C++内存模型简述
目录
一、什么是内存模型
二、内存的分类
三、各分区例程
1、 全局/静态存储区
2、 常量区
3、栈(Stack)区域
4、 堆(Heap)区域
四、堆和栈的区别
五、堆和自由存储区的区别
1、 malloc/free和new/delete的区别
2、 C++中new/delete的工作过程
一、什么是内存模型
内存模型就是一种语言它独特的管理者一套程序的机制,像C语言会将内存区域划分成堆、栈、静态全局变量区、常量区;而C++则分为堆、栈、自由存储区、全局/静态变量区、常量存储区;划分的目的是为了能够方便编译器的管理和运行。再比如Java和Python都有自己的一套虚拟内存管理机制和垃圾回收机制。这些操作无疑是为了方便程序员的日常开发,减少程序员对内存太多的操作。
二、内存的分类
| 分类标准 | 分区数量 |
| 两大分区 | 代码区、数据区 |
| 四大分区 | 代码区、全局区(全局/静态存储区)、栈区、堆区 |
| c语言分区 | 堆、栈、静态全局变量区、常量区 |
| c++语言分区 | 堆、栈、自由存储区、全局/静态变量区、常量存储区 |
| 内存模型根据生命周期的不同分区 | 自由存储区、动态区、静态区 |
我们就按照C++语言的内存划分区域来讲解内存管理机制
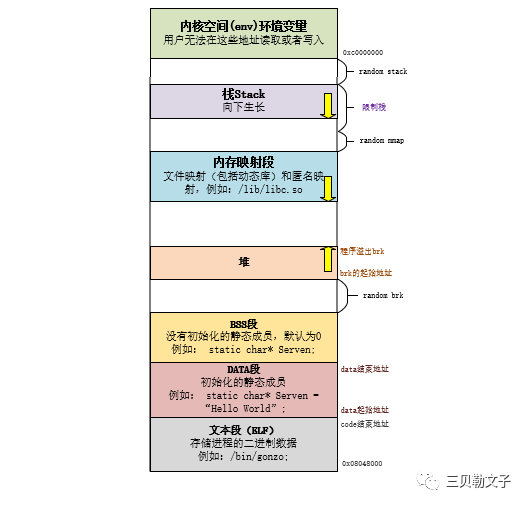
文本段(ELF):主要用于存放我们编写的代码,但是不是按照代码文本的形式存放,而是将代码文本编译成二进制代码,存放的是二进制代码,在编译时就已经确定这个区域存放的内容是什么了,并且这个区域是只读区域;
DATA段:这个区域主要用于存放编译阶段(非运行阶段时)就能确定的数据,也就是初始化的静态变量、全局变量和常量,这个区域是可读可写的。这也就是我们通常说的静态存储区;
BSS段:这个区域存放的是未曾初始化的静态变量、全局变量,但是不会存放常量,因为常量在定义的时候就一定会赋值了。未初始化的全局变量和静态变量,编译器在编译阶段都会将其默认为0;
HEAP(堆):这个区域实在运行时使用的,主要是用来存放程序员分配和释放内存,程序结束时操作系统会对其进行回收,(程序员分配内存像malloc、free、new、delete)都是在这个区域进行的;
STACK(栈):存放函数的参数值和局部变量,这个区域的数据是由编译器来自己分配和释放的,只要执行完这个函数,那么这些参数值和变量都会被释放掉;
内核空间(env)环境变量:这个区域是系统内部的区域,我们是不可编辑的;
三、各分区例程
1、 全局/静态存储区
这个区域有两个段,分别是BSS段和DATA段,均存放着全局变量和静态变量(包括全局静态变量和局部静态变量),其中BSS存放的是程序员编写的未初始化的全局变量和静态变量(这其中C和C++的BSS还有区别,区别就是:C中的BSS段分为高地址和低地址,高地址是存放全局变量,低地址是存放静态未初始化);而DATA存放已经初始化的全局变量、静态变量和常量。
#include #includeusing namespace std;/*定义全局变量*/int serven_1; // 定义未初始化的全局变量static int serven_3; // 定义未初始化的静态变量int serven_2 = 2; // 定义初始化的全局变量static int serven_4 = 4; // 定义初始化的静态变量int main(int argc, char *argv[]){ QCoreApplication a(argc, argv); cout<<"BSS:"<<endl; cout<<"The address of serven_1:"<<&serven_1<<", The data of serven_1:"<<serven_1<<endl; cout<<"The address of