【开卷数据结构 】图的五大存储方式
目录
1.邻接矩阵
2.邻接表
3. 十字链表
4.邻接多重表
5.边集数组

1.邻接矩阵
图的邻接矩阵存储方式是用两个数组来表示图。一个一维数组 V 存储图中顶点信息,一个二维数组(称为邻接矩阵) A 存储图中的边或弧的信息
设 G=(V,E) 是具有n个顶点的图,顶点的顺序为(v0,v1 ,… ,vn-1),则G的邻接矩阵A:
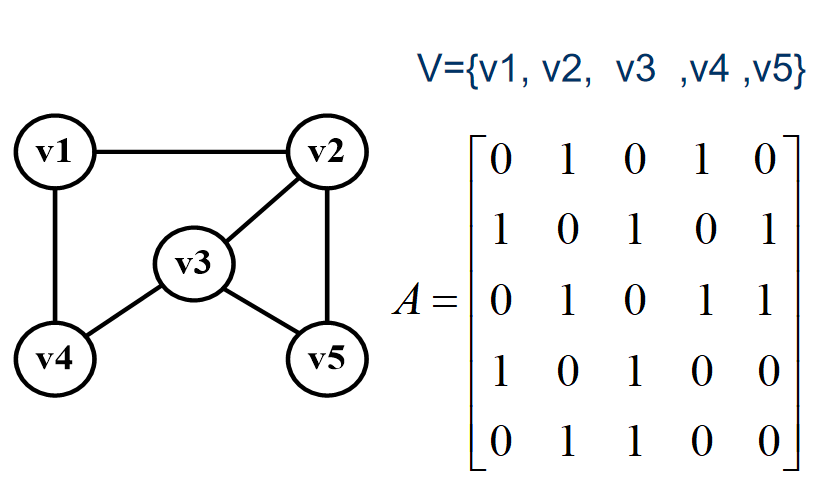
下图是一个无向图和它的邻接矩阵:
通过观察不难发现:
- 1)无向图的邻接矩阵是一个对称矩阵,且主对角线都为 0 。
- 2)我们要知道某个顶点的度,其实就是这个顶点 Vi 在邻接矩阵中第 i 行(或第 i 列)的元素之相。比如顶点 V1 的度就是 0+1+0+1+0=2 。
- 3)求顶点 vi 的所有邻接点就是将矩阵中第 i 行元素扫描一遍, A[i][j] 为 1 就是邻接点。
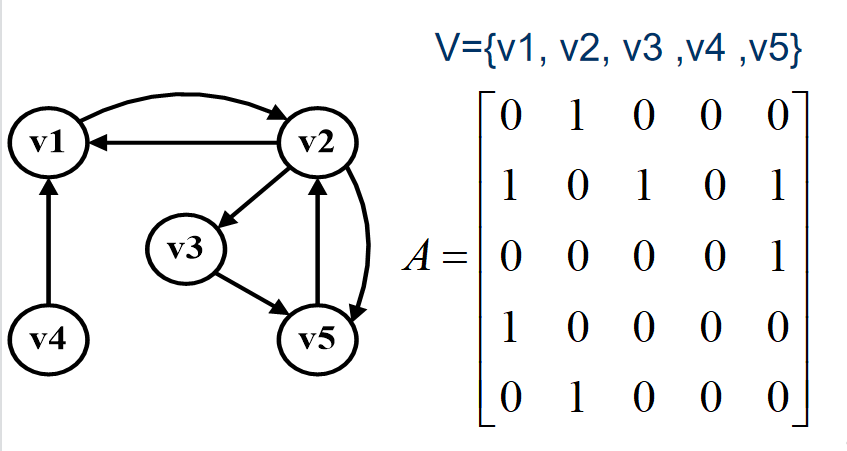
下图是一个有向图和它的邻接矩阵:
通过观察不难发现:
- 1)有向图的邻接矩阵不是一个对称矩阵,且主对角线都为 0 。
- 2)有向图讲究入度与出度,顶点 V1 的入度为 1 ,正好是第 V1 列各数之和。顶点 V1 的出度为 2,即第 V1 行的各数之和。
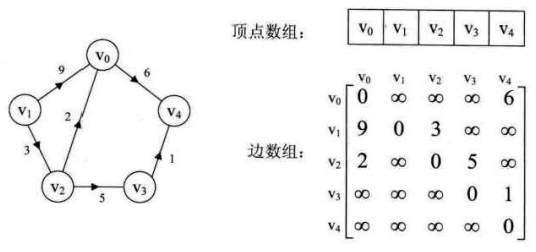
对于带权图来说,若顶点 Vi 和 Vj 之间有边相连,则邻接矩阵中对应项存放着该边对应的权值
下图是有向网图和它的邻接矩阵:
💬 代码演示
通过上文,我们可以定义出邻接矩阵的存储结构:
#define MAXNum 100 //顶点的最大值 typedef char VertexType; //顶点信息为字符类型typedef struct{VertexType Vex[MAXNum]; //顶点表 int arcs[MAXNum][MAXNum]; //邻接矩阵 int vexnum,arcnum; //顶点数和边数}MGraph;
