高级程序员绝世心法——模块化之函数封装
这是机器未来的第13篇文章
写在前面:
- 博客简介:专注AIoT领域,追逐未来时代的脉搏,记录路途中的技术成长!
- 专栏简介:本专栏的核心就是:快!快!快!2周快速拿下Python,具备项目开发能力,为机器学习和深度学习做准备。
- 面向人群:零基础编程爱好者
- 专栏计划:接下来会逐步发布跨入人工智能的系列博文,敬请期待
- Python零基础快速入门系列
- 快速入门Python数据科学系列
- 人工智能开发环境搭建系列
- 机器学习系列
- 物体检测快速入门系列
- 自动驾驶物体检测系列
- …
文章目录
- 1. 函数概述
- 2. 函数分类
-
- 2.1 内置函数
- 2.2 自定义函数
- 3. 函数的定义
-
- 3.1 函数的结构
- 3.2 函数参数详解
-
- 3.2.1 位置参数
- 3.2.2 默认参数
- 3.2.3 命名关键参数
- 3.2.4 可变参数
- 3.2.5 关键参数
- 3.2.6 各种参数之间组合
- 4. 函数的注释
- 5. 匿名函数
-
- 5.1 语法
- 5.2 def函数和lambda表达式的区别
- 6. 递归函数
- 7. 高阶函数
-
- 7.1 高阶函数定义
-
- 7.2.1 map
-
- 7.2.1.1 常规def函数实现
- 7.2.1.2 lambda表达式实现
- 7.2.2 filter函数
- 7.2.3 sorted

1. 函数概述
官方定义:函数是组织好的,可重复使用的,用来实现单一,或相关联功能的代码段。
为什么要用函数?在回答这个问题之前,我们先看两张机房接线的对比图:

左侧是堆积如山凌乱的排线,对于运维工作人员来说,每次维护都是上刑场;右侧是按功能区分不同颜色整齐整洁的排线,对运维人员来说,只需要快速定位问题就好了。
无论任何一种编程语言,我们都有同样的要求:高内聚、低耦合。什么叫做高内聚,就是同样功能或相似功能的代码聚合在一起,不要相似的代码这个代码文件有一点,那个代码文件也有一点,分散在不同的代码文件中;什么叫做低耦合,不相关代码不要混淆在一起,你中有我,我中有你。
举个高耦合的例子,初级程序员经常犯的毛病就是爱用全局变量,然后整个代码工程文件都在使用。这种用法有非常多的缺点:
- 不好维护,全局变量在很多文件中都在使用及处理,在发生变更时非常容易遗漏;
- 对于多线程、多进程业务来说,会有同步问题;
- 维护难度高,要是交给别的开发者维护,简直就是灾难,通俗的话叫做“屎山”;
- 基本上难以移植,不能形成可复用的代码资产;
- …
而要实现高内聚、低耦合的方式就是模块化。
说到模块化,提一个问题:一个成熟的代码工程的层次结构是怎样的?
代码工程,代码多级分层,模块文件,类,函数,代码块。
以华为OpenHarmony项目为例,越是复杂的系统,代码分层越多,但是总体都符合上面描述的代码层次结构。
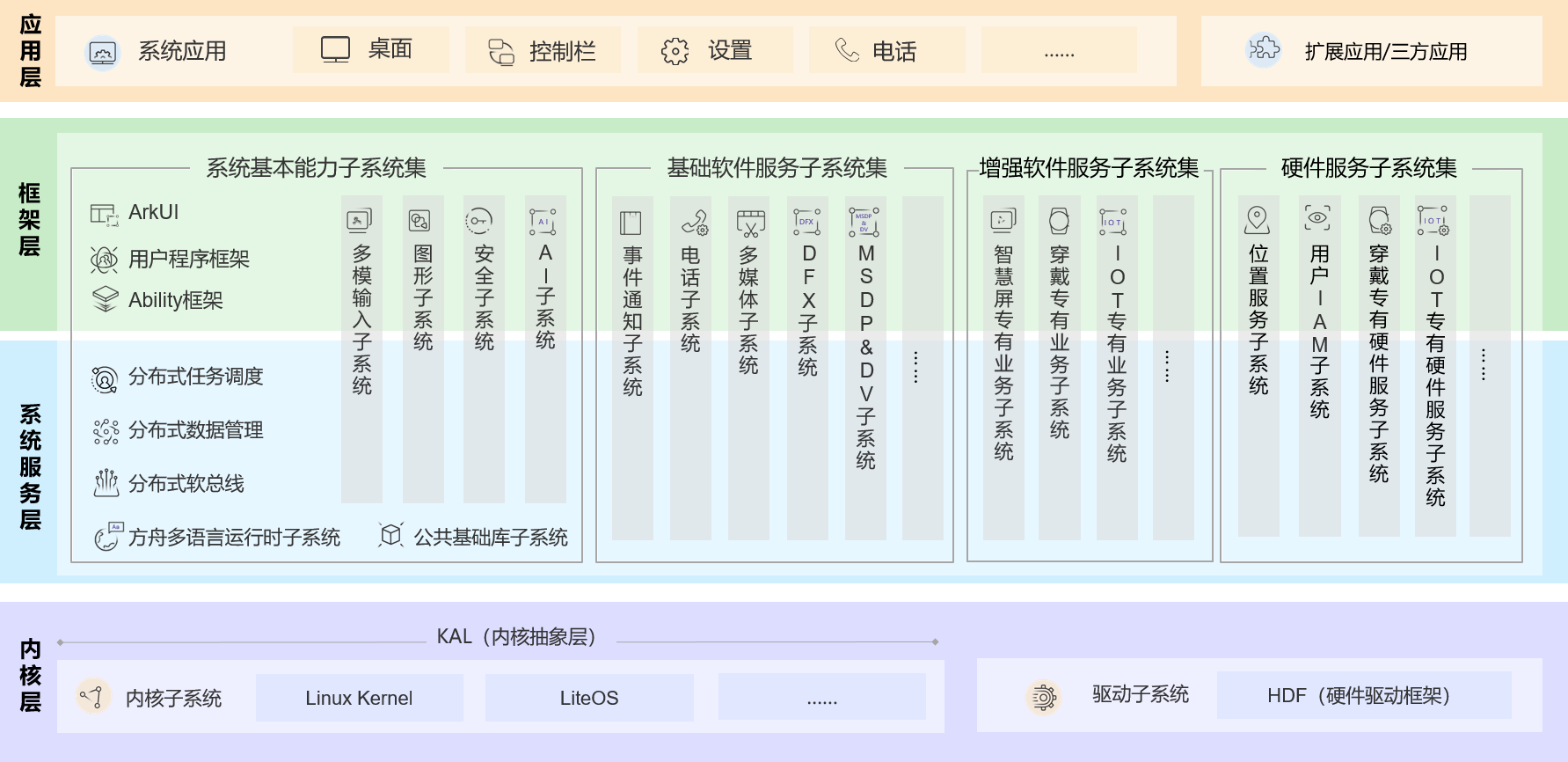
