基于Python的直播平台数据分析可视化系统
温馨提示:文末有 CSDN 平台官方提供的学长 QQ 名片
1. 项目背景
随着移动互联网和5G的快速发展,视频直播行业呈现出丰富多元的内容形态,覆盖更多的场景和受众,视频成为了当前主流的信息传递媒介。本项目利用 python 网络爬虫抓取从某直播平台的直播数据,对不同直播频道数据进行统计分析,同时解析弹幕数据,通过文本清洗、关键词抽取,实现评论词云可视化,并基于 tfidf+情感词典算法实现评论的情感分析。
2. 功能组成
基于Python的直播平台数据分析可视化系统的功能主要包括:
3. 基于Python的直播平台数据分析可视化系统
3.1 系统注册登录
3.2 直播数据爬虫
利用 python 网络爬虫爬取某直播平台不同直播频道的直播数据(注:考虑版权问题,具体直播网站地址已脱敏),获取直播平台的所有直播频道:
# 首次爬取不存在类别列表文件,爬取url = 'https://www.xxxx.com/directory/all'headers = { 'user-agent': "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36 Edg/79.0.309.56"}response = requests.get(url, headers=headers)# 处理不同页面的编码问题encode = chardet.detect(response.content)if encode['encoding'] == 'GB2312': response.encoding = 'gbk'else: response.encoding = 'utf8'html = response.textsoup = BeautifulSoup(html, 'lxml')category_divs = soup.select('div.Aside-menu-block')cate_json = html[html.index('$DATA = {') + 8: html.index('var pageType = ')].strip()[:-1]cate_infos = json.loads(cate_json)cate_infos = cate_infos['leftNav']['cateList']xxxx_category = {}for cate_info, cate_div in zip(cate_infos, category_divs): first_cate = cate_div.find('a', class_='Aside-menu-title') first_cate_name = first_cate.text.strip() first_cate_url = 'https://www.xxxx.com' + first_cate['href'] if cate_info['cn1'] != first_cate_name: raise ValueError xxxx_category[first_cate_name] = {'url': first_cate_url, 'second_category': [], 'id': cate_info['id']} second_cates = cate_div.select('a.Aside-menu-item') for second_cate_info, second_cate in zip(cate_info['list'], second_cates): second_cate_name = second_cate.text.strip() second_cate_url = 'https://www.xxxx.com' + second_cate['href'] if second_cate_info['cn2'] != second_cate_name: raise ValueError xxxx_category[first_cate_name]['second_category'].append({'second_cate_name': second_cate_name, 'second_cate_url': second_cate_url, 'cid2': second_cate_info['cid2']})对每个直播频道进行循环抓取详细的直播信息:
......# 对每个大类别的数据进行循环爬取insert_sql = 'INSERT INTO zhibo_info(spider_time, first_cate, second_cate, online_watchers) VALUES (?,?,?,?)'for first_cate_name in xxxx_category: print('--> 爬取大类别:{}'.format(first_cate_name)) first_cate = xxxx_category[first_cate_name] for second_cate in first_cate['second_category']: print('爬取:', second_cate['second_cate_name']) spider_time = datetime.now().strftime("%Y-%m-%d %H:%M:%S") online_watchers = {} # 保存视频id 和 在线观看人数 page_idx = 1 while True: api_url = 'https://www.xxxx.com/gapi/rkc/directory/2_{}/{}'.format(second_cate['cid2'], page_idx) headers = { 'user-agent': "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36 Edg/79.0.309.56" } response = requests.get(api_url, headers=headers) response.encoding = 'utf8' # 数据爬完了 if 'invalid param' in response.text: break videos = response.json()['data']['rl'] # 视频的在线人数 for v in videos: if v['rid'] not in online_watchers: online_watchers[v['rid']] = v['ol'] page_idx += 1 if page_idx > 8: # 页面只显示 8 页的视频 break ......3.3 不同直播频道直播数据分析
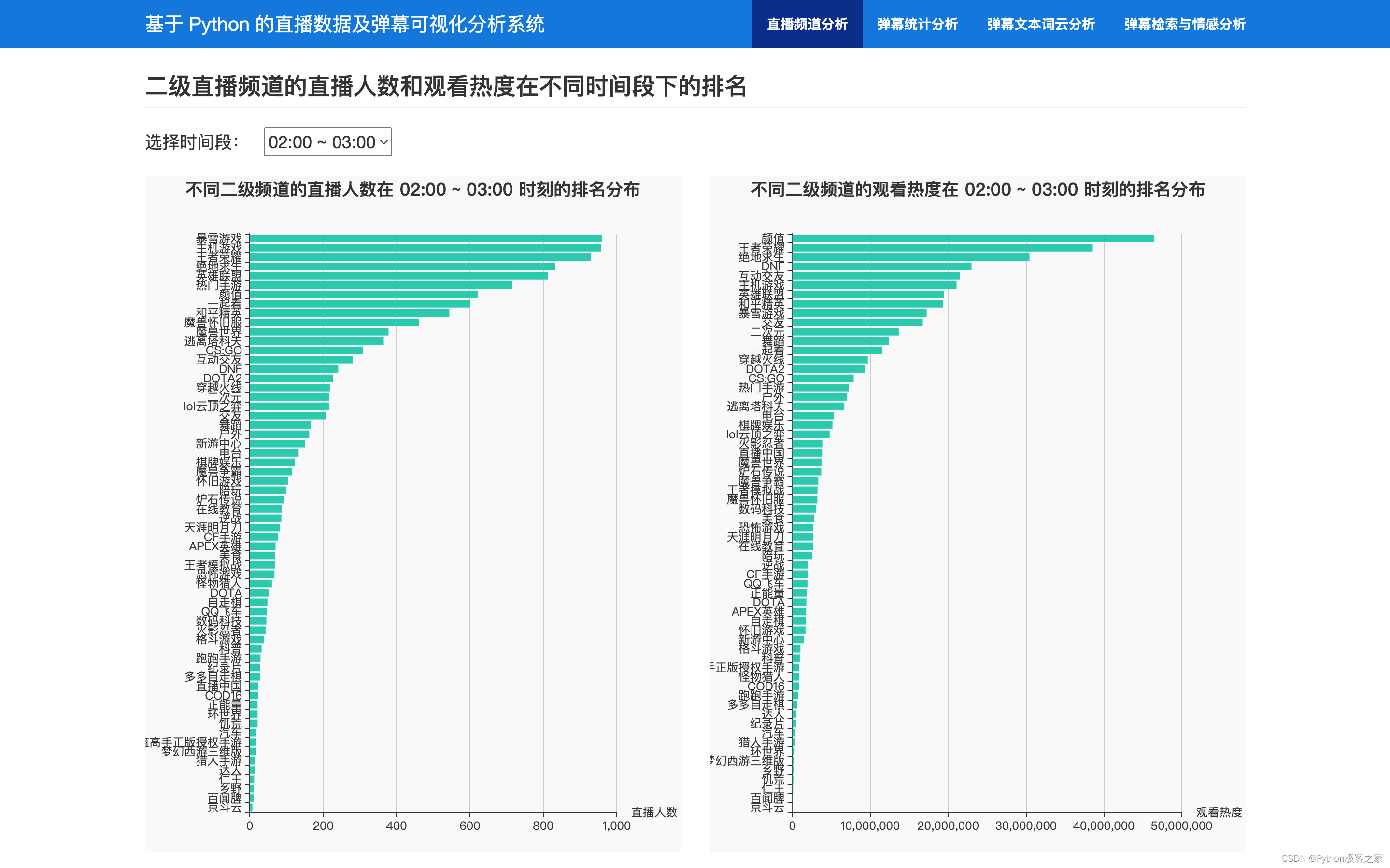
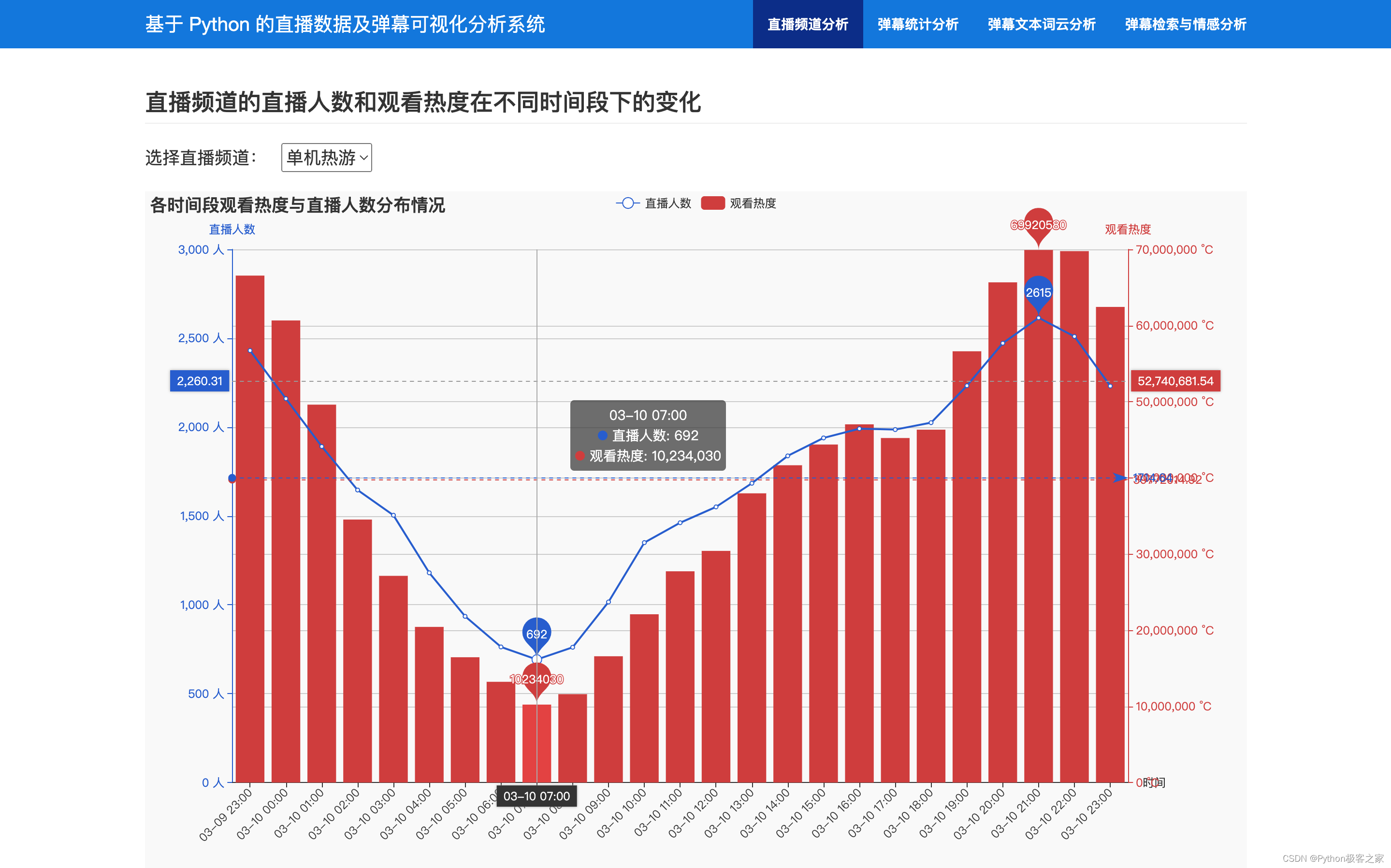
