Spring 定义错误案例分析
文章目录
以下为学习极客空间《Spring 编程常见错误 50 例》学习笔记整理,原课程课程链接 十分值得推荐,欢迎了解~
Spring 的核心
Spring 的两大核心:IOC、AOP,IOC 是由扫描器自动发现哪些类需要成为 bean,然后实例化成 bean(只能通过反射了);AOP 是拦截方法调用,进行一些扩展,这里也是用的反射,对代理对象进行增强后返回。
Spring 的简单易用得益于 “约定大于配置”。
案例1:隐式扫描不到 Bean 的定义
👾 问题:
刚接触 Spring 时可能有遇到这个约定——启动类和需要成为 baan 的类要写在同一个包下,比如某个 controller 和启动类不在一个包里,就会发现访问 controller 无效的情况。
🐾分析:
关键点在于 @SpringBootApplication 注解,继承了另外一些注解,具体定义如下:
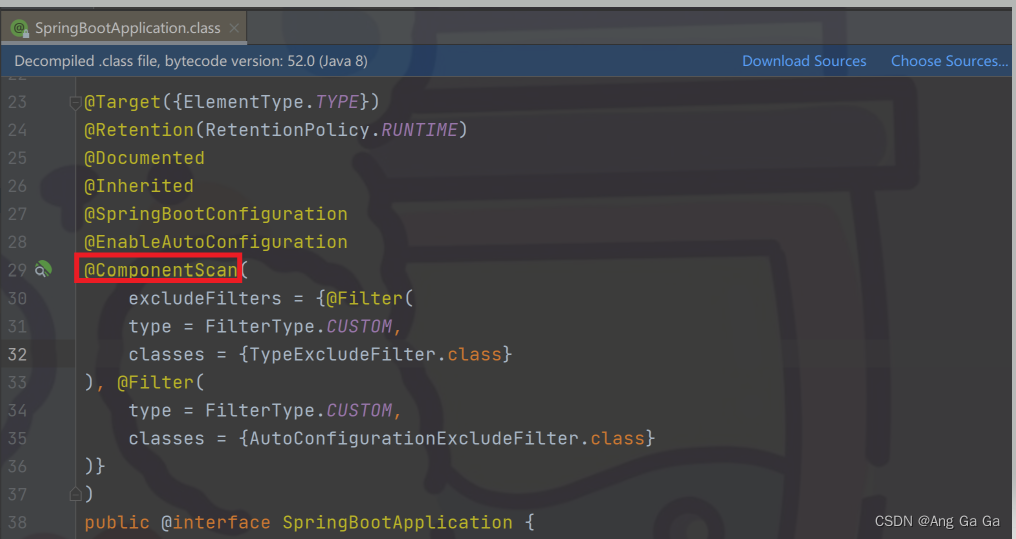
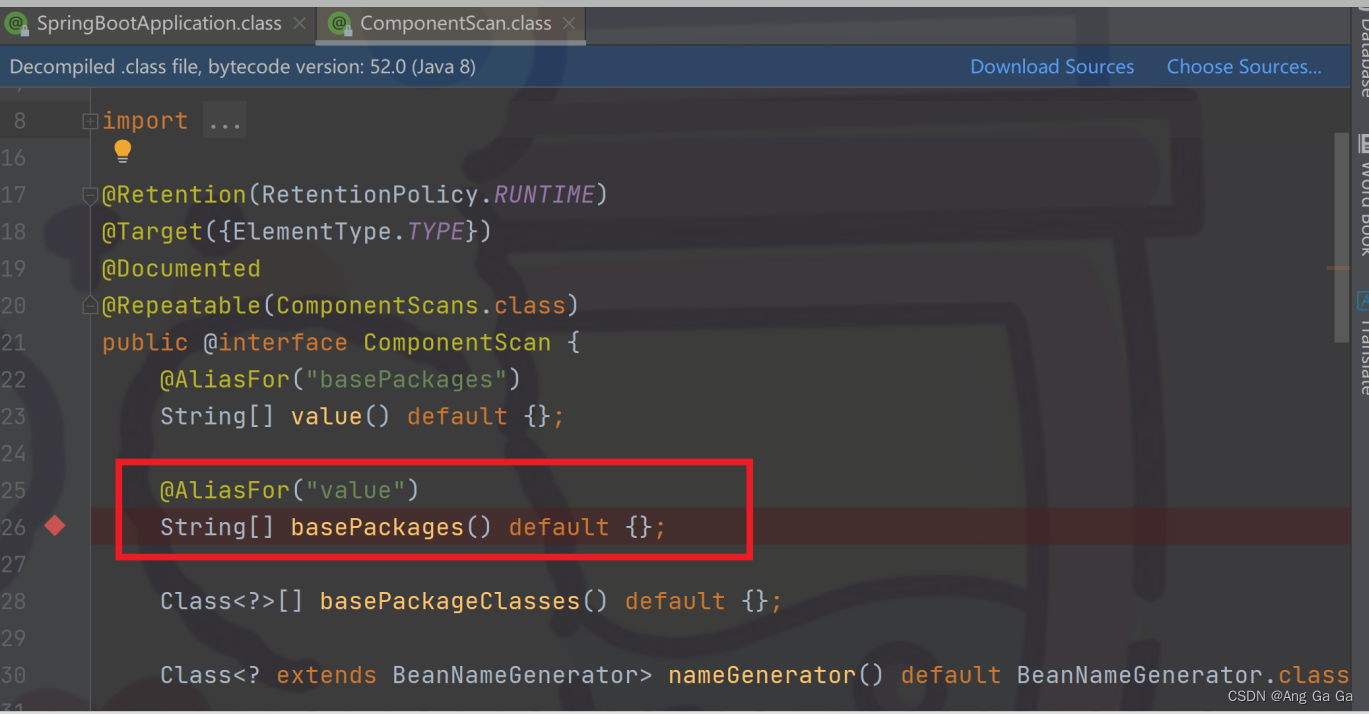
其中ComponentScan,就是用来扫描定义的 bean 的,它的 basePackages没有指定,所以默认为空,再看org.springframework.context.annotation.ComponentScanAnnotationParser,其中 parse 方法,debug 模式可以看到,当 basePackages 为空时,实际上扫描的是启动类所在的包。
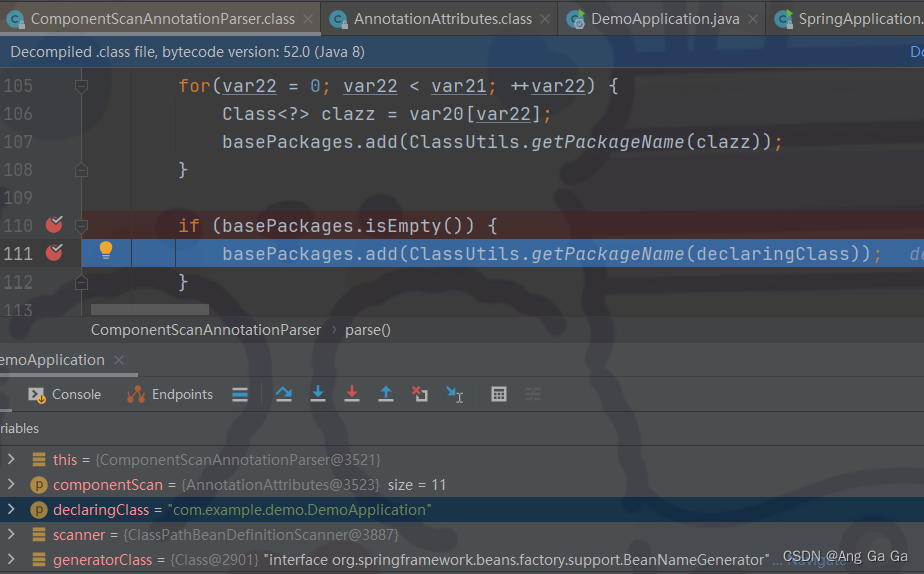