代码块是一个功能的最小组成单元,而要实现功能的封装,就需要用到函数来实现。函数实现了功能的内聚封装,逻辑低耦合。
以嵌入式开发中常见的串口驱动模块举例吧。
硬件驱动层
- 串口驱动模块文件
- 串口初始化函数
- 串口初始化相关代码块集合
- 串口发送函数
- 串口接收函数
- 串口释放函数
- 指示灯驱动模块文件
- …
- AD采样模块文件
- …
从串口驱动模块举例可以看到,相关功能的代码块集合封装成函数,多个相关函数的集合封装成模块文件,多个模块文件构成代码分层级,多个代码分层最终实现了产品的功能。
常说万丈高楼平地起,编程也是一样,一个个的函数就像积木一样组合在一起,最终成为万丈高楼。
高内聚、低耦合基本是初级程序员走上高级程序员所必须要悟到的绝世心法。
所以函数到底是什么?相关联的、功能单一的代码集合,隔离无关代码,高度聚焦的、可重复使用,易于移植的代码封装。
2. 函数分类
2.1 内置函数
像print、len、input、range这些都属于内置函数,python内部定义好的函数,可以直接使用。
2.2 自定义函数
除了内置函数之外,开发者还可以自定义函数,实现想要的功能,从而达到一次编写、多次调用的目的
3. 函数的定义
3.1 函数的结构
def [函数名]([函数的参数]): # 参数根据需要来,可以没有参数 [函数实现代码块] return [返回值] #可以不写,无return就无返回- 函数名
- 函数名命名规则和变量一样,可以为字母、数字、下划线,不可以数字开头;
- 函数参数
- 函数的参数作为输入输出使用,对于不可变数据类型只能作为输入使用,可变数据类型可以传递输出;
- 注意参数后面有个冒号:限定代码块范围属于函数
- 形参与实参:
- 函数定义时,括号内的参数为形参;函数调用时,括号内的参数为实参
- 函数代码块
- 函数功能的具体实现
- 返回值
- 返回值根据需要选择,可以有,也可以无, 无返回值时,函数中的值无法传递到函数外。
- 如果返回值有多个,以元组的形式返回
- return关键字有终止函数运行的功能,return关键字后面的代码不会被执行
举个例子:
# 函数的定义def multiply(x, y): z = x * y return z# 函数的调用a = multiply(5, 6)a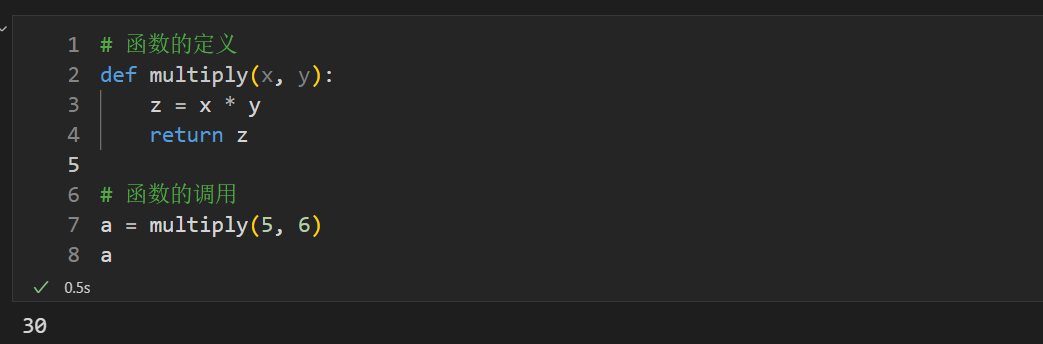
3.2 函数参数详解
3.2.1 位置参数
根据函数定义时参数的位置一一对应。
- 函数调用时,位置参数传入顺序必须和定义时一致;
- 函数调用时,参数的数量必须和定义时一致;
# 函数的定义def multiply(x, y): print(f"x={x}, y={y}") z = x * y return z# 函数的调用a = multiply(5, 6)a# 输出x=5, y=630交换位置:
# 函数的定义def multiply(x, y): print(f"x={x}, y={y}") z = x * y return z# 函数的调用a = multiply(6, 5)a# 输出x=6, y=530可以看到参数的取值变了。
深度学习的一些函数,,例如Conv2D,参数特别多,位置写错,可能训练结果差之千里,一定要注意顺序。
