Redis事件驱动框架(下),让服务转动起来?
文章目录
- 前言
- 一、哪些事件?
-
- 1、结构:
- 2、形象化?
- 二、文件事件
-
- 1、起源:
-
- 1.1 事件处理入口
- 1.2 注册
- 2、连接事件:
-
- 2.1 接收新连接
- 2.2 IO就绪监听
- 3、IO读/命令执行:
- 4、IO写事件:
- 三、时间事件
-
- 1、起源:
-
- 1.1 结构
- 1.2 主流程
- 2、serverCron 周期性执行?
-
- 1.1 databasesCron
- 1.2 clientsCron
- 1.3 触发 AOF 重写
- 1.4 触发 RDB 执行
- 1.5 stopThreadedIOIfNeeded
- 3、内存驱逐策略?
- 总结
前言
本文参考源码版本为
redis6.2
我们知道,一家公司有多个部门分工合作,各司其职,才能支撑起整个公司的正常运转,如下图:
类比来看,redis 也由很多模块共同支撑,不同的是,redis 更像围绕一根轴心工作;当然,各模块的都以事件为通信介质,保持与轴心的信息互通。(总线型)
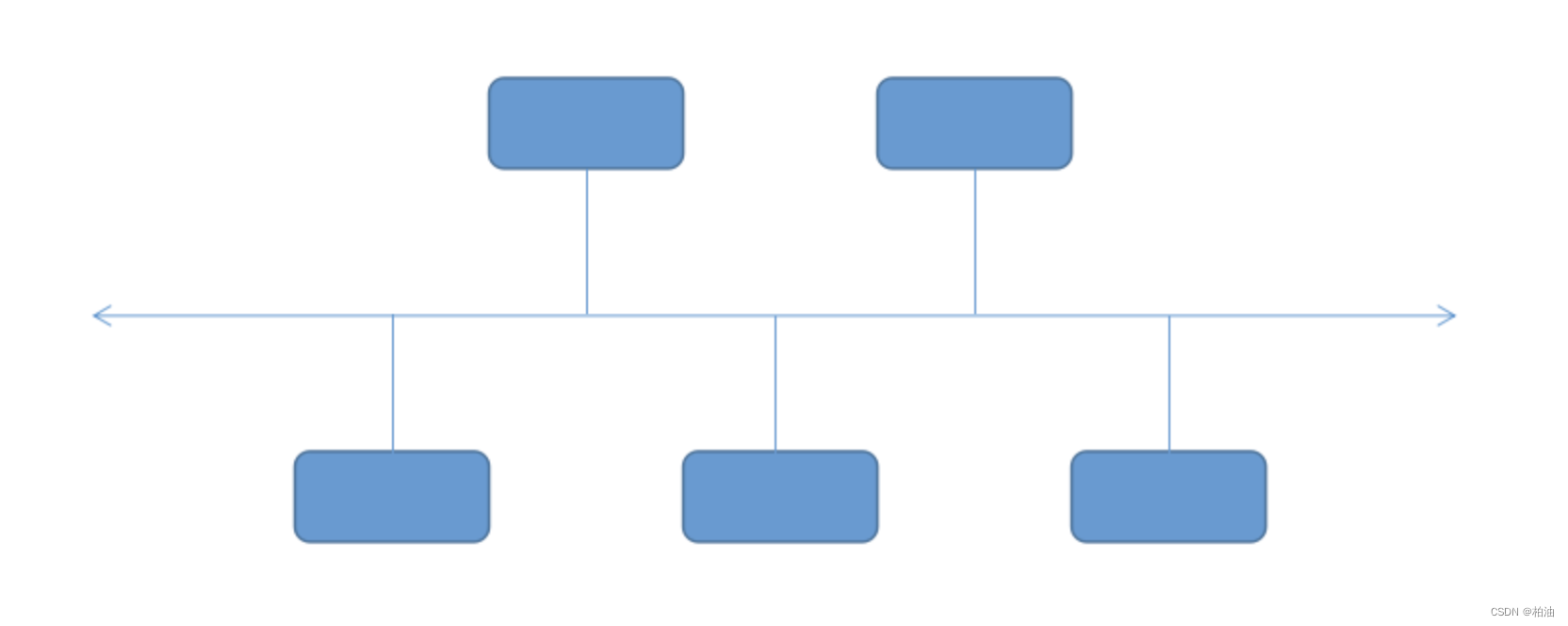
其实,这里的中轴线就是 redis 中的主线程,各个模块要处理的任务都通过事件的形式,投递到主线程,然后由主线程逐一处理。
这里的事件,分为客户端的连接请求、IO读/写、命令执行等;以及后台处理的周期性任务,比如,淘汰过期 key、rehash 等。
一、哪些事件?
