Python深度学习基础(七)——Python手动实现多层神经网络
根据之前的文章我们可以很容易的搭建出多层神经网络,下面我们以其中一种方式为例实现多层神经网络,推荐使用jupyter notebook
引入包
其中:
sklearn.datasets:用于生成数据集
sklearn.neural_network.MLPClassifier:用于生成数据集
numpy:数据批处理
matplotlib:画图
warnings.simplefilter:简单过滤器
from sklearn import datasetsimport numpy as npimport matplotlib.pyplot as pltfrom sklearn.neural_network import MLPClassifier #多层神经网络from warnings import simplefilter设置简单过滤器以及画图的字体和正负号
通过plt中的rcParams可以对plt画图进行设置
simplefilter(action='ignore', category=FutureWarning)plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来设置字体plt.rcParams['axes.unicode_minus']=False # 用来正常显示负号画图函数
生成二维的网格数据,通过数据的预测结果进行区域划分
def plot_decision_boundary(model, X, y): x0_min, x0_max = X[:,0].min()-1, X[:,0].max()+1 x1_min, x1_max = X[:,1].min()-1, X[:,1].max()+1 x0, x1 = np.meshgrid(np.linspace(x0_min, x0_max, 100), np.linspace(x1_min, x1_max, 100)) Z = model.predict(np.c_[x0.ravel(), x1.ravel()]) Z = Z.reshape(x0.shape) plt.contourf(x0, x1, Z, cmap=plt.cm.Spectral) plt.ylabel('x1') plt.xlabel('x0') plt.scatter(X[:, 0], X[:, 1], c=np.squeeze(y))基础层的实现
Layer类
# 定义一个layerclass Layer: def __init__(self): pass #前向计算 def forward(self, input): return input #反向传播 def backward(self, input, grad_output): passReLU激活函数
class ReLU(Layer): def __init__(self): pass def forward(self,input): return np.maximum(0,input) # relu函数为max(0,x) def backward(self,input,grad_output): relu_grad = input>0 #relu函数导数为1 if x>0 else 0 return grad_output*relu_gradSigmoid激活函数
# 定义Sigmoid层class Sigmoid(Layer): def __init__(self): pass def _sigmoid(self,x): return 1.0/(1+np.exp(-x)) def forward(self,input): return self._sigmoid(input) def backward(self,input,grad_output): sigmoid_grad = self._sigmoid(input)*(1-self._sigmoid(input)) return grad_output*sigmoid_gradTanh激活函数
class Tanh(Layer): def __init__(self): pass def _tanh(self,x): return np.tanh(x) def forward(self,input): return self._tanh(input) def backward(self, input, grad_output): grad_tanh = 1-(self._tanh(input))2 return grad_output*grad_tanhSoftMax激活函数
class SoftMax(Layer): def __init__(self): pass def _softmax(self,x): x_exp = np.exp(x) x_exp_sum = x_exp.sum(axis=1) return x_exp/x_exp_sum def forward(self,input): return self._softmax(input) def backward(self, input, grad_output): passDense层
__init__:初始化学习率,随机生成权值weights,将偏置biases置为0
forward:前向传递,输入和权值点乘再加上权值
backward:反向传递
class Dense(Layer): def __init__(self, input_units, output_units, learning_rate=0.5): self.learning_rate = learning_rate self.weights = np.random.randn(input_units, output_units)#初始化影响很大 self.biases = np.zeros(output_units) def forward(self,input): return np.dot(input,self.weights)+self.biases #重点中的重点,这个函数你读懂了,那神经网络你就彻底入门了。这个函数是我们神经网络,任督二脉! def backward(self,input,grad_output): grad_input = np.dot(grad_output, self.weights.T) grad_weights = np.dot(input.T,grad_output)/input.shape[0] grad_biases = grad_output.mean(axis=0) self.weights = self.weights - self.learning_rate*grad_weights self.biases = self.biases - self.learning_rate*grad_biases return grad_input多层神经网络的实现
