【函数式编程实战】(四)流-Stream API原理解析

前言:
📫 作者简介:小明java问道之路,专注于研究计算机底层,就职于金融公司后端高级工程师,擅长交易领域的高安全/可用/并发/性能的设计和架构📫
🏆 Java领域新星创作者、阿里云专家博主、华为云享专家🏆
🔥 如果此文还不错的话,还请👍关注、点赞、收藏三连支持👍一下博主哦
本文导读
集合是java中使用最多的数据结构,我们如何处理大量元素就是个问题,多线程(线程池)+迭代器性能是还可以,但是太麻烦,也不利于开发和管理,并发的问题还要考虑,这个时候为了保证java的流行性,或者说为了不让java淘汰,在高版本搞出来 流(Stream)。
一、集合与流
集合是java中使用最多的数据结构,包括List、Map,面向对象编程更像是面向集合面向数据结构编程,当我们要处理大量元素的时候,往往会使用多线程,多线程还不能直接创建,要使用线程池创建,麻烦的一批(Java开发规范);
我们如何处理大量元素就是个问题,多线程(线程池)+迭代器性能是还可以,但是太麻烦,也不利于开发和管理,并发的问题还要考虑,这个时候为了保证java的流行性,或者说为了不让java淘汰,在高版本搞出来 流(Stream)。
流(Stream)是声明式处理集合的,我们可以把他当做一个高级的 迭代器+多线程容器,他不能简单理解为一个 流 数据结构,集合(List、Map)可以增删改查,虽然流可以实现诸如过滤、合并,分组等等操作,但是其元素是 按需计算,这其实是一种生产者-消费者模式,流就像一个 正在创建的集合,他会按要求变化后计算值。
下面三段代码,for循环遍历list + if、list转迭代器 + if、等同逻辑
// for + if List orderAmt = new ArrayList(); for (OrderInfo orderInfo : orderInfos) { if (orderInfo.getOrderAmt().compareTo(BigDecimal.ZERO) > 0) { orderAmt.add(orderInfo.getOrderAmt()); } } // 迭代器 + if Iterator it = orderInfos.iterator(); while (it.hasNext()) { OrderInfo orderInfo = it.next(); if (orderInfo.getOrderAmt().compareTo(BigDecimal.ZERO) > 0) { orderAmt.add(orderInfo.getOrderAmt()); } } // Stream流 + Lambda表达式 List collect = orderInfos.stream() .filter(orderInfo -> orderInfo.getOrderAmt().compareTo(BigDecimal.ZERO) > 0) .map(orderInfo -> orderInfo.getOrderAmt()).collect(Collectors.toList());二、什么是流
流是Java 高版本的API,是声明式处理集合的,声明式(简洁)就是说我想要做什么而不是如何实现,把他当做一个高级的 迭代器(可复合-灵活)+多线程容器(可并行-性能好)
