SPL工业智能:发现时序数据的异常
基本问题
工业生产过程中会产生大量的数据,比如电压、温度、流量等等,它们随时间推移而不断产生,这些数据在多数情况下是正常的,否则生产无法正常进行;少数情况下,数据是异常的,生产效率会降低甚至发生事故。在重大事件(如事故)发生之前,通常会在运行数据上有所体现,比如电流突然上升,后续很可能断电,造成一些不必要的损失,如果及时发现电流增大这一信号,及时找到原因并处置则可以将损失降到最小。因此及时发现异常数据并报警,提醒操作人员进行相应的操作,可以提高生产效率并避免事故发生。
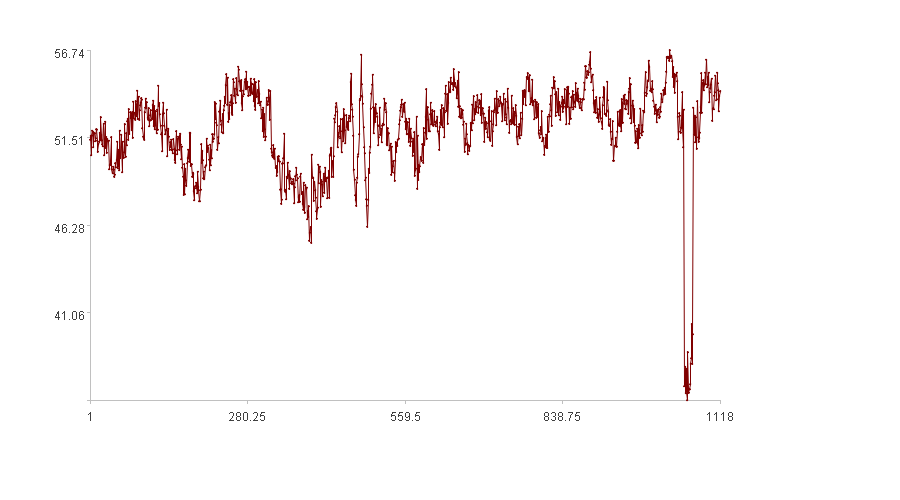
当前工业界常用的异常发现机制很简单,一般是凭经验设置一个范围,当仪表超过该范围时就认为是异常。这种方式过于简单粗暴了,经常会发生漏报(范围设置过宽)或误报(范围设置过窄)。因为生产过程是动态的,产生的数据也是动态的,简单的设置范围不可能适用于所有的生产状况,如下图:

左侧平稳期和右侧平稳期都是正常状态,如果左侧出现点1,右侧出现点2,它们都应该被判定为异常点,但如果简单的用固定范围来判断,这两个点都在固定范围内(图中的上下限),判断就会出错,所以需要动态的去判断某个点是否异常。
动态的判断异常,容易想到的方法是利用机器学习方法来动态发现异常。但机器学习是有监督方法,需要大量已知的异常数据,而实际场景通常并没有这些现成的数据,还需要人工标记出来。但是工业仪表产生的数据量对于人来说是个天文数字,依靠人工来标记不现实,而且人工标记也很难保证正确性,还要再去校对,工作量无比巨大,结果也就没有可操作性。所以只能使用无监督学习方法完成异常发现任务。
算法思路
没有标记好的异常数据,无监督方法怎么定义“异常”呢?
