Kafka实战《原理2》
Kafka Broker
工作流程
Zookeeper存储的Kafka信息
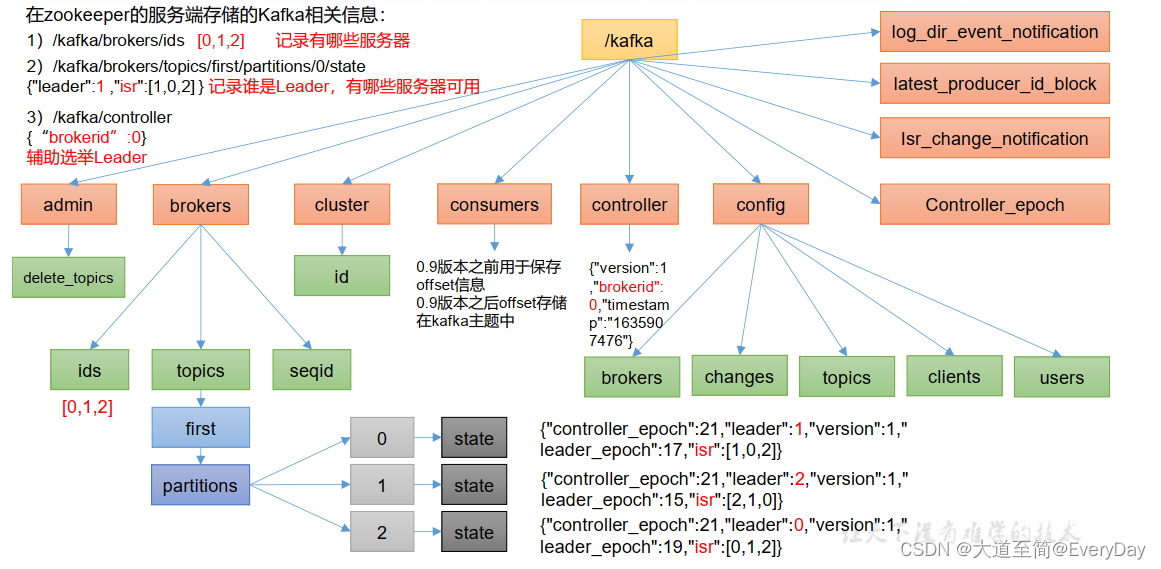
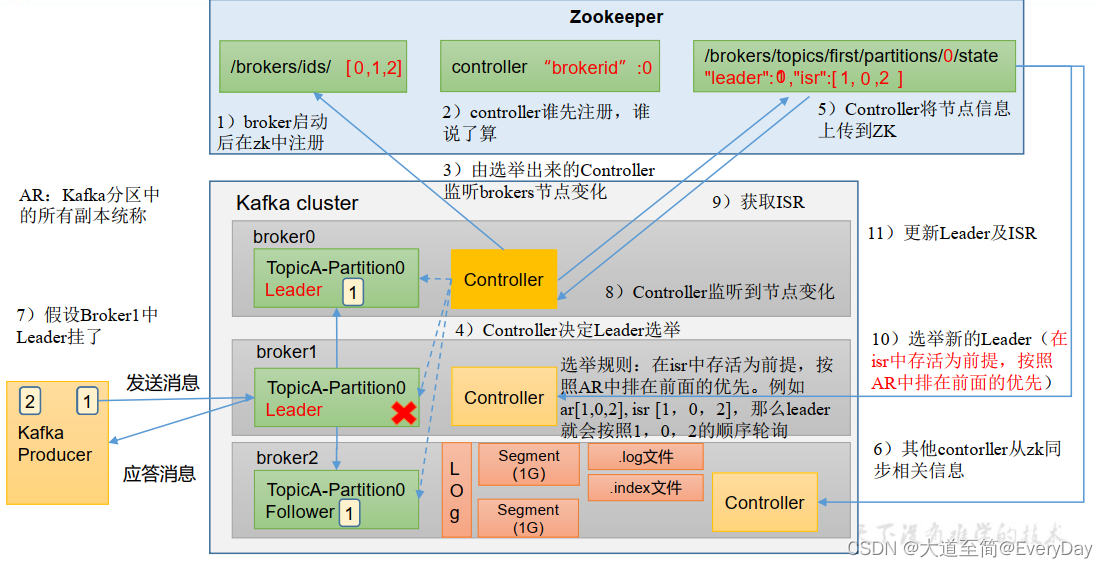
Kafka Broker总体工作流程
Broker参数
| 参数名称 | 描述 |
|---|---|
| replica.lag.time.max.ms | ISR中,如果Follower长时间未向Leader发送通信请求或同步数据,则将该Follower踢出ISR中,该时间阈值,默认30s |
| auto.leader.rebalance.enable | 默认true,自动Leader Partition平衡 |
| leader.imbalance.per.broker.percentage | 默认10%,每个broker允许的不平衡的leader比率。如果每个broker超过了这个值,控制器会触发leader平衡 |
| leader.imbalance.check.interval.seconds | 默认300s,检查Leader负载是否平衡的间隔时间 |
| log.segment.bytes | kafka中的日志是分成一块块存储的,此配置是指log日志划分成块大小,默认值1g |
| log,index.interval,bytes | 默认4kb,kafka每当写入4kb大小的日志,然后就往index文件里面记录一个索引 |
| log.retention.hours | kafka中数据保存的时间,默认7天 |
| log. retention.minutes | kafka中数据保存的时间,分钟级别,默认关闭 |
| log. retention.ms | kafka中数据保存的时间,毫秒级别,默认关闭 |
| log.retention.check.interval.ms | 检查数据是否超时的间隔,默认是5分钟 |
| log.cleanup.policy | 默认是delete,表示数据启用删除策略;如果设置为compact,表示所有的数据启用压缩策略 |
节点服役和退役
节点服役
新节点添加
1,启动新节点
./kafka-server-start.sh -daemon ../config/server.properties2,执行负载均衡
- 创建一个要均衡的主题 vim topics-to-move.json
{"topics":[{"topic":first}],"version": 1}- 生成一个负载均衡的计划
bin/kafka-reassign-partitions.sh --bootstrap-server ah101:9092 --topics-to-move-json-file topics-to-move.json --broker-list "1001,1002,1003" --generate- 创建副本负载计划 vim increase-replication-factor.json