serven_3:"<<&serven_3<<", The data of serven_3:"<<serven_3<<endl; cout<<"DATA:"<<endl; cout<<"The address of serven_2:"<<&serven_2<<", The data of serven_2:"<<serven_2<<endl; cout<<"The address of serven_4:"<<&serven_4<<", The data of serven_4:"<<serven_4<<endl; return a.exec();}运行结果:

代码分析:
程序定义了两个全局变量serven_1和serven_2,两个静态变量serven_3和serven_4,其中serven_2和serven_4是初始化的,所以serven_1和serven_3是存放在BSS段,并且编译器会将这两个未初始化的变量默认初始化为0;而serven_2和serven_4这两个变量是初始化的,存放在DATA段。
2、 常量区
上面说到常量是存放在DATA段区域的,下面我们来看一下例子:
#include #includeusing namespace std;/*定义全局变量*/int serven_1; // 定义未初始化的全局变量static int serven_3; // 定义未初始化的静态变量int serven_2 = 2; // 定义初始化的全局变量static int serven_4 = 4; // 定义初始化的静态变量/*定于全局常量*///const char *serven_5 = "serven";const char* serven_5 ="serven";int main(int argc, char *argv[]){ QCoreApplication a(argc, argv); const char* serven_6 ="serven"; char * serven_7 = "serven"; char * serven_8 = serven_7; char s[]="serven"; char s2[]="serven"; s[1]='1'; *s='1'; cout<<"The address of serven_5:"<<&serven_5<<", The data of serven_5:"<<serven_5<<endl; cout<<"The address of serven_6:"<<&serven_6<<", The data of serven_6:"<<serven_6<<endl; cout<<"The address of serven_7:"<<&serven_7<<", The data of serven_7:"<<serven_7<<endl; cout<<"The address of serven_8:"<<&serven_8<<", The data of serven_8:"<<serven_8<<endl; cout<<"The address of s:"<<s<<", The data of s:"<<s<<endl; cout<<"The address of s2:"<<s2<<", The data of s2:"<<s2<<endl; printf("The Pointer of serven_5 :%p\n",serven_5); printf("The Pointer of serven_6 :%p\n",serven_6); printf("The Pointer of serven_7 :%p\n",serven_7); printf("The Pointer of serven_8 :%p\n",serven_8); printf("The Pointer of s :%p\n",s); printf("The Pointer of s2 :%p\n",s2); return a.exec();}