分析不同直播频道的直播人数和观看热度在不同时间段的占比等信息进行统计分析:
def category_hot_rank(check_hour): """ 不同大类直播频道在不同时间点的热度 """ ...... first_cate_zhibo_info = {} for first_cate in first_cates: sql = "SELECT spider_time, online_watchers FROM zhibo_info WHERE first_cate='{}'".format(first_cate) cursor.execute(sql) results = cursor.fetchall() if len(results) == 0: zhibo_cnt, watcher_cnt = 0, 0 else: zhibo_cnt, watcher_cnt = 0, 0 for result in results: spider_time, online_watchers = result spider_time = datetime.strptime(spider_time, '%Y-%m-%d %H:%M:%S') hour = spider_time.hour if check_hour == hour: online_watchers = json.loads(online_watchers) zhibo_cnt += len(online_watchers) # 直播人数 watcher_cnt += sum(online_watchers.values()) # 观看热度 first_cate_zhibo_info[first_cate] = {'直播人数': zhibo_cnt, '观看热度': watcher_cnt} ......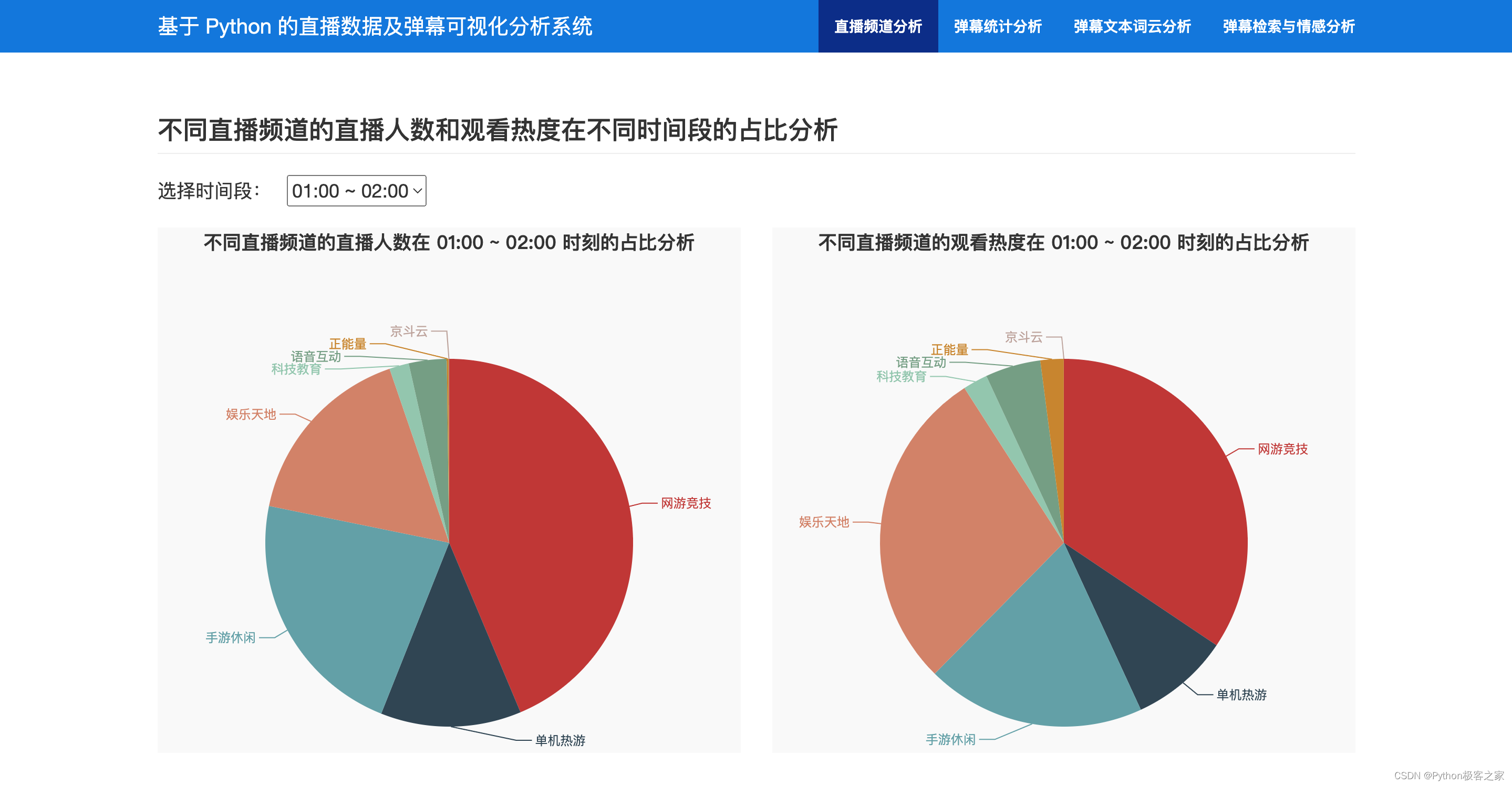
3.4 弹幕信息统计分析
通过对弹幕发送时间,每个视频发送弹幕数量等维度进行统计分析:
