《WeNet语音识别实战》答疑回顾(四)

问 1:我训练Aishell-1模型,训练到第10个左右的epoch,loss就会飞掉,可能是什么原因呀?
我是用的一张2080ti的单卡跑的。训练了两次,一次在第6个epoch,loss飞了;一次在第9个epoch,loss也飞了。
我把warmup的k值改成0.15,loss还是飞掉了,可能是啥原因呀?
学习率大概在0.001的时候就飞了,之前用默认warmup k=0.2的时候,学习率到0.0015才飞了。
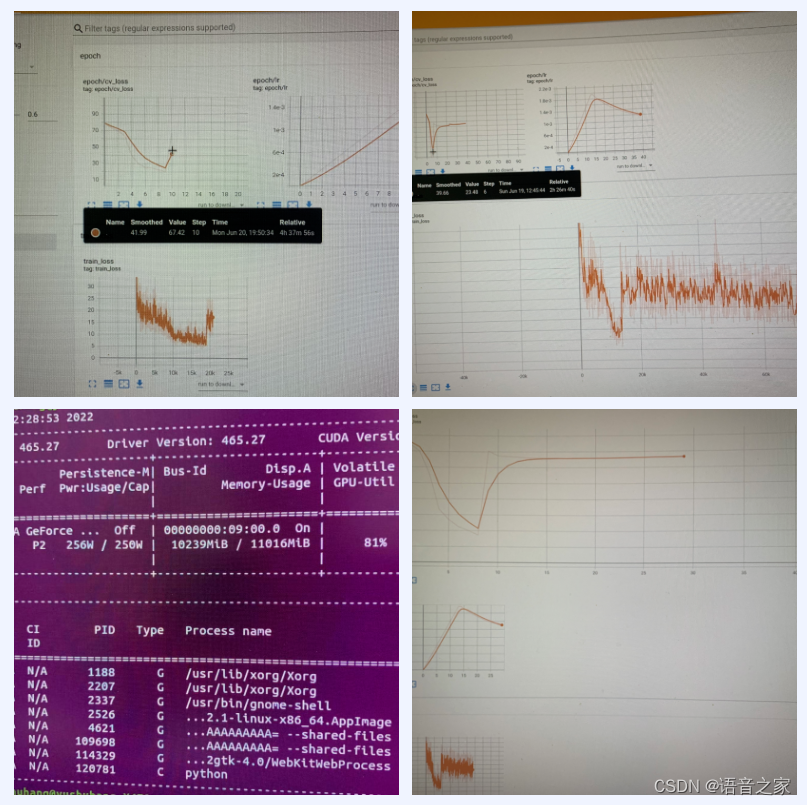
答:模型的训练过程中,可能因为卡数,使用机器的个数不同,可能会导致训练过程中loss飞掉。还有关键的一点是transformer在学习时有一步是学习率的warm up,它是一个由小到大再逐渐下降的变化过程,在WeNet配置中有一个warm up step主要负责这部分的功能。官方提供的模型在训练时损失没有飞掉,但是我们训飞了,这是因为warm up这个步骤和卡数、GPU的数量以及和训练过程中梯度的累计都有一些关系。这种情况一般的解决方法是可以把学习率设置得小一些,把swarm up step得的数量设置得更大一些。
问 2:请教大神们,做语音标注,多长的时长存一个file比较合适呢?我看很多公开的都在3到五秒之内。这个长短和最后的效果,有怎样的关系呢?
答:公开的数据都是语音一句话的听写,或者是朗读类的,它采集的语料比较短,而且以前的识别系统可以识别的也比较短,现在的系统识别自然语音,几秒到几十秒都是可以的,具体长短和效果的联系,只要语音不要太长大家都不会太在意。如果自己在做数据集的标注,只要正常按照句子去切分就好。在训练过程中如果音频过长的话,训练的batch会非常大,有可能会导致训练时显存溢出,所以大家一般都是使用三到五秒比较合适。
问 3:这个U2框架在进行识别的时候怎么区别流式与非流式啊?
