CUDA Graph图详解
CUDA图
CUDA Graphs 为 CUDA 中的工作提交提供了一种新模型。图是一系列操作,例如内核启动,由依赖关系连接,独立于其执行定义。这允许一个图被定义一次,然后重复启动。将图的定义与其执行分开可以实现许多优化:首先,与流相比,CPU 启动成本降低,因为大部分设置都是提前完成的;其次,将整个工作流程呈现给 CUDA 可以实现优化,这可能无法通过流的分段工作提交机制实现。
要查看图形可能的优化,请考虑流中发生的情况:当您将内核放入流中时,主机驱动程序会执行一系列操作,以准备在 GPU 上执行内核。这些设置和启动内核所必需的操作是必须为发布的每个内核支付的间接成本。对于执行时间较短的 GPU 内核,这种开销成本可能是整个端到端执行时间的很大一部分。
使用图的工作提交分为三个不同的阶段:定义、实例化和执行。
- 在定义阶段,程序创建图中操作的描述以及它们之间的依赖关系。
- 实例化获取图模板的快照,对其进行验证,并执行大部分工作的设置和初始化,目的是最大限度地减少启动时需要完成的工作。 生成的实例称为可执行图。
- 可执行图可以启动到流中,类似于任何其他 CUDA 工作。 它可以在不重复实例化的情况下启动任意次数。
图架构
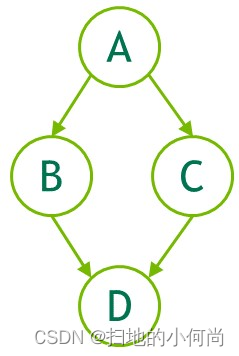
一个操作在图中形成一个节点。 操作之间的依赖关系是边。 这些依赖关系限制了操作的执行顺序。
一个操作可以在它所依赖的节点完成后随时调度。 调度由 CUDA 系统决定。
节点类型
图节点可以是以下之一:
- 核函数
- CPU函数调用
- 内存拷贝
- 内存设置
- 空节点
- 等待事件
- 记录事件
- 发出外部信号量的信号
- 等待外部信号量
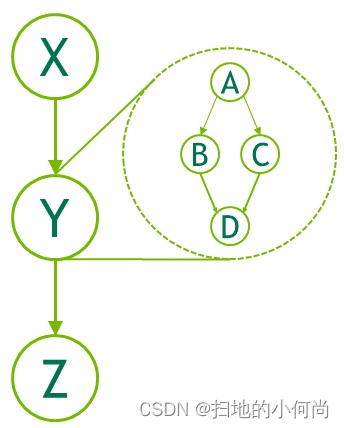
- 子图:执行单独的嵌套图。 请参下图。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-q3pdSW0h-1653956198029)(child-graph.png)]
利用API创建图
可以通过两种机制创建图:显式 API 和流捕获。 以下是创建和执行下图的示例。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-S1I4OXF5-1653956198029)(create-a-graph.png)]
// Create the graph - it starts out emptycudaGraphCreate(&graph, 0);// For the purpose of this example, we'll create// the nodes separately from the dependencies to// demonstrate that it can be done in two stages.// Note that dependencies can also be specified // at node creation. cudaGraphAddKernelNode(&a, graph, NULL, 0, &nodeParams);cudaGraphAddKernelNode(&b, graph, NULL, 0, &nodeParams);cudaGraphAddKernelNode(&c, graph, NULL, 0, &nodeParams);cudaGraphAddKernelNode(&d, graph, NULL, 0, &nodeParams);// Now set up dependencies on each nodecudaGraphAddDependencies(graph, &a, &b, 1); // A->BcudaGraphAddDependencies(graph, &a, &c, 1); // A->CcudaGraphAddDependencies(graph, &b, &d, 1); // B->DcudaGraphAddDependencies(graph, &c, &d, 1); // C->D使用流捕获创建图
流捕获提供了一种从现有的基于流的 API 创建图的机制。 将工作启动到流中的一段代码,包括现有代码,可以等同于用与 cudaStreamBeginCapture() 和 cudaStreamEndCapture() 的调用。
cudaGraph_t graph;cudaStreamBeginCapture(stream);kernel_A<<>>(...);kernel_B<<>>(...);libraryCall(stream);kernel_C<<>>(...);cudaStreamEndCapture(stream, &graph);对 cudaStreamBeginCapture() 的调用将流置于捕获模式。 捕获流时,启动到流中的工作不会排队执行。 相反,它被附加到正在逐步构建的内部图中。 然后通过调用 cudaStreamEndCapture() 返回此图,这也结束了流的捕获模式。 由流捕获主动构建的图称为捕获图(capture graph)。
流捕获可用于除 cudaStreamLegacy(“NULL 流”)之外的任何 CUDA 流。 请注意,它可以在 cudaStreamPerThread 上使用。 如果程序正在使用legacy stream,则可以将stream 0 重新定义为不更改功能的每线程流。 请参阅默认流。
可以使用 cudaStreamIsCapturing() 查询是否正在捕获流。
跨流依赖性和事件
流捕获可以处理用 cudaEventRecord() 和 cudaStreamWaitEvent() 表示的跨流依赖关系,前提是正在等待的事件被记录到同一个捕获图中。
当事件记录在处于捕获模式的流中时,它会导致捕获事件。捕获的事件表示捕获图中的一组节点。
