详解Linux内核态调试工具kdump
目录
1、kdump介绍
1.1、kexec及其实现机制
1.2、几个基本概念
1.3、kdump机制
1.4、kdump执行流程
2、Kdump配置与使用
2.1、内核配置
2.2、安装kdump
2.3、修改内核启动参数
2.4、修改kdump配置文件
2.5、启动kdump
2.6、验证kdump
3、kdump解析
4、通过dmesg信息去分析
5、总结
kdump是目前最有效的linux内存镜像收集机制,广泛应用于各大linux厂商的各种产品中,在调试Linux系统内核方面起着不可替换的重要作用。
比如当你运行某个驱动程序时系统莫名其妙的没有反应了,看不到任何的异常信息打印,查看驱动程序的运行日志也看不到有用的信息,通过系统监控发现在系统没有反应之前系统的CPU、内存、负载、流量都很正常,就是突然没有响应了!驱动程序一般运行在系统的内核态中,排查系统内核态的异常似乎很是麻烦,此时有个强大的工具kdump可以使用,可以导出出问题的驱动程序的内存及异常上下文信息到dump转储文件中,事后我们去分析这个dump文件,可能就能很快定位发生异常的原因了。今天我们就来详细地讲述一下kdump转储工具的使用。
1、kdump介绍
kdump的概念出现在 2005 左右,是迄今为止最可靠的内核转存机制,已经被主要的 linux 厂商选用。kdump是一种先进的基于 kexec 的内核崩溃转储机制,用来捕获kernel crash(内核崩溃)时候产生的crash dump。当内核产生错误(系统崩溃、死锁或者死机)时,kdump会将内存导出为vmcore保存到磁盘。
kdump的实现可以分为两个部分:内核和用户工具。内核提供机制,用户工具在这些机制上实现各种转储策略。内核机制对用户工具的接口是一个系统调用:kexec_load(),它被用于加载捕获内核和传递一些相关信息。
kdump的实现依赖于kexec,下面分别介绍kexec、kdump这两个机制相关的内容。
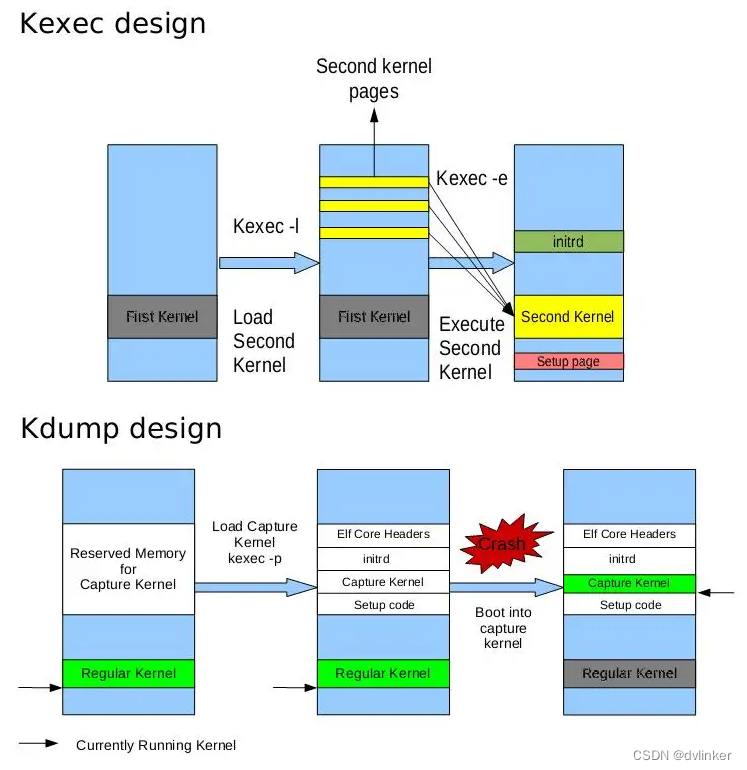
1.1、kexec及其实现机制
kexec是一个快速启动机制,允许通过已经运行的内核的上下文启动一个Linux内核,不需要经过BIOS。BIOS可能会消耗很多时间,特别是带有众多数量的外设的大型服务器。这种办法可以为经常启动机器的开发者节省很多时间。
kexec的实现包括2个组成部分:内核空间和用户空间。
一是内核空间的系统调用:kexec_load(),负责在生产内核(production kernel 或 first kernel)启动时将捕获内核(capture kernel或sencond kernel)加载到指定地址。
kexec 在 kernel 里以一个系统调用 kexec_load() 的形式提供给用户。这个系统调用主要用来把另一个内核和其 ramdisk 加载到当前内核中。在 kdump 中,捕获内核只能使用事先预留的一小段内存。生产内核的内存镜像会被以 /proc/vmcore 的形式提供给用户。这是一个 ELF 格式的方件,它的头是由用户空间工具 kexec 生成并传递来的。在系统崩溃时,系统最后会调用 machine_kexec()。这通常是一个硬件相关的函数。它会引导捕获内核,从而完成 kdump 的过程。
二是用户空间的工具kexec-tools,他将捕获内核的地址传递给生产内核,从而在系统崩溃的时候能够找到捕获内核的地址并运行。没有kexec就没有kdump。先有kexec实现了在一个内核中可以启动另一个内核,才让kdump有了用武之地。
kdump 的很大一部分工作都是在用户空间内完成的。与 kexec 相关的集中在一个叫“kexec-tools”的工具中的“kexec”程序中。该程序主要是为调用 kexec_load() 收集各种信息,然后调用之。这些信息主要包括 purgatory 的入口地址,还有一组由 struct kexec_segment 描述的信息。
1.2、几个基本概念
