JVM学习记录-字符串常量池
学习宋红康老师和深入理解java虚拟机中关于String的理解和笔记,如下是自己的学习整理和理解,如果有理解错误望指正
文章目录
1.字符串常量池
字符串常量池的位置
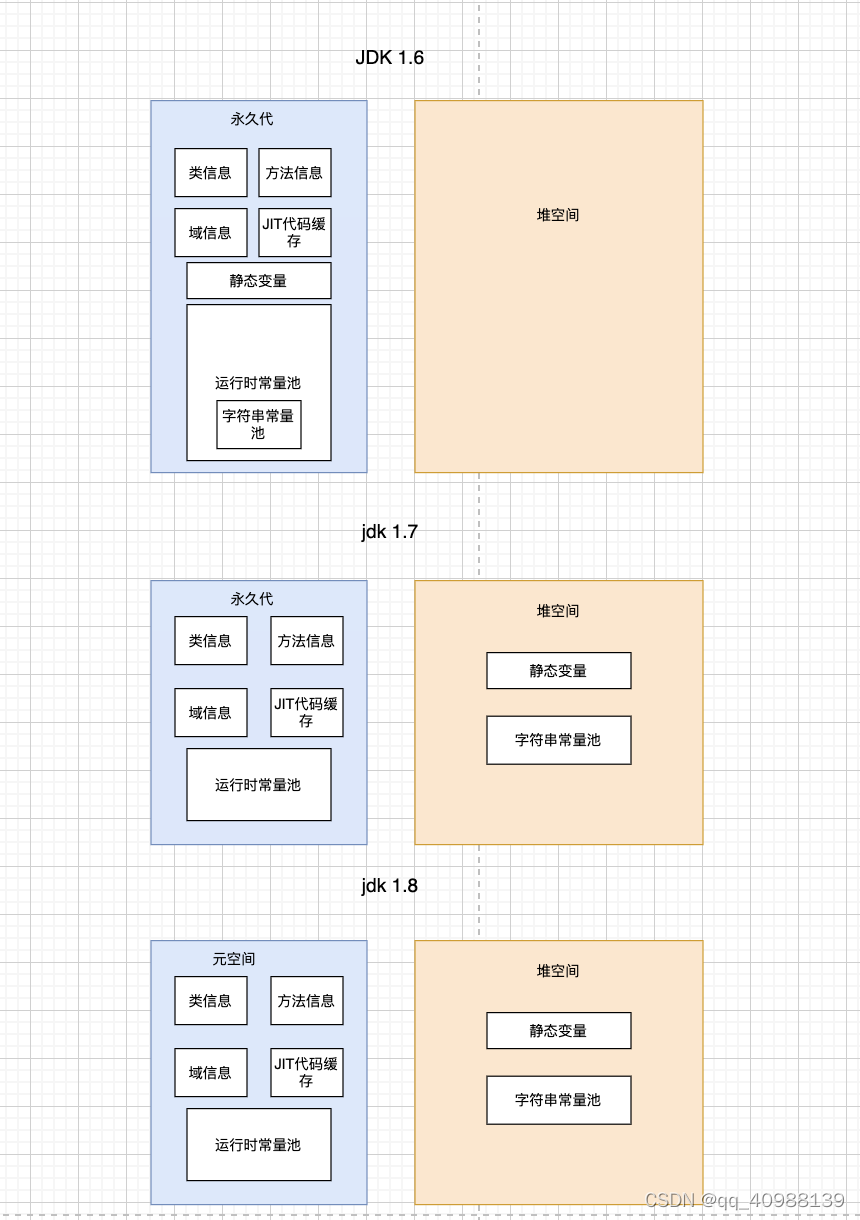
jdk1.6:字符串常量池是存在于堆空间之外的
jdk1.7 / jdk 1.8:字符串常量池移入了堆中
字符串常量池即String pool是一个固定大小的HashTable,可通过设置设置参数 -XX:StringTableSize设置StringTable的长度,jdk 1.6时该字符串常量池的数组长度默认为1009,jdk1.7开始默认长度为60013,且参数最小不可低于1009;
自行测试通过在1.8环境下将-XX:StringTableSize调整为1000会出现错误如下:

字符串常量池的哈希表结构
为侧面证明字符串常量池是一个哈希表结构,编写了如下代码:
public class TestJvmString5 { public static void main(String[] args) { long start = System.currentTimeMillis(); for (int i = 0; i < 1000000; i++) { // valueOf底层是调动 interger的toString ,interger的toString是通过 new String(buf, true);实现的 // 通过调用intern方法确保将字符串能够放入字符串常量池 String s = String.valueOf(i).intern(); } System.out.println("代码耗时:"+ (System.currentTimeMillis() - start)); }}测试结果如下:
-XX:StringTableSize = 1009时:代码耗时:5812
-XX:StringTableSize = 1000000是:代码耗时:182
通过耗时可以看到,因为调大数组的长度在哈希表结构中会大大降低hash冲突,将元素添加到哈希表的耗时会降低,所以从侧面印证了字符串常量池是哈希表结构
案例代码分析
通过分析如下代码加深了自己对字符串常量池的理解:
public class TestJvmString2 { public static void main(String[] args) { TestString2 ts2 = new TestString2(); System.out.println(ts2.str); System.out.println(ts2.chars); changes(ts2.str,ts2.chars); System.out.println(ts2.str); System.out.println(ts2.chars); } public static void changes(String s,char[] chars) { s = "2"; chars[0] = 'b'; }}class TestString2 { String str = "1"; char[] chars = {'t','e','s','t'};}这段代码的输出为:

一开始不容易理解为什么ts2.str仍然没有发生改变,后来自己通过这段时间的学习和认知通过画图分析了上述代码(如下图),在changes方法中通过改变s的值对ts2对象中str的引用产生不了影响:
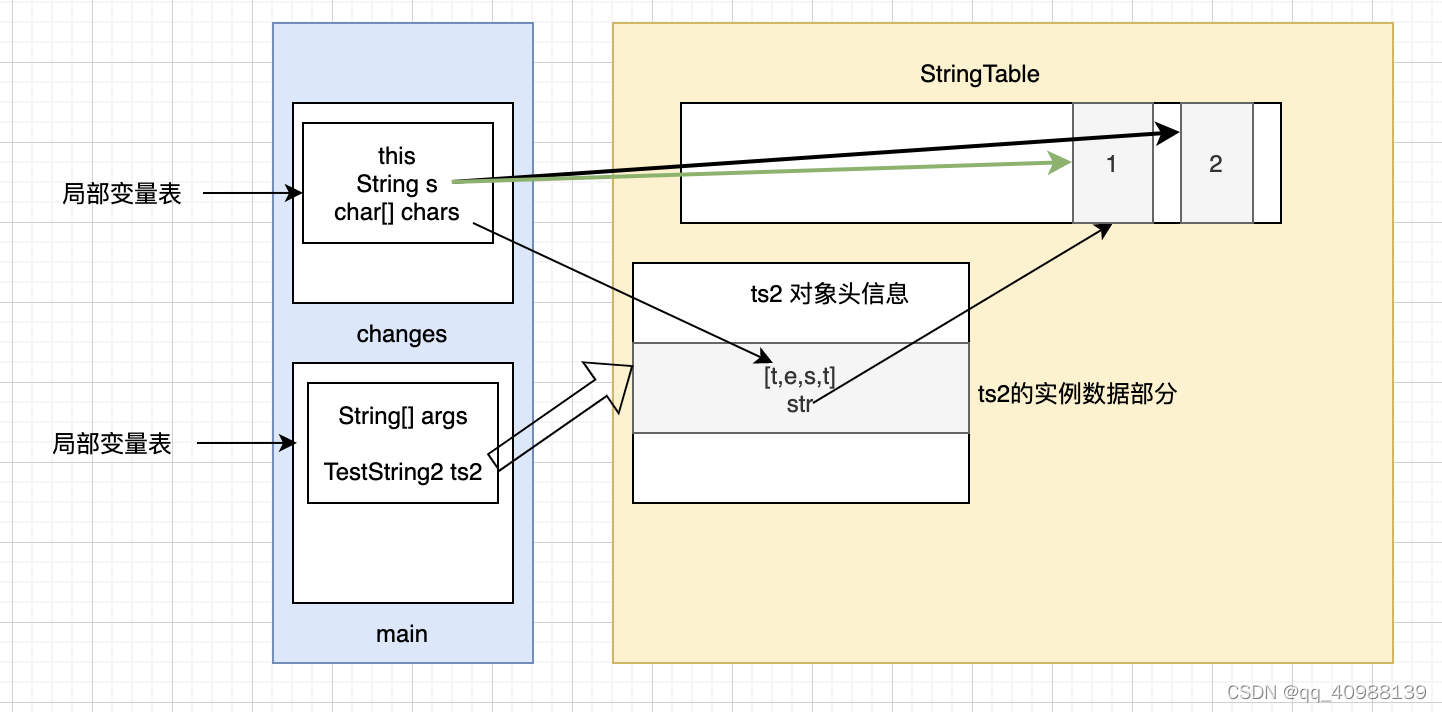
2.通过new String()和""创建字符串的区别
通过"“直接赋值只会在字符串常量池中创建字符串,如果字符串常量池存在,则不会创建;通过new String(”")会产生一或者两个字符串对象,如果字符串常量池存在则只在堆中创建一个字符串对象,如果字符串常量池不存在则在字符串常量池和堆中都各创建一个字符串对象。
通过如下代码帮助理解:
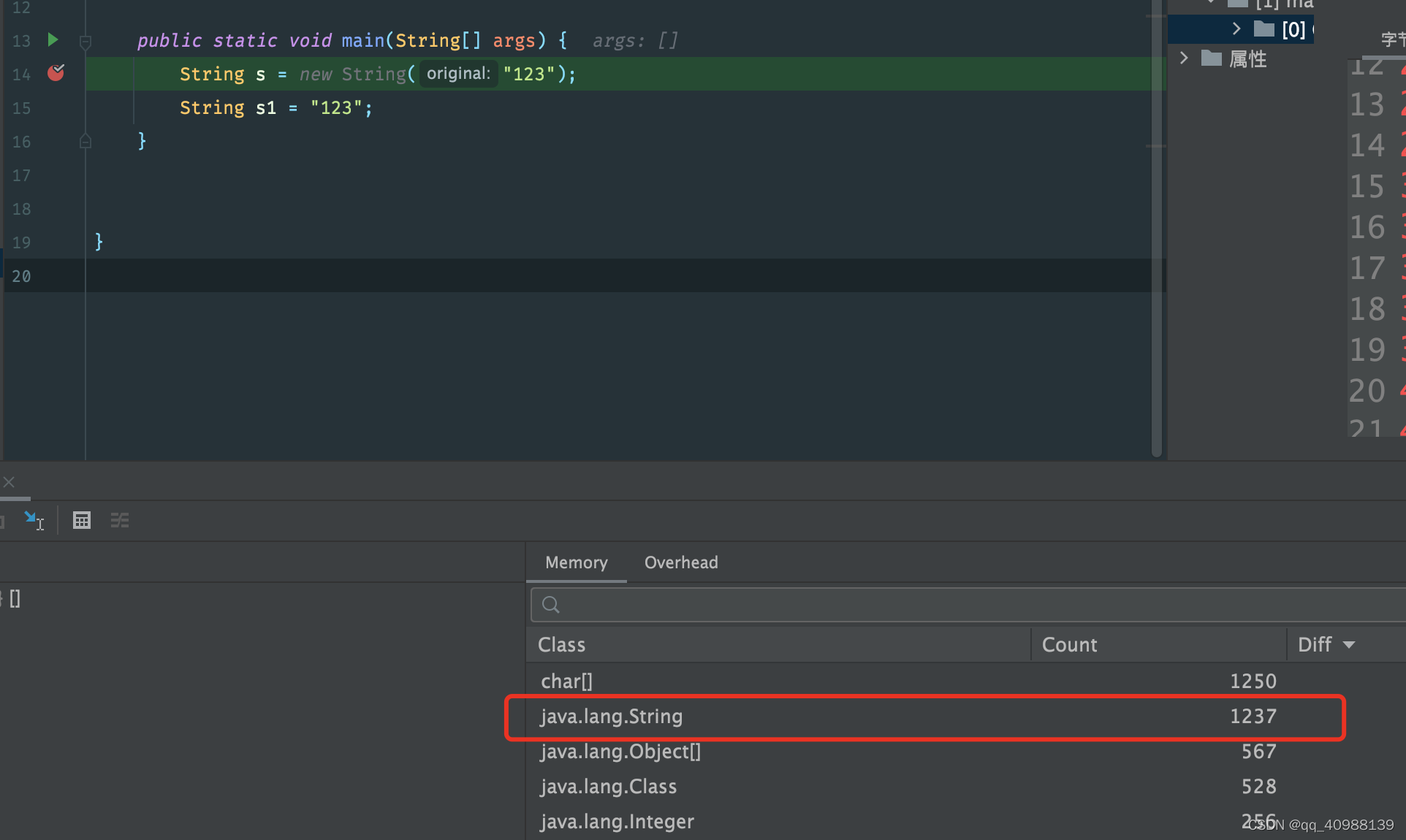
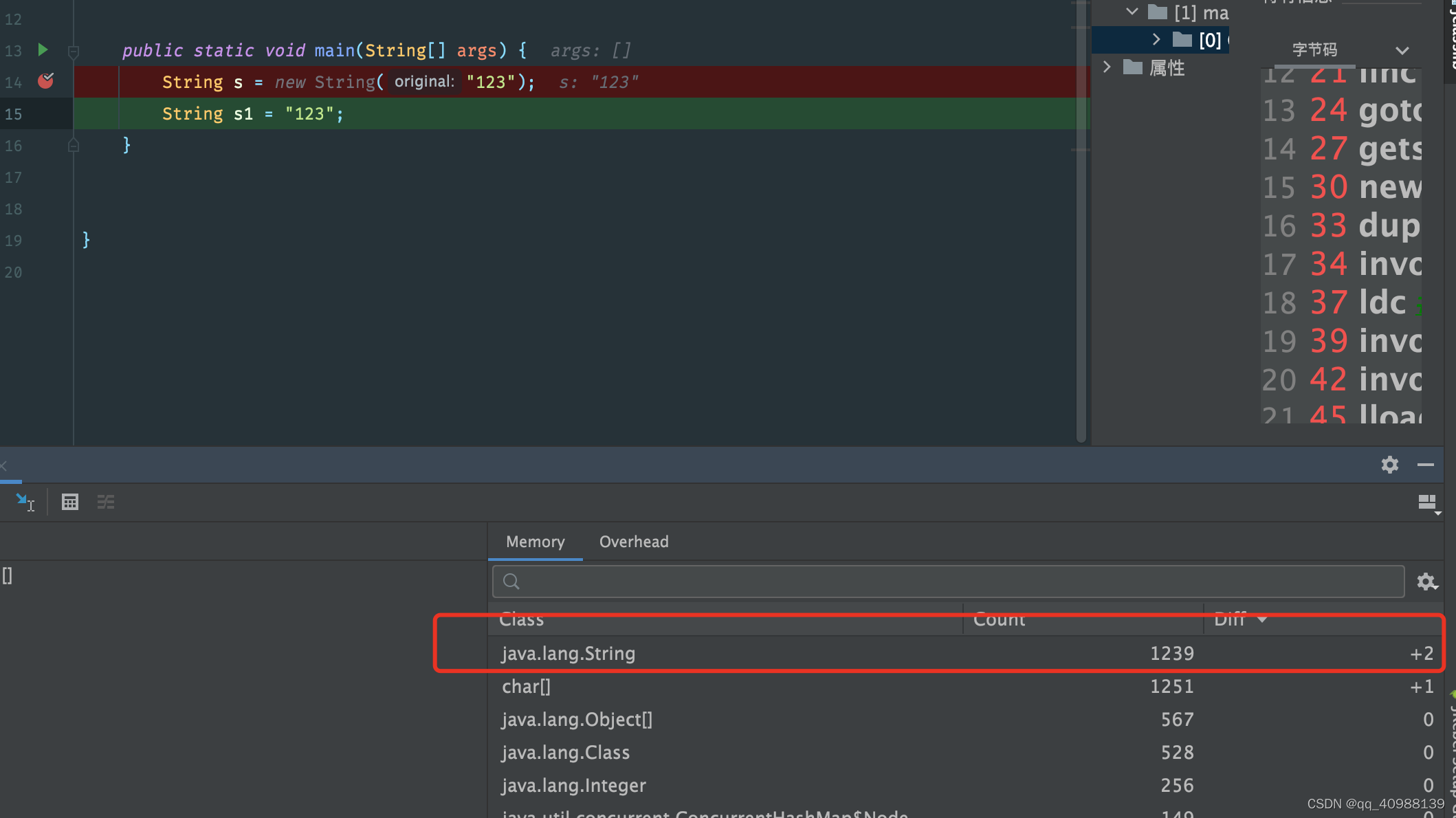
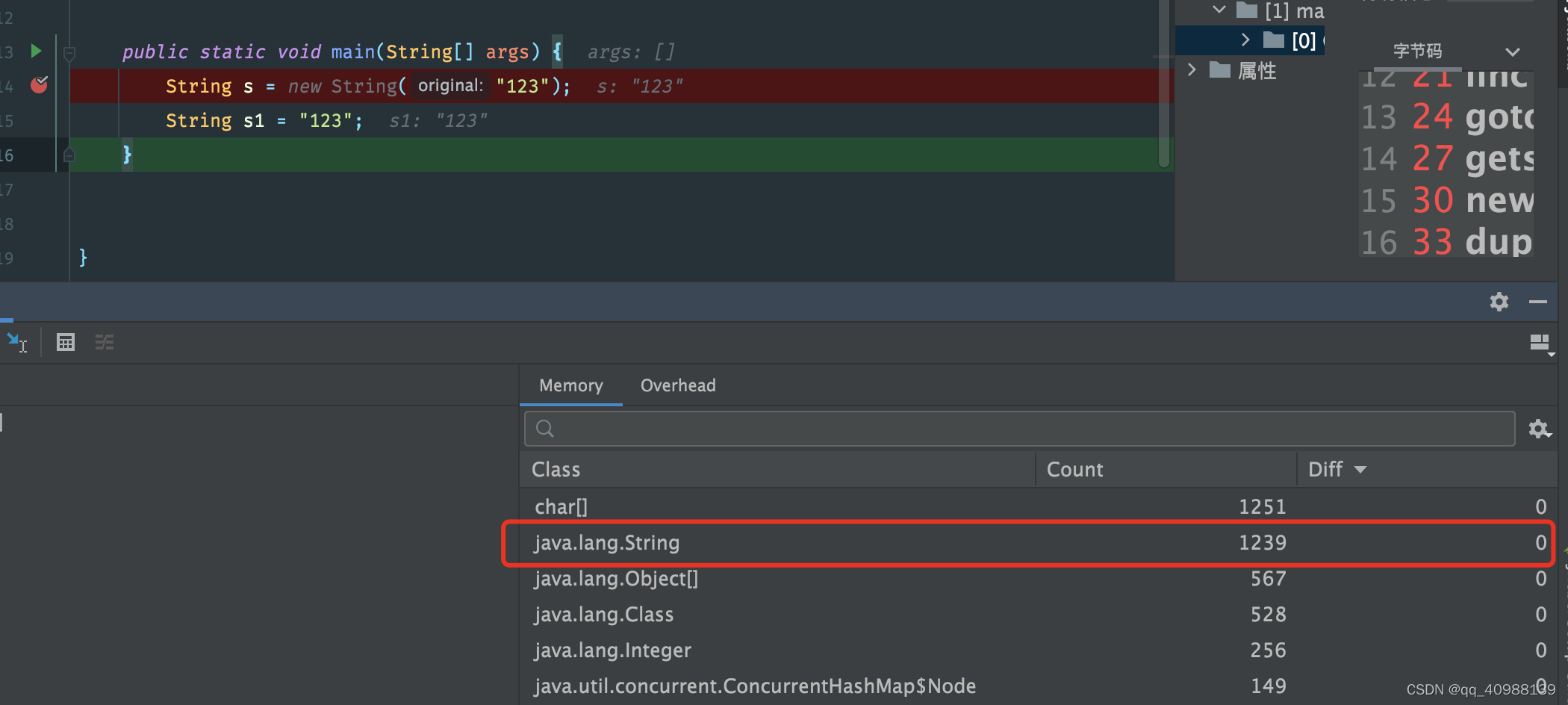
分析:还未执行new String的时候是1237个String对象,当执行了new String(“123”)操作之后,增加了两个String对象;当执行完代码String s1 = "123"后,观察到String对象的数量并没有增加;
3.字符串拼接的细节
先看代码