答:chunk的大小如果设成整句就是非流式,U2这个框架学完大家会发现一个模型可以做流式也可以做非流式,就看你如何设定chunk,这个在《WeNet语音识别实战课》五六七章都有详细的讲解内容。
问 4:我的增量训练,train了7个epoch,decode出乱子了,请问是怎么回事?
答:如果选择了自回归的解码方式的话,在长音频上会非常容易出现这样的问题。
问 5:如果说话长度超过了给定阈值后,WeNet是否可以认为把一句话分割成多句话了,分别识别?
答:runtime 的代码中,超过 20s 就会强制截断。
问 6:推理的时候为什么batch size只能是1?
答:Runtime其中包含好几种Runtime实现,一种是训练时python对它做推理,如果是使用CPU,确实有一个限制它得batchsize是1,这是因为如果batchszie不是1,对于不同长度的句子就需要做padding,padding在解码的逻辑处理过程中出现一些问题,导致解码的性能不太好,所以强制限制了batchsize等于1。另外,有的过程是可以并行的,也就是多句话同时做,有的只能单句做比如ctc、beam_search等,如果batchsize设置不等于1,也会拆成一句话一句话去做,效果和batchsize为1是一样的。但如果能够接触GPU的inference的话,它的batchsize是可以不为1的。
问 7:这段代码的作用是什么?在runtime推理的时候,好像没有用到这个 conf/train_960_unigram5000.model 模型,这个是英文才会用吧?
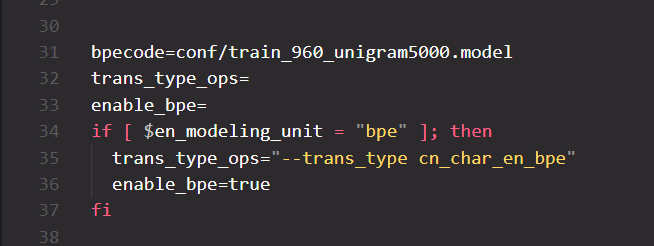
答:这个应该是Multi-CN的recipe中的代码,我们将多个中文的数据集合并在一起,其中也有英文,所以在建模的时候同时要考虑中英文的情况。对于中文我们使用字这种建模单元,对于英文我们可以使用字母或者BPE这种。这一段代码只是在训练过程中发挥作用,其实和Runtime推理过程没什么关系。它的功能就是把单词拆分成不同的部分,在推理时其实是一个反向的过程,也就是我们需要合并,所以并不需要这个步骤。
问 8:大家有没有遇到过这种情况,使用CLion 编译Debug程序,点击调试时程序就直接运行了,无法命中断点,也不能进行单步调试 。
答:建议还是使用onnx,可能你调用的包是linux版本,导致你不能做调试,建议可以使用linux的runtime。
问 9:可否通过简化WeNet模型结构,用轻量级模型来做 唤醒词或关键词检测呢?尽量减少性能占用,基于WeNet开发,这条路能走吗?
答:这个是完全可以做的,轻量化的模型大家可以用一些CNN的结构去做,完全可以做唤醒词或者关键词检测这种任务,在wenet里也有关键词检测的recipe叫做vkw2021可以使用。
问 10:模型导出时是支持量化模型导出的,那么在runtime推理时,怎么使用导出的量化模型;需要对输入数据做额外的预处理吗?
答:不需要。
问 11:aishell1里stage6生成final.zip步骤每次跑都报这个错误,有可能是什么问题?

答:可以手动跑一下这个命令试试,可能是环境有冲突。
问 12:我 7.4 Decoding with runtime这一步报错,想问一下words.fst这个文件夹是应该什么时候生成的?