当流等待捕获的事件时,如果尚未将流置于捕获模式,则它会将流置于捕获模式,并且流中的下一个项目将对捕获事件中的节点具有额外的依赖关系。然后将两个流捕获到同一个捕获图。
当流捕获中存在跨流依赖时,仍然必须在调用 cudaStreamBeginCapture() 的同一流中调用 cudaStreamEndCapture();这是原始流。由于基于事件的依赖关系,被捕获到同一捕获图的任何其他流也必须连接回原始流。如下所示。在 cudaStreamEndCapture() 时,捕获到同一捕获图的所有流都将退出捕获模式。未能重新加入原始流将导致整个捕获操作失败。
// stream1 is the origin streamcudaStreamBeginCapture(stream1);kernel_A<<>>(...);// Fork into stream2cudaEventRecord(event1, stream1);cudaStreamWaitEvent(stream2, event1);kernel_B<<>>(...);kernel_C<<>>(...);// Join stream2 back to origin stream (stream1)cudaEventRecord(event2, stream2);cudaStreamWaitEvent(stream1, event2);kernel_D<<>>(...);// End capture in the origin streamcudaStreamEndCapture(stream1, &graph);// stream1 and stream2 no longer in capture mode 上述代码返回的图如图 10 所示。
注意:当流退出捕获模式时,流中的下一个未捕获项(如果有)仍将依赖于最近的先前未捕获项,尽管已删除中间项。
禁止和未处理的操作
同步或查询正在捕获的流或捕获的事件的执行状态是无效的,因为它们不代表计划执行的项目。当任何关联流处于捕获模式时,查询包含活动流捕获的更广泛句柄(例如设备或上下文句柄)的执行状态或同步也是无效的。
当捕获同一上下文中的任何流时,并且它不是使用 cudaStreamNonBlocking 创建的,任何使用旧流的尝试都是无效的。这是因为legacy stream句柄始终包含这些其他流;legacy stream将创建对正在捕获的流的依赖,并且查询它或同步它会查询或同步正在捕获的流。
因此在这种情况下调用同步 API 也是无效的。同步 API,例如 cudaMemcpy(),将工作legacy stream并在返回之前对其进行同步。
注意:作为一般规则,当依赖关系将捕获的内容与未捕获的内容联系起来并排队执行时,CUDA 更喜欢返回错误而不是忽略依赖关系。将流放入或退出捕获模式时会出现异常;这切断了在模式转换之前和之后添加到流中的项目之间的依赖关系。
通过等待来自正在捕获并且与与事件不同的捕获图相关联的流中的捕获事件来合并两个单独的捕获图是无效的。等待正在捕获的流中的未捕获事件是无效的。
图中当前不支持将异步操作排入流的少量 API,如果使用正在捕获的流调用,则会返回错误,例如 cudaStreamAttachMemAsync()。
失效
在流捕获期间尝试无效操作时,任何关联的捕获图都将失效。 当捕获图无效时,进一步使用正在捕获的任何流或与该图关联的捕获事件将无效并将返回错误,直到使用 cudaStreamEndCapture() 结束流捕获。 此调用将使关联的流脱离捕获模式,但也会返回错误值和 NULL 图。
更新实例化图
使用图的工作提交分为三个不同的阶段:定义、实例化和执行。在工作流不改变的情况下,定义和实例化的开销可以分摊到许多执行中,并且图提供了明显优于流的优势。
图是工作流的快照,包括内核、参数和依赖项,以便尽可能快速有效地重放它。在工作流发生变化的情况下,图会过时,必须进行修改。对图结构(例如拓扑或节点类型)的重大更改将需要重新实例化源图,因为必须重新应用各种与拓扑相关的优化技术。
重复实例化的成本会降低图执行带来的整体性能优势,但通常只有节点参数(例如内核参数和 cudaMemcpy 地址)发生变化,而图拓扑保持不变。对于这种情况,CUDA 提供了一种称为“图形更新”的轻量级机制,它允许就地修改某些节点参数,而无需重建整个图形。这比重新实例化要有效得多。
更新将在下次启动图时生效,因此它们不会影响以前的图启动,即使它们在更新时正在运行。一个图可能会被重复更新和重新启动,因此多个更新/启动可以在一个流上排队。
CUDA 提供了两种更新实例化图的机制,全图更新和单个节点更新。整个图更新允许用户提供一个拓扑相同的 cudaGraph_t 对象,其节点包含更新的参数。单个节点更新允许用户显式更新单个节点的参数。当大量节点被更新时,或者当调用者不知道图拓扑时(即,图是由库调用的流捕获产生的),使用更新的 cudaGraph_t 会更方便。当更改的数量很少并且用户拥有需要更新的节点的句柄时,首选使用单个节点更新。单个节点更新跳过未更改节点的拓扑检查和比较,因此在许多情况下它可以更有效。以下部分更详细地解释了每种方法。
图更新限制
内核节点:
- 函数的所属上下文不能改变。
- 其功能最初未使用 CUDA 动态并行性的节点无法更新为使用 CUDA 动态并行性的功能。
cudaMemset 和 cudaMemcpy 节点:
- 操作数分配/映射到的 CUDA 设备不能更改。
- 源/目标内存必须从与原始源/目标内存相同的上下文中分配。
- 只能更改一维 cudaMemset/cudaMemcpy 节点。
额外的 memcpy 节点限制:
- 不支持更改源或目标内存类型(即 cudaPitchedPtr、cudaArray_t 等)或传输类型(即 cudaMemcpyKind)。
外部信号量等待节点和记录节点:
- 不支持更改信号量的数量。
- 对主机节点、事件记录节点或事件等待节点的更新没有限制。
全图更新