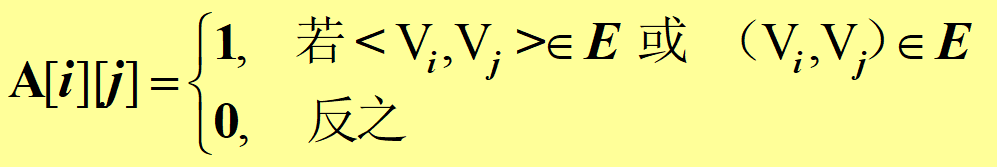


2.邻接表
当一个图为稀疏图时,使用邻接矩阵法显然要浪费大量的存储空间,图的邻接表法结合了序存储和链式存储方法,可以大大减少这种不必要的浪费。
邻接表的处理办法:
- 图中顶点用一个一维数组存储,当然也可以用单链表来存储。用数组可以较容易的读取顶点信息,更加方便。另外,对于顶点数组中,每个数据元素还需要存储指向第一个邻接点的指针,以便于查找该顶点的边信息。
- 图中每个顶点 vi 的所有邻接点构成一个线性表。由于邻接点的个数不定,所以用单链表存储,无向图称为顶点 vi 的边表,有向图则称为以 vi 为弧尾的出边表。
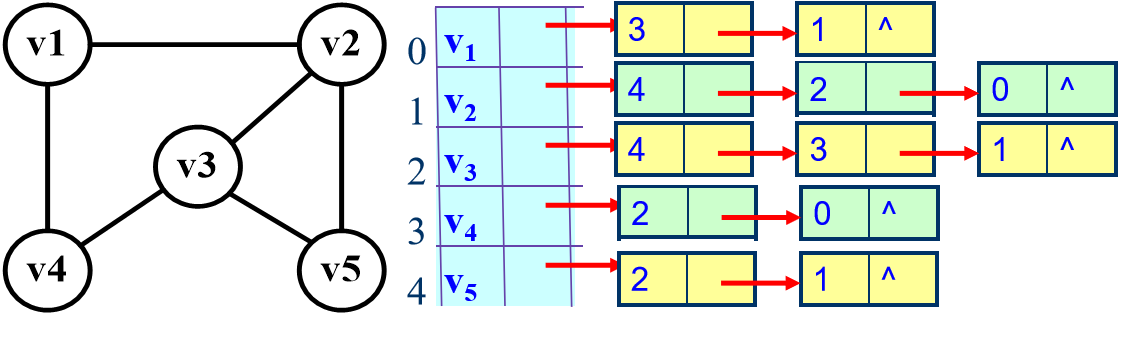
下图是一个无向图的邻接表结构:
邻接表存储的图具有的特点:
- 邻接表表示不唯一。取决于单链表的创建算法和边的输入次序。
- 对于无向图,邻接表的顶点 vi 对应的第i个链表的边结点数目正好是顶点 vi 的度。
- 对于有向图,邻接表的顶点 vi 对应的第 i 个链表的边结点数目仅是顶点 vi 的出度。入度为所有邻接点域为 i 的边结点的数目。
💬 代码演示
#define MAXVEX 100//图中顶点数目的最大值typedef char VertexType;typedef int EdgeType;//边表结点typedef struct EdgeNode{int adjvex; //该弧所指向的顶点的下标或者位置EdgeType weight; //权值,对于非网图可以不需要struct EdgeNode *next; //指向下一个邻接点}EdgeNode;//顶点表结点typedef struct VertexNode{Vertex data; //顶点域,存储顶点信息EdgeNode *firstedge //边表头指针}VertexNode, AdjList[MAXVEX];//邻接表typedef struct{AdjList adjList;int numVertexes, numEdges;//图中当前顶点数和边数}
