数据结构与算法_06_跳表
数据结构与算法,系列文章传送地址,请点击本链接。
我们知道,在有序数组中,我们可以通过二分查找,通过O(logn)的时间复杂度快速查找数据,而链表只能从头节点逐一往后遍历。那么有没有一种数据结构能够支持链表的类二分查找效果呢?答案是肯定的,这就是我们今天要讲的,通过跳表来完成。
一、跳表是什么?
对于一个单链表来讲,即便链表中存储的数据是有序的,如果我们要想在其中查找某个数据,也只能从头到尾遍历链表。这样查找效率就会很低,时间复杂度会很高,是 O(n)。
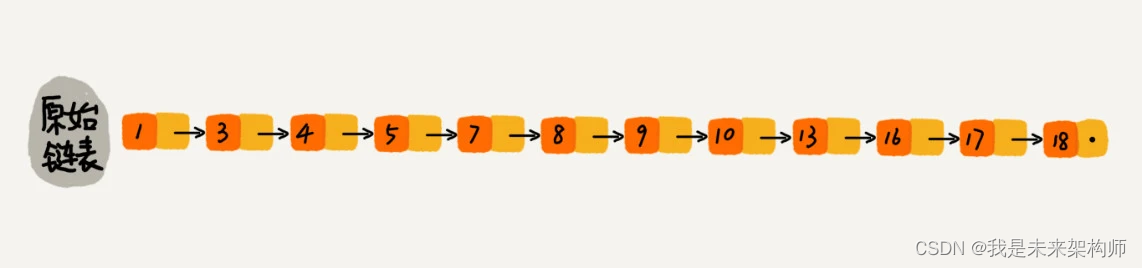
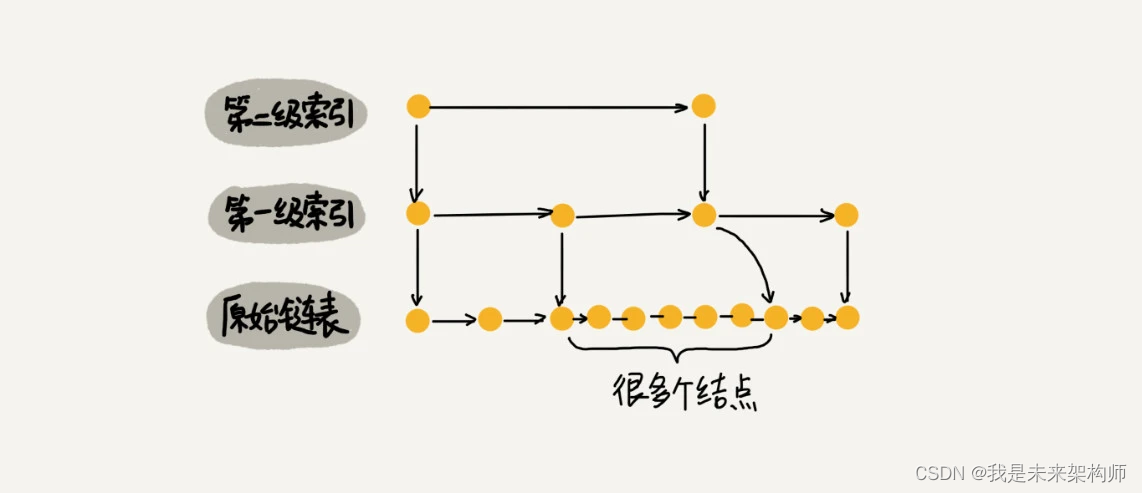
那怎么来提高查找效率呢?如果像图中那样,对链表建立一级“索引”,查找起来是不是就会更快一些呢?每两个结点提取一个结点到上一级,我们把抽出来的那一级叫做索引或索引层。
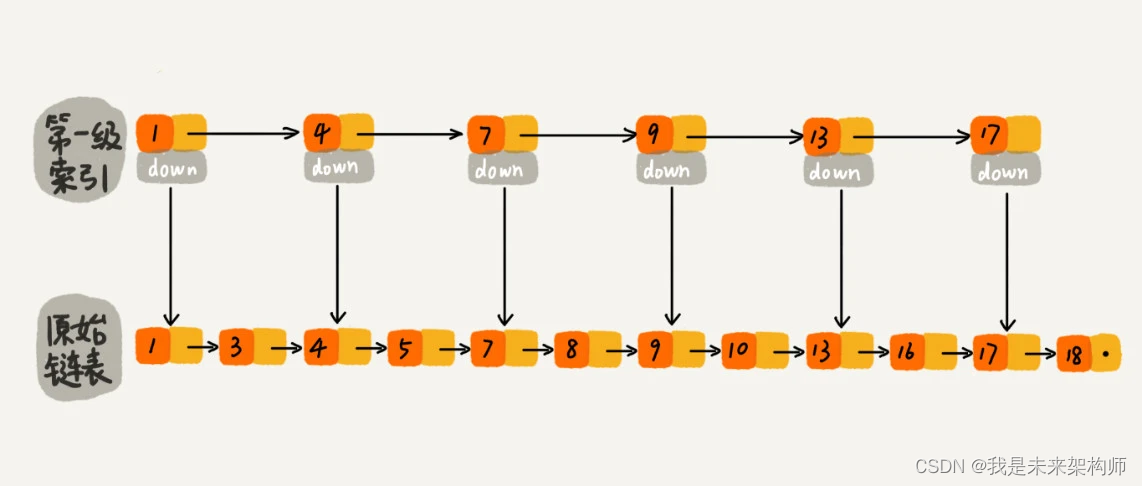
如果我们现在要查找某个结点,比如 16。我们可以先在索引层遍历,当遍历到索引层中值为 13 的结点时,我们发现下一个结点是 17,那要查找的结点 16 肯定就在这两个结点之间。然后我们通过索引层结点的 down 指针,下降到原始链表这一层,继续遍历。这个时候,我们只需要再遍历 2 个结点,就可以找到值等于 16 的这个结点了。这样,原来如果要查找 16,需要遍历 10 个结点,现在只需要遍历 7 个结点。
上面是增加一层索引减少的查找次数,如果增加多层,自然也就相应减少更多了。如下图,遍历到62,我们只需要查找11个节点
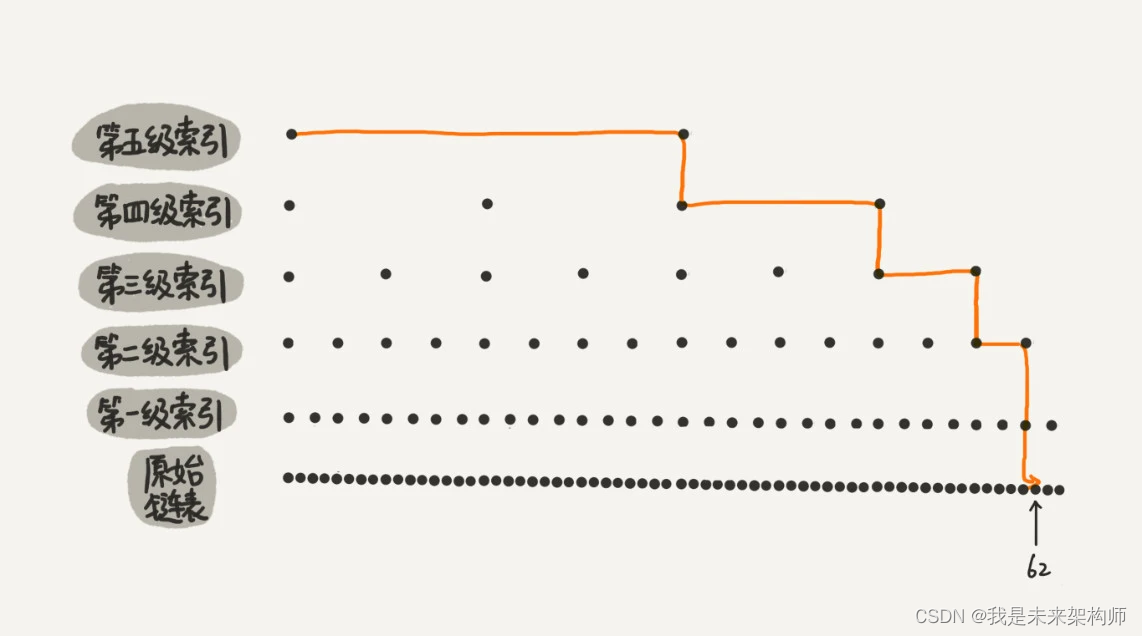
