【Kafka】第三篇-Kafka的集群及Canal介绍
【上一章 【Kafka】第二篇-Kafka的核心概念及分区消费规则】
学习路线
-
- Kafka集群架构
- Kafka集群环境
- Kafka案例实战
- What is Canal?
-
- 工作原理
-
- MySQL的主从复制将经过如下步骤:
- Canal工作原理
- Canal使用场景
- Canal运行环境
-
- MySQL环境的准备
-
- 相关命令:
- Canal要注意binlog日志格式要求为row格式;
- Canal环境准备
-
- 1、下载 canal部署程序
- 2、配置修改
- 3、启动Canal
- 4、查看进程:
- 5、查看 server 日志
- 6、查看 instance 的日志
- 7、关闭Canal
- MySQL+Canal+Kafka应用实践
-
- 1.修改canal 配置文件
- 2.修改instance配置文件:
- 结合ELK实现日志收集系统
Kafka集群架构
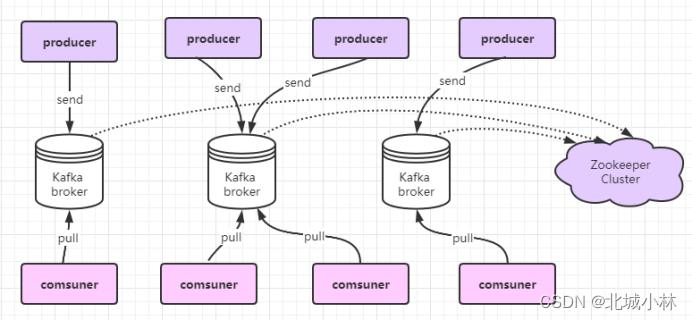
-
一个Kafka 集群体系架构包括多个Producer、多个Broker 、多个Consumer,以及一个zooKeeper 集群,其中 ZooKeeper是 Kafka 用来负责集群元数据的管理、控制器的选举等操作的,Producer将消息发送到 Broker, Broker 负责将收到的消息存储到磁盘中,而Consumer 负责从 Broker 订阅并消费消息;
-
我们知道Kafka的一个topic下可以有多个分区,每个分区又引入了多副本 Replica机制,通过增加副本数量可以提升容灾能力,同一分区的不同副本中保存的是相同的消息(在同一时刻,副本之间并非完全一样),副本之间是一主多从的关系,其中leader副本负责处理读写请求,follower 副本只负责与 leader 副本的消息同步,副本处于不同的broker,当leader副本出现故障时,从follower副本中重新选举新的leader副本对外提供服务,Kafka通过多副本机制实现了故障的自动转移,当Kafka集群中某个broker故障时仍然能保证服务可用;
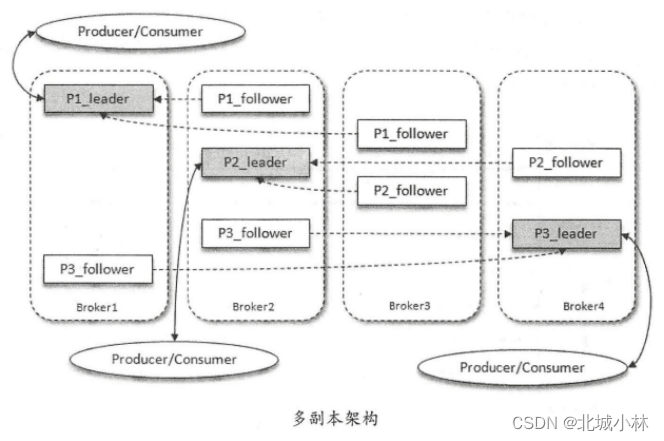
-
上图中,Kafka集群中有4个broker,某个topic主题中有3个分区,且副本因子(即副本个数)也为3,那么每个分区便有1个leader副本和2个follower 副本,生产者和消费者只与leader副本进行交互,而follow副本只负责消息的同步,很多时候 follower 副本中的消息相对leader副本而言会有一定的滞后;
-
分区中的所有副本统称为AR (Assigned Replicas),所有与leader副本保持一定程度同步的副本组成 ISR (On-Sync Replicas) , ISR 集合是AR集合中 一个子集,消息会先发送到leader副本,然后follower副本才能从leader副本中拉取消息进行同步,同步期间内follower副本相对于leader副本而言会有一定程度滞后,leader副本同步滞后过多的副本(不包 leader 副本)组成 OSR (Out-of-Sync Replicas ),即AR=ISR+OSR,在正常情况下,follower副本都应该与 leader 副本保持一定程度的同步,即AR=ISR,OSR集合为空;
-
leader 副本负责维护和跟踪ISR集合中所有follower的滞后状态,follower副本落后或故障时,leader副本会把它从ISR集合中剔除,OSR集合中若有 follower副本“追上”了leader副本,那么leader副本会把它从OSR集合转移至 ISR 集合,leader副本发生故障时,只有在ISR集合中的副本才有资格被选举为新的leader,而在OSR 集合中的副本没有机会被选举为leader;