redis 服务器是典型的事件驱动程序,而事件又分为文件事件(socket 的可读/可写事件)与时间事件(定时任务)两大类。无论是文件事件还是时间事件都封装在结构体 aeEventLoop中。
1、结构:
typedef struct aeEventLoop { int maxfd; /* highest file descriptor currently registered */ int setsize; /* max number of file descriptors tracked */ long long timeEventNextId; time_t lastTime; /* Used to detect system clock skew */ aeFileEvent *events; /* Registered events */ aeFiredEvent *fired; /* Fired events */ aeTimeEvent *timeEventHead; int stop; void *apidata; /* This is used for polling API specific data */ aeBeforeSleepProc *beforesleep; aeBeforeSleepProc *aftersleep;} aeEventLoop;-
其中,stop 标识事件循环是否结束;events 为文件事件数组,存储已经注册的文件事件;fired 存储被触发的文件事件;
-
redis 中多个时间事件形成链表,timeEventHead 即为时间事件链表头节点;
-
redis 服务器需要阻塞等待文件事件(IO多路复用查询)的发生,进程阻塞之前会调用 beforesleep 函数,进程因为某种原因被唤醒之后会调用 aftersleep 函数。
-
redis 底层可以使用 4 种 I/O多路复用模型(select、epoll等), apidata 是对这 4 种模型的进一步封装。
2、形象化?
一主一辅撑起 redis 大半天下。redis 服务启动最后阶段调用 aeMain 方法,真正启动了事件处理程序,一方面要处理主营业务,另一方面又要不断调整自身状况,就有了下面这种模式:
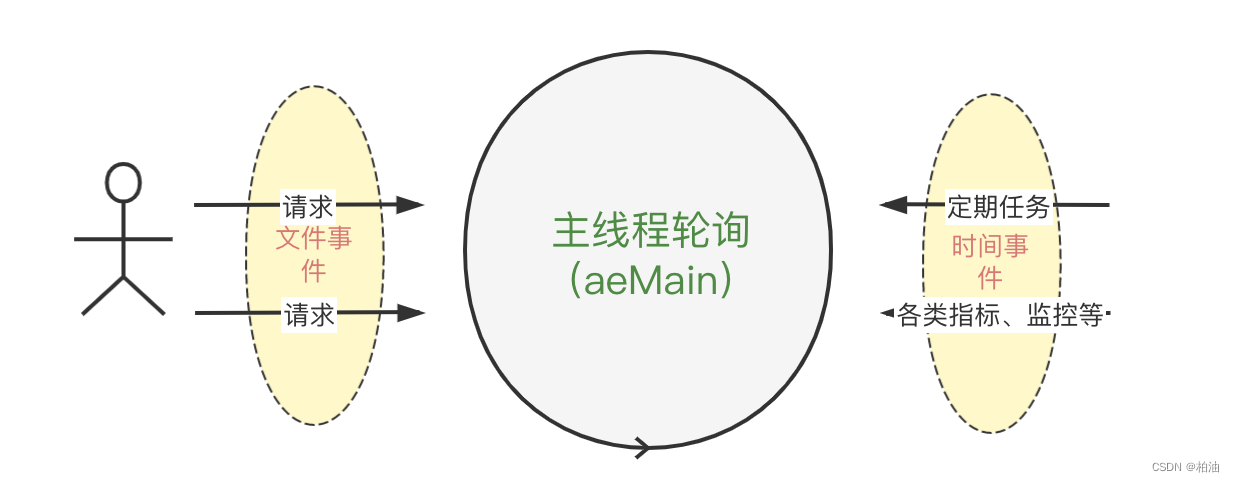
redis 核心业务自然是处理客户端的请求,我们称之为 主事件。当然,一个系统的正常运转需要很多辅助功能,比如周期性的巡检、任务处理等等,我们称之为 辅事件。
一主一辅均围绕着中轴线(主线程)交替性的执行各自任务。我们知道,redis 使用单线程执行命令,有个极大的好处是,不用考虑多线程带来的并发问题,以及线程上下文切换带来的开销问题。
因此,像 key过期淘汰策略、字典 rehash 等都是同命令处理在一个单线程内串行处理,不过会控制每次处理的数量,避免造成阻塞。
也正是这种主辅关系,redis 会优先处理主事件,然后再处理辅事件,如下图:
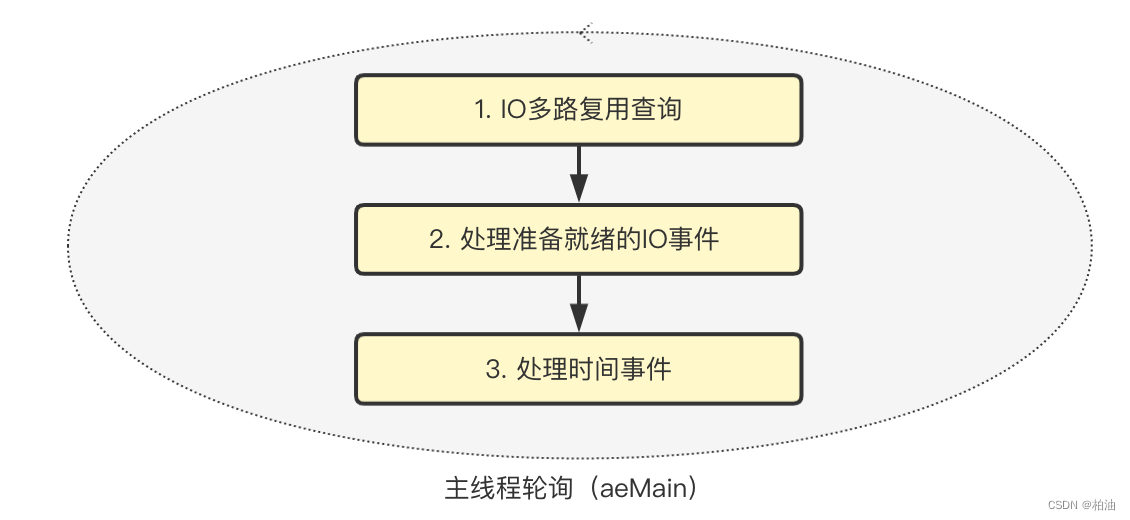
对应源码如下(aeMain在外层):
// ae.c#aeProcessEventsint aeProcessEvents(aeEventLoop *eventLoop, int flags){ ... // 1. 处理 文件事件 if (eventLoop->maxfd != -1 || ((flags & AE_TIME_EVENTS) && !(flags & AE_DONT_WAIT))) { ... // 1.1 多路复用查询IO事件是否就绪 numevents = aeApiPoll(eventLoop, tvp); // 1.2 处理就绪事件 for (j = 0; j < numevents; j++) { aeFileEvent *fe = &eventLoop->events[eventLoop->fired[j].fd]; ... if (!invert && fe->mask & mask & AE_READABLE) { fe->rfileProc(eventLoop,fd,fe->clientData,mask); fired++; fe = &eventLoop->events[fd]; /* Refresh in case of resize. */ } ... if (fe->mask & mask & AE_WRITABLE) { if (!fired || fe->wfileProc != fe->rfileProc) { fe->wfileProc(eventLoop,fd,fe->clientData,mask); fired++; } } ... } } // 2. 处理 时间事件 if (flags & AE_TIME_EVENTS) processed += processTimeEvents(eventLoop); return processed; /* return the number of processed file/time events */}二、文件事件