总结:这种链表加多级索引的结构,就是跳表
二、跳表时间复杂度分析
按照我们刚才讲的,每两个结点会抽出一个结点作为上一级索引的结点,那第一级索引的结点个数大约就是 n/2,第二级索引的结点个数大约就是 n/4,第三级索引的结点个数大约就是 n/8,依次类推,也就是说,第 k 级索引的结点个数是第 k-1 级索引的结点个数的 1/2,那第 k级索引结点的个数就是 n/(2k)。
假设索引有 h 级,最高级的索引有 2 个结点。通过上面的公式,我们可以得到 n/(2h)=2,从而求得 h=log2n-1。如果包含原始链表这一层,整个跳表的高度就是 log2n。我们在跳表中查询某个数据的时候,如果每一层都要遍历 m 个结点,那在跳表中查询一个数据的时间复杂度就是 O(m*logn)。
那这个 m 的值是多少呢?按照前面这种索引结构,我们每一级索引都最多只需要遍历 3 个结点,也就是说 m=3,为什么是 3 呢?我来解释一下。
假设我们要查找的数据是 x,在第 k 级索引中,我们遍历到 y 结点之后,发现 x 大于 y,小于后面的结点 z,所以我们通过 y 的 down 指针,从第 k 级索引下降到第 k-1 级索引。在第 k-1 级索引中,y 和 z 之间只有 3 个结点(包含 y 和 z),所以,我们在 K-1 级索引中最多只需要遍历 3 个结点,依次类推,每一级索引都最多只需要遍历 3 个结点。
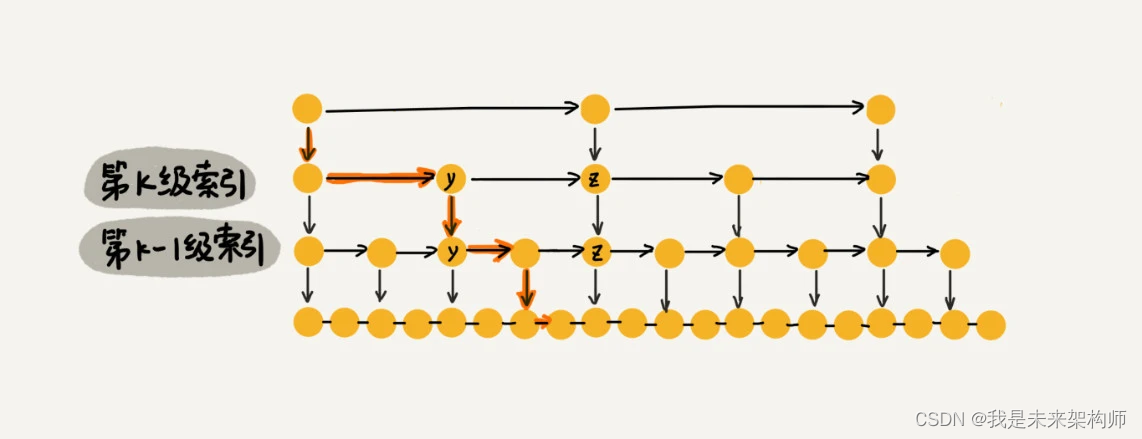
通过上面的分析,我们得到 m=3,所以在跳表中查询任意数据的时间复杂度就是 O(logn)。这个查找的时间复杂度跟二分查找是一样的。
三、跳表空间复杂度分析