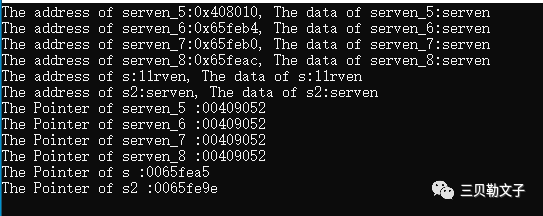
代码分析:
变量serven_5是常量,存储在DATA段区域,serven_6是局部的常量、serven_7和serven_8是局部的变量指针,他们都是指向一个常量“serven”,这个常量存储在常量区的,也就是存储在DATA区域,可以看到在后面打印serven_5~serven_8的时候的地址都是一样的,都是存储在DATA区域。而s和s2是局部变量,存储在栈区域,可以看到代码中打印出来的指针都是在栈区域里面。总结就是:s和s2是定义在局部函数里面的变量,所以存放在栈区域,serven_6~serven_8是定义在局部里面的指针,指向的是常量,所以指向的常量存放在DATA区域,而指针本身存放在栈。
3、栈(Stack)区域
栈区域是编译器自动根据变量进行分配的,不是由程序员进行开辟的,所以编译器即会自动分配也会将其释放,这个区域主要存放函数的参数值、局部变量、形参等等。
#include #includeusing namespace std;void TEST(int ser_x, int ser_y, int ser_z){ int serven_9 = 9; int serven_10 = 10; int serven_11 = 11; printf("The Pointer of ser_x is: %p\n",&ser_x); printf("The Pointer of ser_y is: %p\n",&ser_y); printf("The Pointer of ser_z is: %p\n",&ser_z); printf("The Pointer of serven_9(TEST) is: %p\n",&serven_9); printf("The Pointer of serven_10(TEST) is: %p\n",&serven_10); printf("The Pointer of serven_11(TEST) is: %p\n",&serven_11);}int main(int argc, char *argv[]){ QCoreApplication a(argc, argv); int serven_9 = 9; int serven_10 = 10; int serven_11 = 11; int serven_12 = 12; int serven_13 = 13; printf("The Pointer of serven_9(MAIN) is: %p\n",&serven_9); printf("The Pointer of serven_10(MAIN) is: %p\n",&serven_10); printf("The Pointer of serven_11(MAIN) is: %p\n",&serven_11); TEST(serven_11, serven_12,serven_13); printf("The Pointer of serven_13 is: %p\n",&serven_13); return a.exec();}运行结果:
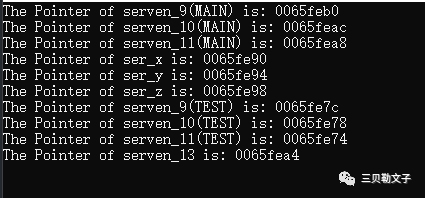
程序分析:
首先我们先来看一下这个图,是内存管理机制里面的栈,可以看到main函数中定义的变量serven_9 ~ serven_13分别入栈,而且入栈的顺序是从高地址到低地址,每个变量占用4个字节,所以地址相差也就是4个字节。然后就是形参入栈,形参入栈顺序是从右往左入栈,所以ser_z~ser_x的地址也是依次递减的,最后就是TEST函数里面的局部变量,将局部变量serven_9 ~ serven_11依次入栈,并且地址也是一次递减。而且可以看到serven_13的地址和serven_11是隔壁,由此可以看出,栈的先进后出,也就是调用完函数TEST后会把局部变量serven_11(TEST)~serven_9(TEST)、serv_x~ser_z全部出栈,然后再将serven_13入栈。
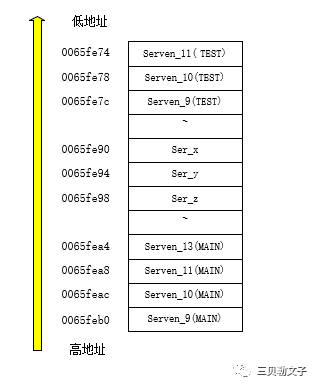
但是,我们可以发现了定义serven_11之后的调用函数,函数的形参入栈的地址与serven_11定义时的地址相差很远,大概有三个字节,这三个字节中有一个是serven_11,那么多出来两个字节是什么呢?这是因为在调用函数的时候会进行一些操作:
首先我们需要了解几个概念:栈帧、寄存器esp、寄存器ebp
| 栈帧 | 每个函数有自己的栈帧,栈帧中维持着所需要的各种信息(包括参数、返回地址、参数个数、其它) |
| 寄存器esp | 保存当前栈帧的栈顶 |
| 寄存器ebp | 保存当前栈帧的栈底 |
那么函数在栈入参时候的结构为:
函数的局部变量:(ebp)最右参数->中间参数->最左参数->返回地址->运行时参数(esp);
例如:
#include #includeusing namespace std;void TEST(int ser_x, int ser_y){ int serven_14 = 14; int serven_15 = 15; printf("The Pointer of ser_x(TEST):%p\n",&ser_x); printf("The Pointer of ser_y(TEST):%p\n",&ser_y); printf("The Pointer of serven_9(TEST):%p\n",&serven_14); printf("The Pointer of serven_9(TEST):%p\n",&serven_15);}int main(int argc, char *argv[]){ QCoreApplication a(argc, argv); int serven_14 = 14; int serven_15 = 15; TEST(serven_14,serven_15); return a.exec();}运行结果:
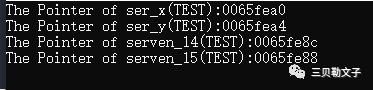
代码分析:
上面的代码在汇编里面呈现
(1)main函数中
push a;push b;call TEST;(2)TEST函数中
push ebp;mov esp ebp; // 保存现场,储存其他寄存器的值这时栈帧结构是:ser_y->ser_x->返回地址->ebp,esp;
我们要取参数需要进行ebp+4()返回地址,ebp+8等操作;
push a;mov a 1;push b;mov b 1;这时栈帧结构为:ser_y->ser_x->返回地址->ebp(serven_14)->esp(serven_15);
最后退出函数
ret 8;ret8 的意思时我们两个参数需要将寄存器偏移8个单位;我们需要将esp偏移,将ebp偏移清空内存,这样我们的函数就算调用完了。这里我们可以看到ebp和esp的作用:ebp 可以定位函数形参,定位返回地址,esp可以清空运行时内存。
-
这里有个问题,我们为什么要从右到左入参呢?
根据栈的特点,第一个形参将在固定的ebp+4的位置,很方便获取方便使用
-
为什么方便获取第一个参数就是好呢?
这就要说到C中的可变参数函数。在使用可变参数函数的时候必须有第一个参数,根据第一个参数可以定位可变参数的长度,设想一下如果不是从右向左入参,那么地日光参数无法获取,可变参数的长度将无法获取(读取文件可以解决),所以说向右入参可以兼容C语言中的一些设定。