def danmu_time_in_video(jishu): """弹幕再视频中出现的时间""" ...... in_video_times = cursor.fetchall() in_video_times = [t[0] for t in in_video_times] in_video_times = sorted(in_video_times) time_counts = {} for t in in_video_times: second = round(t) if second not in time_counts: time_counts[second] = 0 time_counts[second] += 1 filled_time_counts = {} for second in range(max(time_counts.keys())): if second not in time_counts: filled_time_counts[second] = 0 else: filled_time_counts[second] = time_counts[second] times = list(filled_time_counts.keys()) counts = [filled_time_counts[t] for t in times] ......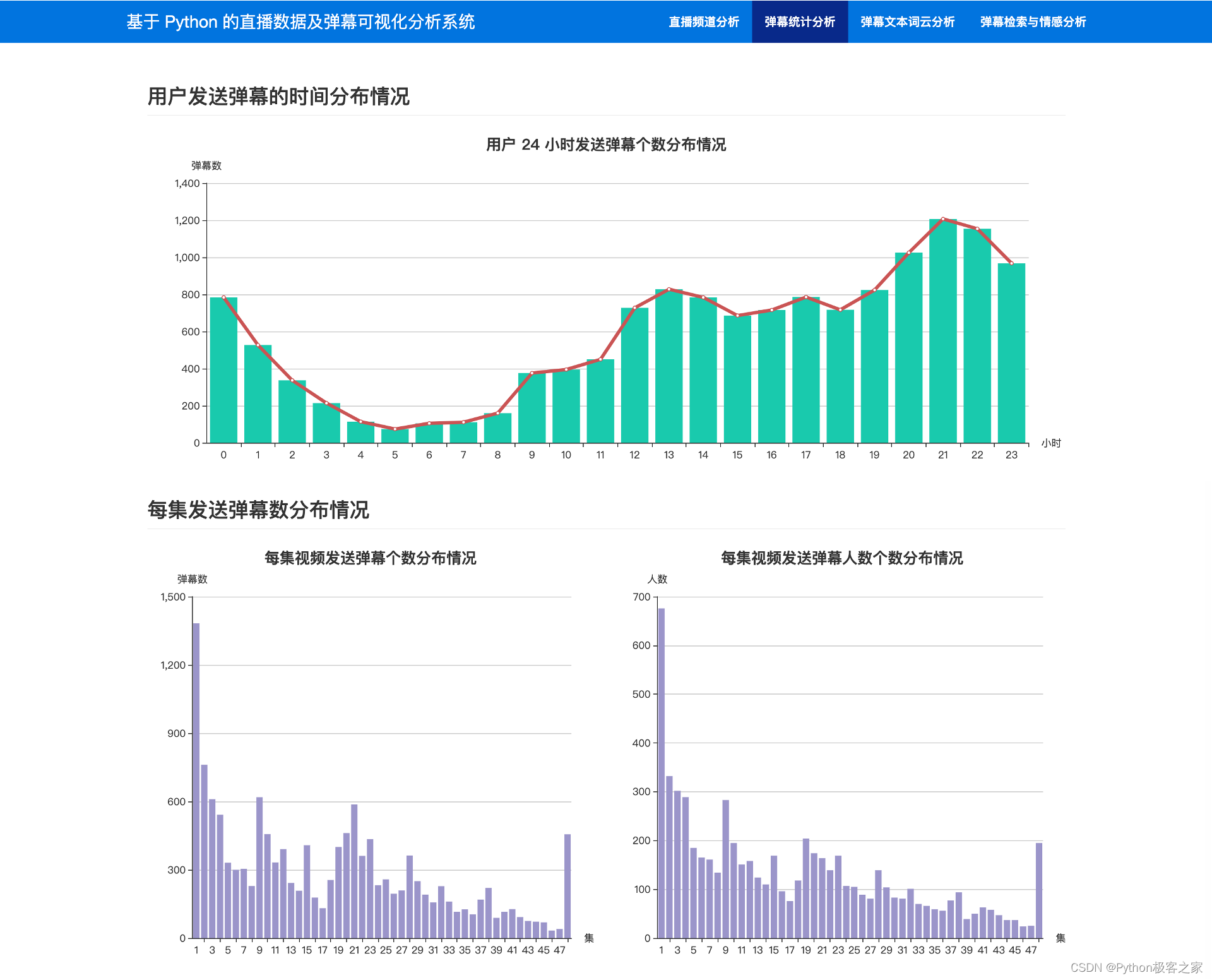
3.5 弹幕文本关键词抽取与词云分析
@app.route('/meiji_wordcloud/')def meiji_wordcloud(jishu): """弹幕文本词云分析""" ...... wordclout_dict = {} for text in texts: words = jieba.cut(text[0]) for word in words: if word not in STOPWORDS: if word not in wordclout_dict: wordclout_dict[word] = 0 else: wordclout_dict[word] += 1 wordclout_dict = [(k, wordclout_dict[k]) for k in sorted(wordclout_dict.keys()) if wordclout_dict[k] > 1] wordclout_dict = [{"name": k[0], "value": k[1]} for k in wordclout_dict] ......