在讲解kdump机制之前,我们先来看几个概念:
生产内核 :第一个运行的内核(正常的系统运行内核)。
捕获内核:第二个运行的内核(系统异常时,会启动捕获内核,用以对生产内核下的内存进行收集和转存)。
vmcore:这里讲的ramdisk实际上就是把一段内存假设为一个硬盘驱动器(使用ramdisk作为文件系统可以大幅提高读写速度)。
ramdisk:这里讲的是内核分析出内存的使用和分布等情况,然后把这些信息综合起来生成一个ELF头文件保存起来。
ELF文件:这里是指收集到的生产内核产生的内存核心内容。
1.3、kdump机制
kdump机制的实现需要两个不同目的的内核,生产内核和捕获内核。生产内核是捕获内核服务的对像。捕获内核会在生产内核崩溃时启动起来,与相应的ramdisk一起组建一个微环境,用以对生产内核下的内存进行收集和转存。注意,在启动时,kdump保留了一定数量的重要的内存,为了计算系统需要的真正最小内存,加上kdump使用的内存数量,以决定真正的最小内存的需求。
关于生产内核、捕获内核、vmcore的具体说明:
生产内核就是系统正常运行的一般内核。生产内核保留了内存的一部分给捕获内核启动用。由于kdump利用kexec启动捕获内核,绕过了 BIOS,所以生产内核的内存得以保留。这是内核崩溃转储的本质。
捕获内核启动后,会像一般内核一样,去运行为它创建的 ramdisk 上的 init 程序。而各种转储机制都可以事先在 init 中实现。为了在生产内核崩溃时能顺利启动捕获内核,捕获内核(以及它的 ramdisk)是事先放到生产内核的内存中的。而捕获内核启动后需要使用的一小部分内存是通过 crashkernel=Y@X 这一内核参数在生产内核中保存的。
生产内核的内存是通过 /proc/vmcore 这个文件交给捕获内核的。为了生成它,用户工具先在生产内核中分析出内存的使用和分布等情况,然后把这些信息综合起来 生成一个 ELF 文件头保存起来。捕获内核被引导时会被同时传递这个 ELF 文件头的地址,通过分析它,捕获内核就可以生成出 /proc/vmcore。有了 /proc/vmcore 这个文件,捕获内核的 ramdisk 中的脚本就可以通过通常的文件读写和网络来实现 各种策略了。同时 kdump 的用户工具还提供了缩减内存镜像尺寸的工具。这就是 Kdump 的基本设计。
注意,kdump用于对内存镜像的转储,它不但可以转储内存镜像到本地硬盘,还可以将内存镜像通过 NFS, SSH 等协议转储到不同机器的设备上。
1.4、kdump执行流程
当系统崩溃时,kdump使用kexec启动到第二个内核。第二个内核叫做捕获内核,启动的时候会与相应的ramdisk一起组件一个微环境,用于转存系统内存,导出为vmcore并保存到磁盘。具体流程如下:
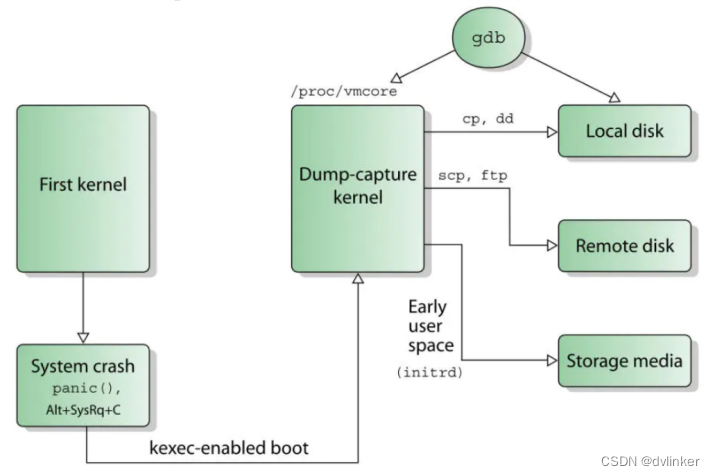
1)First kernel(生产内核)正常运行;
2)运行过程中,系统出现异常(也可以是模拟通过sysrq触发panic);
3)在系统崩溃时,系统最后会调用 machine_kexec(),触发并启动Sencond kernel(捕获内核),传递ELF头文件的地址;
4)捕获内核与相应的ramdisk一起组建一个微环境,获取ELF头文件的地址,并生成出/proc/vmcore文件;
5)捕获内核的ramdisk中的脚本开始执行,将/proc/vmcore文件中的数据通过文件读写和网络来实现对生产内核下的内存进行收集和转存。
6)通过gdb、crash等工具,对收集到的vmcore文件镜像分析
2、Kdump配置与使用
不同的Linux发行版本对Kdump的配置都是不一样的,本文主要介绍CentOS的Kdump配置。
想要实现Kdump功能,需要哪些配置?主要有以下几点
1)内核配置
2)安装kdump(kexec-tools)工具
3)修改内核启动参数("crashkernel=xxxM quiet")
4)修改kdump配置文件