先来看一份数据:
先来看人是怎么发现异常的。
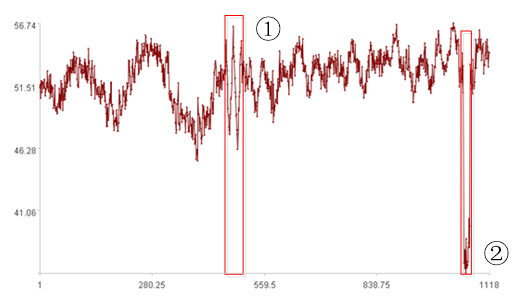
人观察这段数据后,发现的异常如上图,各段原因如下:
① 变化过快;
② 值过小。
异常大致是这几类:值过大或过小和变化过快。它们有个共同的特点,出现的情况比较少。我们不难得出一个抽象的说法:经常出现的情况是正常,没出现过或者很少出现的情况可以定义为异常。
那么发现异常的任务就转换为发现不常出现的情况,判断数据是否不常出现,就是看当前数据相较于之前一段时间内的数据是否不常出现。利用之前一段时间数据学出一个模型E,用它来判断当前数据是否异常。比如之前一段时间的数据在110内,那么当前时刻的数据在这个范围内就认为是正常,如果当前时刻的数据不在该范围内(比如等于11或0),则认为是异常。而110这个范围就是通过历史数据学出的模型E。拿着模型E就能算出当前数据是否异常了,即:
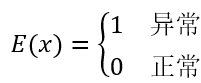
这样数据过大或者过小的异常就可以被发现了。
但是这种方法不一定能发现变化过快的异常数据,如下图:
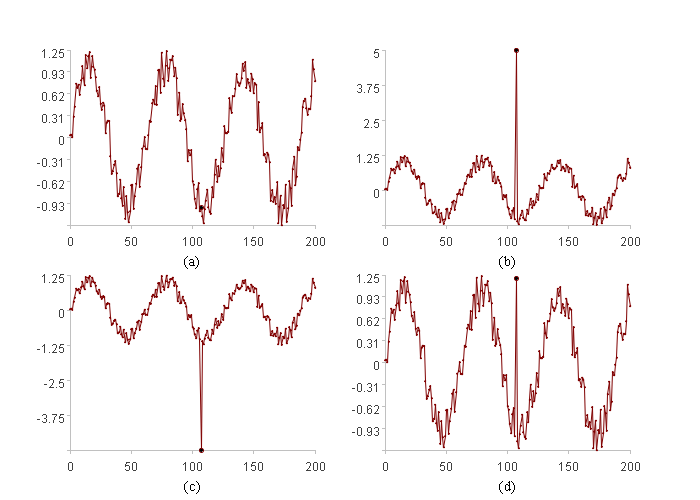
上述方法可以发现(b)©中的异常,但对于(d)中的异常就无能为力了,那该如何发现呢?
(d)中的情况就是变化过快,我们来看看能否用“变化快慢”这个数学量来发现异常。
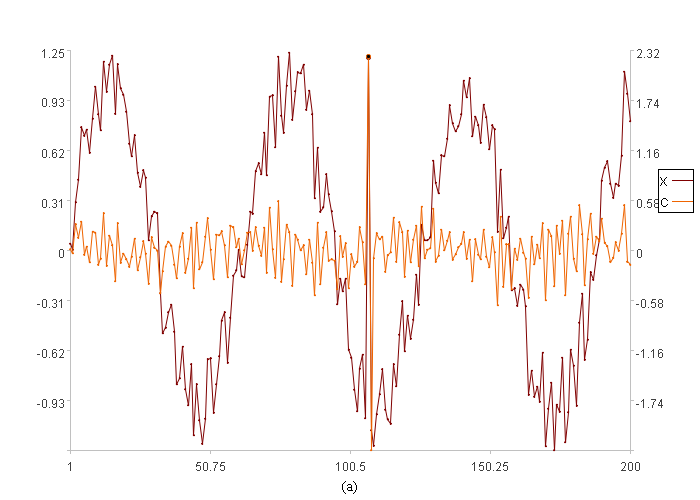
上图中曲线C就是“变化快慢”曲线,他是利用原值X衍生得到的,用刚才介绍的方法对C来发现异常即可发现变化过快这类异常。
由此看来,只要找到合适的数学量来表征这些数据的某些特征,就可以区分出常见和不常见的状态。比如下图:
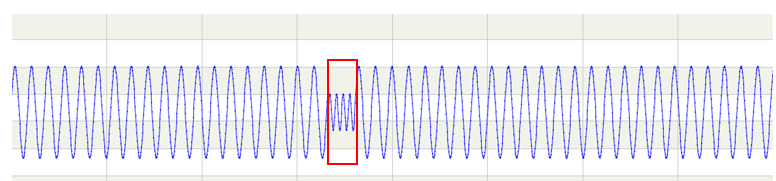
红框中的异常就是幅度异常,值和变化率都处于正常范围,只是幅度变小了,此时需要一个表征幅度的数学量来发现异常。