3. 十字链表
十字链表是有向图的一种链式存储结构。
在十字链表中,对应于有向图的每条弧有一个结点,对应每一个顶点也有一个结点。
这些结点的结构如下图所示:
弧结点有五个域:尾域(tailvex)和头域(headvex)分别指示弧尾和弧头这两个结点在图中的位置。链域(hlink)指向弧头相同的下一条弧。链域(tlink)指向弧尾相同的下一条弧。info 域指向该弧的相关信息。
顶点结点中有三个域:data 域存放顶点相关的数据信息。firstin 和 firstout 两个域分别指向以该顶点为弧头或弧尾的第一个弧结点。
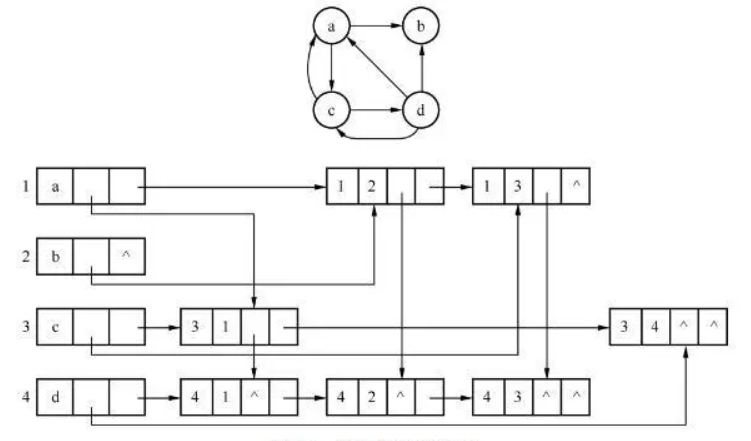
有向图的十字链表表示法如下图所示:
十字链表存储的图具有的特点:
- 在十字链表中很容易找到以 V1 为尾的弧,也容易找到以 V1 为头的弧,因而容易求得顶点的出度和入度。
- 图的十字链表表示不是唯一的。
💬 代码演示
#define MAXVEX 100 //图中顶点数目的最大值typedef char VertexType;typedef int EdgeType; //边表结点typedef struct EdgeNode{int adjvex; //该弧所指向的顶点的下标或者位置EdgeType weight; //权值struct EdgeNode *next; //指向下一个邻接点}EdgeNode;//顶点表结点typedef struct VertexNode{Vertex data; //顶点域,存储顶点信息EdgeNode *firstedge //边表头指针}VertexNode, AdjList[MAXVEX];//邻接表typedef struct{AdjList adjList;int numVertexes, numEdges;//图中当前顶点数和边数}