public static void testNewStr2() { String s1 = "a"; String s2 = "b"; String s3 = "a" + "b"; String s4 = "ab"; String s5 = s1 + "b"; System.out.println(s3 == s4); System.out.println(s3 == s5); System.out.println(s3 == s5.intern());}打印结果为:
true
false
true
打开testNewStr2方法观察其字节码指令
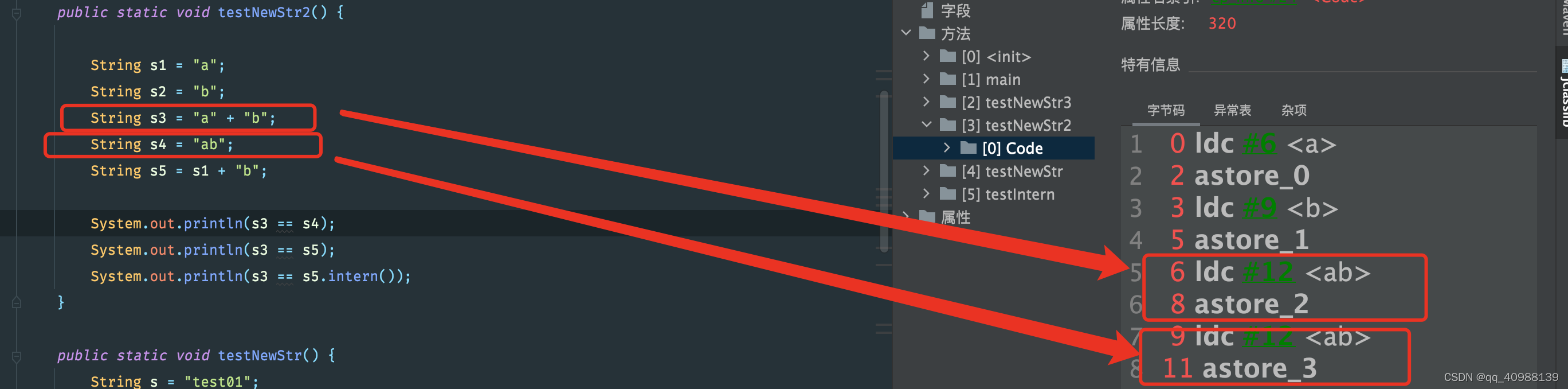
String s3 在编译器已经被优化成了String s3 = "ab"和 s4并无区别,那么s3==s4自然都是从常量池获取,即为true;然后我们再观察String s5的相关拼接操作:
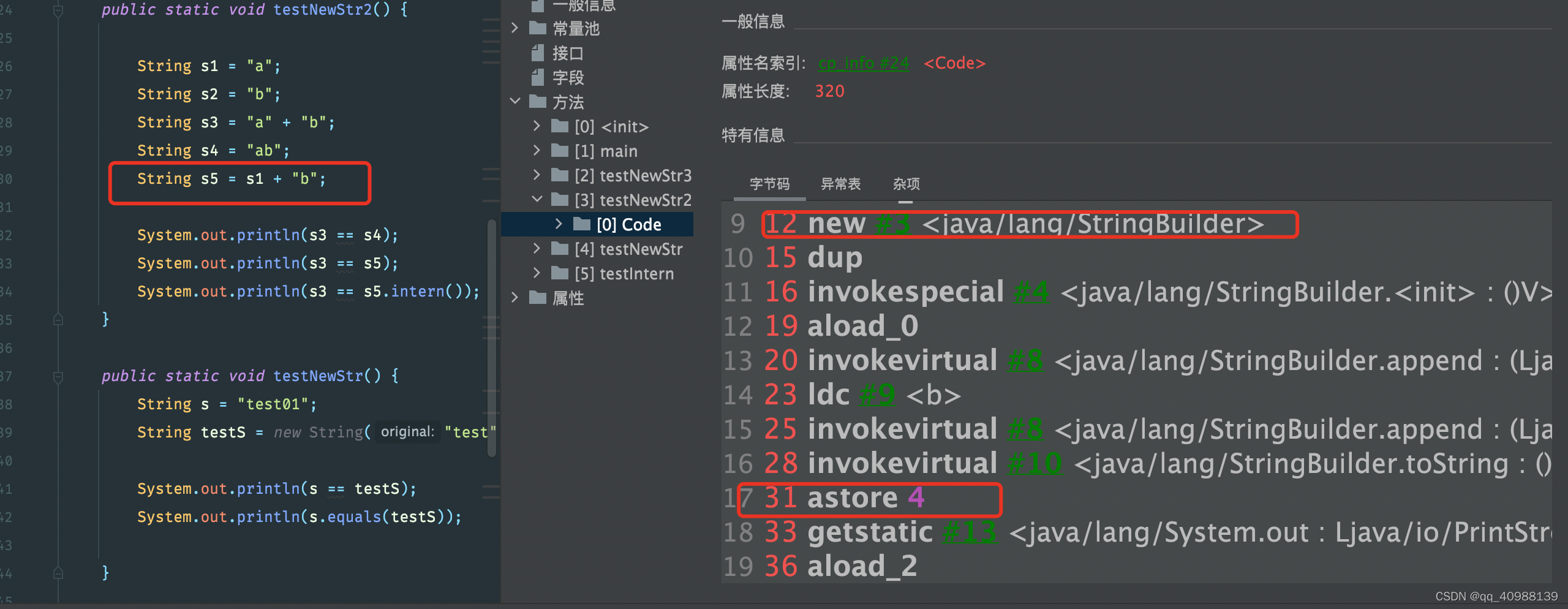