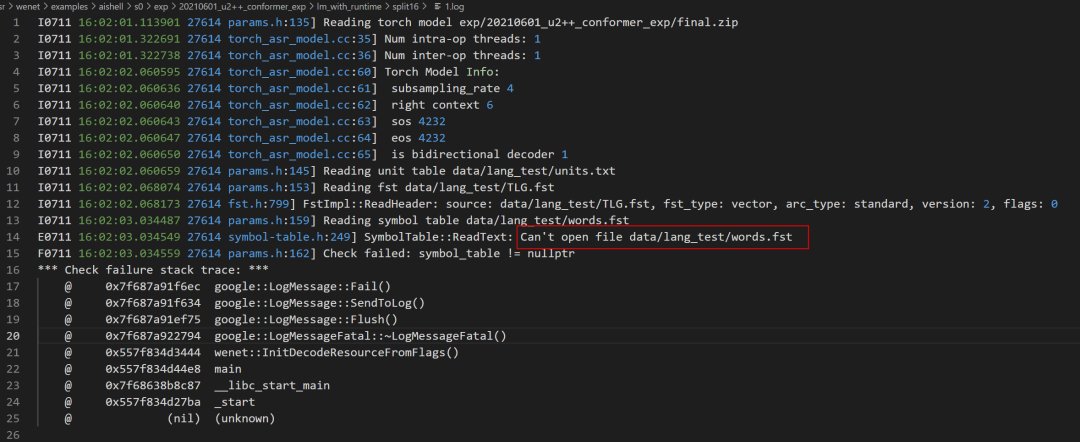
答:文件夹的名字是words.txt不是words.fst,源代码这里有个 topo error,已经修改更新了。
问 13: 如果字典里面有字母,比如asr这样的缩写,如何更好的识别,做热词可以,但是需要每个字母读的比较清晰,有啥更好的办法吗?
答:可能需要看一下你的 word piece 是怎么对 ASR 分词的。
问 14:请教个问题,wenet的模型量化,但是输入还是 float型。那么是不是可以理解为:推理计算是调用的还是 float的卷积计算,对推理速度是没有提升的。能否将输入转为 float16,甚至转为 uint8进行提速,这个想法可行吗?
答:wenet中的模型用的是pytorch中的动态量化,只有部分算子如linear是量化的,其它如 CNN 是未量化的。
也就是浮点和定点运算混合的。浮点输入碰到定点的算子时,会调用 Quantize 将输入转换为int8。定点输入碰到浮点算子时,会调用Dequantize转换为浮点。
问 15:想问一下我们在部署went x86时用什么样的部署会比较有效率?
答:我们在部署时都会结合一些分布式或者其他框架,这样会比较好,不太会直接用其中的websocket去部署。在语音识别领域里,实时率和效率相关,实时率比较低的时候可以支持更大量的并发。在x86上部署的时候可以使用量化的模型,它的RTF会更好一些。里面介绍到的语言模型,使用blank和frame skipping这种技巧整个效率会更高一些。
问 16:wenetspeech数据集中,音频的平均长度是多少啊?如果重新做标注,应该截取一个多长的声音片段呢?5秒可以吗?
以及像iPhone,OPPO这种,是不是要在切词的时候选择BP E模式呢?
答:没有专门统计过WeNetSpeech的语音长度,估计最终都在八秒以下。我们的数据是按照不同批次做的,因为整个数据是从字幕里来的,后期会有相应的限制它不会超过八秒,前期的数据有一些可能会长一点。一般截取音频长度在十秒以内是比较好的,考虑到太长的句子在训练的时候会导致内存溢出的问题。所有英文词在训练的时候都推荐使用BPE这种模式,这个也是行业中的一个标准的做法,无论在识别、NLP还是机器翻译中都是这样用的。
问 17:请问用window11已经安装了Git bash的情况下,怎么在vscode里使用bash?
答:只需要在vscode里的terminal.integrated.shell.windows里设置一下shell的路径就可以了。
问 18:对热词的bias还不支持英文吗?还有这部分是只有C++ code吗?
答:对热词是支持英文的,只要你的分词、构图没问题都可以。这部分只有C++的代码,它是一个偏向于产品级的一个应用,我们在科研方面就不太会使用到热词,为了考虑到效率,我们都是使用C++去实现。但是我们在python的包中也提供了一个接口,大家可以去Runtime里参考一下,它里面有把C++编译好的结果再通过python包装,然后我们就可以在那里面使用热词。
问 19:音频语料除了口音外,也有领域要求吗?
