记一次生产事故排查——CPU高负载原因排查分析
文章目录
- 1. 背景描述
- 2. 排查过程
- 3. 总结
- 4. 代码附录
最近线上一个在线服务发现请求特别慢,接口经常出现超时问题,需要排查定位接口慢的原因。通过对现场和代码进行模拟(毕竟公司代码不太好放上来)总结一下此次排查给经验,尽可能为大家排查线上问题提供一些帮助。
1. 背景描述
大半夜运维打电话反馈请求到服务端接口非常缓慢,并且出现超时、报500现象,严重影响客户使用,需要排查问题原因。
 稳住不方,首先看到这样的问题直接去排查 CPU 和内存的情况。线上服务器为16核、64G配置机器,查看内存还有目前仅占用 2.4% ,内存正常。
稳住不方,首先看到这样的问题直接去排查 CPU 和内存的情况。线上服务器为16核、64G配置机器,查看内存还有目前仅占用 2.4% ,内存正常。
按理说三台这样配置机器的应该是能够满足当前业务需求的,然后通过 top 命令查看 CPU 负载情况,看了之后直呼好家伙,负载 load 均维持在 20 多,并且单 CPU 使用都到了 80%、90%。根据进程号查看哪一个 java 进程出现负载过高的情况,仔细一问才知道有个客户搞活动,客户端在疯狂请求接口导致 CPU 直接打满。
2. 排查过程
好了,目前初步定为了问题原因——CPU 负载太高导致接口相应变慢,接下来就是要去定位具体是什么原因导致 CPU 负载高。
2.1 定位负载过高的进程
通过 top 命令我们可以看到负载高的进程对应的进程号,如下图所示,可以看到该进程是一个 java 进程。
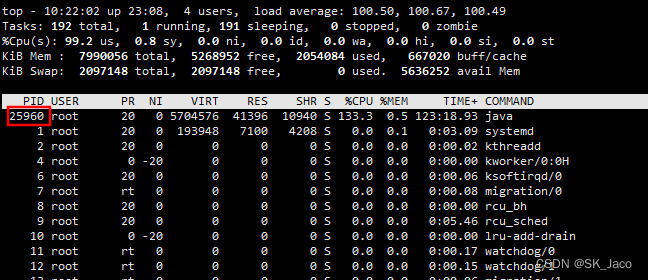
通过 jps 指令可以查看具体是哪个服务,可以看到出现问题确实为我们模拟出来的这个程序进程,虽然我们能够从接口判断出来是哪个服务导致,但是如果一个环境中部署了多个服务,并且服务存在一定的调用,那么这样查看进程号对应服务名的这一步还是很有必要的。

2.2 进程内运行分析
获取进程中各线程的 CPU 使用情况
首先排查进程内各线程的 CPU 使用情况,命令如下:
ps -mp PID -o THREAD,tid,time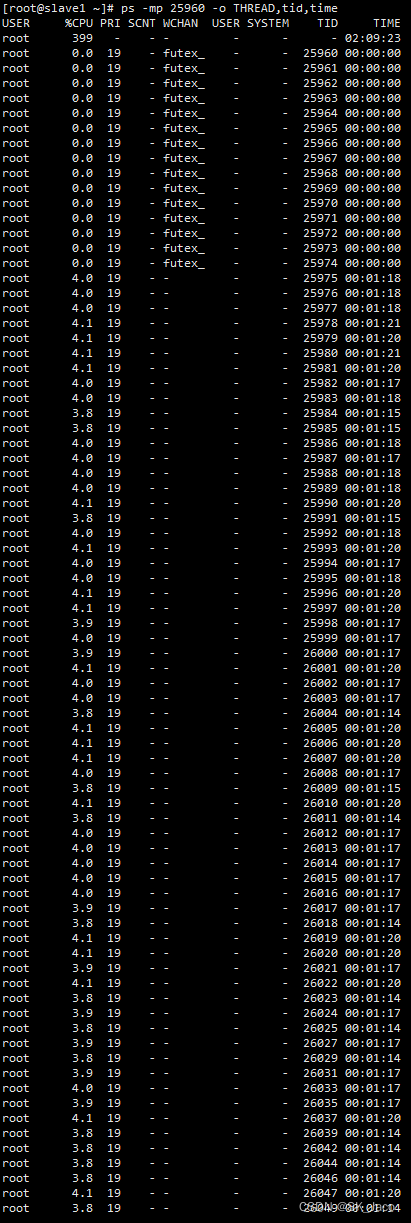
命令参数说明:
-m:在进程后面显示线程
-p:后面需要跟上进程号列表,通过进程号进行选择。使用 -mp 即筛选出指定的进程号中的线程列表
-o:自定义格式化
线程号处理
我们找到 CPU 占用比较高的一个线程,如 24960 这个线程,由于系统中的线程栈使用 16 进制进行记录,因此我们需要将 10 进制的线程号转换为 16 进制的,为下一步排查做准备。这里可以使用计算器,也可以直接使用 linux 指令打印出 25978 转换为 16 进制的结果为 657a。
printf "%x\n" 25978
排查进程堆栈信息
通过 jstack 命令可以打印整个进程的线程堆栈信息,在堆栈信息中查找上一步处理的线程号。从日志中可以看到是 RunningMethod.run() 最后执行在这个方法上的 14 行,正好是示例代码中死循环部分。排查其他线程也同样是在这一步阻塞住。一个不够可以多选几个线程进行对比。