3.6 弹幕检索与情感分析
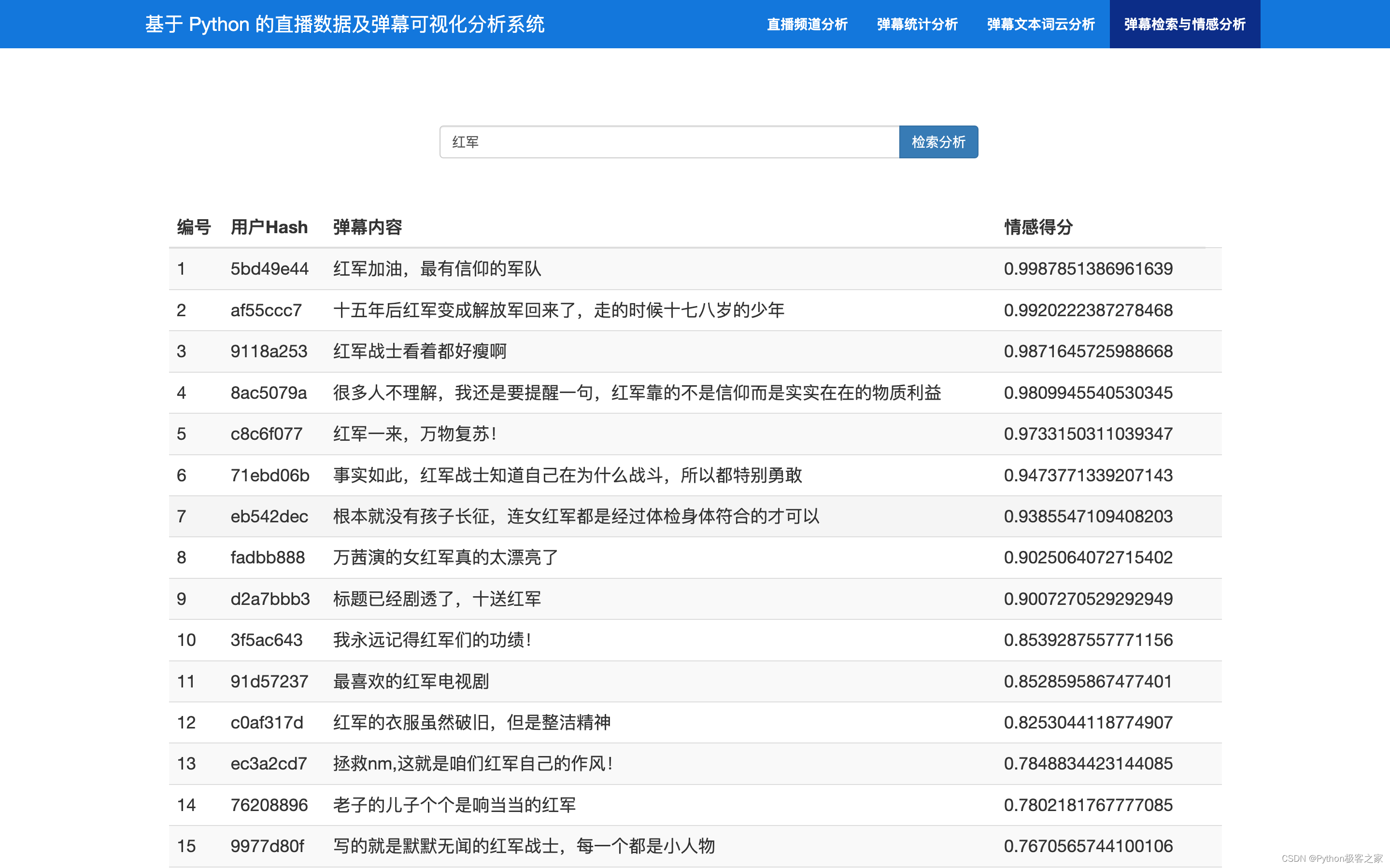
4. 总结
本项目利用 python 网络爬虫抓取从某直播平台的直播数据,对不同直播频道数据进行统计分析,同时解析弹幕数据,通过文本清洗、关键词抽取,实现评论词云可视化,并基于 tfidf+情感词典算法实现评论的情感分析。
欢迎大家点赞、收藏、关注、评论啦 ,由于篇幅有限,只展示了部分核心代码。
技术交流认准下方 CSDN 官方提供的学长 QQ 名片
精彩专栏推荐订阅:
Python 毕设精品实战案例