要了解流是什么,还要了解他的定义、类路径、如何使用,以及一些使用规范
流在 java.util.stream.Stream 接口中定义,我们可以看到接口注释中有大量讲解,我们就根据这些注释学习流
我们看源码,该类里面有大量方法接口(就和集合一样),可以访问元素,但是集合是数据结构,所以他主要目的是使用特定算法和数据结构存储/访问元素;但流的目的是计算。Stream 流的接收元素是泛型,流会使用一个数据源(这个数据源流不会改变顺序)
注释中说了,1、流是懒加载原则;仅当 端操作启动时才对源数据执行计算,并且仅在需要时消耗源元素;2、流不会改变原有的数据源;3、流只操作一次;4、可能会抛出 IllegalStateException;5、流不需要被关闭;6、流是内部迭代。详细论证我们放到下面
三、流的使用原则
流使用包括3件事,要有数据源来执行操作,要有一个链这个链试试中间操作的步骤,一个终端操作生成结果。下面代码会论证 这些原则以及上述原理
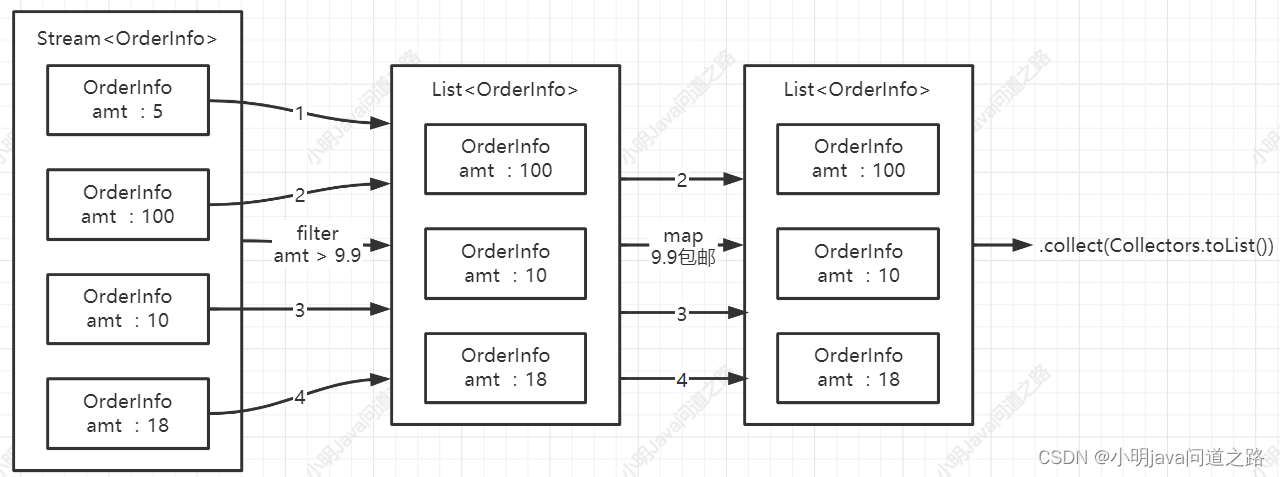
流只能遍历一次,且是按顺序遍历(流是按顺序遍历的,不会一个List都过滤完,才map,而是每个元素都是流水线执行的)
// 流是按顺序遍历的,不会一个List都过滤完,才map,而是每个元素都是流水线执行的List collect = orderInfos.stream().filter(orderInfo -> { System.out.println("===filter" + orderInfo.getOrderAmt()); return orderInfo.getOrderAmt().compareTo(BigDecimal.ZERO) > 0;}).map(orderInfo -> { System.out.println("===map" + orderInfo.getOrderAmt()); return orderInfo.getOrderAmt();}).collect(Collectors.toList());System.out.println(collect);// 流只能操作一次,当再次使用的时候会报错IllegalStateException:operated upon or closedStream stream = collect.stream();stream.forEach(System.out::print);System.out.println("===========");stream.forEach(System.out::print);
流, java.util.stream.Stream 接口中定义 很多方法,这些方法分为 两大类。filter、map、limit、forEach、peek 等,可以连成流水线;collect 触发流水线执行并关闭(终端操作)。我们把连接起来称为中间操作,关闭流的称为终端操作。一个流的使用原则就是要有数据源、中间操作、终端从操作
四、流的运行原理
为什么Stram流、Lamda表达式式写法又叫作函数式编程?一是调用手法像是函数一般,只须传入参数即可调用;二是Lamda实现方式为生出静态函数调用而成
下图执行步骤标号 1 2 3 4,那流是如何 解决 Stream流水线的?
