节点开始,一个从头节点的下一个节点开始,二者同时往后移动,遇到是key值的节点就删除,最后再处理一下需要删除头节点的情况
代码如下:
public void delAll(int key) { if(head==null) { return; } ListNode del = this.head.next; //要删除的节点 ListNode prev = this.head; //del的前一个节点 while(del!=null) { if(del.data==key) { prev.next=del.next; del=del.next; } else { del=del.next; prev=prev.next; } } //单独处理头结点为删除节点的情况,头节点往后移动即可 if(this.head.data==key) { this.head=this.head.next; } }单链表就结束了,后面会找一些关于链表的oj题目,来看看单链表的实际使用
完