cudaGraphExecUpdate() 允许使用相同拓扑图(“更新”图)中的参数更新实例化图(“原始图”)。 更新图的拓扑必须与用于实例化 cudaGraphExec_t 的原始图相同。 此外,将节点添加到原始图或从中删除的顺序必须与将节点添加到更新图(或从中删除)的顺序相匹配。 因此,在使用流捕获时,必须以相同的顺序捕获节点,而在使用显式图形节点创建 API 时,必须以相同的顺序添加或删除所有节点。
以下示例显示了如何使用 API 更新实例化图:
cudaGraphExec_t graphExec = NULL;for (int i = 0; i < 10; i++) { cudaGraph_t graph; cudaGraphExecUpdateResult updateResult; cudaGraphNode_t errorNode; // In this example we use stream capture to create the graph. // You can also use the Graph API to produce a graph. cudaStreamBeginCapture(stream, cudaStreamCaptureModeGlobal); // Call a user-defined, stream based workload, for example do_cuda_work(stream); cudaStreamEndCapture(stream, &graph); // If we've already instantiated the graph, try to update it directly // and avoid the instantiation overhead if (graphExec != NULL) { // If the graph fails to update, errorNode will be set to the // node causing the failure and updateResult will be set to a // reason code. cudaGraphExecUpdate(graphExec, graph, &errorNode, &updateResult); } // Instantiate during the first iteration or whenever the update // fails for any reason if (graphExec == NULL || updateResult != cudaGraphExecUpdateSuccess) { // If a previous update failed, destroy the cudaGraphExec_t // before re-instantiating it if (graphExec != NULL) { cudaGraphExecDestroy(graphExec); } // Instantiate graphExec from graph. The error node and // error message parameters are unused here. cudaGraphInstantiate(&graphExec, graph, NULL, NULL, 0); }cudaGraphDestroy(graph); cudaGraphLaunch(graphExec, stream); cudaStreamSynchronize(stream);}典型的工作流程是使用流捕获或图 API 创建初始 cudaGraph_t。 然后 cudaGraph_t 被实例化并正常启动。 初始启动后,使用与初始图相同的方法创建新的 cudaGraph_t,并调用 cudaGraphExecUpdate()。 如果图更新成功,由上面示例中的 updateResult 参数指示,则启动更新的 cudaGraphExec_t。 如果由于任何原因更新失败,则调用 cudaGraphExecDestroy() 和 cudaGraphInstantiate() 来销毁原始的 cudaGraphExec_t 并实例化一个新的。
也可以直接更新 cudaGraph_t 节点(即,使用 cudaGraphKernelNodeSetParams())并随后更新 cudaGraphExec_t,但是使用下一节中介绍的显式节点更新 API 会更有效。
有关使用情况和当前限制的更多信息,请参阅 Graph API。
单个节点更新
实例化的图节点参数可以直接更新。 这消除了实例化的开销以及创建新 cudaGraph_t 的开销。 如果需要更新的节点数相对于图中的总节点数较小,则最好单独更新节点。 以下方法可用于更新 cudaGraphExec_t 节点:
cudaGraphExecKernelNodeSetParams()cudaGraphExecMemcpyNodeSetParams()cudaGraphExecMemsetNodeSetParams()cudaGraphExecHostNodeSetParams()cudaGraphExecChildGraphNodeSetParams()cudaGraphExecEventRecordNodeSetEvent()cudaGraphExecEventWaitNodeSetEvent()cudaGraphExecExternalSemaphoresSignalNodeSetParams()cudaGraphExecExternalSemaphoresWaitNodeSetParams()
有关使用情况和当前限制的更多信息,请参阅 Graph API。
使用图API
cudaGraph_t 对象不是线程安全的。 用户有责任确保多个线程不会同时访问同一个 cudaGraph_t。
cudaGraphExec_t 不能与自身同时运行。 cudaGraphExec_t 的启动将在之前启动相同的可执行图之后进行。
图形执行在流中完成,以便与其他异步工作进行排序。 但是,流仅用于排序; 它不限制图的内部并行性,也不影响图节点的执行位置。
请参阅图API。