文件事件是 redis 核心事件,主要负责用户请求过程中的连接、IO读/写以及命令处理等操作。
我们在上一篇文章 一文搞懂,redis单线程执行全貌 围绕单线程(主IO线程)详细分析了用户请求的各个阶段,其中主要分析的就是文件事件。
关于文件事件,我们用一张图来看看:
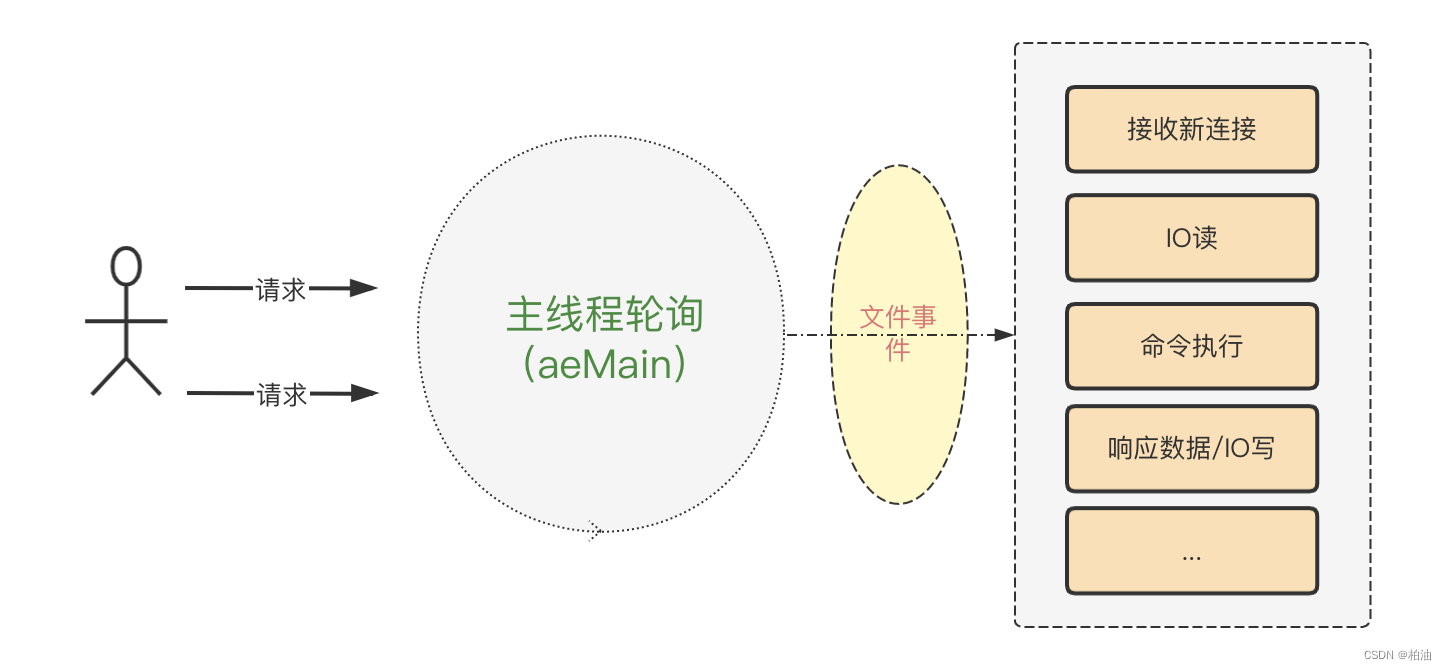
1、起源:
1.1 事件处理入口
// ae.c#aeMainvoid aeMain(aeEventLoop *eventLoop) { eventLoop->stop = 0; while (!eventLoop->stop) { aeProcessEvents(eventLoop, AE_ALL_EVENTS|AE_CALL_BEFORE_SLEEP|AE_CALL_AFTER_SLEEP); }}一切用户请求以及后台任务处理,都将从这里开始。
1.2 注册
// server.c#initServer() if (server.port != 0 && listenToPort(server.port,server.ipfd,&server.ipfd_count) == C_ERR) ... for (j = 0; j < server.ipfd_count; j++) { if (aeCreateFileEvent(server.el, server.ipfd[j], AE_READABLE, acceptTcpHandler,NULL) == AE_ERR) { serverPanic( "Unrecoverable error creating server.ipfd file event."); } }绑定端口,并注册文件描述符 ipfd 至内核进行监听新连接,并指定处理新连接的方法 acceptTcpHandler。
2、连接事件:
2.1 接收新连接
上面提到,在注册的时候,需要指定新连接的处理方法 acceptTcpHandler:
// networkind.c#acceptTcpHandlervoid acceptTcpHandler(aeEventLoop *el, int fd, void *privdata, int mask) { int cport, cfd, max = MAX_ACCEPTS_PER_CALL; char cip[NET_IP_STR_LEN]; UNUSED(el); UNUSED(mask); UNUSED(privdata); while(max--) { cfd = anetTcpAccept(server.neterr, fd, cip, sizeof(cip), &cport); if (cfd == ANET_ERR) { if (errno != EWOULDBLOCK) serverLog(LL_WARNING, "Accepting client connection: %s", server.neterr); return; } serverLog(LL_VERBOSE,"Accepted %s:%d", cip, cport); acceptCommonHandler(connCreateAcceptedSocket(cfd),0,cip); }}继续往下走,我们看到创建了 client,并为 readHandler 指定具体读取数据的 readQueryFromClient 方法:
// networking.c#createClientclient *createClient(connection *conn) { client *c = zmalloc(sizeof(client)); if (conn) { connNonBlock(conn); connEnableTcpNoDelay(conn); if (server.tcpkeepalive) connKeepAlive(conn,server.tcpkeepalive); connSetReadHandler(conn, readQueryFromClient); connSetPrivateData(conn, c); } ... }最后,我们看到,通过 readHandler 将新连接的文件描述符注册至内核:
// connection.c#connSocketSetReadHandlerstatic int connSocketSetReadHandler(connection *conn, ConnectionCallbackFunc func) { if (func == conn->read_handler) return C_OK; conn->read_handler = func; if (!conn->read_handler) aeDeleteFileEvent(server.el,conn->fd,AE_READABLE); else if (aeCreateFileEvent(server.el,conn->fd, AE_READABLE,conn->type->ae_handler,conn) == AE_ERR) return C_ERR; return C_OK;}然后就可以等待新连接的IO就绪事件了。