4、 堆(Heap)区域
这个区域是由程序员来进行分配内存和释放内存用的,当我们使用malloc/free、new/delete(这是在自由存储区上分配和释放的,某种意义上来说呢,起始自由存储区是堆的一个子集)。
在这里要注意的是,我们申请了空间内存一定要释放,如果没有释放那就会导致内存的泄露,后果很严重!!!你遇到过的电脑蓝屏也许就是内存泄漏引起的。
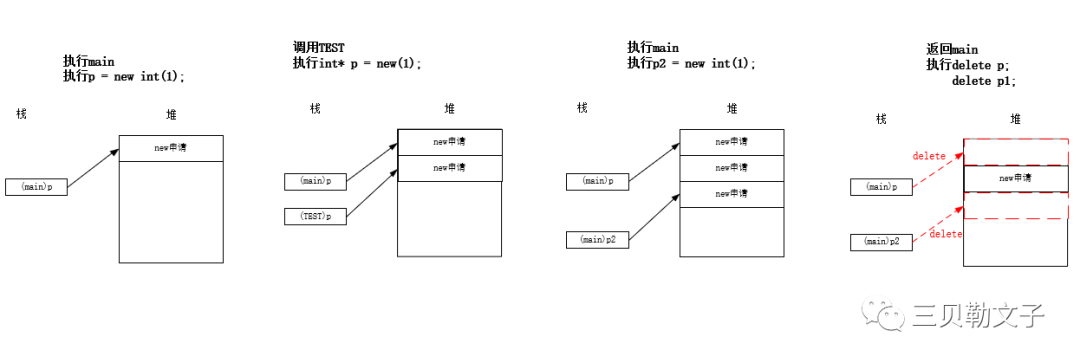
(1)测试在申请内存的顺序中没有出现释放的情况
#include #includeusing namespace std;void TEST(){ int *p = new int(1); printf("TEST p is %p\n", p); delete p;}int main(int argc, char *argv[]){ QCoreApplication a(argc, argv); int *p = new int(1); printf("main p is %p\n", p); int *p1 = new int(2); printf("main p1 is %p\n", p1); TEST(); delete p; delete p1; return a.exec();}运行结果:
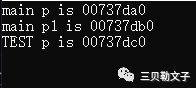
代码分析:
首先在main函数中new了一个p,然后在new了一个p1,最后在调用TEST函数,new了一个p。三个指针申请的内存区域均不一样。
分配和释放图示:
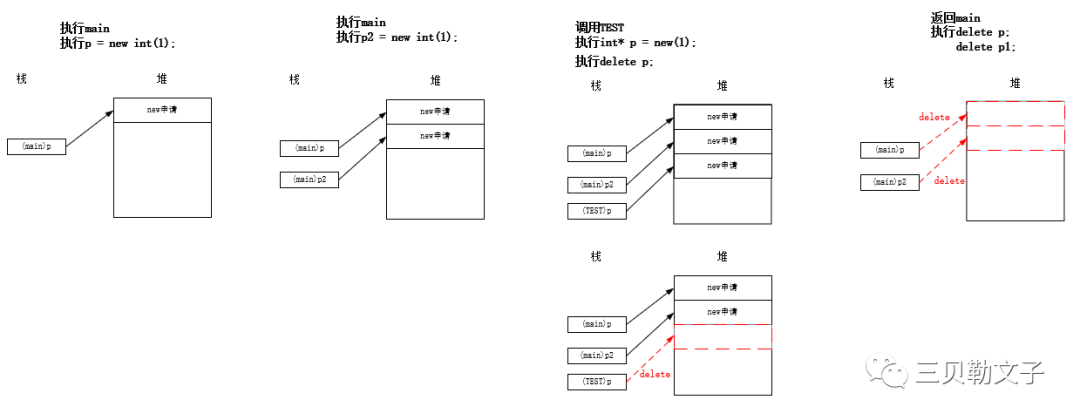
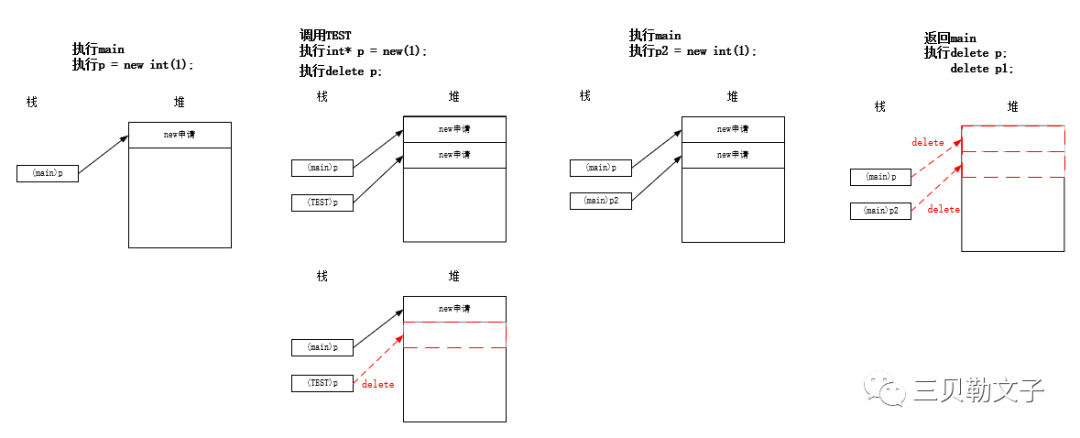
(2)测试在申请内存的顺序中有出现释放的情况
改变调用TEST顺序后:
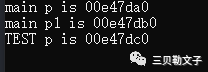
#include #includeusing namespace std;void TEST(){ int *p = new int(1); printf("TEST p is %p\n", p); delete p;}int main(int argc, char *argv[]){ QCoreApplication a(argc, argv); int *p = new int(1); printf("main p is %p\n", p); TEST(); int *p1 = new int(2); printf("main p1 is %p\n", p1); delete p; delete p1; return a.exec();}运行结果:
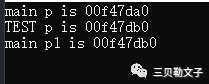
代码分析:
从结果看到了TEST里面的p和main中的p1是同一个地址,也就是首先main中定义了一个p,并且申请了四个字节的内存,然后返回地址为00f47da0,接下来就是调用TEST函数,在函数里面定义了一个指针p,然后申请了四个字节的内存,然后返回地址00f47db0,然后释放掉申请的这块区域,接下来就到了main函数中的p2指针,申请的区域可以在main中的p接下去的地址,也就是可以是在调用TEST函数中申请的那块内存区域,因为被释放掉了嘛,所以这个区域就恢复可以被申请。
分配和释放图示:
(3)测试在没有delete的情况