tf.keras.layers.Conv2D( filters, kernel_size, strides=(1, 1), padding='valid', data_format=None, dilation_rate=(1, 1), groups=1, activation=None, use_bias=True, kernel_initializer='glorot_uniform', bias_initializer='zeros', kernel_regularizer=None, bias_regularizer=None, activity_regularizer=None, kernel_constraint=None, bias_constraint=None, kwargs)3.2.2 默认参数
默认参数用于在函数未传递参数时使用默认值处理,例如输入的数据集某一个样本某个特征数据缺失,就可以使用一个默认值填充,然后进行后续处理。
举个例子, 当乘法函数只输入一个参数时,y默认取1:
# 函数的定义def multiply(x, y=1): print(f"x={x}, y={y}") z = x * y return z# 函数的调用a = multiply(5)a# 输出x=5, y=15注意事项:
- 默认参数必须位于参数列表的最右端,默认参数的后面不能有位置参数,否则解释器会无法识别报错。
# 函数的定义def multiply(y=1, x): print(f"x={x}, y={y}") z = x * y return z# 函数的调用a = multiply(5) # 5到底是y呢,还是x,无法解释a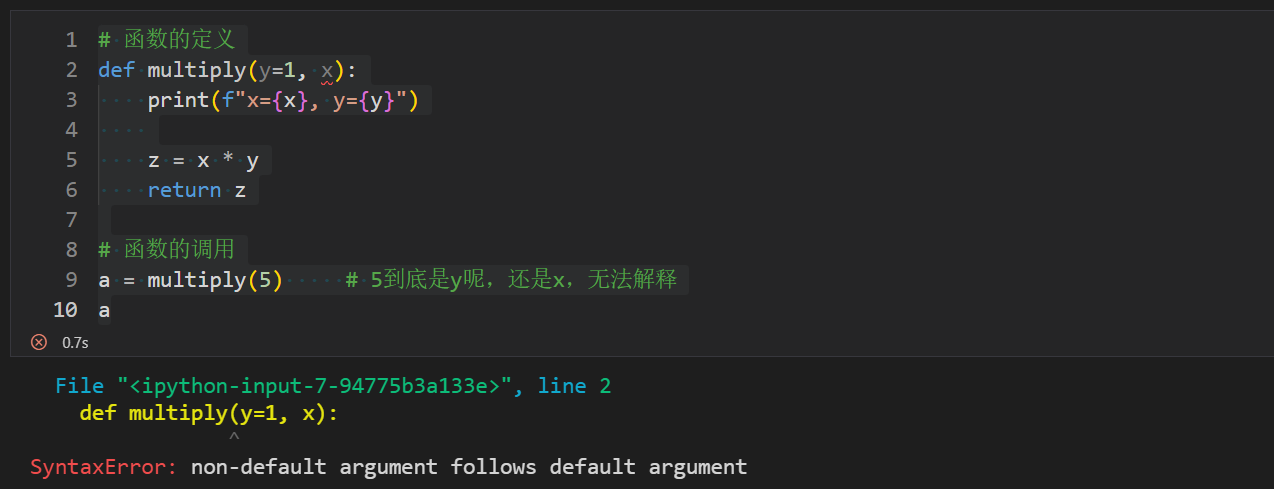
提示错误为:默认参数后跟着非默认参数。
- 默认参数定义时一定要使用不可变数据类型,否则结果可能会超出预期;
# 函数的定义def list_add(x=[]):"""参数x为默认参数,目的是没有参数传入时,返回一个[0]"""print(f"x={x}")x.append(0)return x# 函数的调用a = list_add() print("return:", a)a = list_add() print("return:", a)a = list_add() print("return:", a)# 输出x=[] return: [0] x=[0] return: [0, 0] x=[0, 0] return: [0, 0, 0]可以看到x的输入值发生了变化,第一次被调用时,x增加了一个[0],第二次作为输入时,已经不是[]了。
出现这种问题的原因是什么呢?