{ "partitions": [ { "topic": "first", "partition": 0, "replicas": [ 1001, 1002, 1003 ] }, { "topic": "first", "partition": 1, "replicas": [ 1002, 1001, 1003 ] }, { "topic": "first", "partition": 2, "replicas": [ 1001, 1002, 1003 ] }, { "topic": "first", "partition": 3, "replicas": [ 1003, 1002, 1001 ] }, { "topic": "first", "partition": 4, "replicas": [ 1001, 1002, 1003 ] }, { "topic": "first", "partition": 5, "replicas": [ 1003, 1001, 1002 ] }, { "topic": "first", "partition": 6, "replicas": [ 1002, 1001, 1003 ] }, { "topic": "first", "partition": 7, "replicas": [ 1001, 1003, 1002 ] } ], "version": 1}- 执行副本存储计划
./kafka-reassign-partitions.sh --bootstrap-server ah101:9092 --reassignment-json-file increase-replication-factor.json --execute
- 验证副本存储计划
./kafka-reassign-partitions.sh --bootstrap-server ah101:9092 --reassignment-json-file increase-replication-factor.json --verify
节点退出
- 创建一个要均衡的主题 vim topics-to-move.json
{"topics":[{"topic":first}],"version": 1}- 生成一个负载均衡的计划
bin/kafka-reassign-partitions.sh --bootstrap-server ah101:9092 --topics-to-move-json-file topics-to-move.json --broker-list "1001,1002" --generate- 创建副本负载计划 vim remove-replication-factor.json
- 执行副本存储计划
./kafka-reassign-partitions.sh --bootstrap-server ah101:9092 --reassignment-json-file remove-replication-factor.json --execute-
- 验证副本存储计划
./kafka-reassign-partitions.sh --bootstrap-server ah101:9092 --reassignment-json-file remove-replication-factor.json --verifyKafka副本
副本的基本信息
- 作用 :提高数据的可靠性
- 默认副本1个,生产环境一般配置为2个,保证数据的可靠性,太多副本会增加磁盘存储空间,增加网络上的数据传输,降低效率
- 副本分为 Leader和Follower 。kafka生产者只会将数据发送给leader,然后follower会从leader进行同步数据
- kafka分区所有的副本称为AR
AR=ISR+OSR