5)启动kdump功能
6)验证Kdump功能
下面就对这几个方面做具体的介绍。
2.1、内核配置
通常我们认为X86设备默认内核是已经配置了Kdump功能的。
想要确认当前内核是否支持kexec,可通过查看在/sys/kernel/下有没有kexec等文件去确认,同时通过查看 /sys/kernel/kexec_crash_loaded 的值,判断Kdump功能是否加载(“1”为已经加载,“0”为还未加载)
cat /sys/kernel/kexec_crash_loaded如果没有,则需要我们对内核进行配置,具体如下(make menuconfig):
CONFIG_SUSPEND=yPower management options --->[*] Suspend to RAM and standbyCONFIG_KEXEC=yBoot options --->[*] Kexec system call (EXPERIMENTAL)//此参数告诉系统使用Kexec跳过BIOS和引导(新)内核。(提供内核层面的kexec功能支持)CONFIG_CRASH_DUMP=yBoot options --->[*] Build kdump crash kernel (EXPERIMENTAL)//崩溃转储需要启用。没有此选项,Kdump将毫无用处。(提供内核层面的kdump功能支持)CONFIG_SYSFS=yFile systems --->Pseudo filesystems --->[*] Tmpfs virtual memory file system support//启用sysfs文件系统支持CONFIG_PROC_VMCORE=yFile systems --->Pseudo filesystems --->-*- /proc file system support--->[*] /proc/vmcore support//此配置允许Kdump将内存转储保存到/proc/vmcore。CONFIG_DEBUG_INFO=yKernel hacking --->Compile-time checks and compiler options --->[*] Compile the kernel with debug info//此参数表示将使用调试符号构建内核。尽管这将增加内核映像的大小,但是具有可用的符号对于深入分析内核崩溃非常有用,因为它不仅使您可以跟踪导致崩溃的有问题的函数调用问题,而且可以跟踪特定行在相关来源中。2.2、安装kdump
通常我们认为X86设备默认内核是已经配置了Kdump功能的。kdump依赖于kexec工具,验证kexec工具是否存在:
kexec -v如果没有安装kexec工具,安装kexec:
sudo yum updatesudo yum search kexec-toolssudo yum install kexec-tools2.3、修改内核启动参数
之后修改/etc/default/grub内核启动文件,如下:
vi /etc/default/grub修改为:
GRUB_CMDLINE_LINUX="crashkernel=128M quiet"参数说明:
crashkernel=xxx //预留内存大小
quiet //表示在启动过程中只有重要信息显示,类似硬件自检的消息不回显示。
注意如果不加quiet可能会导致生成不了vmcore,原因暂时不明。另外,注意预留内存大小,过大/过小都会导致生成vmcore文件失败(不知道设置多少时,可以尝试每次增加128M)。只要更改了grub文件,都需要更新grub配置。执行完毕后,需要重启才能生效。
sudo grub2-mkconfig -o /boot/grub2/grub.cfgreboot重启成功后,验证是否已成功配置启动参数:
cat /proc/cmdline说明:
如果在cmdline里找到了crashkernel参数,代表已经将配置写入内核了
2.4、修改kdump配置文件