接下来解决问题,当然不只是把 controller 移动到和启动类同一个包下就完事儿😂,而是应该真正满足需求——让启动类能够扫描到 controller (思路:默认情况下,扫描的是启动类所在的包,想让 controller 被扫描到,一种是让 controller位于启动类所在的包中,指标不治本~ 第二种是指定,而不走默认情况,让启动类能够扫描到 controller )
🕶️ 解决方法:
显式声明启动类扫描包,如:
@ComponentScan("com.example.demo.controller")(发现 IDEA 还挺智能的~,如果这里指定的是启动类所在的包,会报错:Redundant declaration: @SpringBootApplication already applies given @ComponentScan)
(说回来,启动类没必要像 controller、service、dao、entity 一样各搞一个包,就放在共有的包就好了,让以上都能扫描到)
不过这样一来,原先默认的扫描范围,即 启动类所在的包,就不会被添加进去了,如果想一并生效,可以使用多个 @ComponentScan,也可以使用 @ComponentScans。
案例2:定义的 Bean 缺少隐式依赖
👾 问题:
有时候,除了默认的无参构造,我们可能也需要把某些参数传进来定义对象,比如:
@Servicepublic class ServiceImpl implements DemoService { private String serviceName; // 有参构造 public ServiceImpl(String serviceName) { this.serviceName = serviceName; }(其实写出这种代码的下一步,就应该会想到说 怎么给这个参数 serviceName 赋值了,毕竟已经再用 Spring 了,就不像之前无它时,想 new 就 new 随时随地 new 了😆)