4.邻接多重表
邻接多重表是无向图的另一种链式存储结构。
在邻接表中,容易求得顶点和边的各种信息,但在邻接表中求两个顶点之间是否存在边而对边执行删除等操作时,需要分别在两个顶点的边表中遍历,效率较低。
与十字链表相似,在临界多重表中,每条边用一个结点表示,其结构如下图所示:
其中,mark 为标志域,可用以标记该条边是否被搜索过;ivex 和 jvex 为该边依附的两个顶点在图中的位置;liink指向下一条依附于顶点 ivex 的边;jlink 指向下一条依附于顶点 jvex 的边,info 为指向和边相关的各种信息的指针域。
每个顶点也用一个结点表示,其结构如下图所示:
其中,data 域存储该顶点的相关信息,firstedge 域指示第一条依附于该顶点的边。
Q:邻接多重表和邻接表有什么区别
A:在邻接多重表中,所有依附于同一顶点的边串联在同一链表中,由于每条边依附于两个顶点,因此每个边结点同时链接在两个链表中。对无向图而言,其邻接多重表和邻接表的差别仅在于,同一条边在邻接表中用两个结点表示,而在邻接多重表中只有一个结点。
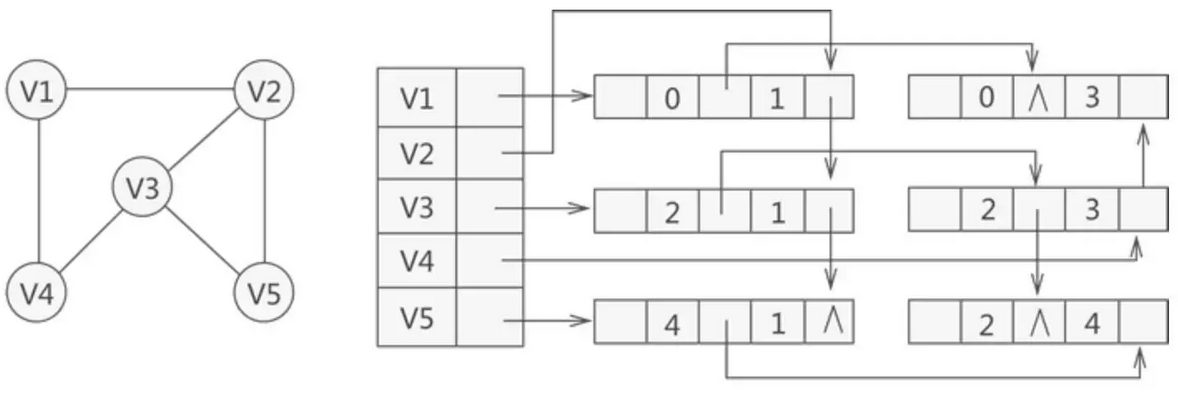
无向图的邻接多重表表示法如下图所示:
邻接多重表的各种基本操作的实现和邻接表类似。


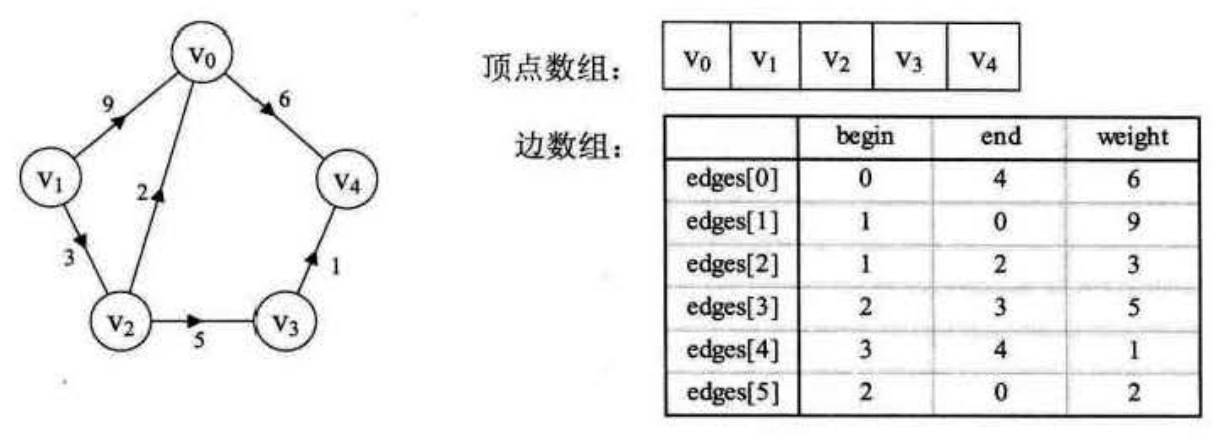
5.边集数组
边集数组是由两个一维数组构成。一个是存储顶点的信息;另一个是存储边的信息。边数组每个数据元素由一条边的起点下标 (begin), 终点下标 (end) 和权 (weight) 组成,如下图所示:
显然边集数组关注的是边的集合,在边集数组中要查找一个顶点的度需要扫描整个边数组,效率并不高。因此它更适合对边依次进行处理的操作,而不适合对顶点相关的操作。