ISR: 表示和Leader保持同步的Follower的集合。如果Follower长时间未向Leader发送通信请求或者同步数据,则该数据会被踢出ISR列表,该时间阈值由replica.lag.time.max,ms参数设定,默认30s。Leader发生故障的时候,就会从ISR中选举新的Leader。
OSR:表示Follower与Leader副本同步的时候,延迟过多的副本。
Leader选举流程
Kafka集群中有一个broker 的Controller会被选举为Controller Leader,负责管理集群broker的上下线,所有的topic的分区副本分配和Leader选举等工作。
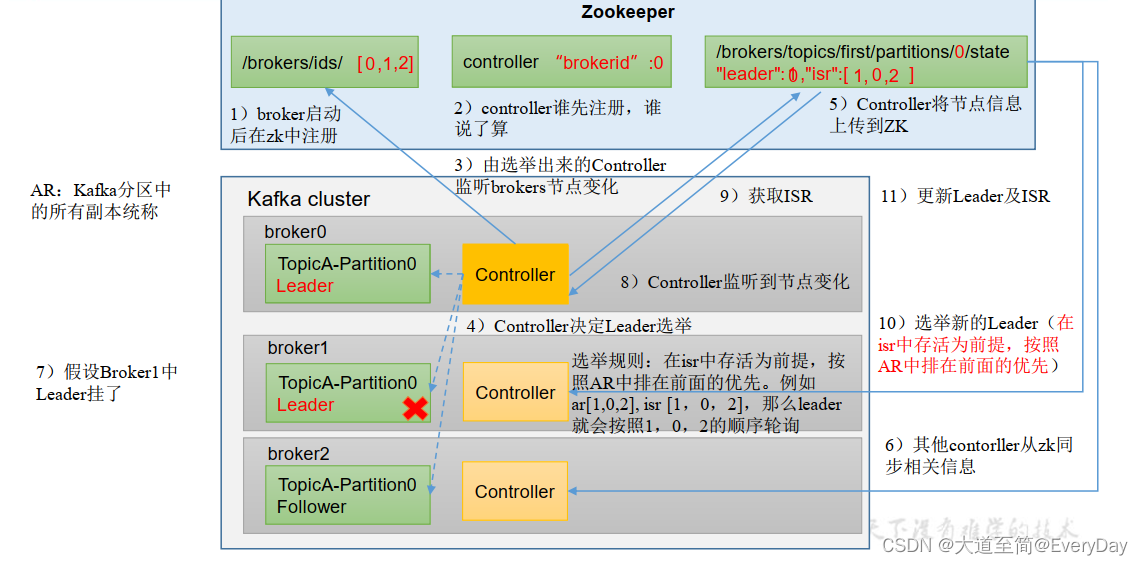
Follower故障处理细节
LEO(log end offset):每个副本的最后offset,LEO其实就是最新的offset+1
HW(high watermark): 所有副本中最小的LEO。
1)Follower故障
- Follower发生故障后会被踢出ISR
- 这个期间 Leader和Follower继续接受数据
- 待该Follower恢复后,Follower会读取本地磁盘记录的上次HW,并将log文件高于HW部分截取掉,从HW开始向Leader进行同步
- 等该Follwer的LEO大于等于该partitionde HW,则将Follower重新加入ISR
2)Leader故障
- Leader发生故障的时候,会从ISR中选出一个新的Leader
- 为保证多个副本之间数据一致性,其余的Follower会先将各自的log文件高于HW的部分裁掉,然后从新的Leader同步
注意:这只能保证副本之间的数据一致性,并不能保证数据不丢失或者不重复
分区副本分配
如果一个topic 创建16个分区 3个副本
那么AR规律
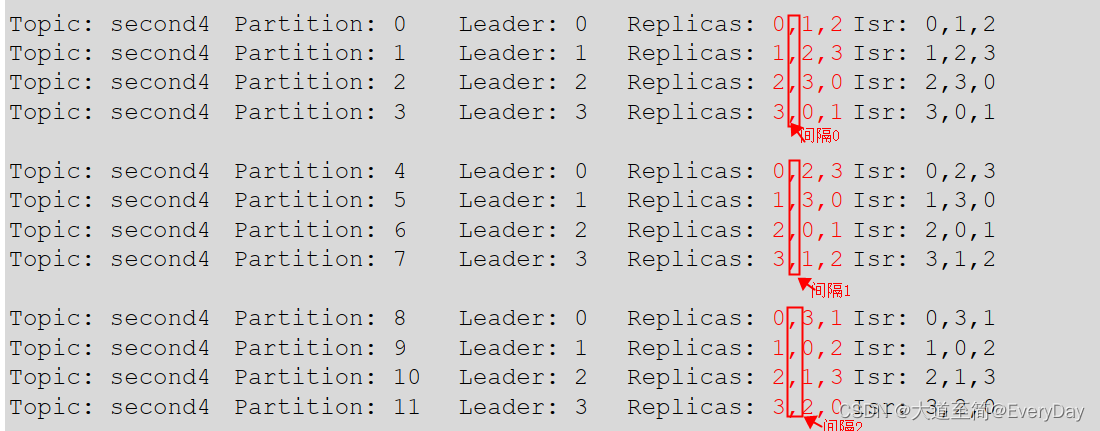
特点:
1)第一列为每个broker id 的排序 比如0,1,2,3,比如 1001 1002,1003
2)根据broker的数量作为一组进行副本分配
比如如果是4个broker组成的集群 那么leader 是0,1,2,3 ,AR 和ISR的列表的第一个也必定的是0,1,2,3
3) 一把第一个是间隔为0 第2个间隔为1 ,第三个间隔为2,这个间隔数和副本设置的数量有关系的
比如设置副本数为3 那么最后的间隔最大数为2 (3-1)
手动调整分区副本存储
生产环境中,每台服务器的配置和性能不一致,但是kafka只会根据自己的代码规则创建对应的副本,就会导致个别服务器存储压力比较大。所以需要手动调整分区副本的存储。
需求: 创建一个新的topic (testTopic) ,4个分区,2个副本,。将该topic的所有副本都存储到broker0和broker1
步骤
1)创建topic
bin/kafka-topics.sh --bootstrap-server ah101:9092 --create --partitions 4 --replication-factor 2 -topic testTopic- 创建副本存储计划 (所有的副本存储在broker0 ,broker1)vim assign.json