继续修改/etc/kdump.conf配置文件:
vim /etc/kdump.conf打开kdump.conf文件后,其中需要注意的三行内容:
...
path /var/crash #指定coredump文件放在/var/crash文件夹中
core_collector makedumpfile -c -l -message-level 1 -d 31 #加上-c表示压缩,原文件中没有
default reboot #生成coredump后,重启系统
...
注意,选项-c添加上后,可能会导致生成vmcore失败,原因不明,如果不添加可能会导致vmcore非常大(我这边vmcore有1.2GB)
2.5、启动kdump
执行命令启动kdump服务,如下:
systemctl enable kdump.servicesystemctl start kdump.service如果您之前配置过kdump服务的,可以使用restart命令重新启动下,否则不一定能用,如:
systemctl restart kdump.service查看Kdump服务
systemctl status kdump● kdump.service - Crash recovery kernel arming
Loaded: loaded (/usr/lib/systemd/system/kdump.service; enabled; vendor preset: enabled)
Active: active (exited) since Mon 2020-12-21 14:45:36 CST; 7min ago
Main PID: 6983 (code=exited, status=0/SUCCESS)
Memory: 0B
CGroup: /system.slice/kdump.service
2.6、验证kdump
最后,通过模拟系统异常崩溃,验证kdump是否已启用:
echo 1 > /proc/sys/kernel/sysrqecho c > /proc/sysrq-trigger重启后,查看/var/crash目录。每一次内核崩溃都会在/var/crash目录下创建一个127.0.0.1-xxx(后缀是产生该目录时的具体时间)对应的目录,里面保存有vmcore和vmcore-dmesg.txt文件。
ls /var/crash/
total 1252896
-rw------- 1 root root 1282844960 Dec 23 19:34 vmcore
-rw-r--r-- 1 root root 114362 Dec 23 19:34 vmcore-dmesg.txt说明:
vmcore-dmesg.txt是生产内核的dmesg信息。
vmcore文件为通过kdump等手段收集的操作系统core dump信息,在不采用压缩的情况下,其相当于整个物理内存的镜像,所以其中包括了最全面、最完整的信息,对于分析定位各种疑难问题有极大的帮助。配置kdump后,在内核panic后,会自动进入kump流程,搜集并转储vmcore。
3、kdump解析
解析kdump捕获的vmcore文件,需要准备如下:
1)crash工具;
2)发生崩溃的内核映像文件(vmlinux),包含调试内核所需调试信息;
3)崩溃转储文件(vmcore);
下面我们就来讲述解析vmcore文件的完整过程!
crash工具即为专门用于分析vmcore文件的工具,其中提供了大量的实用分析命令,极大的提高了vmcore的分析效率。通过执行crash命令,解析vmcore文件,如下:
crash xxx/vmlinux xxx/vmcore例如:
crash /boot/vmlinux /var/crash/127.0.0.1-2020-12-24-17:20:41/vmcore上述命令的执行结果如下:
GNU gdb (GDB) 7.6
Copyright (C) 2013 Free Software Foundation, Inc.