2.2 IO就绪监听
对于内核提供 IO 多路复用,需要我们主动批量查询已注册的文件描述符是否有IO事件准备就绪,即:
// ae.c#aeProcessEventsint aeProcessEvents(aeEventLoop *eventLoop, int flags){ ... // 调用内核多路复用API, 查询是否有IO事件就绪。当遇到超时或者部分IO事件就绪时返回 // 其中 numevents 表示就绪的IO事件数量 numevents = aeApiPoll(eventLoop, tvp); ...} 不同系统内核提供的支持不一样,因此,redis 也写了几套不同系统的 IO多路复用 支持,这里我们以 Linux 系统的 epoll 为例:
// ae_epoll.c#aeApiPollstatic int aeApiPoll(aeEventLoop *eventLoop, struct timeval *tvp) { aeApiState *state = eventLoop->apidata; int retval, numevents = 0; retval = epoll_wait(state->epfd,state->events,eventLoop->setsize, tvp ? (tvp->tv_sec*1000 + tvp->tv_usec/1000) : -1); if (retval > 0) { int j; numevents = retval; for (j = 0; j < numevents; j++) { int mask = 0; struct epoll_event *e = state->events+j; if (e->events & EPOLLIN) mask |= AE_READABLE; if (e->events & EPOLLOUT) mask |= AE_WRITABLE; if (e->events & EPOLLERR) mask |= AE_WRITABLE|AE_READABLE; if (e->events & EPOLLHUP) mask |= AE_WRITABLE|AE_READABLE; eventLoop->fired[j].fd = e->data.fd; eventLoop->fired[j].mask = mask; } } return numevents;}可以看到,最终通过内核提供 API epoll_wait 进行阻塞式查询。
3、IO读/命令执行:
当通过 IO多路复用监听到有读事件就绪时,就通过前面我们指定的readQueryFromClient 方法进行处理:
// networking.c#readQueryFromClientvoid readQueryFromClient(connection *conn) { client *c = connGetPrivateData(conn); ... // 读取数据 nread = connRead(c->conn, c->querybuf+qblen, readlen); ... // 命令执行 processInputBuffer(c);}继续往下定位,最终会定位到 redis 封装的一些列 xxxCommand,每个命令都有其对应的实现,调用该实现就执行了客户端命令。
4、IO写事件:
每个 xxxCommand 处理完结果后都会调用类似于 addReply 的方法进行响应:
void addReply(client *c, robj *obj) { if (prepareClientToWrite(c) != C_OK) return; if (sdsEncodedObject(obj)) { if (_addReplyToBuffer(c,obj->ptr,sdslen(obj->ptr)) != C_OK) _addReplyProtoToList(c,obj->ptr,sdslen(obj->ptr)); } else if (obj->encoding == OBJ_ENCODING_INT) { char buf[32]; size_t len = ll2string(buf,sizeof(buf),(long)obj->ptr); if (_addReplyToBuffer(c,buf,len) != C_OK) _addReplyProtoToList(c,buf,len); } else { serverPanic("Wrong obj->encoding in addReply()"); }}先将数据输出到到客户端缓冲区,在下一轮事件循环时再统一返回到客户端,具体处理方法在 handleClientsWithPendingWrites。