这里以两层神经网络为例,隐藏层的激活函数常用relu,这里激活函数选用的全是sigmoid函数,其他激活函数可以自己试一下。
这个多层神经网络有2个输入,1个隐藏层(5个神经元),输出层神经元的个数,可以实现多分类
__init__:新建一个列表来存储层
forward:设置一个列表来存储每一层正向传递的值
predict:通过正向传递获取概率,如果大于阈值则为第1类,如果小于阈值则为第0类,这里设置的是0.5,也可以使用别的
predict_proba:正向传递的结果
_train:但轮次的训练
train:按照轮次数训练
class MLPClassifier(Layer): def __init__(self): self.network = [] self.network.append(Dense(2,5)) self.network.append(Sigmoid()) self.network.append(Dense(5,5)) self.network.append(Sigmoid()) def forward(self,X): self.activations = [] input = X for layer in self.network: self.activations.append(layer.forward(input)) input = self.activations[-1] assert len(self.activations) == len(self.network) return self.activations def predict(self,X): y_pred = self.forward(X)[-1] y_pred[y_pred>0.5] = 1 y_pred[y_pred<=0.5] = 0 return y_pred def predict_proba(self,X): logits = self.forward(X)[-1] return logits def _train(self,X,y): #先前向计算,再反向传播,梯度下降更新权重参数w,b self.forward(X) layer_inputs = [X]+self.activations logits = self.activations[-1] # 这里的损失函数需要自己定义 loss = np.square(logits - y.reshape(-1,5)).sum() loss_grad = 2.0*(logits-y.reshape(-1,5)) for layer_i in range(len(self.network))[::-1]: layer = self.network[layer_i] loss_grad = layer.backward(layer_inputs[layer_i],loss_grad) #grad w.r.t. input, also weight updates return np.mean(loss) def train(self, X, y): for e in range(1000): loss = self._train(X,y) print(loss) return self生成数据并画图
生成五种类别的数据并画图
x_train,y_train = datasets.make_blobs(n_samples=100, n_features=2, centers=5, cluster_std=1)plt.scatter(x_train[y_train==0,0],x_train[y_train==0,1])plt.scatter(x_train[y_train==1,0],x_train[y_train==1,1])plt.scatter(x_train[y_train==2,0],x_train[y_train==2,1])plt.scatter(x_train[y_train==3,0],x_train[y_train==3,1])plt.scatter(x_train[y_train==4,0],x_train[y_train==4,1])plt.show()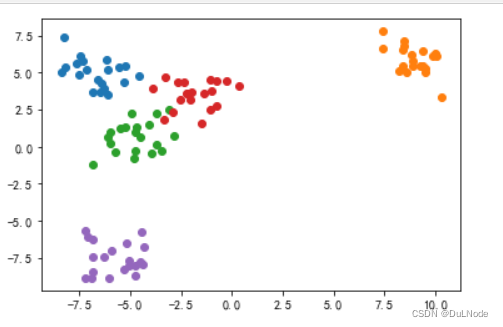
进行one_hot编码
借用sklearn进行one_hot编码
from sklearn.preprocessing import OneHotEncodery = OneHotEncoder().fit_transform(y_train.reshape(-1,1)).toarray()训练模型并画图
初始化并训练模型
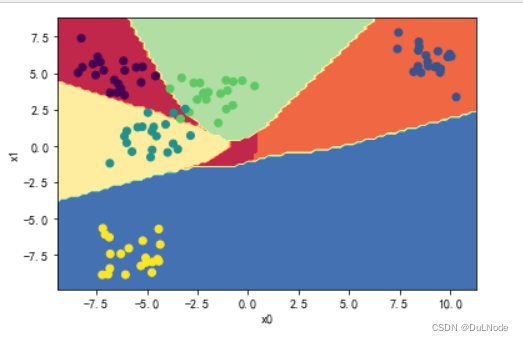
MLP = MLPClassifier().train(x_train,y)画图
from collections import Counterdef plot_decision_boundary(model, X, y): x0_min, x0_max = X[:,0].min()-1, X[:,0].max()+1 x1_min, x1_max = X[:,1].min()-1, X[:,1].max()+1 x0, x1 = np.meshgrid(np.linspace(x0_min, x0_max, 100), np.linspace(x1_min, x1_max, 100)) Z = model.predict(np.c_[x0.ravel(), x1.ravel()]) Z[Z[:,0]==1.0,0]=0 Z[Z[:,1]==1.0,0]=1 Z[Z[:,2]==1.0,0]=2 Z[Z[:,3]==1.0,0]=3 Z[Z[:,4]==1.0,0]=4 Z = Z[:,0].reshape(x0.shape) plt.contourf(x0, x1, Z, cmap=plt.cm.Spectral) plt.ylabel('x1') plt.xlabel('x0') plt.scatter(X[:, 0], X[:, 1], c=np.squeeze(y)) plot_decision_boundary(MLP,x_train,y_train)