jstack 25960|grep 657a -A 10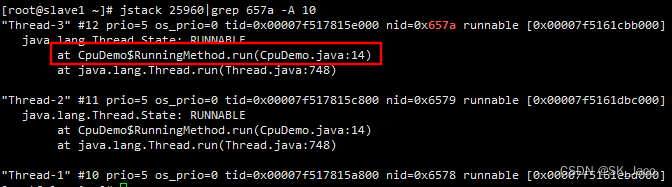
更进一步排查方法执行耗时
使用 Arthas 进行排查( Arthas 排查线上问题真的好用),通过 trace 命令追踪该方法执行耗时。
trace class-pattern method-pattern由于测试代码为了模拟使用的死循环,显示 trace 结果效果不太好。在生产环境我们可以根据上一步定位到的类及方法,通过 trace 命令查看该方法调用链中所需耗时。
以官方的 math-game 为例,当我们跟踪 MathGame 的 run 方法时,将打印出该方法的调用链路及每个方法的执行时间,如下图所示:
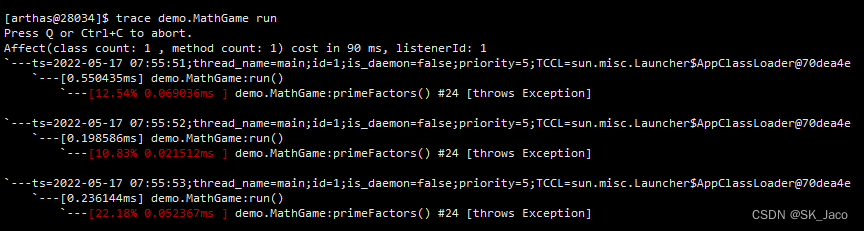
生产环境中执行结果类似,能够根据打印结果定位到具体耗时的方法位置。今后会专门写 Arthas 排查相关博客进行总结。
得出结论
根据以上排查流程结果能够定位到耗时方法、以及执行效率。这次生产事故是由于在解析模板参数时将全量模板及对应参数进行解析导致的,每一次请求均会单独做一次解析,而解析过程又是非常占用资源并耗时的。由于以前并发量不高所以一直没有暴露出问题,这次客户一搞活动就出现了生产事故,由此看出开发这一块的同事并未考虑到并发性能这一块。

2.3 解决方案
紧急方案:
- 修改 JVM 参数,并增加机器临时应急,这也只是紧急处理方法,熬过当晚活动
短期方案:
- 添加缓存。由于存在大量重复模板解析因此对解析完成后的模板进行缓存,防止重复操作减轻 CPU 压力
- 模板瘦身。以前直接一股脑的将全量数据进行解析,因此需要对模板进行瘦身,只解析需要解析的部分,不需要解析的部分不再操作直接替换即可
长期方案:
- 重构模板解析方法,以前的方法臃肿且不易扩展,需要选用轻量级的解析方案以应对将来的大量请求场景
3. 总结
这次线上事故原因最终还是被定位到了(程序运行导致 CPU 负载过高),定位过程也是比较常规的 CPU 负载过高的排查过程。从问题排查出也暴露出以下几个问题:
- 开发代码时不仅要实现功能,还需要考虑性能问题
- 开发完成做好自测以及压力测试
- 遇到生产问题不能慌,一步步排查总能够找到原因
文章中仅使用了死循环进行模拟,因此并不能够完整的模拟出事故现场,但是整体思路不变,整个流程应用于线上问题定位效果更佳。
4. 代码附录
1import java.util.concurrent.TimeUnit;23public class CpuDemo {4 public static void main(String[] args) {5 System.out.println("CPU high load start.");6 for (int i = 0; i < 100; i++) {7 new Thread(new RunningMethod()).start();8 }9 }1011 public static class RunningMethod implements Runnable {12 public void run() {1314 while(true) {15 }16 }17 }1819}