// networking.c#handleClientsWithPendingWriteint handleClientsWithPendingWrites(void) { ... listRewind(server.clients_pending_write,&li); while((ln = listNext(&li))) { client *c = listNodeValue(ln); ... // 1. 尝试写回客户端 if (writeToClient(c->fd,c,0) == C_ERR) continue; // 2. 如果数据没处理完,通过向内核注册可写事件,下一次主循环进行处理 if (clientHasPendingReplies(c)) { ... // 注册可写事件 if (aeCreateFileEvent(server.el, c->fd, ae_flags, sendReplyToClient, c) == AE_ERR) { freeClientAsync(c); } } } return processed;}三、时间事件
redis 服务器内部有很多定时任务需要执行,比如定时清除超时客户端连接,定时删除过期键等,定时任务被封装为时间事件 aeTimeEvent 对象,多个时间事件形成链表,存储在aeEventLoop 结构体的 timeEventHead 字段,它指向链表首节点。
我们通过一张图来看看,时间事件做了什么:
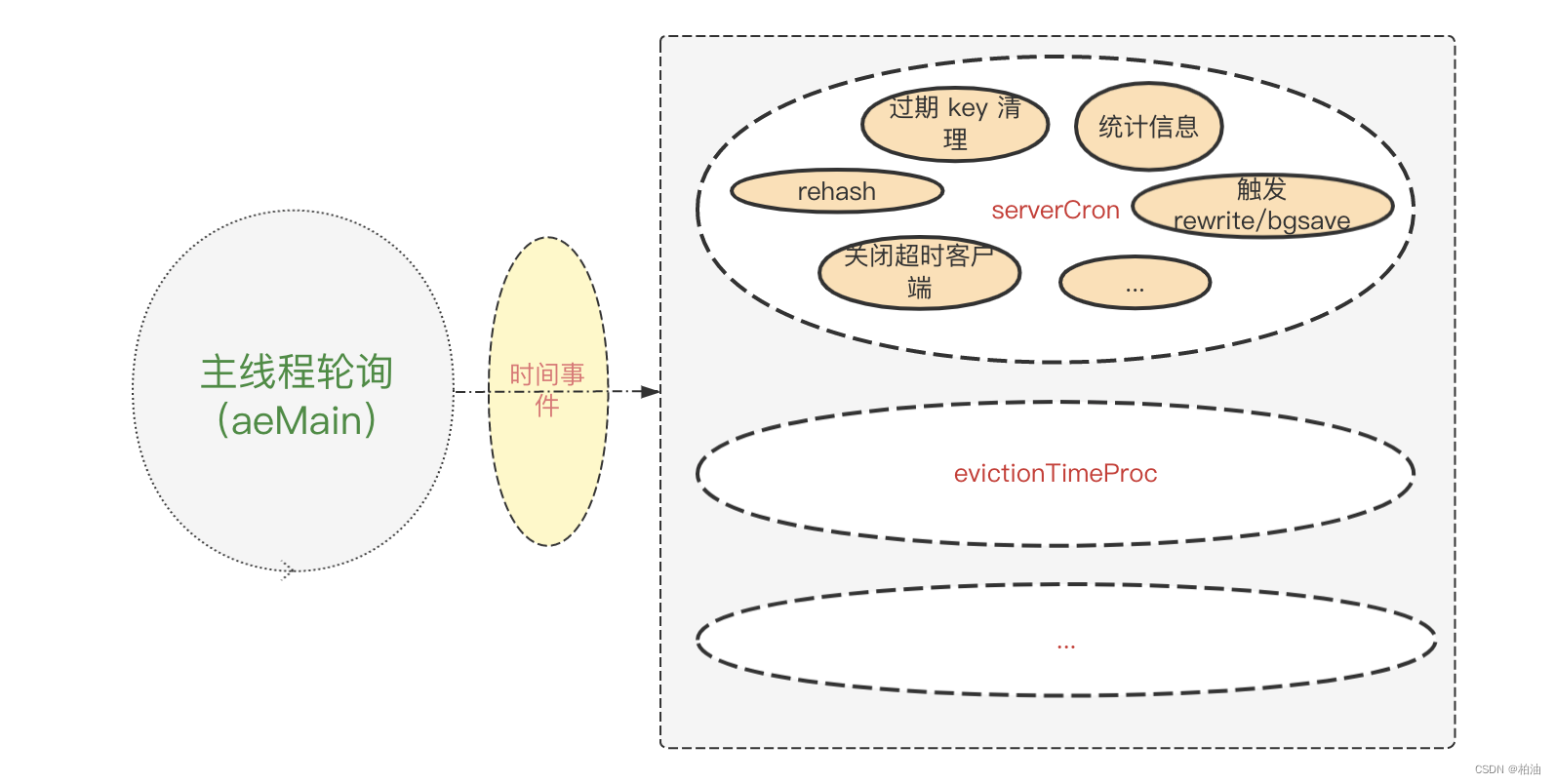
1、起源:
1.1 结构
typedef struct aeTimeEvent { long long id; /* time event identifier. */ long when_sec; /* seconds */ long when_ms; /* milliseconds */ aeTimeProc *timeProc; aeEventFinalizerProc *finalizerProc; void *clientData; struct aeTimeEvent *prev; struct aeTimeEvent *next;} aeTimeEvent;各字段含义如下。
- id:时间事件唯一 ID,通过字段 eventLoop->timeEventNextId 实现;
- when_sec 与 when_ms:时间事件触发的秒数与毫秒数;
- timeProc:函数指针,指向时间事件处理函数;
- finalizerProc:函数指针,删除时间事件节点之前会调用此函数;
- clientData:指向对应的客户端对象;
- next:指向下一个时间事件节点。
1.2 主流程
时间事件执行函数 processTimeEvents 的处理逻辑比较简单,只是遍历时间事件链表,判断当前时间事件是否已经到期,如果到期则执行时间事件处理函数 timeProc:
// ae.c#processTimeEventsstatic int processTimeEvents(aeEventLoop *eventLoop) { int processed = 0; aeTimeEvent *te; long long maxId; te = eventLoop->timeEventHead; maxId = eventLoop->timeEventNextId-1; monotime now = getMonotonicUs(); while(te) { long long id; // 如果时间事件已被删除,直接从事件链表中删除即可 if (te->id == AE_DELETED_EVENT_ID) { ... } // 如果在当前轮次时间事件处理过程中产生新的时间事件,就留到下一个轮次在进行处理。 if (te->id > maxId) { te = te->next; continue; } // 如果指定的执行时间到了,就执行;反之,跳到下一个事件判断 if (te->when <= now) { int retval; id = te->id; te->refcount++; // 核心逻辑,执行事件(具体timeProc由调用方指定) retval = te->timeProc(eventLoop, id, te->clientData); te->refcount--; processed++; now = getMonotonicUs(); if (retval != AE_NOMORE) { te->when = now + retval * 1000; } else { te->id = AE_DELETED_EVENT_ID; } } te = te->next; } return processed;}我们看到,te->timeProc(eventLoop, id, te->clientData) 这行代码是真正执行时间事件的逻辑,由调用方指定具体的处理逻辑。