首先来看一下变量参数传递的机制:首先变量作为参数传递到函数中时,函数会产生一个变量的副本,在函数中对参数的操作,其实都是针对变量的副本的操作,举例说明:
# 函数的定义def echo(x):print(f"2.x = {x}, id(x):{id(x)}")# x的值在函数中已经发生了变化x = 6print(f"3.x = {x}, id(x):{id(x)}")return xk = 5print(f"1.k = {k}, id(k):{id(k)}")# 函数的调用a = echo(x = k) # 在函数外打印k的值,发现k的值没有发生变化print(f"4.k = {k}, id(k):{id(k)}")1.k = 5, id(k):140721390874496# k原始值和直接引用的对象地址2.x = 5, id(x):140721390874496# k作为参数传递给函数后,其值及直接引用的对象地址,发现没有变化3.x = 6, id(x):140721390874528# 在函数中修改参数,其值及直接引用的对象地址,发生了变化4.k = 5, id(k):140721390874496# 出函数后,发现k值没有发生变化从上面的结果可以看到,以不可变类型作为参数传递,其在函数内操作的其实是另外一个变量,在函数内对参数的修改不会影响到它的值。
而可变数据类型为参数传递时,虽然变量作为参数传递到函数中也会产生一个变量的副本,但是其是间接引用的,它们会间接引用到内存堆中同一个列表/字典对象,因此在函数中对可变数据类型的操作都会反馈到函数外的可变数据变量上。
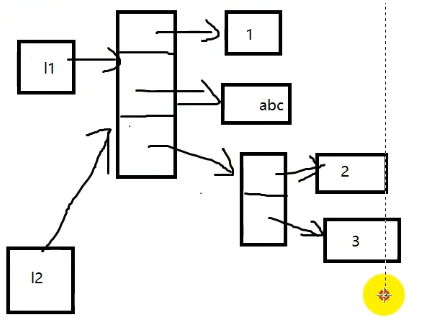
如何避免这种情况呢,默认参数使用不可变数据类型.
# 函数的定义def list_add(x=None):"""参数x为默认参数,目的是没有参数传入时,返回一个[0]"""print(f"x={x}")if x == None:x = [0]return x# 函数的调用a = list_add() print("return:", a)a = list_add() print("return:", a)a = list_add() print("return:", a)# 输出x=None return: [0] x=None return: [0] x=None return: [0]3.2.3 命名关键参数
命名关键参数主要体现在函数调用的时候:函数调用的时候,指定参数名的参数
调用函数时,命名关键参数可以和位置参数一起用,但是命名关键参数必须在位置参数的后面
另外在函数定义阶段,在关键字参数前增加一个”*”,表明后续的参数都是命名关键字参数,强制性必须按照命名关键字参数的用法使用,不可省略。
# 命名关键参数def multiply(x, *, y):# *号后面的是命名关键字参数, z = x * y return z# 函数的调用a = multiply(5, y=6)a# 输出30错误用法示例:命名关键参数在位置参数的前面
# 命名关键参数-错误用法def multiply(x, y): z = x * y return z# 函数的调用a = multiply(y=6, 5)a File "", line 8 a = multiply(y=6, 5)^SyntaxError: positional argument follows keyword argument提示语法错误:命名关键参数在位置参数的前面
3.2.4 可变参数
Python函数提供了可变参数,来方便进行参数个数未知时的调用。可变参数将以tuple形式传递。
格式: *参数 (即在参数前加*号)
def getsum(*num): sum = 0 for n in num: sum += n return sumlist = [2, 3, 4]print(getsum(1, 2, 3))print(getsum(*list))#结果:6 9序列的打包:当定义函数的时候,在函数参数的前面加 * ,将元素打包成元组的形式
