排序算法——希尔排序
引言
希尔排序,这个排序算法如同一位精明的园丁,通过逐渐缩小花园的大小来打理他的植物,最终将整个花园(数组)排列得井井有条。它是一种插入排序的变种,特别适用于处理大规模数据集。尽管在最坏情况下,它的性能与插入排序相同,但通常情况下,希尔排序表现得更高效。今天,我们就来探讨这个算法,从其基本原理、实例操作,到具体实现和性能分析,全方位地了解希尔排序的奥秘。
相关问题
1. 希尔排序是如何工作的?
希尔排序通过将数据分成多个子集并分别进行排序来工作。它首先设定一个增量序列,通常是数组长度的一半,然后在这些增量下对数据进行排序。随着增量的减小,数据集逐渐变得有序,直到增量减少到1,进行最后一次排序,此时数据已经基本有序,因此排序效率较高。
2. 希尔排序与插入排序有什么不同?
希尔排序不同于插入排序,它不是简单地将每个元素插入到已经排好序的子序列中,而是通过对元素进行分组,先在较大范围内进行比较和交换,逐步缩小搜索范围,这大大减少了移动元素的次数。
相关答案
1. 希尔排序的优点是什么?
希尔排序的主要优点是其高效的性能,尤其是在处理大规模数据集时。通过增量序列的选择,它能够有效减少需要移动的元素数量,这在某种程度上减少了算法的复杂度。
2. 希尔排序的缺点是什么?
尽管希尔排序在处理大规模数据时表现出色,但在数据已经接近有序的情况下,它的效率可能会降低,这时直接插入排序可能更优。此外,希尔排序的内部循环依赖于序列的增量,这些增量的选择对算法性能有显著影响。
总结
希尔排序,这个算法如同其名,是一个智慧的工具,它巧妙地使用增量来修剪整个序列,最终达到完美的排序效果。通过本文的探讨,我们不仅学会了如何实现希尔排序,还深入理解了其背后的原理和策略。希望这些知识能帮助你在数据的世界中更加得心应手,像掌握了一把精准的园林剪,剪裁出最美的数据花园。
目录
🛴基本介绍
算法思想
🛹实例
思路分析
代码实现
🛵算法性能分析
🛴基本介绍
希尔排序也是一种插入排序,它是简单插入排序经过改进之后的一个更高效的版本,也称为见效增量排序。
希尔排序的时间复杂度比直接插入排序的时间复杂度小,他与直接插入排序的不同在于它会优先比较距离较远的元素。
算法思想
希尔排序是按照一定的增量进行分组排序,对每组使用直接插入排序算法排序;随着分组个数的减少,每组中元素就会越来越多,当增量减少为1时,排序结束。
🛹实例
原始数组:[8,9,1,7,2,3,5,4,6,0]
分组的个数与数据个数有关。一般情况下,选择增量为gap=length/2
分组的个数一般为奇数个,因为偶数组会存在重复排序,所以分组个数为奇数组
思路分析
第一趟排序:初始增量gap=length/2=5,即将整个数组分为五组,对这五组分别进行直接插入排序
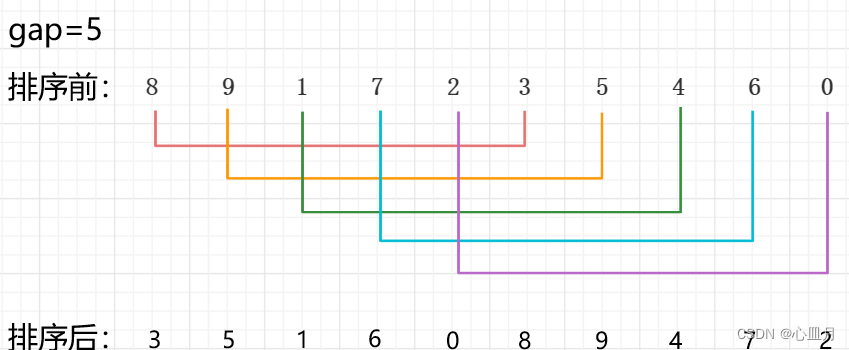
第二趟排序:然后缩小增量,gap=5/2=2,数组被分为两组,对这两组分别进行直接插入排序
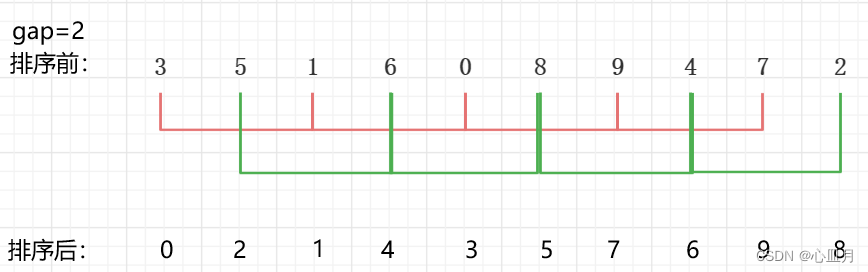
第三趟排序:
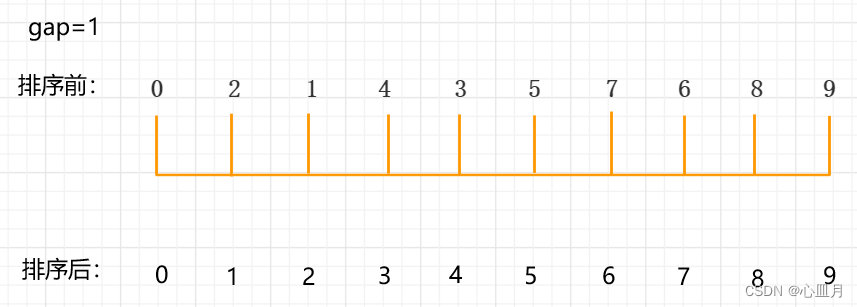
再缩小增量为gap=2/2=1,此时整个数组为1组,进行直接插入排序,结果如下:
代码实现
public class ShellSort { public static void main(String[] args) { int []arr={8,9,1,7,2,3,5,4,6,0}; shellSort(arr); System.out.println("排序后的数组为:"+Arrays.toString(arr)); } private static void shell(int[]arr,int gap){ if (arr==null||arr.length==1){ return; } //从第二个元素开始,和前面的有序表进行比较 for (int i=1;i=0;j-=gap){ if (arr[j]>temp){ arr[j+gap]=arr[j];//后移一个位置 } else { break; } } arr[j+gap]=temp; } } public static void shellSort(int []arr) { int[] gaps = {5, 3, 1}; for (int i = 0; i < gaps.length; i++) { shell(arr, gaps[i]); } }}运行结果:

🛵算法性能分析
时间复杂度:O(n^1.3-1.5)
空间复杂度:O(1)
稳定性:不稳定