License GPLv3+: GNU GPL version 3 or later
This is free software: you are free to change and redistribute it.
There is NO WARRANTY, to the extent permitted by law. Type "show copying"
and "show warranty" for details.
This GDB was configured as "x86_64-unknown-linux-gnu"...KERNEL: /boot/vmlinux
DUMPFILE: /var/crash/127.0.0.1-2020-12-24-17:20:41/vmcore [PARTIAL DUMP]
CPUS: 8
DATE: Thu Dec 24 17:20:34 2020
UPTIME: 00:34:45
LOAD AVERAGE: 3.37, 3.71, 3.38
TASKS: 1316
NODENAME: fe0fdb76-b761-11e9-b107-0014101e89e7
RELEASE: 3.10.0+
VERSION: #1 SMP Thu Dec 24 16:27:16 CST 2020
MACHINE: x86_64 (3408 Mhz)
MEMORY: 31.9 GB
PANIC: "SysRq : Trigger a crash"
PID: 1942
COMMAND: "bash"
TASK: ffff88068c957300 [THREAD_INFO: ffff88062b8f4000]
CPU: 2
STATE: TASK_RUNNING (SYSRQ)
crash>
其实通过上述的“PANIC”字段信息,已经能大致分析出vmcore产生的原因。产生Panic的原因是sysrq触发了一个crash(Ps:我使用了sysrq模拟内核崩溃“echo c > /proc/sysrq-trigger”)。
通过“bt”命令+上述的“PID”字段,可以打印问题进程的栈信息,如下:
crash> bt 1942
PID: 1942 TASK: ffff88068c957300 CPU: 2 COMMAND: "bash"
#0 [ffff88062b8f7b48] machine_kexec at ffffffff81051e9b
#1 [ffff88062b8f7ba8] crash_kexec at ffffffff810f27e2
#2 [ffff88062b8f7c78] oops_end at ffffffff81689948
#3 [ffff88062b8f7ca0] no_context at ffffffff816793f1
#4 [ffff88062b8f7cf0] __bad_area_nosemaphore at ffffffff81679487
#5 [ffff88062b8f7d38] bad_area_nosemaphore at ffffffff816795f1
#6 [ffff88062b8f7d48] __do_page_fault at ffffffff8168c6ce
#7 [ffff88062b8f7da8] do_page_fault at ffffffff8168c863
#8 [ffff88062b8f7dd0] page_fault at ffffffff81688b48
[exception RIP: sysrq_handle_crash+22]
RIP: ffffffff813baf16 RSP: ffff88062b8f7e80 RFLAGS: 00010046
RAX: 000000000000000f RBX: ffffffff81a7b180 RCX: 0000000000000000
RDX: 0000000000000000 RSI: ffff88086ec8f6c8 RDI: 0000000000000063
RBP: ffff88062b8f7e80 R8: 0000000000000092 R9: 0000000000000e37
R10: 0000000000000e36 R11: 0000000000000003 R12: 0000000000000063
R13: 0000000000000246 R14: 0000000000000004 R15: 0000000000000000
ORIG_RAX: ffffffffffffffff CS: 0010 SS: 0018
#9 [ffff88062b8f7e88] __handle_sysrq at ffffffff813bb6d2
#10 [ffff88062b8f7ec0] write_sysrq_trigger at ffffffff813bbbaf
#11 [ffff88062b8f7ed8] proc_reg_write at ffffffff812494bd
#12 [ffff88062b8f7ef8] vfs_write at ffffffff811dee9d