序列的拆包:当函数执行的时候,在实际参数的前面加 * ,将序列进行拆包
def getsum(*num): # 参数序列的拆包 print(num) sum = 0 for n in num: sum += n return sumlist = [2, 3, 4]print(getsum(1, 2, 3))print(getsum(*list)) # 参数序列的打包#结果:6 9# 输出(1, 2, 3)6(2, 3, 4)# 对列表整个打包成元组作为参数传递进来93.2.5 关键参数
Python的可变参数以tuple形式传递,而关键字参数则是以dict形式传递。 即可变参数传递的是参数值,关键字参数传递的是参数名:参数值键值对。
形式:kw 这是惯用写法,建议使用,容易被理解
def personinfo(name, age, kw): print('name:', name, 'age:', age, 'ps:', kw) personinfo('Steve', 22)personinfo('Lily', 23, city = 'Shanghai')personinfo('Leo', 23, gender = 'male',city = 'Shanghai')3.2.6 各种参数之间组合
一次函数调用可以传递以上所述任何一种参数或者多种参数的组合,当然也可以没有任何参数。正如默认参数必须在最右端一样,使用多种参数时也对顺序有严格要求,也是为了解释器可以正确识别到每一个参数。
顺序:位置参数、默认参数、可变参数、命名关键字参数和关键字参数。
def function(a, b, c=0, *, d, kw): print(f'a = {a}, b ={b}, c = {c}, d = {d}, kw = {kw}')function(5, 6, d=36, e=99, f=27)a = 5, b =6, c = 0, d = 36, kw = {'e': 99, 'f': 27}4. 函数的注释
举个例子:
# 函数的定义def multiply(x, y): """函数注释:乘法的实现 Args: x (_type_): 乘数 y (_type_): 被乘数 Returns: _type_: 乘积 """ z = x * y return z# 函数的调用a = multiply(5, 6)a# 输出305. 匿名函数
当函数体非常简单,可以使用lambda来定义匿名函数,而不用def来定义函数
5.1 语法
lambda [arg1 [,arg2,.....argn]]:expression5.2 def函数和lambda表达式的区别
| def函数 | lambda表达式 | |
|---|---|---|
| 函数名 | 必须命名 | 匿名,无函数名 |
| 主体 | 代码块组合 | 仅支持一个返回值表达式 |
| 参数 | 位置、默认、命名关键、可变、关键参数 | 和def函数支持的一致 |
| 返回值 | 按需选择 | 函数对象,执行时返回表达式的值 |
| 使用场景 | 全场景 | 功能非常简单时,且仅少量调用的场景;可作为输入配合高阶函数使用 |
| 内存机制 | 建立函数时需要进行栈分配 | 无需变量,直接传递对象(也就是说无变量引用过程),用过即销毁 |
| 变量作用域 | 可以访问全局变量,函数内、外变量 | 仅可访问参数列表中的变量 |
举个例子:
- 函数def的实现
# 函数的定义def multiply(x, y): """函数注释:乘法的实现 Args: x (_type_): 乘数 y (_type_): 被乘数 Returns: _type_: 乘积 """ z = x * y return z# 函数的调用a = multiply(5, 6)a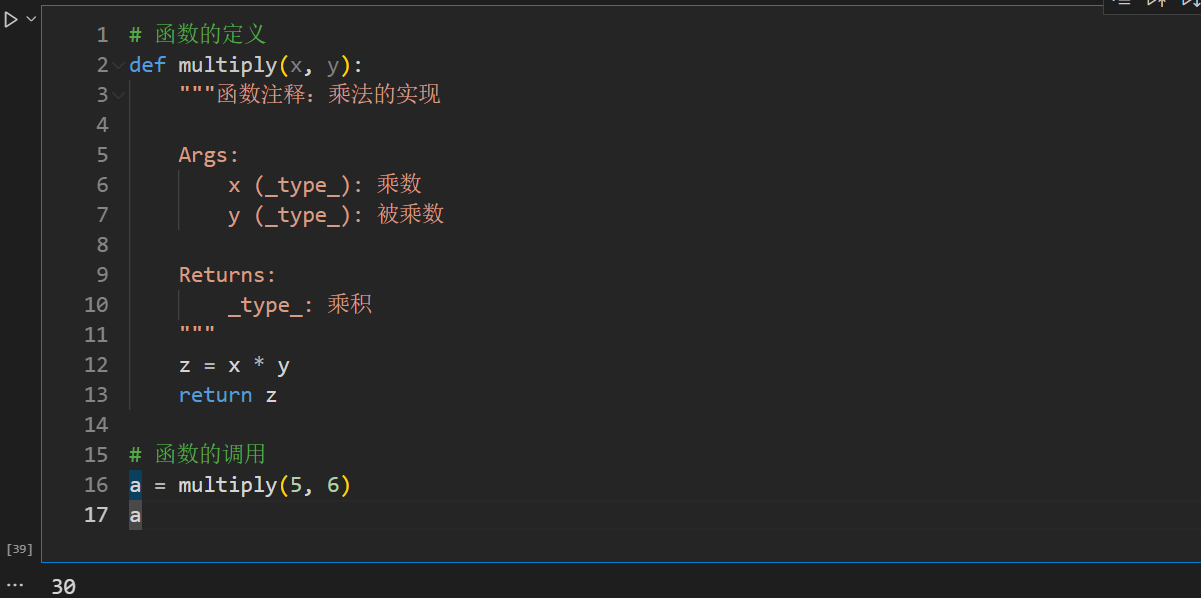
- lambda表达式的实现
f = lambda x, y: x*yf(5, 6)
6. 递归函数
To Iterate is Human, to Recurse, Divine.