#include #includeusing namespace std;void TEST(){ int *p = new int(1); printf("TEST p is %p\n", p); //delete p;}int main(int argc, char *argv[]){ QCoreApplication a(argc, argv); int *p = new int(1); printf("main p is %p\n", p); int *p1 = new int(2); printf("main p1 is %p\n", p1); TEST(); delete p; delete p1; return a.exec();}运行结果:
代码分析:
这种结果和我们测试第一种情况一样,三个指针申请的内存空间均不一样。因为在调用用TEST函数后没有将TEST函数中的p指针释放掉,所以申请的那块区域还占着内存呢。而因为TEST是局部函数,调用完这个函数后指针(TEST)p就会被编译器释放掉,留着申请的那块内存区域在那里孤苦伶仃,也就是泄露了。
分配和释放图示:
四、堆和栈的区别
| 比较类别 | 堆 | 栈 |
| 管理方式 | 由程序员分配和释放 | 编译器自动管理 |
| 空间大小 | 最大可达4GB | 空间有限 |
| 产生碎片 | 会造成空间碎片 | 不会 |
| 生长方向 | 向上生长(低地址-高地址) | 向下生长(高地址-低地址) |
| 分配方式 | malloc、new、calloc、realloc | 编译器管理 |
| 分配效率 | 低 | 高 |
五、堆和自由存储区的区别
自由存储区其实上是一个逻辑概念
堆是物理概念。
1、 malloc/free和new/delete的区别
(1)new、delete是C++中的操作符,而malloc和free是标准库函数。操作符可以在类的内部重载,malloc/free不行,唯一的关联只是在默认情况下new/delete调用malloc/free
(2)malloc/free(只是分配内存,不能执行构造函数,不能执行析构函数),new/free。
(3)new返回的是指定类型的指针,并且可以自动计算所申请内存的大小。而 malloc需要我们计算申请内存的大小,并且在返回时强行转换为实际类型的指针。
2、 C++中new/delete的工作过程
申请的是普通的内置类型的空间:
(1)调用 C++标准库中 operator new函数,传入大小。(如果申请的是0byte则强制转化成1byte)
(2)申请相对应的空间,如果没有足够的空间或其他问题且没有定义_new_hanlder,那么会抛出bad_alloc的异常并结束程序,如果定义了_new_hanlder回调函数,那么会一直不停的调用这个函数直到问题被解决为止
(3)返回申请到的内存的首地址.
申请的是类空间:
(1)如果是申请的是0byte,强制转换为1byte
(2)申请相对应的空间,如果没有足够的空间或其他问题且没有定义_new_hanlder,那么会抛出bad_alloc的异常并结束程序
(3)如果定义了_new_hanlder回调函数,那么会一直不停的调用这个函数直到问题被解决为止。
(4)如果这个类没有定义任何构造函数,析构函数,且编译器没有合成,那么下面的步骤跟申请普通的内置类型是一样的。
(5)如果有构造函数或者析构函数,那么会调用一个库函数,具体什么库函数依编译器不同而不同,这个库函数会回调类的构造函数。
(6)如果在构造函数中发生异常,那么会释放刚刚申请的空间并返回异常
(7)返回申请到的内存的首地址
delete 与new相反,会先调用析构函数再去释放内存(delete 实际调用 operator delete)
operator new[]的形参是 sizeof(T)*N+4就是总大小加上一个4(用来保存个数);空间中前四个字节保存填充长度。然后执行N次operator new
operator delete[] 类似;
看在小编花了一整体整理了C++内存管理机制的份上,给个赞吧。
欢迎关注微信公众号“ 三贝勒文子 ”,每天学习C++哦