#13 [ffff88062b8f7f38] sys_write at ffffffff811df93f
#14 [ffff88062b8f7f80] system_call_fastpath at ffffffff81691049
RIP: 00007fb320bcb500 RSP: 00007ffde533c198 RFLAGS: 00000246
RAX: 0000000000000001 RBX: ffffffff81691049 RCX: ffffffffffffffff
RDX: 0000000000000002 RSI: 00007fb3214eb000 RDI: 0000000000000001
RBP: 00007fb3214eb000 R8: 000000000000000a R9: 00007fb3214d5740
R10: 0000000000000001 R11: 0000000000000246 R12: 0000000000000001
R13: 0000000000000002 R14: 00007fb320e9f400 R15: 0000000000000002
ORIG_RAX: 0000000000000001 CS: 0033 SS: 002b
可以看到最后几步触发了缺页异常,进入crash_kexec的流程,最后调用 machine_kexec()。这通常是一个硬件相关的函数。它会引导启动捕获内核,从而完成 kdump 的过程。
代码就是走到了sysrq_handle_crash函数首地址+0x22这段命令的时候,触发的缺页异常。
注意这里,对应x86-64汇编,应用层下来的系统调用对应的6个参数存放的寄存器依次对应:rdi、rsi、rdx、rcx、r8、r9。对于多于6个参数的,仍存储在栈上。通过“bt命令”,我们可以分析异常进程的栈信息,得到关键信息:[exception RIP: sysrq_handle_crash+22],代码就是走到了sysrq_handle_crash函数首地址+0x22这段命令的时候,触发的缺页异常。
能不能再具体一点?当然可以!通过“dis -l (function+offset) 10” 命令,反汇编出指令所在代码,10代表打印该指定位置开始的10行信息。
crash> dis -l sysrq_handle_crash+22 10
/home/wangjunsource/sdx/sdx_x86/packages/linux_lsp/kernel/linux-3.10.0/drivers/tty/sysrq.c: 138
0xffffffff813baf16 : movb $0x1,0x0
/home/wangjunsource/sdx/sdx_x86/packages/linux_lsp/kernel/linux-3.10.0/drivers/tty/sysrq.c: 139
0xffffffff813baf1e : pop %rbp
0xffffffff813baf1f : retq
/home/wangjunsource/sdx/sdx_x86/packages/linux_lsp/kernel/linux-3.10.0/drivers/tty/sysrq.c: 85
0xffffffff813baf20 : nopl 0x0(%rax,%rax,1) [FTRACE NOP]
0xffffffff813baf25 : push %rbp
/home/wangjunsource/sdx/sdx_x86/packages/linux_lsp/kernel/linux-3.10.0/drivers/tty/sysrq.c: 90
0xffffffff813baf26 : xor %eax,%eax
/home/wangjunsource/sdx/sdx_x86/packages/linux_lsp/kernel/linux-3.10.0/drivers/tty/sysrq.c: 89
0xffffffff813baf28 : movl $0x7,0x6322be(%rip) # 0xffffffff819ed1f0
/home/wangjunsource/sdx/sdx_x86/packages/linux_lsp/kernel/linux-3.10.0/drivers/tty/sysrq.c: 85
0xffffffff813baf32 : mov %rsp,%rbp
0xffffffff813baf35 : push %rbx
/home/wangjunsource/sdx/sdx_x86/packages/linux_lsp/kernel/linux-3.10.0 -- MORE -- forward: , or j backward: b or k
/drivers/tty/sysrq.c: 88
0xffffffff813baf36 : lea -0x30(%rdi),%ebx
解析:代码位置+函数+函数偏移位置+该位置的汇编指令...很容易定义到具体的哪一行代码,更方便我们去分析问题的原因!