——人类擅长迭代,而神掌控递归!有兴趣的可以看一下分形理论,你会发现世界惊人的相似。
递归是一种重要的思想,它将复杂问题不断地分成更小的相似的子问题,直到子问题可以用普通的方法解决,然后在子问题解决的基础上逐步解决上层的复杂问题。
递归就是有去(递去)有回(归来),从复杂问题出发,到达可解决的子问题(停止条件),然后再从停止条件返回解决上层复杂问题。
递归算法有三个重要的原则:
- 递归算法必须有停止条件(否则会无限循环)
- 递归算法必须改变其状态并向停止条件靠近(数据规模在减小)
- 递归算法必须递归地调用自己,找到函数的等价关系式
def mySum(n): # 结束条件:如果不加结束条件就会无限循环 if n == 1: # 函数的结束条件 print(f"mySum({n}) = {n}") return 1 # 继续递归 print(f"mySum({n}) = {n} + mySum({n-1})") return n + mySum(n-1)# 函数的等价关系式:mySum(n) = n + mySum(n-1)# 递归函数的调用mySum(100)mySum(100) = 100 + mySum(99)
mySum(99) = 99 + mySum(98)
…
mySum(4) = 4 + mySum(3)
mySum(3) = 3 + mySum(2)
mySum(2) = 2 + mySum(1)
mySum(1) = 1
5050
参考文章:
- 详解递归思想:https://wenku.baidu.com/view/4d3f014cbb4ae45c3b3567ec102de2bd9605de1d.html
7. 高阶函数
7.1 高阶函数定义
一个函数可以作为参数传给另外一个函数,或者一个函数的返回值为另外一个函数(若返回值为该函数本身,则为递归),满足其一则为高阶函数。
import timedef my_print(tag, x):# 自定义打印函数 t = time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(time.time())) print(f"[{tag}][{t}]{x}")def log(tag, x, f):# 日志函数 f(tag, x)# 调用日志函数:my_print函数作为参数传递给log函数使用,log函数就是高阶函数log("main_app", "program started!", my_print)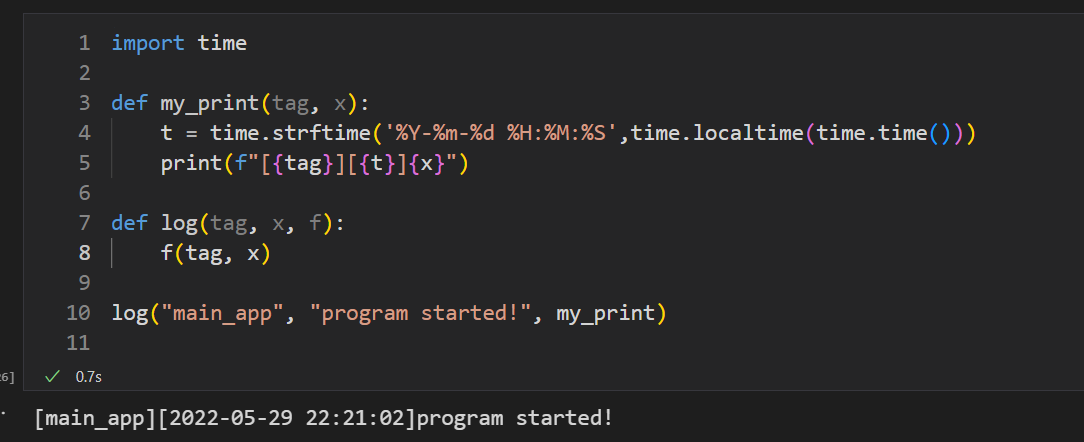
## 7.2 常用的高阶函数-
map
将迭代对象中的每一个元素都应用一下func,得到返回值,形成新的迭代对象
-
filter
过滤函数,按照函数将迭代对象中每一个元素都调用一次func方法,会得到True/False,如果True留下,如果是False丢弃