Stream中用某种实例化后的PipelineHelper来代表Stage,将具有先后顺序的各个Stage连到一起,就构成了整个流水线。跟Stream相关类和接口的继承关系图示。
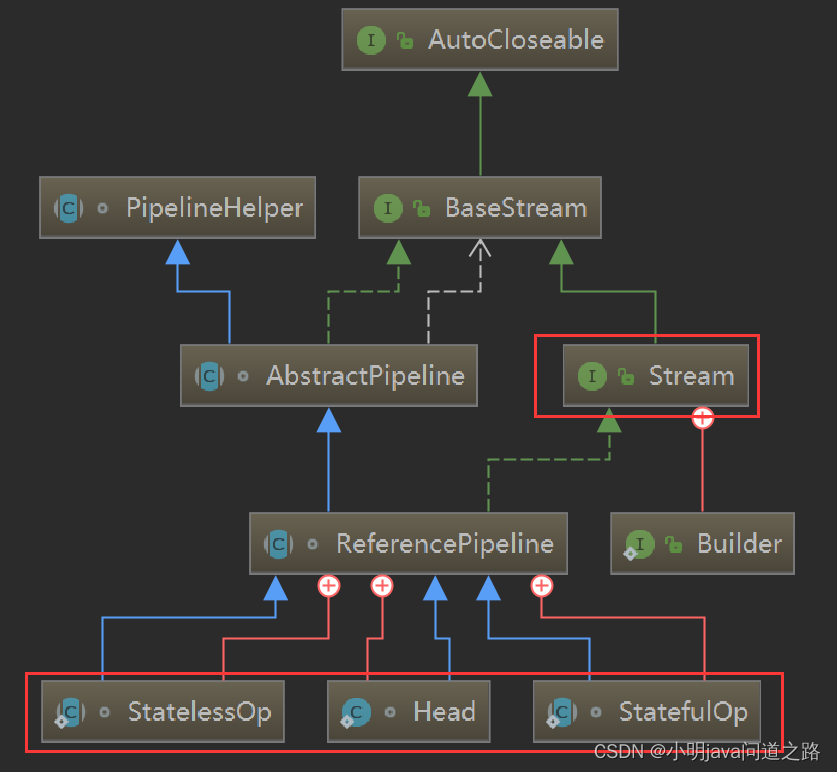
上图中Head用于表示第一个Stage,即调用调用诸如Collection.stream()方法产生的Stage,很显然这个Stage里不包含任何操作;StatelessOp和StatefulOp分别表示无状态和有状态的Stage,对应于无状态和有状态的中间操作。
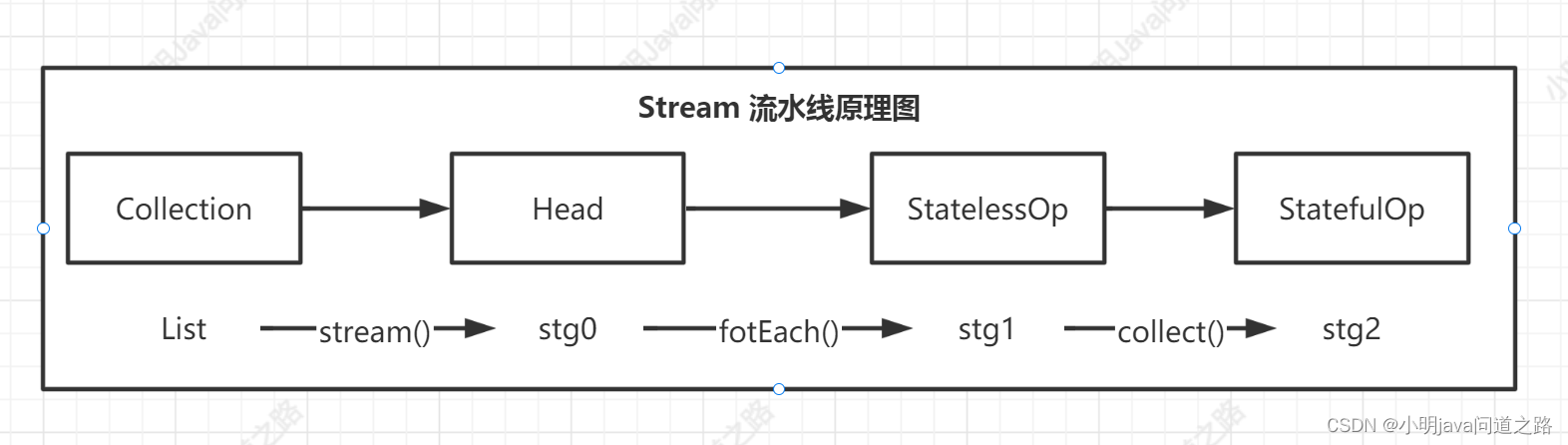
下图中通过Collection.stream()方法得到Head也就是stg0,紧接着调用一系列的中间操作,不断产生新的Stream。这些Stream对象以双向链表的形式组织在一起,构成整个流水线,由于每个Stage都记录了前一个Stage和本次的操作以及回调函数,依靠这种结构就能建立起对数据源的所有操作。这就是Stream记录操作的方式。
小结
本文通过集合引出Stream流,主要讲解了流的基本概念、使用的原理,Stream流水线的运行原理。