-
OrderTopic --> 指定了3个分区 -->每一个分区指定3个副本(备份)
这3个副本包含了主副本(所以就是1个主副本,2个从副本)
Kafka集群环境
1、kafka是一个压缩包,直接解压即可使用,所以我们就解压三个kafka;
2、配置kafka集群:server.properties
(1)三台分别配置为:
broker.id=1、broker.id=2、broker.id=3该配置项是每个broker的唯一id,取值在0~255之间;
(2)三台分别配置listener=PAINTEXT:IP:PORT
listeners=PLAINTEXT://192.168.1.1:9091listeners=PLAINTEXT://192.168.1.1:9092listeners=PLAINTEXT://192.168.1.1:9093三台分别配置advertised.listeners=PAINTEXT:IP:PORT
advertised.listeners=PLAINTEXT://192.168.1.1:9091advertised.listeners=PLAINTEXT://192.168.1.1:9092advertised.listeners=PLAINTEXT://192.168.1.1:9093(3)配置日志目录
log.dirs=/usr/local/kafka_2.13-2.5.0-01/logs/kafka-logslog.dirs=/usr/local/kafka_2.13-2.5.0-02/logs/kafka-logslog.dirs=/usr/local/kafka_2.13-2.5.0-03/logs/kafka-logs这是极为重要的配置项,kafka所有数据就是写入这个目录下的磁盘文件中的;
(4)配置zookeeper连接地址
zookeeper.connect=localhost:2181如果zookeeper是集群,则:zookeeper.connect=localhost:2181,localhost:2182,localhost:2183(5)设置副本个数
offsets.topic.replication.factor=3集群启动:
用 daemon参数
./kafka-server-start.sh ../config/server.properties & ./kafka-server-start.sh -daemon ../config/server.properties然后查看/logs/server.log日志文件,查看启动是否正常;
Kafka 集群会定期自动关闭但却无法找到原因,从日志上broker 是正常关闭而非异常崩溃,原因就是启动方式没有使用-daemon;
Kafka案例实战
-
MySQL + Canal + kafka + logstash + elasticsearch + kibana (或者elasticsearch-head)
-
MySQL + Canal + kafka + 自己写个client消费kafka–> 业务处理
系统 + kafka + logstash + elasticsearch + kibana (或者elasticsearch-head) -
抖音/快手: 系统日志 --> kafka --> logstash --> elasticsearch --> kibana (或者elasticsearch-head)
What is Canal?