前面说过,主线程是围绕事件展开的,并对事件做了一层封装(事件的增删查等操作),先来看看创建时间事件:
// ae.c#aeCreateTimeEventlong long aeCreateTimeEvent(aeEventLoop *eventLoop, long long milliseconds, aeTimeProc *proc, void *clientData, aeEventFinalizerProc *finalizerProc){ long long id = eventLoop->timeEventNextId++; aeTimeEvent *te; te = zmalloc(sizeof(*te)); if (te == NULL) return AE_ERR; te->id = id; te->when = getMonotonicUs() + milliseconds * 1000; te->timeProc = proc; te->finalizerProc = finalizerProc; te->clientData = clientData; te->prev = NULL; te->next = eventLoop->timeEventHead; te->refcount = 0; if (te->next) te->next->prev = te; eventLoop->timeEventHead = te; return id;}可以看到,新增的时间事件直接维护在 aeEventLoop 结构的时间事件链表头部;我们从新增事件入手,往上找,发现有这几处通过 aeCreateTimeEvent 创建时间事件,并指定如 serverCron、evictionTimeProc 这样的事件处理函数:
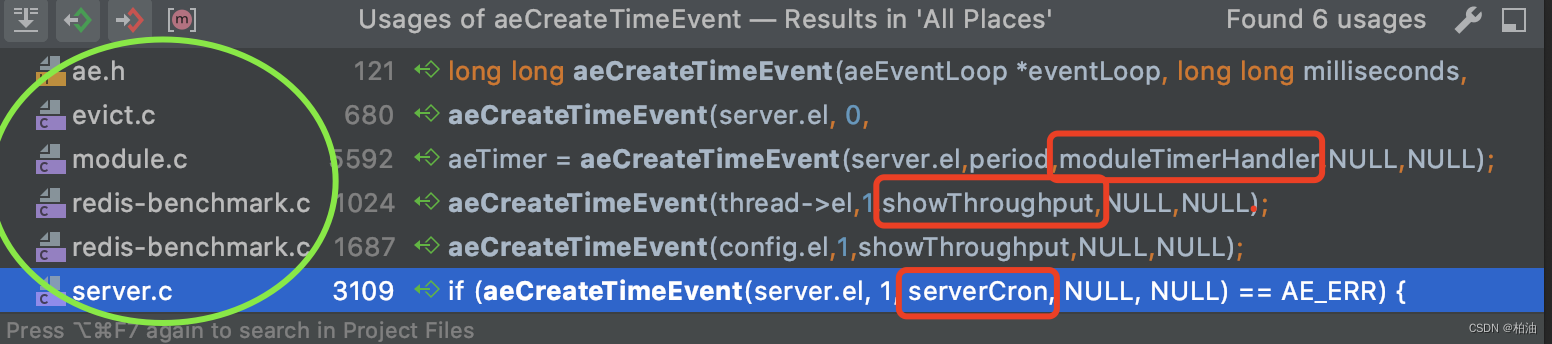
其中,serverCron 是我们待会主要介绍的函数。
先说结论,时间事件目前主要有以下两大类:
- 定期型周期任务
- 内存驱逐(淘汰)策略
其中定期型的周期任务(serverCron)又分为 定时处理(处理一次)和周期处理两类,并根据返回值来区分,源码中如下:
// ae.c#processTimeEventsstatic int processTimeEvents(aeEventLoop *eventLoop) { ... retval = te->timeProc(eventLoop, id, te->clientData); te->refcount--; processed++; now = getMonotonicUs(); // #define AE_NOMORE -1 if (retval != AE_NOMORE) { te->when = now + retval * 1000; } else { te->id = AE_DELETED_EVENT_ID; } ...} 如果时间处理函数返回值 retval != -1 表示周期性任务,并指定下一次执行时间;反之直接从时间事件列表中删除即可。
2、serverCron 周期性执行?
周期性处理函数,每秒执行频率由全局参数 server.hz 控制,主要做了以下几件事情:
- 处理过期 key (查询时惰性处理)
- 看门狗
- 更新部分统计信息
- 对 DB 字典进行 rehash
- 触发BGSAVE / AOF重写,并处理终止的子进程
- 不同类型的客户端超时。
- 副本重连接
- …
其中,我们挑选几个常见的处理来看看:
1.1 databasesCron
void databasesCron(void) { // 1. 随机抽样淘汰已过期的键 if (server.active_expire_enabled) { if (iAmMaster()) { activeExpireCycle(ACTIVE_EXPIRE_CYCLE_SLOW); } else { expireSlaveKeys(); } } // 2. 整理磁盘碎片(目前还未实现) activeDefragCycle(); // 3. 在进行 rehash 前先检查是否有子进程在活动(RDB、AOF),避免同时大量 copy-on-write 使内存紧张。 if (!hasActiveChildProcess()) { ... /* 3.1 Resize */ // 这一步其实是尝试对db字典进行缩容,条件是 used_size / total_size <= 10% // 值得注意的是,这一步只是打开渐进式 rehash 标识,并未开始真正元素迁移。 for (j = 0; j < dbs_per_call; j++) { tryResizeHashTables(resize_db % server.dbnum); resize_db++; } /* 3.2 Rehash */ // 渐进式 rehash // 如果渐进式 rehash 标识已经打开,开始真正元素迁移。 if (server.activerehashing) { for (j = 0; j < dbs_per_call; j++) { int work_done = incrementallyRehash(rehash_db); if (work_done) { break; } else { // 该 db 不需要 rehash,则进行下一个 rehash_db++; rehash_db %= server.dbnum; } } } }}这里的主要操作时针对 DB 的后台操作,比如 key 过期清理、磁盘碎片整理 、字典 resize / rehash。