-
reduce
接收两个参数,把一个函数作用在一个序列上,reduce会把结果继续和序列的下一个元素做累计计算
-
sortby
如果指定了key,那么会根据key指定函数名,对每个元素使用函数,得到返回值,再根据返回值排序
7.2.1 map
map函数有2个参数:函数和迭代对象,返回值为map对象,其功能为将迭代对象中的每一个元素都应用一下func,得到返回值,形成新的迭代对象
举例:
假如国家发钱促进消费,每人发放1万元数字人民币。这里有张三、李斯、龙川三人的账户余额分别为10000,300,3210,那么实现代码为
7.2.1.1 常规def函数实现
X = [10000, 300, 3210]def giveout_momey(balance): return balance + 10000X2 = list(map(giveout_momey, X))# map返回值为map对象,用list将其展开X2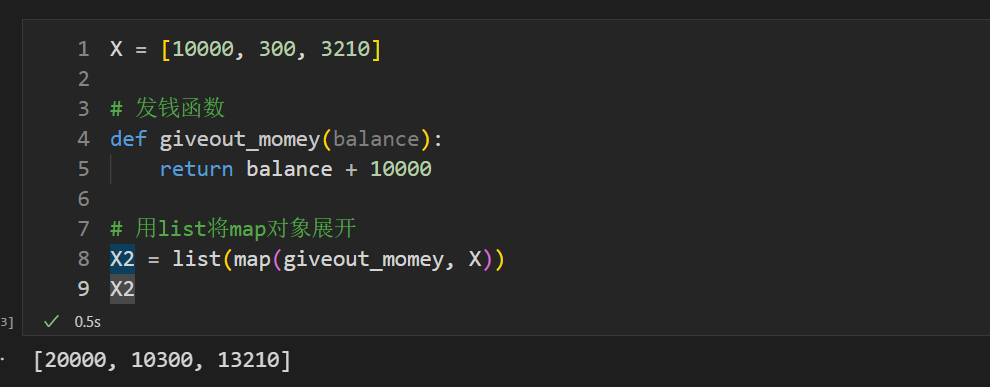
7.2.1.2 lambda表达式实现
giveout_money发钱函数很简单,可以使用lambda表达式来代替
# lambda表达式实现X = [10000, 300, 3210]X2 = list(map(lambda x:x+10000, X))X2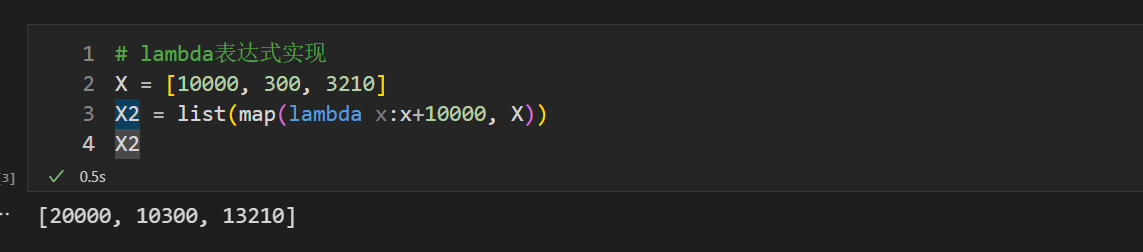
7.2.2 filter函数
过滤函数,按照函数将迭代对象中每一个元素都调用一次func方法,会得到True/False,如果True留下,如果是False丢弃
举例:挑出万元户
# 挑出万元户X = [10000, 300, 3210]list(filter(lambda x:x>=10000, X))
-
reduce
接收两个参数,把一个函数作用在一个序列上,reduce会把结果继续和序列的下一个元素做累计计算
from functools import reduceX = [10, 3, 2, 7, 9, 8]reduce(lambda x, y:x+y, [10, 3, 2, 7, 9, 8])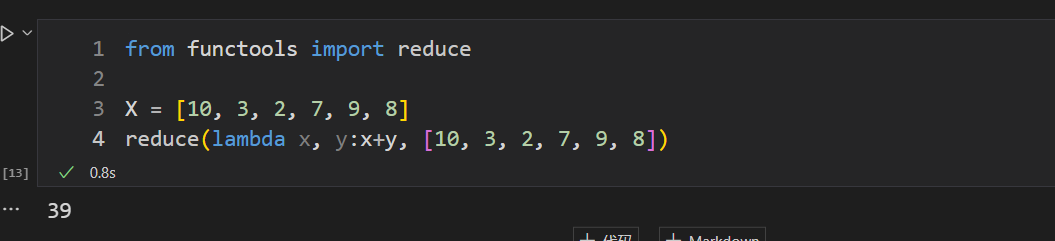
计算逻辑:先取10和3,求和后为13,然后再取后一个元素2,再做累加为15,再取后一个元素7…,直至累加完全部元素,最后返回一个值
7.2.3 sorted
如果指定了key,那么会根据key指定规则排序,对每个元素使用函数,得到返回值,再根据返回值排序,第三个参数为升序/倒序选项,返回值为排序后的可迭代对象
举例:对学生的科目成绩(语文、数学、英语)排序