-
Canal [k?'n?l],中文翻译为 水道/管道/沟渠/运河,主要用途是用于 MySQL 数据库增量日志数据的订阅、消费和解析,是阿里巴巴开发并开源的,采用Java语言开发;
-
历史背景是早期阿里巴巴因为杭州和美国双机房部署,存在跨机房数据同步的业务需求,实现方式主要是基于业务 trigger(触发器) 获取增量变更。从2010年开始,阿里巴巴逐步尝试采用解析数据库日志获取增量变更进行同步,由此衍生出了Canal项目;
Github:https://github.com/alibaba/canal
工作原理
传统MySQL主从复制工作原理
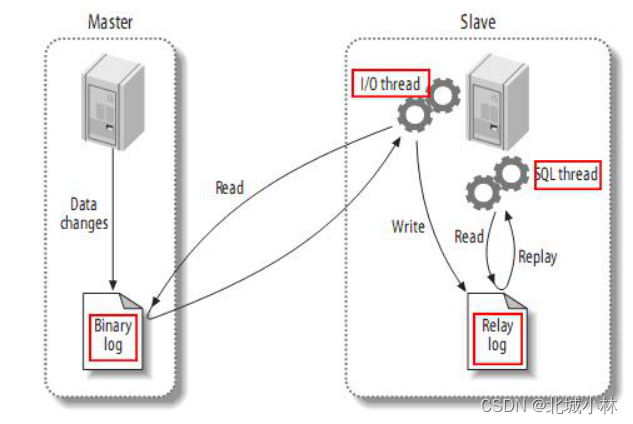
从上层来看,复制分成三步:
MySQL的主从复制将经过如下步骤:
- 1、当 master 主服务器上的数据发生改变时,则将其改变写入二进制事件日志文件中;
- 2、salve 从服务器会在一定时间间隔内对 master 主服务器上的二进制日志进行探测,探测其是否发生过改变,如果探测到 master 主服务器的二进制事件日志发生了改变,则开始一个 I/O Thread 请求 master 二进制事件日志;
- 3、同时 master 主服务器为每个 I/O Thread 启动一个dump Thread,用于向其发送二进制事件日志;
- 4、slave 从服务器将接收到的二进制事件日志保存至自己本地的中继日志文件中;
- 5、salve 从服务器将启动 SQL Thread 从中继日志中读取二进制日志,在本地重放,使得其数据和主服务器保持一致;
- 6、最后 I/O Thread 和 SQL Thread 将进入睡眠状态,等待下一次被唤醒;
Canal工作原理
- 1、canal 模拟 MySQL slave 的交互协议,把自己伪装为 MySQL slave,向 MySQL master 发送dump 协议;
- 2、MySQL master 收到 dump 请求,开始推送 binary log 给 slave (即canal );
- 3、canal 解析 binary log 对象 (原始数据为byte流)
Canal使用场景
Canal是基于MySQL变更日志增量订阅和消费的组件,可以使用在如下一些一些应用场景:
- 数据库实时备份;
-业务cache刷新; - search build;
- 价格变化等重要业务消息;
- 带业务逻辑的增量数据处理;
- 跨数据库的数据备份(异构数据同步) 例如mysql => oracle,mysql=>mongo,mysql =>redis,mysql => elasticsearch等;
当前canal 主要是支持源端 MySQL(也支持MariaDB),版本包括 5.1.x , 5.5.x , 5.6.x , 5.7.x , 8.0.x;
Canal运行环境
MySQL环境的准备
- 1、准备好MySQL运行环境;(安装好)
- 2、开启 MySQL的binlog写入功能,配置 binlog-format 为ROW模式;
my.cnf中配置如下:
[mysqld]log-bin=mysql-bin #开启 binlogbinlog-format=ROW #选择 ROW 模式server_id=1 #配置MySQL replaction需要定义,不要和canal的slaveId重复- 3、授权canal连接MySQL账号具有作为MySQL slave的权限, 如果已有账户可直接 grant授权:
(1)启动MySQL服务器;
(2)登录mysql:./mysql -uroot -p -h127.0.0.1 -P3306
(3)执行如下命令:
CREATE USER canal IDENTIFIED BY 'canal'; GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%';FLUSH PRIVILEGES;相关命令:
#是否启用了日志
show variables like 'log_bin';#怎样知道当前的日志
show master status;#查看mysql binlog模式
show variables like 'binlog_format';#获取binlog文件列表
show binary logs;#查看当前正在写入的binlog文件
show master status\G#查看指定binlog文件的内容
show binlog events in 'mysql-bin.000002';Canal要注意binlog日志格式要求为row格式;
Binlog的三种基本类型分别为:
- ROW模式 除了记录sql语句之外,还会记录每个字段的变化情况,能够清楚的记录每行数据的变化历史,但是会占用较多的空间,需要使用mysqlbinlog工具进行查看;
- STATEMENT模式 只记录了sql语句,但是没有记录上下文信息,在进行数据恢复的时候可能会导致数据的丢失情况;
MIX模式 比较灵活的记录,例如说当遇到了表结构变更的时候,就会记录为- - statement模式,当遇到了数据更新或者删除情况下就会变为row模式;