仅仅是生成是否异常还不够,异常还应区分异常的程度,比如1~10范围内是正常的,当前时刻是11的异常度就应该小于当前时刻是15的异常度,也就是说超限的幅度越大,异常度越大。这就要改造上面模型E,让它的判断结果返回一个连续值,使其能表征超限幅度越大,异常度越大。
实践效果
把上面思路写成代码,就可以完成异常发现了。比如动态算出值过大过小的异常度,SPL代码大体如下:
| A | |
| 1 | =file(C1).import@tc().(tag1) |
| 2 | =A1.(if(#<=100,,threshold(~[-100:0],"up",4))) |
| 3 | =A1.(if(#<=100,,threshold(~[-100:0],"down",4))) |
| 4 | =A1.m(101:) |
| 5 | =A2.m(101:) |
| 6 | =A3.m(101:) |
| 7 | =A4.(max(0,~-A5(#),A6(#)-~)/(A5(#)-A6(#))) |
SPL有很强大的集合运算能力,实现区间上的阈值计算很方便。这段代码仅是个示意,并不完整,其中还调用了计算阈值的函数,而这个函数在不同场景要使用不同的计算方法,很难通用起来。这个问题足够大,值得专门撰文讨论,但并不是本文重点,所以就不再列出了,这并不影响理解其中的原理。
计算结果示例如下:
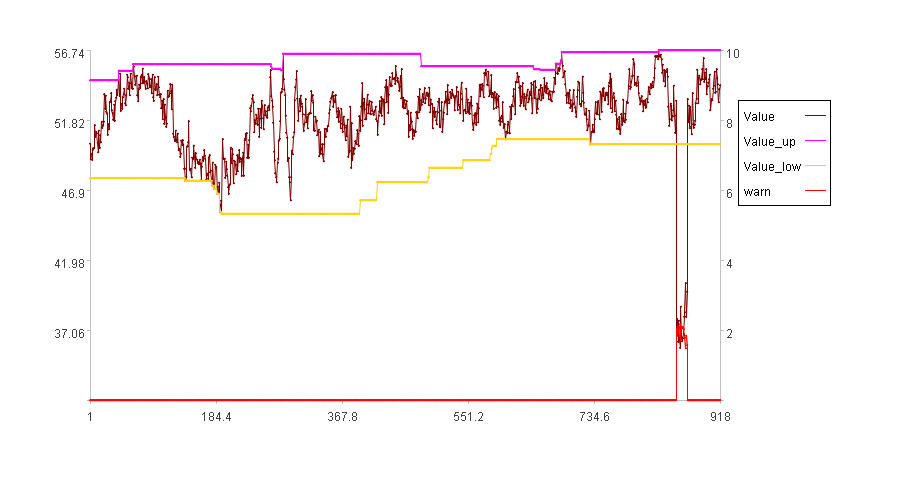
图中Value是数据,Value_up是动态上限,Value_low是动态下限,warn是异常度。从图中可以看出,算法准确发现了值过小的异常。
如果观察变化率,大体的SPL代码:
| A | |
| 1 | =file(C1).import@tci() |
| 2 | =A1.((ss=if(#<=D1,~[0:D1],~[-D1:0]),slope(ss))) |
| 3 | =A2.(if(#<=D2,,threshold(~[-D2:0],"up",3))) |
| 4 | =A2.(0) |
| 5 | =A2.m(D2+1:) |
| 6 | =A3.m(D2+1:) |
| 7 | =A4.m(D2+1:) |
| 8 | =A5.(max(0,~-A6(#),A7(#)-~)/(A6(#)-A7(#))) |