跳表的空间复杂度分析并不难,我在前面说了,假设原始链表大小为 n,那第一级索引大约有 n/2 个结点,第二级索引大约有 n/4 个结点,以此类推,每上升一级就减少一半,直到剩下 2 个结点。如果我们把每层索引的结点数写出来,就是一个等比数列。
这几级索引的结点总和就是 n/2+n/4+n/8…+8+4+2=n-2。所以,跳表的空间复杂度是 O(n)。也就是说,如果将包含 n 个结点的单链表构造成跳表,我们需要额外再用接近 n 个结点的存储空间。
我们前面都是每两个结点抽一个结点到上级索引,如果我们每三个结点或五个结点,抽一个结点到上级索引。
示例,每三个节点建立索引,相应通过等比数列求和公式,总的索引结点大约就是 n/3+n/9+n/27+...+9+3+1=n/2。尽管空间复杂度还是 O(n),但比上面的每两个结点抽一个结点的索引构建方法,要减少了一半的索引结点存储空间。
实际上,在软件开发中,我们不必太在意索引占用的额外空间。在讲数据结构和算法时,我们习惯性地把要处理的数据看成整数,但是在实际的软件开发中,原始链表中存储的有可能是很大的对象,而索引结点只需要存储关键值和几个指针,并不需要存储对象,所以当对象比索引结点大很多时,那索引占用的额外空间就可以忽略了
四、高效的动态插入和删除
跳表这个动态数据结构,不仅支持查找操作,还支持动态的插入、删除操作,而且插入、删除操作的时间复杂度也是 O(logn)。这个主要体现了链表的优势,当知道相应的位置之后,只需要做对应的链接就行。
五、跳表索引动态更新
如果我们频繁操作跳表,比如在某个端插入大量的节点,那么跳表的索引效果会降低,极端情况会退化为链表。
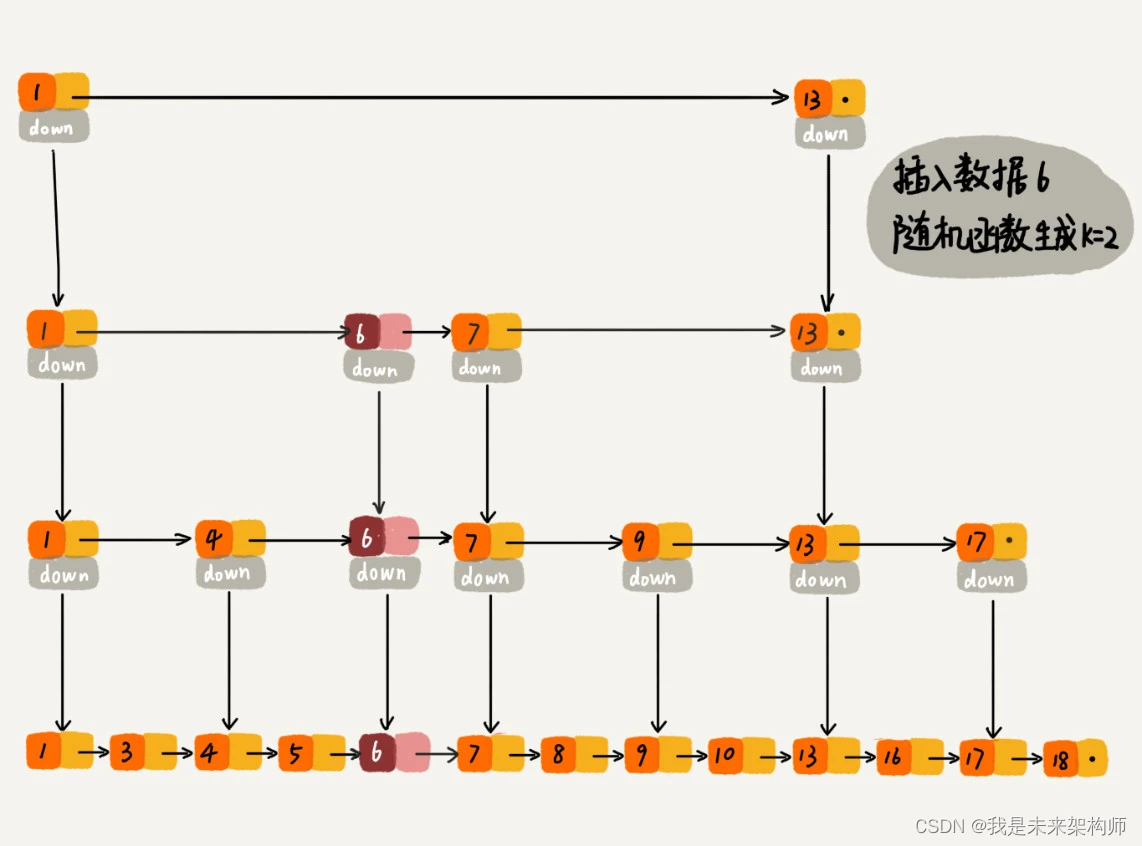
面对这个问题,跳表采用:随机函数来维护前面提到的“平衡性”。