ServiceImpl 类,用了 @Service 注解,也就成了一个 bean,然后使用这个 bean:
@RestController@RequestMapping("/demo")public class DemoController { @Autowired DemoService demoService;@RequestMapping("/getScope") public String getScope(){ return demoService.toString(); }运行报错:
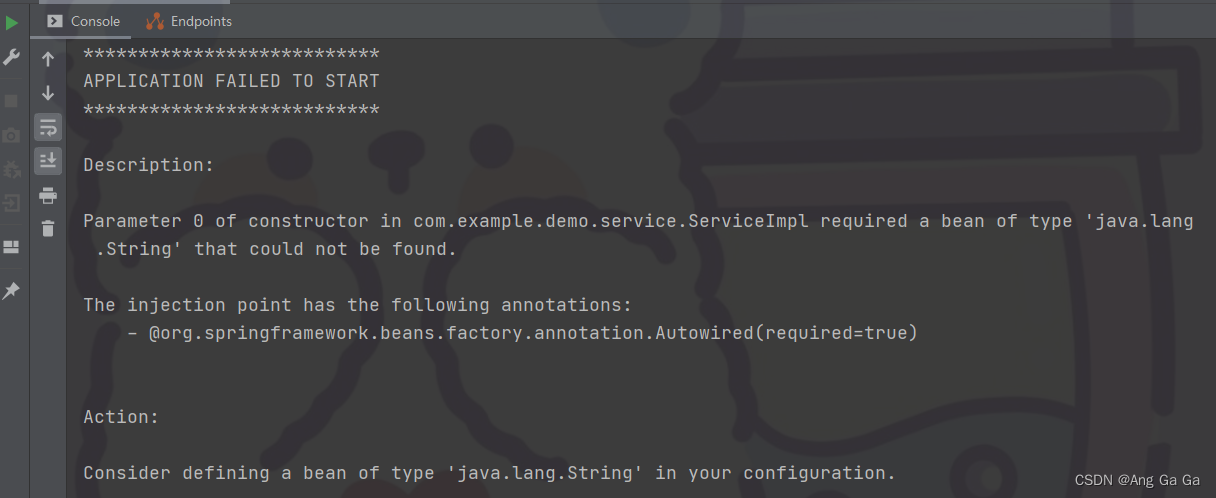
报错大概是说 ServiceImpl 的构造器需要一个 String 类型的参数,但实际上没找到。
🐾分析:
当创建一个 Bean 时,调用的方法是org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory #createBeanInstance。它主要包含两大基本步骤:寻找构造器和通过反射调用构造器创建实例。 关键代码:
Constructor<?>[] ctors = this.determineConstructorsFromBeanPostProcessors(beanClass, beanName); if (ctors == null && mbd.getResolvedAutowireMode() != 3 && !mbd.hasConstructorArgumentValues() && ObjectUtils.isEmpty(args)) { ctors = mbd.getPreferredConstructors(); return ctors != null ? this.autowireConstructor(beanName, mbd, ctors, (Object[])null) : this.instantiateBean(beanName, mbd); } else { return this.autowireConstructor(beanName, mbd, ctors, args); } 其中 determineConstructorsFromBeanPostProcessors 用来获取构造器,然后通过 autowireConstructor 方法,带着构造器 ctors 去创建实例,而这一步,不仅需要构造器,还需要构造器对应的参数 args··。 (待验证:这个报错其实也说明 bean默认是没有无参构造的,否则不传有参构造的参数,应该也能创建实例才对 补充:当只有一个有参构造时,是不会调用无参构造的;但是如果有多个有参构造可供调用,Spring 无从选择,将会尝试去调用默认构造;但是默认构造是不存在的,所以这种情况会报错。 )
既然在用 Spring 了,那就不直接显式使用 new 了,只能寻找依赖作为构造器调用参数。
至于这个构造器参数的获取,关键代码见 org.springframework.beans.factory.support.ConstructorResolver#autowireConstructor,其中:
argsHolder = this.createArgumentArray(beanName, mbd, resolvedValues, bw, paramTypes, paramNames, this.getUserDeclaredConstructor(candidate), autowiring, candidates.length == 1); 这里的 createArgumentArray 方法,就是用来构建构造器参数的,最终是会到 beanFactotry 中获取到 bean,代码看不出啥名堂,在此就不罗列了。案例中目前没有 serviceName 实例,也就报错了。
🕶️ 解决方法:
在 ServiceImpl 里定义一个能让 Spring 装配给 ServiceImpl 构造器参数的 bean,比如:
@Bean public String serviceName() { return "hello"; } 这时又会报新的错误,循环依赖:
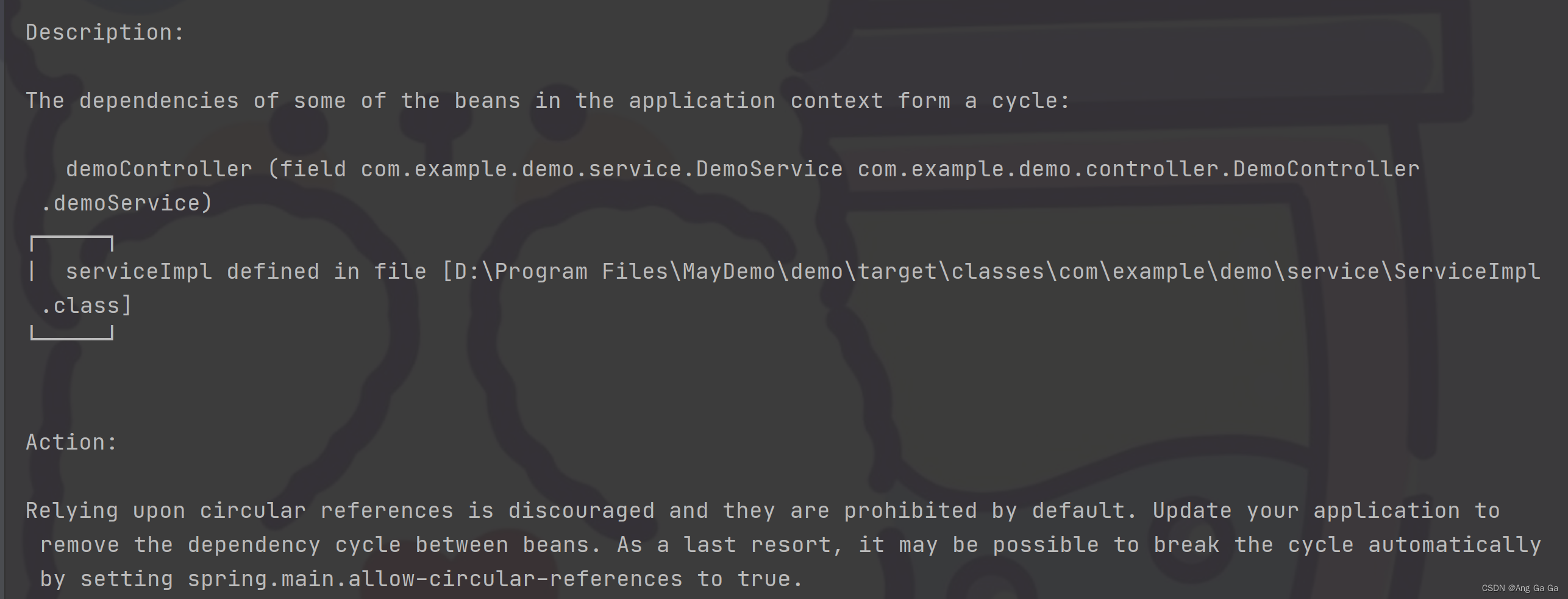
这是因为这个写法,会导致 ServiceImpl 的构造,依赖于 ServiceName,而 ServiceName 又需要先有 ServiceImpl ,尴尬了😅。给挪到 Controller 层也是一样的报错,因为 Controller 依赖了 ServiceImpl ,而 ServiceImpl 的构造,依赖于 ServiceName,而 ServiceName 又需要先有 Controller,循环得更深了: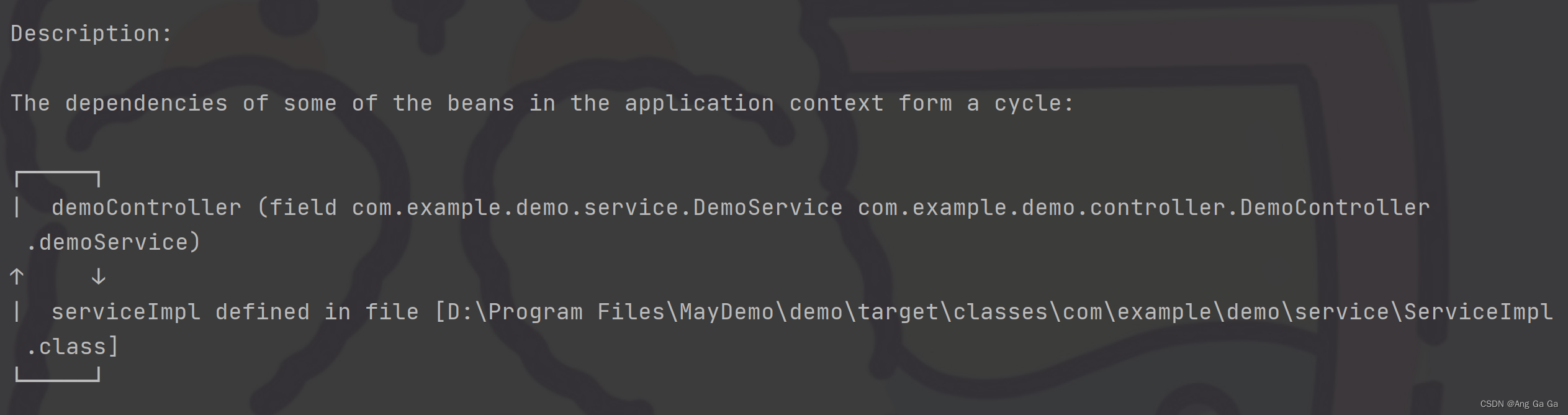
想要打破循环,重新定义一个类,用 @Component标识,然后再注册 ServiceImpl 即可:(待验证:这里方法名使用 getServiceName 也可,而且如果 serviceName() 和 getServiceName()方法同时存在,前者优先,这是什么原理?使用@Bean 作用在方法上,不指定 bean 名称的话,bean的命名规则是怎样的?