通过“dis”命令,我们很容易得到“代码位置+函数+函数偏移位置+该位置的汇编指令...”等等信息应该能很容易定位到具体哪一行代码出问题。
什么?还是分析不出来!?能不能再具体一点?难道想让它给你指出具体问题出在哪一行了?当然也可以!通过“sym 地址”命令,可以看到这个地址上对应的符号表信息,并且具体到源代码的那一行。
crash> sym ffffffff813baf16
ffffffff813baf16 (t) sysrq_handle_crash+22 /home/wangjunsource/sdx/sdx_x86/packages/linux_lsp/kernel/linux-3.10.0/drivers/tty/sysrq.c: 138
出问题的位置在“drivers/tty/sysrq.c”源文件中的第138行。
还有其他的命令,就不一一举例了,简单的描述下:
log命令:打印vmcore所在的系统内核日志信息3
mod命令:查看当时内核加载的所有内核模块信息
ps命令:打印进程信息
files命令:打印指定进程所打开的文件信息
vm命令:打印指定进程当时虚拟内存基本信息
task命令:查看当前进程或指定进程task_struct和thread_info的信息。(它会把task_struct中所有成员的值打印出来)
kmem命令:查看当时系统内存使用信息
...
通过help查看其他命令。
4、通过dmesg信息去分析
其实也可以不通过vmcore去分析问题的(毕竟vmcore的环境搭建起来不是那么的方便),日常通过有限的dmesg信息,也可以分析出很多内容。分析dmesg信息:
[ 2081.459132] SysRq : Trigger a crash
[ 2081.462707] BUG: unable to handle kernel NULL pointer dereference at (null)
[ 2081.470616] IP: [] sysrq_handle_crash+0x16/0x20
[ 2081.476810] PGD 7bf5a1067 PUD 679167067 PMD 0
[ 2081.481364] Oops: 0002 [#1] SMP
[ 2081.484652] Modules linked in: xfs(E) libcrc32c(E) dccp_diag(E) dccp(E) udp_diag(E) unix_diag(E) af_packet_diag(E) netlink_diag(E) iptable_nat(E) nf_conntrack_ipv4(E) nf_defrag_ipv4(E) nf_nat_ipv4(E) xt_addrtype(E) iptable_filter(E) xt_conntrack(E) nf_nat(E) nf_conntrack(E) bridge(E) stp(E) llc(E) overlay(E) tcp_diag(E) inet_diag(E) fuse(E) swcsm22(OE) intel_powerclamp(E) coretemp(E) intel_rapl(E) kvm_intel(E) kvm(E) crc32_pclmul(E) ghash_clmulni_intel(E) ppdev(E) aesni_intel(E) lrw(E) gf128mul(E) glue_helper(E) ablk_helper(E) cryptd(E) pcspkr(E) parport_pc(E) sg(E) parport(E) shpchp(E) acpi_pad(E) ip_tables(E) ext4(E) mbcache(E) jbd2(E) sd_mod(E) crc_t10dif(E) crct10dif_generic(E) crct10dif_pclmul(E) crct10dif_common(E) crc32c_intel(E) i915(E) ahci(E) igb(E) libahci(E) ptp(E) pps_core(E) drm_kms_helper(E)
[ 2081.558510] dca(E) i2c_algo_bit(E) libata(E) drm(E) i2c_hid(E) video(E) dm_mirror(E) dm_region_hash(E) dm_log(E) dm_mod(E) brd(E)
[ 2081.569304] CPU: 2 PID: 1942 Comm: bash Tainted: G W OE ------------ T 3.10.0+ #1
[ 2081.577913] Hardware name: Default string Default string/SKYBAY, BIOS 5.11 03/13/2018
[ 2081.586046] task: ffff88068c957300 ti: ffff88062b8f4000 task.ti: ffff88062b8f4000
[ 2081.593740] RIP: 0010:[] [] sysrq_handle_crash+0x16/0x20
[ 2081.602538] RSP: 0018:ffff88062b8f7e80 EFLAGS: 00010046
[ 2081.608009] RAX: 000000000000000f RBX: ffffffff81a7b180 RCX: 0000000000000000
[ 2081.615354] RDX: 0000000000000000 RSI: ffff88086ec8f6c8 RDI: 0000000000000063
[ 2081.622619] RBP: ffff88062b8f7e80 R08: 0000000000000092 R09: 0000000000000e37