分析:对于s5的操作对应着字节指令中12行到31行的相关操作,可以看到对于变量s1 + “b"的操作是先在堆中创建一个StringBuilder对象,然后调用stringbuilder的init构造方法初始化,然后将局部变量表的索引为0的数据加载到操作数栈的栈顶,然后调用append方法将栈顶元素出栈进行拼接,然后从字符串常量池中取出字符串b入栈顶,然后调用append方法拼接字符串"b”,最后调用toString方法(toString方法底层是通过new String()实现的),再将变量放入局部变量表下标为4的位置。所以,通过变量名拼接字符串会先创建一个StringBuilder,然后再在堆中创建了一个String对象,所以s5是在堆中而不在字符串常量池里;那么s3 == s5 结果必然是false;
问题:String s = new String(“a”) + new String(“b”) 会创建几个对象;
1.一个StringBuilder对象
2.如果字符串常量池不存在"a",则会在堆和字符串常量池各创建一个String对象,
3.如果字符串常量池不存在"b",则会在堆和字符串常量池各创建一个String对象,
4.最后调用StringBuilder的toString 会在堆中创建一个为"ab"的String对象(注意此时常量池中是不会创建“ab”的)
4.关于intern方法
intern方法:当调用 intern 方法时,如果字符串常量池中已经包含一个等于该 String 对象的字符串,通过equals方法确定,则返回池中的字符串。否则,将此 String 对象添加到池中并返回对该 String 对象的引用。
上述是intern方法源码中的注释, 通过看上述方法最后一句可能会产生些误导;例如:“当字符串在字符串常量池中不存在时,则添加到池中并返回该字符串的引用”,在jdk1.6时,确实是这样,但在jdk1.7和jdk1.8时,当字符串在字符串常量池中不存在时,却是在字符串常量池中存储该字符串在堆中的引用地址 ,例如下面这一段代码:
public static void main(String[] args) { String s = new String("a") + new String("b"); //这一段代码结束字符串常量池中还未产生"ab" String s1 = s.intern(); //在字符串常量池中存储s在堆中的引用 String s2 = "cd"; //在字符串常量池中生成字符串"cd" String s3 = new String("c") + new String("d"); //在堆中创建一个为"cd"的字符串对象 String s4 = s3.intern(); //确认"cd"在字符串常量池是否存在,存在则返回在字符串常量池中的字符串对象 System.out.println(s1 == s); //s和s1指向的内存地址一样 System.out.println(s3.equals(s4)); System.out.println(s3 == s4); //可以发现,虽然内容相同但是内存地址并不相同}运行结果为:
true
true
false
画了个图帮忙自己理解(箭头整的不好看)
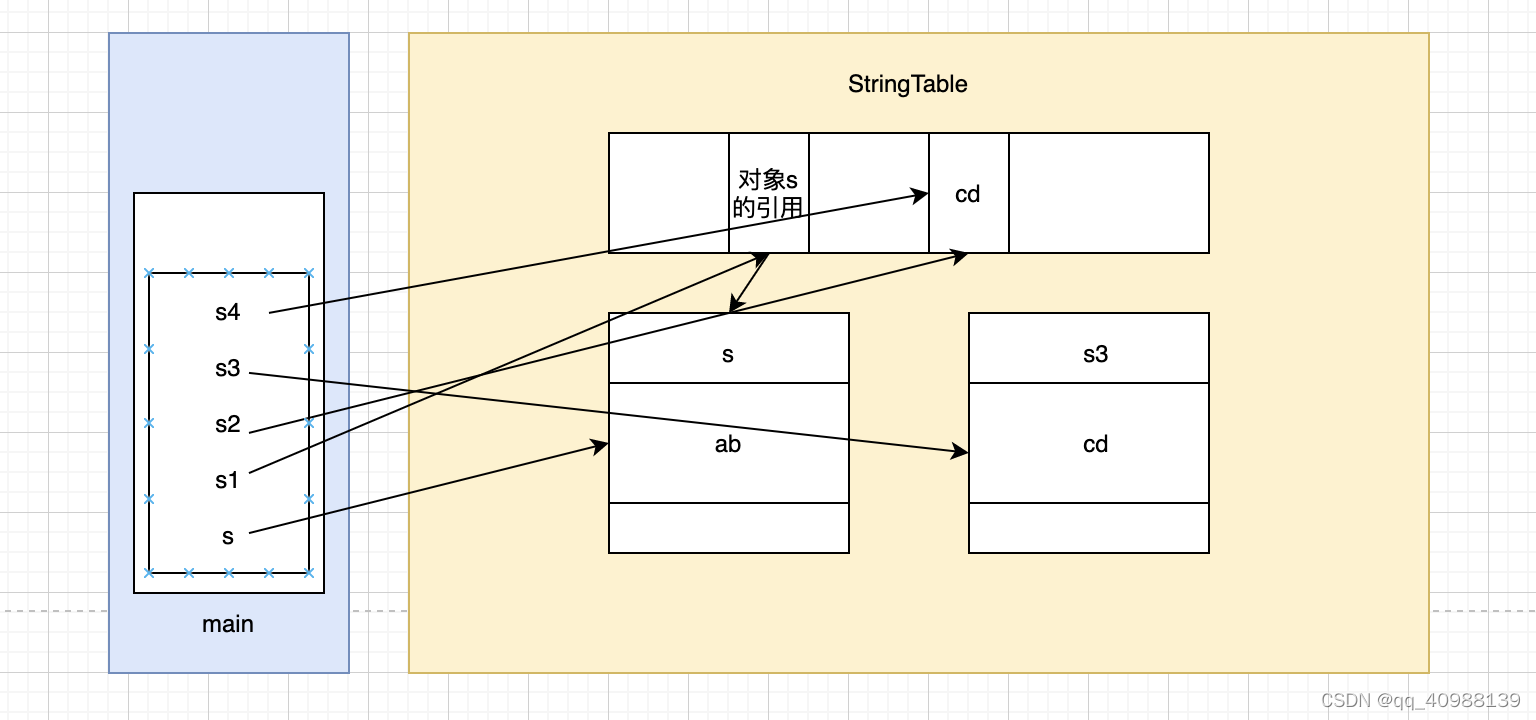
总结: 如果该字符串在字符串常量池尚未存在的,调用intern方法在jdk1.7和jdk1.8会在字符串常量池中是保存的地址而不是再创建一个;而如果该字符串在调用intern方法之前在字符串常量池中就已经存在,则调用intern方法返回的是字符串常量池中的字符串对象;