- 感觉对应的 beanName 应该就是 serviceName 和 getServiceName;装配时若找到前者,就用不到后者了,因为我声明了名称和方法名相反的bean:
@Componentpublic class ServiceNameClass { @Bean("serviceName") public String getServiceName() { return "hello"; } @Bean("getServiceName") public String serviceName() { return "123"; }}结果输出的是 hello,说明 xxx 是比getxxx优先的。包括把两个方法颠倒也不影响的。而如果两个bean名称相同,似乎是哪个 bean 写在前面,就先
只是为什么 getXXX 的 bean 也能做装配,这里不太理解… )
以上是一个有参构造的情况,如果是多个呢:
@Servicepublic class ServiceImpl { private String serviceName; public ServiceImpl(String serviceName){ this.serviceName = serviceName; } public ServiceImpl(String serviceName, String otherStringParameter){ this.serviceName = serviceName; }} 如果我们仍用非 Spring 的思维去审阅这段代码,可能不会觉得有什么问题,毕竟 String 类型可以自动装配了,无非就是再增加了一个 String 类型的参数otherStringParameter 而已。但是如果了解 Spring 内部是用反射来构建 Bean 的话,就不难发现问题所在:存在两个构造器,都可以调用时,到底应该调用哪个呢?最终 Spring 无从选择,只能尝试去调用默认构造器,而这个默认构造器又不存在,所以测试这个程序它会出错。
案例3:原型 Bean 被固定
👾 问题:
再来看个 Bean 定义不生效的例子,使用原型 Bean:
@Service@Scope(ConfigurableBeanFactory.SCOPE_PROTOTYPE)public class ServiceImpl {}使用它:
@RestControllerpublic class HelloWorldController { @Autowired private ServiceImpl serviceImpl; @RequestMapping(path = "hi", method = RequestMethod.GET) public String hi(){ return "helloworld, service is : " + serviceImpl; };} 结果发现,不管访问多少次这个路径,访问的结果都是不变的,跟个单例似的,这与它定义为原型 Bean 的 初衷背道而驰。
🐾分析:
当一个属性成员 serviceImpl 声明为 @Autowired 之后,那么在创建 HelloWorldController 这个 Bean 时,会先使用构造器反射出这个实例,然后再装配各个标记为 @Autowired 的属性成员,具体的执行过程,会使用到很多 BeanPostProcessor 来完成工作,其中相关的是 AutowiredAnnotationBeanPostProcessor,它会通过 DefaultListableBeanFactory#findAutowireCandidates 寻找到 ServiceImpl 类型的 Bean,然后赋值给 serviceImpl 成员。【为啥删掉呢,因为这个类里我没找到这个方法:)】 关键步骤见org.springframework.beans.factory.annotation.AutowiredAnnotationBeanPostProcessor.AutowiredMethodElement#inject:
protected void inject(Object bean, @Nullable String beanName, @Nullable PropertyValues pvs) throws Throwable { if (!this.checkPropertySkipping(pvs)) { Method method = (Method)this.member; Object[] arguments; if (this.cached) { try { arguments = this.resolveCachedArguments(beanName); } catch (NoSuchBeanDefinitionException var8) { arguments = this.resolveMethodArguments(method, bean, beanName); } } else { arguments = this.resolveMethodArguments(method, bean, beanName); } if (arguments != null) { try { ReflectionUtils.makeAccessible(method); method.invoke(bean, arguments); } catch (InvocationTargetException var7) { throw var7.getTargetException(); } } } } 可以看到,第一次HelloWorldController自动注入的时候,会通过反射机制设置给对应的 field:serviceImpl,这个 field 的执行只发生一次,所以后续就固定起来了,并不会因为 ServiceImpl 标记了 SCOPE_PROTOTYP 而改变。也就是说,只要程序一启动,HelloWorldController 里的 serviceImpl 是固定的,@Scope并不起作用。
🕶️ 解决方法:
破除这个“固定”的封印即可,使得每次使用时,都会重新获取一次属性,方法如下:
(1)自动注入 Context
定义个 getServiceImpl() 方法,通过方法能够获取到一个新的 ServiceImpl 类实例:
@Autowired private ApplicationContext applicationContext; public ServiceImpl getServiceImpl(){ return applicationContext.getBean(ServiceImpl.class); }(待验证:尚且不知道applicationContext.getBean的原理)
(2)使用 Lookup 注解
也是定义个 getServiceImpl() 方法,使用 @Lookup 注解:
@Lookup public ServiceImpl getServiceImpl3(){ return null; } 使用 @Lookup 注解的方法,具体实现是无所谓的,甚至在方法里打印日志,执行起来也并不会打印,只需知道 使用@Lookup 会使用 CGLIB (CGLIB:对代理对象类生成的 class 文件加载进来,通过修改其字节码生成子类来进行代理)实现动态代理,还有个异曲同工的方法:
(3)使用 scope注解的proxyMode:
@Service@Scope(ConfigurableBeanFactory.SCOPE_PROTOTYPE)@Scope(proxyMode = ScopedProxyMode.TARGET_CLASS, value = ConfigurableBeanFactory.SCOPE_PROTOTYPE)public class ServiceImpl {}这样注入到 controller 的 bean 也是代理对象来得,每次都会从beanfactory 里面重新拿来。
总结
- @SpringBootApplication 继承了一些注解,其中 @ComponentScan 是用来扫描定义的 bean 的,若未指定包名,默认只扫描启动类所在的包;而如果显式指定其他包,原来的默认包就被忽略了。
-
- @ComponentScan可以多个同时使用,且都生效。效果等同于 @ComponentScans。
- @ComponentScan可以多个同时使用,且都生效。效果等同于 @ComponentScans。
- 当只有一个有参构造时,Spring 创建该类实例时是不会调用无参构造的,并且需要提供构造方法的参数实例以供装配;
而如果有多个有参构造可供调用,Spring 无从选择,将会尝试去调用默认无参构造,但是默认构造是不存在的,所以会报错。∴ 不要提供多个有参构造。
- 单例对象的 @Autowired 属性一定是单例的,即使用了
@Scope(ConfigurableBeanFactory.SCOPE_PROTOTYPE)也还是单例,因为自程序启动后只会装配一次。 -
- 解决方法:使用applicationContext.getBean 或 @Lookup、或 proxyMode = ScopedProxyMode.TARGET_CLASS,每次都重新获取一次属性。
-
-
- @Lookup 作用在方法上,使得该方法返回值使用 CGLIB 动态代理生成,方法实现不重要 ,随便怎么写都行,应该走不到这里来。
- @Lookup 作用在方法上,使得该方法返回值使用 CGLIB 动态代理生成,方法实现不重要 ,随便怎么写都行,应该走不到这里来。
-
补充
想到啥记录啥~
1、为什么对象要有 getter、setter 方法?
在实例方法中有一类特殊的方法,它们一般不包含任何业务逻辑,仅仅是为类成员属性提供读取和修改的方法(really?好像在业务代码里见过夹带私货的…😥),这样设计的好处:
(1)满足面向对象语言封装的特性。尽可能将属性定义为 private,针对属性值的访问与修改需要使用对应的 getter 和 setter 方法,而不是直接对 publice 的属性进行读取和修改。
(2)有利于统一控制。虽然直接对属性进行读取和修改的方式 和 使用对应的 getter 与 setter 方法在效果上是一样的,但是前者难以应对业务的变化;比如 业务要求对某个值的修改要增加统一的权限控制,如果有 setter 作为统一的属性修改方法,则更容易实现,这种情况在一些使用反射的框架中作用尤其明显。(思考这个问题,可以从方法和直接赋值的区别去考虑,方法有返回值、访问权限控制符、入参,而且方法的存在相当于一个收口,方法声明了之后可以到处使用~)
顺便提一下,同时定义了 isXXX() 和 getXXX() ,在 iBatis、JSON序列化等场景下容易引起冲突,比如 iBatis 通过反射机制解析加载属性的 getter 方法时,首先会获取对象的所有方法,任何筛选出以 get 和 is 开头的方法,并存储到类型为 HashMap 的 getMethods 变量中,其中 key 为 属性名称,value 为 getter 方法,这样的话 isXXX() 和 getXXX() 只能保留一个,哪个方法被存储到 getMethods 变量中,就会保存哪个方法,具有一定的随机性,当两个方法定义不同时,可能导致误用哪个,进而产生问题。(启示:某个字段出问题,特别是 Boolean 类型的,可能就是获取方法有冲突,而实际只保留一个导致的,不失为一个排查思路)
2、什么情况下需要使用单例?
像注册表设置(registry setting)对象、线程池、数据库连接池,这些都是共享的资源,但是只能有一个实例,如果制造出多个实例,就会导致一些问题:资源使用过量、结果不一致等;而且资源也比较珍贵,重用更佳。启示:思考xxx存在的意义这种问题,可以从必要性和优化的角度去考虑,使用xxx是否必要?是否更优?
按说,一个类只存在一个实例,只用 Java 的静态变量(静态变量是类的所有实例共享的,它属于类,不属于任何独立的对象)就能做到,但是如果用静态变量的话,有个缺点:要想把对象赋值给一个静态变量,就得一开始创建好对象,万一创建对象这一步非常耗费资源,而程序在这次执行过程中一直没有执行到它,不就形成浪费了吗,所以单例模式应运而生,需要时才去创建。
✨todoList
- IDEA 报错是啥原理?
- 本文待验证项。