到这一步,你就应该清楚了,key 过期清理以及渐进式 rehash 等操作,即使是后台定期检测并清理也是由主线程(和命令处理同一个线程)来完成。
换句话说,对内存中数据的直接操作,从始至终都是由主线程完成,不会存在多线程并发问题。
1.2 clientsCron
void clientsCron(void) { int numclients = listLength(server.clients); int iterations = numclients/server.hz; mstime_t now = mstime(); // iterations 控制每次(周期)处理客户端的数量 if (iterations < CLIENTS_CRON_MIN_ITERATIONS) iterations = (numclients < CLIENTS_CRON_MIN_ITERATIONS) ?numclients : CLIENTS_CRON_MIN_ITERATIONS; while(listLength(server.clients) && iterations--) { client *c; listNode *head; // 将尾部元素挪到首位(当要移除该元素时可直接移除首位元素,避免O(N)的遍历 ) listRotateTailToHead(server.clients); head = listFirst(server.clients); c = listNodeValue(head); // 超时处理 if (clientsCronHandleTimeout(c,now)) continue; // query_buffer 处理 if (clientsCronResizeQueryBuffer(c)) continue; // 统计 - 最近时间消耗最高的客户端信息 if (clientsCronTrackExpansiveClients(c)) continue; // 统计 - 内存使用信息 if (clientsCronTrackClientsMemUsage(c)) continue; }}主要处理 超时客户端断开连接、释放客户端 query_buffer、更新统计信息(INFO 命令)等。
1.3 触发 AOF 重写
// server.c#serverCronint serverCron(struct aeEventLoop *eventLoop, long long id, void *clientData) { ... if (!hasActiveChildProcess() && server.aof_rewrite_scheduled) { rewriteAppendOnlyFileBackground(); } ... }在周期性任务中执行 AOF rewrite 是一种 scheduled 属性的操作,关键参数 aof_rewrite_scheduled 。
比如,当用户提交 bgrewrite 命令时,发现此时有子进程正在执行中,为避免同时处理,此时会将 bgrewrite 提交到周期性任务中执行,即修改 aof_rewrite_scheduled = 1。
当主线程下一次轮询到处理时间事件时,触发 bgrewrite 执行。
1.4 触发 RDB 执行
// server.c#serverCronint serverCron(struct aeEventLoop *eventLoop, long long id, void *clientData) { ... if (!hasActiveChildProcess() && server.rdb_bgsave_scheduled && (server.unixtime-server.lastbgsave_try > CONFIG_BGSAVE_RETRY_DELAY || server.lastbgsave_status == C_OK)) { rdbSaveInfo rsi, *rsiptr; rsiptr = rdbPopulateSaveInfo(&rsi); if (rdbSaveBackground(server.rdb_filename,rsiptr) == C_OK) server.rdb_bgsave_scheduled = 0; } ... }在周期性任务中触发 bgsave 也是一种候补操作。当用户提交 bgsave 命令时,如果有子进程在执行操作,将暂时不处理;而是将 bgsave 操作 schedule 到周期性任务中,等待主线程下一轮执行时触发。