我们通过一个随机函数,来决定将这个结点插入到哪几级索引中,比如随机函数生成了值 K,那我们就将这个结点添加到第一级到第 K 级这 K 级索引中。
六、跳表的应用场景
redis的有序列表就会使用到跳表作为底层的数据结构。经过有面试题会问,为什么redis有序表要用跳表,而不是红黑树?
要分析原因,那么我们得回到其使用的场景
1、插入一个数据;
2、删除一个数据;
3、查找一个数据;
4、按照区间查找数据(比如查找值在[100, 356]之间的数据);
5、迭代输出有序序列。
应对上面的场景,红黑树也可以做到O(logn)的时间复杂度。但是由于树的结构不太好顺序查找,因此,“按照区间查找数据(比如查找值在[100, 356]之间的数据)”使用跳表效率更高。对于按照区间查找数据这个操作,跳表可以做到 O(logn) 的时间复杂度定位区间的起点,然后在原始链表中顺序往后遍历就可以了。这样做非常高效。
除此之外,Redis 之所以用跳表来实现有序集合,还有其他原因,比如,跳表更容易代码实现。虽然跳表的实现也不简单,但比起红黑树来说还是好懂、好写多了,而简单就意味着可读性好,不容易出错。还有,跳表更加灵活,它可以通过改变索引构建策略,有效平衡执行效率和内存消耗。
声明:文章内容是极客时间专栏学习的学习笔记,会做简化或调整,欢迎大家留言和评论。
数据结构与算法,系列文章传送地址,请点击本链接。![]() https://blog.csdn.net/wanghaiping1993/article/details/125092448
https://blog.csdn.net/wanghaiping1993/article/details/125092448