X = [ ("lily", 100, 95, 66), # 姓名、语文、数学、英语 ("lucy", 99, 86, 100), ("zuck", 100, 69, 90), ("nick", 99, 86, 89)]# 排序规则def sort_rule(x): return x[1], x[2], x[3]# 升序排序reverse=Falsesorted(X, key=lambda x:(x[1], x[2], x[3]), reverse=True)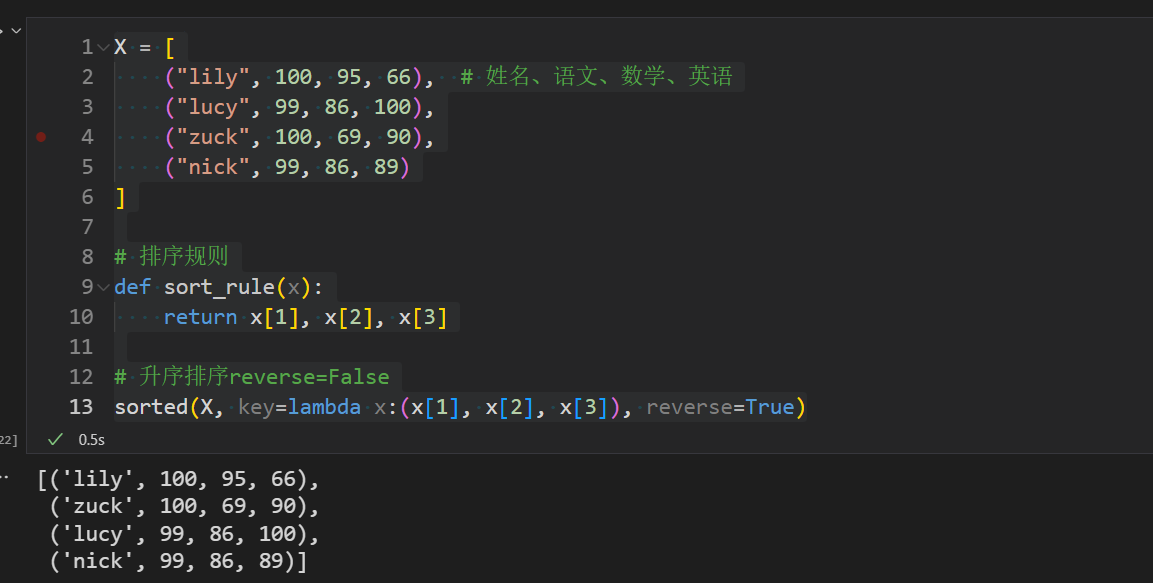
排序逻辑是按照语文、数学、英文的成绩来分组排序,先排语文,如果语文成绩一致,则再排数学,若数学一致则再排英语。
[(‘lily’, 100, 95, 66), # lily的语文成绩和zuck一样好,则继续排数学,lily数学比zuck小,因此lily排第1
(‘zuck’, 100, 69, 90), # zuck的语文成绩比nick和lucy都要好,因此zuck排第2
(‘lucy’, 99, 86, 100), # lucy的语文成绩和nick一样,则继续排数学,lucy的数学成绩和nick一样,则继续排英语,lucy的英语好于nick,则排第3
(‘nick’, 99, 86, 89)] # nick排最后
注意事项:此处lambda表达式的主体为(x[1], x[2], x[3]),为什么要加上小括号变成元组呢,因为lambda表达式仅支持一个表达式,变成元组后就符合lambda表达式的规则,否则就只能用def函数来实现。
参考链接:
- Python函数参数总结(位置参数、默认参数、可变参数、关键字参数和命名关键字参数)
《Python零基础快速入门系列》快速导航:
- Python快速入门系列(1) 人工智能序章:开发环境搭建Anaconda+VsCode+JupyterNotebook(零基础启动)
- Python快速入门系列(2)一文快速掌握Python基础语法
- Python快速入门系列(3)AI数据容器底层核心之Python列表
- Python快速入门系列(4)为什么内存中最多只有一个“Love“?一文读懂Python内存存储机制
- Python快速入门系列(5)Python只读数据容器:列表List的兄弟,元组tuple
- Python快速入门系列(6)字符串、列表、元组原来是一伙的?快看序列Sequence
推荐阅读:
- 物体检测快速入门系列(1)-Windows部署GPU深度学习开发环境
- 物体检测快速入门系列(2)-Windows部署Docker GPU深度学习开发环境
- 物体检测快速入门系列(3)-TensorFlow 2.x Object Detection API快速安装手册
- 物体检测快速入门系列(4)-基于Tensorflow2.x Object Detection API构建自定义物体检测器