{"version":1,"partitions":[{"topic":"testTopic","partition":0,"replicas":[0,1]},{"topic":"testTopic","partition":1,"replicas":[0,1]},{"topic":"testTopic","partition":2,"replicas":[1,0]},{"topic":"testTopic","partition":3,"replicas":[1,0]}]}3) 执行副本存储计划
bin/kafka-reassign-partitions.sh --bootstrap-server ah101:9092 --reassignment-json-file assign.json --execute4) 验证副本存储计划执行的情况
bin/kafka-reassign-partitions.sh --bootstrap-server ah101:9092 --reassignment-json-file assign.json --verify5)查看副本存储情况
bin/kafka-topics.sh --bootstrap-server ah101:9092 --describe --topic testTopicLeader Partition 负载均衡
正常情况下,Kafka本身会自动把Leader Partition均匀的分散在各个机器上,来保证每台机器的读写和吞吐量都是均匀的。但是如果某些broker宕机,会导致leader partition过于集中在其他少部分的几台broker上,这会导致这几台的broker读写请求压力过高,其他宕机的broker重启只后都是follower,读写请求很低,造成集群负载不均衡
| 参数名称 | 描述 |
|---|---|
| auto.leader.rebalance.enable | 默认true,自动Leader partition平衡。生产环境中国,Leader重选举代价比较大,可能会带来性能影响,建议设置false关闭 |
| leader.imbalance.per,broker,percentage | 默认10%,每个broker允许的不平衡的leader的比率。如果每个broker超过这个值,控制器会触发重平衡 |
| leader.imbalance.check.interval.time | 默认值100,检查Leader负载是否平衡的间隔时间 |
文件存储
1)topic数据存储机制
topic是逻辑上的概念,而partition是物理上的概念。每个partition对应一个log文件,该log文件存储的就是Producer生产的数据。Producer生产的数据会被不断的追加到该log文件的末端。为防止log文件过大导致数据定位效率低下,kafka采取分片和索引机制,将每个partition分为多个segement。每个segment包括 “.index”,“.log”,".timeindex"等文件。该文件命名规则 topic名称+分区序号,列如first-0。
说明: index和log文件以当前segment第一条消息的offset命名
通过工具可以查看index和log文件信息
kafka-run-class.sh kafka.tools.DumpLogSegments --file ./000000000000000000000000.indexkafka-run-class.sh kafka.tools.DumpLogSegments --file ./000000000000000000000000.log2)如何在log文件中定位到offset=100的record?