类似地,A2中使用了动态计算“变化快慢”这一数学量的方法,后续的代码和前面判断值的异常度时类似。
“变化快慢”发现异常结果如下:
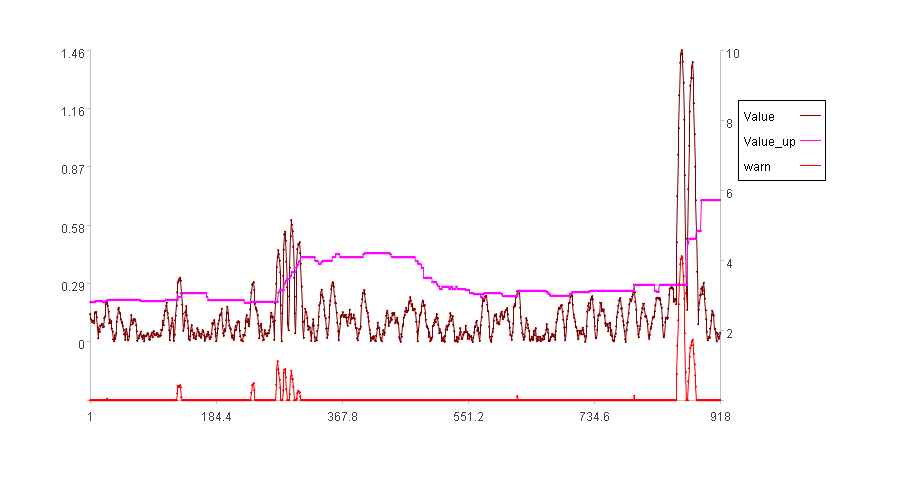
从图中证明算法是有效的,变化过快的地方可以准确发现。
值和“变化快慢”甚至更多特征数据都可以用来发现异常,可以单独使用也可以综合使用,只要通过某种数学方式将他们合并成一个表征综合异常度的量即可。
关联问题
工业生产过程中,有些仪表之间是相互关联的,比如温度升高、压力上升;阀门开度增加、流量增大等等。有时只看单个仪表并不能说明整体异常了,需要观察相互关联仪表的异常情况,才能确定整个系统是否真的出问题了。就好比打喷嚏、嗓子疼、流鼻涕、发烧同时发生时,我们就可以说这个人感冒了,如果只是单一症状,如嗓子疼,可能只是因为这个人大声说话喊破嗓子了,并不能断定这个人感冒了。
我们已经可以计算单个仪表的异常度了,将相互关联的仪表看成一组,同时观察他们各自的异常度,用某种数学方式将他们的异常度聚合起来,就可以得到这组仪表的异常度了。
算法思路
如何将一组仪表的异常度聚合呢?
先来看一组数据:

这里有五个仪表的曲线,红色部分为该仪表异常的部分。
还是先来看看人对时段①②③异常的分析情况:
时段①:只有1个仪表异常且异常度不大,该时段聚合后的异常度应该不大;
时段②:有3个仪表异常,但强度不大,聚合的强度应该也不大;
时段③:有4个仪表异常,而且强度较大,报警强度应该大。
将一组仪表的异常度聚合起来,容易想到的办法就是将所有仪表的异常度平均。但是这意味着对所有仪表一视同仁,即各个仪表同等重要。实际上可能并不是这样,还以感冒为例,发烧这一症状要比嗓子疼和打喷嚏重要得多,需要给它赋予更高的权重。仪表也是类似的,有些仪表测量的指标非常关键,有些可能不太重要,为每个仪表分别赋予权重才能得到更准确的聚合异常度。
那么,权重从何而来?
简单有效的办法是工艺专家提供,可有时专家也不确定各个仪表权重的具体数值,如果能由计算机自动算出各个仪表的权重就更好了。
那么,又怎么自动算权重呢?