Canal环境准备
1、下载 canal部署程序
wget https://github.com/alibaba/canal/releases/download/canal-1.1.4/canal.deployer-1.1.4.tar.gztar -zxvf canal.deployer-1.1.4.tar.gz -C /usr/local/canal.deployer-1.1.42、配置修改
vim conf/example/instance.properties主要是修改配置文件中与自己的数据库配置相关的信息;
canal.instance.master.address=127.0.0.1:3306(其他的都不需要修改)
3、启动Canal
./startup.sh4、查看进程:
ps -ef | grep canal5、查看 server 日志
cat logs/canal/canal.log6、查看 instance 的日志
vi logs/example/example.log7、关闭Canal
./stop.shCanal Server的默认端口号为:11111,如果需要调整的话,可以到/conf目录下的canal.properties文件中进行修改;
至此,我们的MySQL和Canal环境便准备OK了;
MySQL+Canal+Kafka应用实践
1.修改canal 配置文件
vim conf/canal.properties- (1)
#可选项: tcp(默认), kafka, RocketMQcanal.serverMode = kafka- (2)
## MQ ###canal.mq.servers = 192.168.172.128:9092canal.mq.retries = 0canal.mq.batchSize = 16384canal.mq.maxRequestSize = 1048576canal.mq.lingerMs = 100canal.mq.bufferMemory = 33554432canal.mq.canalBatchSize = 50canal.mq.canalGetTimeout = 100canal.mq.flatMessage = truecanal.mq.compressionType = nonecanal.mq.acks = all#canal.mq.properties. =canal.mq.producerGroup = test# Set this value to "cloud", if you want open message trace feature in aliyun.canal.mq.accessChannel = local# aliyun mq namespace#canal.mq.namespace =2.修改instance配置文件:
在canal目录下
vim conf/example/instance.properties- (1)
canal.instance.master.address=127.0.0.1:3306- (2)
# mq configcanal.mq.topic=example# dynamic topic route by schema or table regex#canal.mq.dynamicTopic=mytest1.user,mytest2\\..*,.*\\..*canal.mq.partition=0# hash partition config#canal.mq.partitionsNum=3#canal.mq.partitionHash=test.table:id^name,.*\\..*- 3.启动:
先启动mysql再启动zookeeper再启动kafka最后启动canal查看日志:
vim logs/canal/canal.log消费者接收kafka消息:
./kafka-console-consumer.sh -bootstrap-server 192.168.1.1:9091,192.192.168.1.1:9092,192.168.1.1:9093 --topic mytopic --from-beginning或者使用我们的程序接收消息;
结合ELK实现日志收集系统
- 数据(任何数据)–> kafka --> logstash --> elasticsearch --> kibana (elasticsearch-head插件)
- logstash-from-kafka-to-es.yml
input {kafka {bootstrap_servers => "localhost:9091"topics => ["test"]}}output {elasticsearch {hosts => ["localhost:9200"]index => "kafka-topic-%{+YYY.MM.dd}"}stdout { codec => rubydebug }}- 启动
./logstash -f ../config/logstash_from_kafka_to_es.yml【下一章 【Kafka】第四篇-Kafka为什么这么快?】】