- 根据目标offset定位segment文件
- 找到小于等于目标offset的最大offset对应的索引项
- 定位log文件
- 向下遍历找到目标record记录
3) 文件清理策略
kafka的日志默认保存时间7天,可以通过调整参数修改保存时间。
log.retention.hours 最低优先级小时 ,默认7天
log.retention.check.interval.ms 负责设置检查周期,默认5分钟
4)日志一旦超过设置的时间,怎么处理?
kafka提供的日志清理策略有两种
delete和compact两种
- log.clean.policy=delete 所有的数据启用删除策略
(1)基于时间:默认打开,以segment中所有记录中最大的时间戳作为该文件的时间戳
(2)基于大小:默认关闭。超过设置所有日志总大小,删除最早的segment。 log.retention.bytes 默认-1,表示无穷大 - log.clean.policy=compact
对于相同key 不同value值,只保留最后一个版本。
压缩后offset数据不是连续的。
这种策略只适合特殊场景,比如消息的key为用户id,value是用户资料,通过这中压缩策略,整个消息就保存所有用户的最新资料。
5)高效读写数据
- kafka本身是分布式集群,采用分区技术,并行度高
- 读数据采取稀疏索引,可以快速的定位要消费数据的位置
- 顺序写磁盘(省去大量磁头寻址时间)
- 页缓存+0拷贝技术
PageCahe:kafka重度依赖底层操作系统提供的pagecahce功能。当上层有写操作的时候,操作系统只是将数据写入pagecache,当读操作发生的时候,先从pagecache中读取,如果找不到,在从磁盘中读取
Kafka 消费者
Kafka的消费方式
pull模式:
consumer采用从broker主动拉取数据
push模式:
broker推送数据到consumer
kafka采用的pull方式,因为由broker决定消息发送速率,很难适应所有的消费者的消费速率。
pull模式不足之处:如果kafka没有数据,消费者可能会陷入死循环中,一直返回空数据。
消费的工作流程
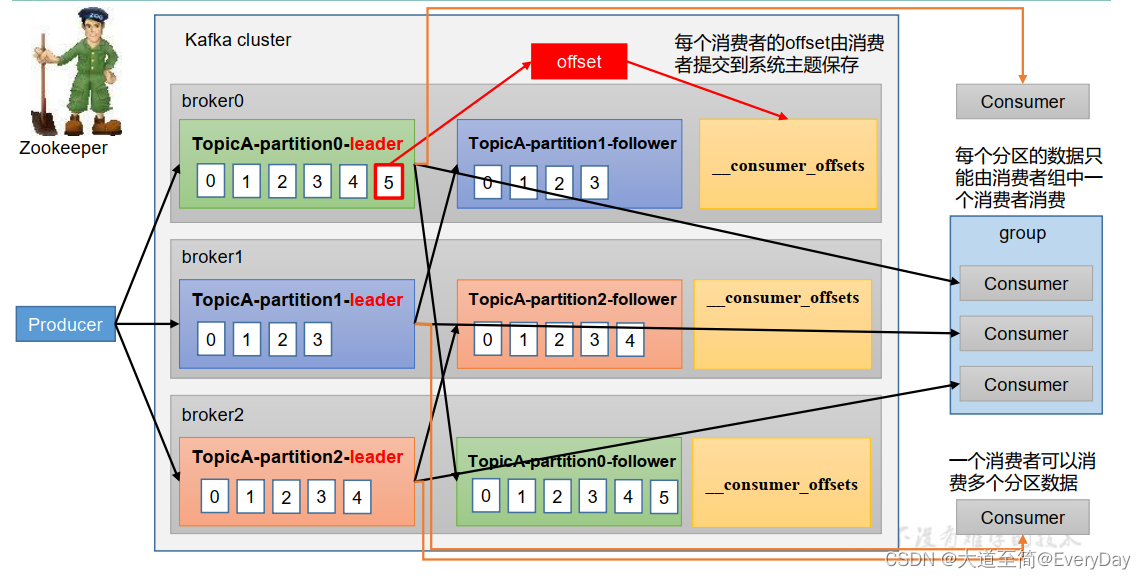
消费者组:由多个消费者组成。形成一个消费者组的条件,所有的消费者的groupid相同
- 消费者组内每个消费者负责消费不同的分区数据,一个分区只能由一个组内消费者消费。
- 消费者组之间互不影响。所有的消费者都属于某个消费者组。即消费者组是逻辑上一个订阅者
- 如果消费者组中添加更多消费者,超过主题分区的数量,则有一部分消费者会闲置。不会接受任何消息