[ 2081.629861] R10: 0000000000000e36 R11: 0000000000000003 R12: 0000000000000063
[ 2081.637186] R13: 0000000000000246 R14: 0000000000000004 R15: 0000000000000000
[ 2081.644561] FS: 00007fb3214d5740(0000) GS:ffff88086ec80000(0000) knlGS:0000000000000000
[ 2081.652857] CS: 0010 DS: 0000 ES: 0000 CR0: 0000000080050033
[ 2081.658767] CR2: 0000000000000000 CR3: 00000005eef57000 CR4: 00000000003407e0
[ 2081.666046] DR0: 0000000000000000 DR1: 0000000000000000 DR2: 0000000000000000
[ 2081.673388] DR3: 0000000000000000 DR6: 00000000fffe0ff0 DR7: 0000000000000400
[ 2081.680661] Stack:
[ 2081.682775] ffff88062b8f7eb8 ffffffff813bb6d2 0000000000000002 00007fb3214eb000
[ 2081.690621] ffff88062b8f7f48 0000000000000002 0000000000000000 ffff88062b8f7ed0
[ 2081.698520] ffffffff813bbbaf ffff8807bba10600 ffff88062b8f7ef0 ffffffff812494bd
[ 2081.706545] Call Trace:
[ 2081.709113] [] __handle_sysrq+0xa2/0x170
[ 2081.715079] [] write_sysrq_trigger+0x2f/0x40
[ 2081.721434] [] proc_reg_write+0x3d/0x80
[ 2081.727048] [] vfs_write+0xbd/0x1e0
[ 2081.732391] [] SyS_write+0x7f/0xe0
[ 2081.737641] [] system_call_fastpath+0x16/0x1b
[ 2081.743796] Code: eb 9b 45 01 f4 45 39 65 34 75 e5 4c 89 ef e8 e2 f7 ff ff eb db 0f 1f 44 00 00 55 c7 05 40 20 63 00 01 00 00 00 48 89 e5 0f ae f8 04 25 00 00 00 00 01 5d c3 0f 1f 44 00 00 55 31 c0 c7 05 be
[ 2081.764509] RIP [] sysrq_handle_crash+0x16/0x20
[ 2081.770853] RSP
[ 2081.774459] CR2: 0000000000000000
dmesg信息中有时候也会打印部分栈信息,具体看到这行:
IP: [] sysrq_handle_crash+0x16/0x20
在dmesg信息中,我们得到了出现异常时,PC指针所在的位置,再通过反汇编内核镜像,得到汇编级的代码,一样可以分析出具体出问题在哪一行:
objdump -DS vmlinux > vmlinux.txt
再分析汇编vmlinux.txt文件:
ffffffff813baf00 :
static void sysrq_handle_crash(int key)
{
ffffffff813baf10: 48 89 e5 mov %rsp,%rbp
char *killer = NULL;panic_on_oops = 1; /* force panic */
wmb();
ffffffff813baf13: 0f ae f8 sfence
*killer = 1;
ffffffff813baf16: c6 04 25 00 00 00 00 movb $0x1,0x0
ffffffff813baf1d: 01
}
根据sysrq_handle_crash+0x16 对应就是ffffffff813baf00+0x16=ffffffff813baf16或者直接根据上面的地址搜索,ffffffff813baf16 看到对应的汇编指令:c6 04 25 00 00 00 00 movb $0x1,0x0。
PS:“sysrq_handle_crash+0x16/0x20”这段的意思是说,函数的总长度就是sysrq_handle_crash首地址+0x20偏移地址,当前异常的位置是sysrq_handle_crash首地址+0x16偏移地址!
当然在这需要一定的汇编代码功底,才能明白。如果崩溃处对应有c代码的话,排查起来就简单多了。
5、总结
希望本文能教给您一些新的知识,我们有时往往距离掌握Linux内核的秘密只有一步之遥。通过kdump,我们可以在系统崩溃时收集内存及关键信息,对其进行分析。如果想要将kdump利用到有些产品上,过程相对要复杂一些,可能要执行下面一些步骤:
1)需要预留一部分内存空间(用于存放捕获内核);
2)需要配置内核(config文件);
3)需要修改配置文件(内核启动参数、kdump配置);
4)需要编译时保留vmliunx,以便在外部发生问题时,通过crash分析(vmlinux必须带debuginfo调试信息);
5)还需要安装各类工具(kexec、kdump、crash…)。