其实,这里和上面触发 AOF 重写原理类似。
1.5 stopThreadedIOIfNeeded
int stopThreadedIOIfNeeded(void) { int pending = listLength(server.clients_pending_write); /* Return ASAP if IO threads are disabled (single threaded mode). */ if (server.io_threads_num == 1) return 1; if (pending < (server.io_threads_num*2)) { if (server.io_threads_active) stopThreadedIO(); return 1; } else { return 0; }}stopThreadedIOIfNeeded 其实是服务于 redis 6.0 中出现的多线程的。redis6.0 中的多线程主要是处理请求的IO 读/写,默认情况下只处理写操作。
我们知道,多线程是有昂贵的上下文切换开销,所以,当待回写客户端数量较少的情况下,所有客户端的读写操作由主IO线程 全权负责即可,让剩下的线程暂时进入休眠状态。
3、内存驱逐策略?
该时间事件用于处理 LRU 涉及的内存驱逐(淘汰)相关操作,一般在 redis 使用内存达到最大限制之后才会进行处理。事件创建时指定的处理方法是 evict.c#evictionTimeProc。
当 redis 内存使用量达到我们设定的最大值 maxmemory 时,会触发内存驱逐(淘汰)机制,其执行入口为 evict.c#performEvictions,在每个命令执行后都会调用该方法判断是否需要执行内存驱逐策略。
你可能会问,既然每次命令执行后都要尝试调该方法进行处理,那为何还需要通过时间事件来处理?
// evict.c#performEvictionsint performEvictions(void) { ... while (mem_freed < (long long)mem_tofree) { ... // 删除选定的 keys if (bestkey) { ... keys_freed++; if (keys_freed % 16 == 0) { ... // 限制单次处理时长,避免长时间在此阻塞 if (elapsedUs(evictionTimer) > eviction_time_limit_us) { if (!isEvictionProcRunning) { isEvictionProcRunning = 1; // 如果达到了单次处理时间限制,就创建时间事件,主线程下一次轮询时处理。 aeCreateTimeEvent(server.el, 0, evictionTimeProc, NULL, NULL); } break; } } } else { goto cant_free; /* nothing to free... */ } } /* at this point, the memory is OK, or we have reached the time limit */ result = (isEvictionProcRunning) ? EVICT_RUNNING : EVICT_OK; ... return result;}从源码中可以看到,为避免长时间阻塞在一个操作上,redis 一般都会设置时间或者字数限制;
这里通过时间限制,如果达到该限制,就创建时间事件,然后退出该次处理。当主线程下一轮到来时触发该操作。
总结
由于之前系列文章大部分都围绕 文件事件 内容展开,因此,本文的重心放在了 时间事件 上。
你可能会好奇,类似于周期性这样的任务居然不是另外开启新线程来处理,仍然交给了主线程。
接着,你会发现,假如我想定期 100ms 执行一次周期任务,这个精准度其实没有那么高;比如,前面执行命令时阻塞了,就会影响后面周期任务的处理时间点等等。
另外, 你可能也注意到了,时间事件是以链表的形式串起来的,每次从头节点插入,每个时间处理时间点并没有顺序,所以,需要每次遍历所有事件。低效吗?
当然,并不低效。因为,到目前为止,总共只有两三个时间事件,如 serverCron、evictionTimeProc 等等。也许后期的迭代中,事件多了,结构可能会变化。
上文中,我将文件事件称之为主事件,时间事件为辅事件,主事件负责对外提供能力,辅事件负责对内自身状况进行调整。
参考文献:
- Redis事件驱动框架(上):何时使用select、poll、epoll?
- 高性能网络编程之 Reactor 网络模型
- 一文搞懂,redis单线程执行全貌
- <> 「陈雷」
- <> 「黄健宏」

