研究生语音识别课程作业记录(一) 非特定人孤立词识别
研究生语音识别课程作业记录(一) 非特定人孤立词识别
- 前言
- 一. 任务要求
- 二. 识别方法
- 三. 语音数据库
- 四. 特征参数提取
- 五. 识别过程及分析
- 六. 小结
前言
研究生期间的语音识别课程作业记录,研一暑假的主要工作,也是自己正式入门语音识别的启程之路,虽然是采用传统方法进行语音识别的工程仿真,但对于一个新手菜鸟来说,这样的训练必不可少,借此机会记录一下,希望可以对刚入门语音识别的小白提供一点开拓的思路。
一. 任务要求
提供声音文件: 0-9的数字孤立词读音文件库,共28人录音样本,每人10次, 手工分割存档。
任务完成建议和要求:
1.数据是16KHz采样的, 一般需要降采样到8KHz后使用。(Matlab中有相应的命令), 如果直接使用16KHz的数据,应用MFCC时的子带数需要调整, 不能用缺省。
2.可以考虑选择12维MFCC+12维其差分共24维作为提取的特征。
3.可以考虑其他的特征, 例如LPC、LPCC、LSP等等,自己研究后决定。
4.训练及识别(一半的数据用于训练(训练集), 一半的数据用于识别(测试集)), 分别给出训练集和测试集的识别率. 特别提醒,任务的目标是非特定人的孤立词识别,因此,建议自己查一下中国期刊网, 研究一下中文期刊的文章,其他学者对非特定人的特征选择是如何优化的,可以借用别人的思路进行特征提取选择。
5.必须用VQ+DTW方法和自己任选一种识别方法(BP/RBF/GMM/DHMM/SVM/ADABOOST)实现识别任务。
6.用doc文档 描述所进行的一切步骤细节,包括预滤波,分帧加窗(海明窗),特征选择和识别机的参数选择过程(必须给出所有的相关细节参数), 给出实验结果(包括研究的中间过程结果即调整参数前后的实验结果,所有的实验结果需要贴图到doc文档中,不要贴程序),给出结论。 还有必须对实验结果及过程中出现的问题和给出的解决方案进行描述和讨论。
7.提交程序要求: 能够读出和所提供数据库完全一样格式的数据,并给出识别结果显示,包括每一个数字的识别率和最终的平均识别率。
8.将来用于评测所提交作业的数据库独立于目前提供的数据库。
二. 识别方法
DTW和DTW+VQ
三. 语音数据库
1,一个命名为0-9 digital C的文件夹里面digital文件中存有0-9九个子文件夹,分别存放0到9的数字的录音文件,其中每个子文件夹内有28个人x10个音=280个语音。总计280*10个数字=2800个语音。
2,所有语音统一为16K采样率,16位,单声道,coolEditor软件录制生成, 手工分割。每个人每个数字录取10段语音, 数据命名说明:ij.wav表示第i个人的第j个样本。
3,在本次试验中,取每个数字每个人的取五段语音(共1400段)作为训练集,另五段语音(共1400段)作为测试集,不同的识别方法对不同的训练集和测试集有着不一样的识别率,所以应根据识别率来给每种识别方法调整测试与训练的样本。
4,分别通过不同的识别方法对不同的函数中的参数进行调整,然后进行训练,测试,最终得出训练及测试的最佳识别率。
四. 特征参数提取
1,本文提取12维MFCC+12维其差分共24维作为提取的特征,首先让每段语音信号通过双门限端点检测函数(edgedetection)获得有效语音段,再通过分帧函数(enframe)得到语音帧数。
2,并对每一帧进行预加重,加窗(海明窗),fft,计算幅度谱的平方通过mel滤波器组每一个滤波器的加权输出和,取对数,再经DCT变换,得到12维的MFCC,然后计算12维其差分MFCC,合并组成24维MFCC。
3,本文未采取LPCC系数作为特征提取是因为:LPCC系数主要是模拟人的发声模型,不如MFCC,它未考虑人耳的听觉特性,进行平均分段, 它对元音有较好的描述能力,对辅音描述能力及抗噪性能比较差,其优点是计算量小,易于实现。
4,本文选择两种样本选择方法,两种分类方法分别适应不同的方法的最佳识别率:
a:训练集:每个数字每人的前五段语音;测试集:每个数字每人的后五段语音。
b: 训练集:每个数字每人的五段偶数序语音;测试集:每个数字每人的五段奇数序语音。
五. 识别过程及分析
(1)比较DTW和DTW+VQ方法
A,DTW
DTW是把时间规整和距离测度计算结合起来的一种非线性规整技术。它是基于动态规划的思想,解决发音长短不一的匹配问题。
1,首先对每一个数字通过双门限端点检测,截取有效语音段;再通过预加重,加窗(海明窗)分帧等,提取MFCC特征参数矩阵nx24维(melbankm函数),然后规整到特定帧数N;将训练集和测试集特征参数分别存为Train_m(1x1400)和Test_m(1x1400)。再通过DTW(动态时间规整)函数将Train_m训练成模板DTWTemplate(1x10)。计算训练集中每个样本与其他各个样本的距离之和,其中最小值所对应的样本的MFCC特征矩阵即为该数字的模板,这样就选取好了DTW的10个模板。
2,通过对训练集Train_m,测试集Test_m样本特征参数与模板DTWTemplate的匹配,得出了识别结果,并统计了识别时间,训练集与测试集不同,则识别率也就不同;通过调整匹配参数,显示最佳识别结果如下:


a:训练集:每个数字每人的前五段语音 测试集:每个数字每人的后五段语音


b: 训练集:每个数字每人的五段偶数序语音;测试集:每个数字每人的五段奇数序语音
3,参数调整:在实验中不同的样本需要调整不同的参数值才能达到较好的实验结果,本方法可调整的参数有:规整帧数N,对不同的N实验结果如下表:
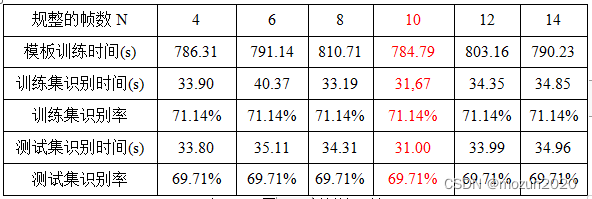
表一:不同规整帧数的识别率
如上表所示,在DTW中训练样本的选取方法不同则会影响识别率,规整后对训练集和测试集的识别率影响不大;但是对于模板训练时间,训练集识别时间,测试集识别时间却有很大影响。由实验结果可以看出,a分类时,训练和测试的识别率都比b分类要高,因此我们在单独运用DTW方法时选用a分类(前五后五)方法。
由表一结果可知,在N=10时耗时最小,耗时比其他数值都少1s以上,因此针对语音识别中的时效性问题,规整后的帧数选取N=10(在DTW+VQ中默认规整后的帧数N=10)。对非特定人的语音识别,DTW方法识别率不高,因此试采取加入VQ方法以提高识别率,实验如下。
B,DTW+VQ
VQ(矢量量化),就是把输入数据分组,成组地量化编码。矢量量化是一种限失真编码,其原理仍可用信息论中的率失真函数理论来分析。而率失真理论指出,即使对无记忆信源,矢量量化编码也总是优于标量量化。
1,在读取语音函数中,提取120*1400的特征参数矩阵VQTrain_m和VQTest_m(5x24=120,帧移xMFCC维数),再通过LBG算法对每一个数字训练出一个码书,得到CodeBooks(1x10),另外训练出VQ的模板VQTemplate(1x10)。
2,识别语音时,首先由每段语音的MFCC系数矩阵求出其VQ码书,求该样本码书与每一个数字码书的欧氏距离,取出距离最小的前三个,即对应该样本最有可能识别成这三个数字中的一个;然后取这三个数字的DTW模板,再对该样本进行DTW模板匹配,得出最终识别出的数字结果。最佳识别结果如下:


a:训练集:每个数字每人的前五段语音 测试集:每个数字每人的后五段语音


b:训练集:每个数字每人的五段偶数序语音 测试集:每个数字每人的五段奇数序语音
分析:在样本选取过程中,a分类方法对训练集的识别有优势,比b分类方法高两个多百分点;但对于测试集的识别,b分类明显比a分类有1.5个百分点的提高。因此两种样本分类方法各有优劣,在实际运用中应根据实际情况的具体要求选择相应的样本分类方法。
3,在运用LBG算法训练码书时,其中LBG算法中的参数L(最大迭代训练次数,大于此将结束迭代)及thr(畸变改进阈值,小于此将结束迭代)。通过控制变量,经过遍历训练,发现在L=120,thr=0.001时识别率明显高于其他参数值,但是多次训练发现所生成的码书仍不稳定,当高识别率的码书被更新后难以重新达到。经过查阅资料,发现VQ算法在初始定义码本时是随机的,因此在限制条件下最后达到量化码本总会有一些偏差,由于这些偏差导致识别率的不同,因此在训练码书时,当得到一个较高识别率的码书时及时保存,经过不断更新得到一个较合适的码书,改善了识别率。
4,在DTW+VQ方法中,需要训练的主要参数有:VQ和DTW的权重:vqweight和dtwweight(vqweight+dtwweight=1,二者定一可决其二)。实验结果如下:
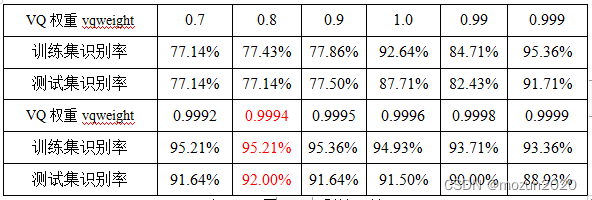
表二:不同VQ权重的识别率
通过上述实验结果分析比较,本文选取的参数分别为L= 120 ; thr=0.001 ; vqweight=0.9994 ;由此得出a分类的最佳训练识别率为95.21% ,最佳测试识别率为92% ;b分类的最佳训练识别率为92.86% ,最佳测试识别率为 93.5%。
通过两个方法比较,发现DTW不适合于非特定人的语音识别,如果能将非特定人语音转化成特定人,其识别率说不定会有很大的提高;本文以后需要完善这方面的实验。VQ+DTW方法因为要多训练一个码书和VQ模板,特别是VQ模板的训练时间很长,但识别率在与DTW方法融合后得到很大的提升,而且DTW+VQ的识别时间更快,因为融合后匹配的运算量减少了许多。
六. 小结
研一的课程作业好多思路都还比较简单稚嫩,但也确实是付出了时间心血,希望未来自己在接下里的日子里,继续努力,继续学习,在语音信号处理方向不断精进!
本系列文章列表如下:
研究生语音识别课程作业记录(一) 非特定人孤立词识别
研究生语音识别课程作业记录(二) 非特定人孤立词识别
研究生语音识别课程作业记录(三) 非特定人孤立词识别