答:这个也是有的,本身不同的领域,它的空间环境是不一样的。现在的模型不是一个纯粹的声学模型,它也包含一些语言模型的信息。你在不同场景的使用习惯也不同,发音的习惯也不一样,不光是口音的问题。一些领域比较小,语料本身包含的语言模型的信息就很有价值。
问 20:A、B两个模型,如果用训练B的时候的dev,做测试集。是不是对A不公平?
答:一般dev集不应该拿来做测试集,你可以围绕dev集选择你的超参数,比如你训练了多少轮,训练B到时候你的目标肯定是把dev集做到更好,才能找到一个比较好的点,如果不在dev集上调肯定有一些不公平。
问 21:语言模型的权重可以通过什么方式设置吗?
答:WeNet中我们没有设置语言模型的权重的方式,我们有设置声学模型权重的方式,有一个参数叫acoustic skill就是专门设置声学的权重的。一般我们将声学模型的权重固定为1,去调整语言模型的权重,但WeNet里我们是反过来,将语言模型的权重设为1去设置声学模型。两种方式都可以,如果使用WeNet就用WeNet中的方式去调节语言模型和声学模型的比例就可以。
问 22:这边用最新的代码编译之后 解码出现nan,请问下有什么解决方法吗?音频路径没有问题,用的是开源的wenet的pretrain模型 然后我自己重新用最新的代码export_jit.py成zip文件。

答:这是一个bug,已经做了修复。
问 23:请问一下wenet librispeech的s0支持语言模型lm解码,s1中没有TLG的代码,是不支持还是效果没有端到端的好,所以丢弃了?
答:s1相当于是我们的一个作废的参考,其中数据的使用和现在的s0也完全不一样,所以这部分在未来会被移除掉。
问 24:Wenet 2.0里热词支持的部分,weight具体是怎么计算的?
答:对于热词我们会根据弧上字的个数去计算它的得分,我们对这个词分完之后,一条弧上有两个字,可能会给他奖励你给的分数乘2。还有一个效果更好的代码是,在热词匹配的过程中,如果已经匹配部分越多的话,那么这个分数就会越来越多,这个方式能够更大程度的把热词识别出来。所以这里我们只要去看一下构图那部分的代码,其实很容易就能找到答案。
问 25: 请问下想在QT里面调用decoder_main.exe,该怎么调?
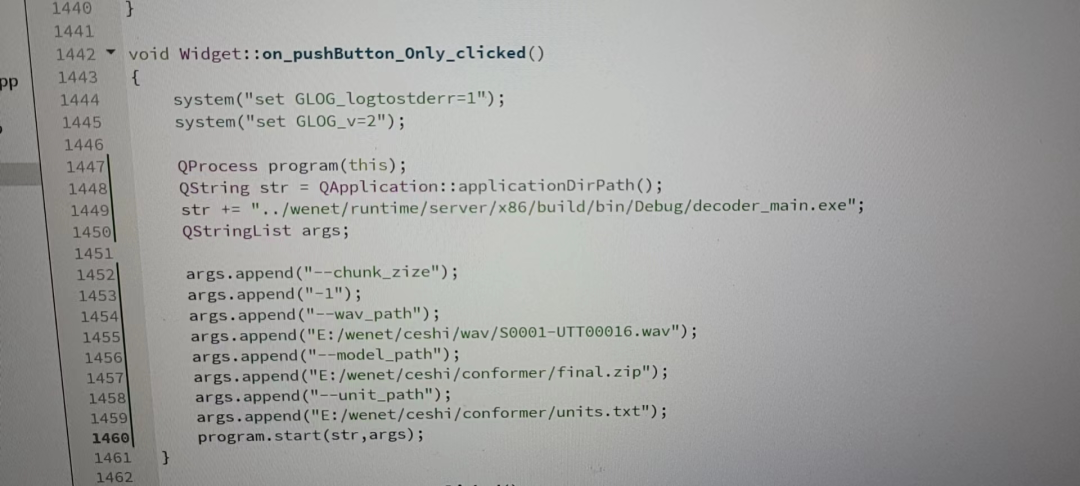
答:我们对QT还不太熟悉,建议可以去直接调用接口,通过C++的代码调用模型的初始化、解码这些接口等等,在我们的Runtime里会有这部分的东西。