先来看个故事:
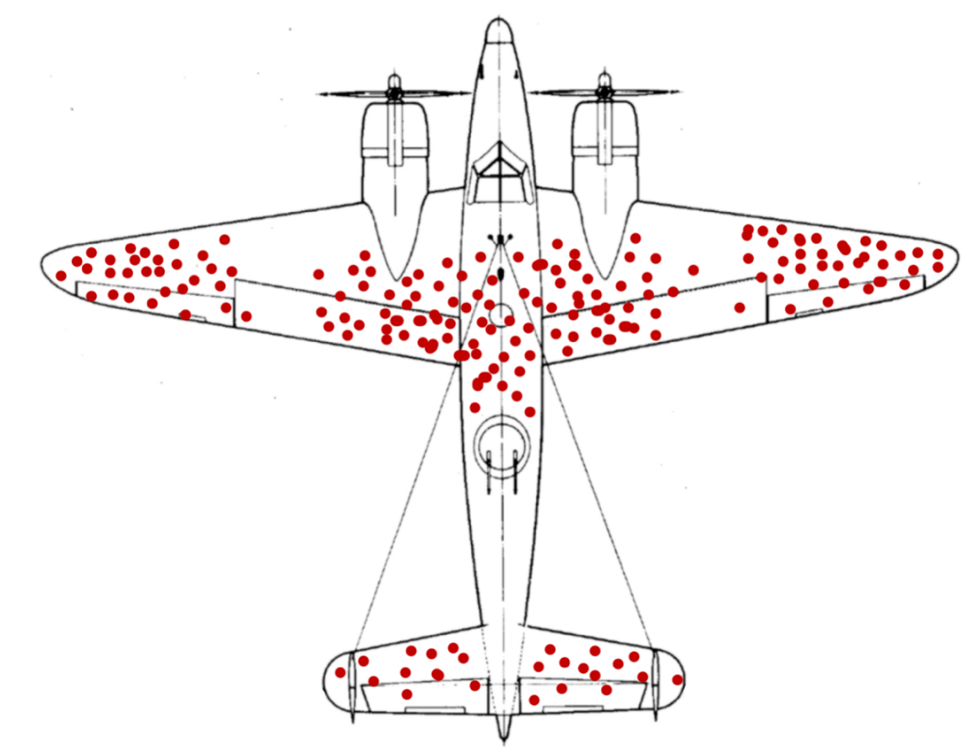
上图是二战时盟军返航飞机弹孔分布图,从图中可以看到,这些弹孔分布并不均匀,翅膀上比较多,引擎上比较少。当时军方普遍认为,应该减少装甲总量,然后在受攻击最多的部位增加装甲,这样飞机可以轻一点,但是防护作用不会减弱,因为防御的效率提高了。但是,这些部位需要增加多少装甲,他们并不清楚,于是找到瓦尔德(哥伦比亚大学的统计研究学家),希望得到答案。但是,瓦尔德彻底否定了他们的想法,给出了相反的答案。
瓦尔德认为,需要加装装甲的地方不应该是留有弹孔的地方,反而是没有弹孔的地方,即飞机的引擎。
瓦尔德说,飞机各部位被击中的概率应该是均等的,但是引擎上的弹孔却比其余部位少,这说明那些被击中引擎的飞机根本没有机会返航。我们看到的数据,都来自成功返航的飞机,这说明即便翅膀被打得千疮百孔,仍能安全返航。
军方马上按照瓦尔德的建议改进了飞机,取得了良好的效果。
这就是“幸存者偏差”。我们不能只考虑看到的数据(返航的飞机),更应该考虑看不到的数据(未返航的飞机)。
为了避免幸存者偏差,各仪表权重的分配方法应该遵循这样的原则:历史上经常异常且异常度大的仪表(相当于机翼)权重小,不常发生异常且异常度小的仪表(相当于引擎)权重大。根据这样的原则,使用一些数学方法计算各仪表的权重,最后利用权重与各仪表的异常度计算出聚合后的异常度。
实践效果
用SPL实现上述算法的关键代码:
| A | |
| 1 | =file("Adata.csv").read() |
| 2 | =A1.(~.array()) |
| 3 | =A2.(if(#<=100,null,weight(A14,~[-100:0]))) |
| 4 | =A2.to(101:) |
| 5 | =A3.to(101:) |
| 6 | =A4.((~A5(#)).sum()) |
这里,A3中计算权值的方法也是要随情况而定的。
计算结果示例如下:
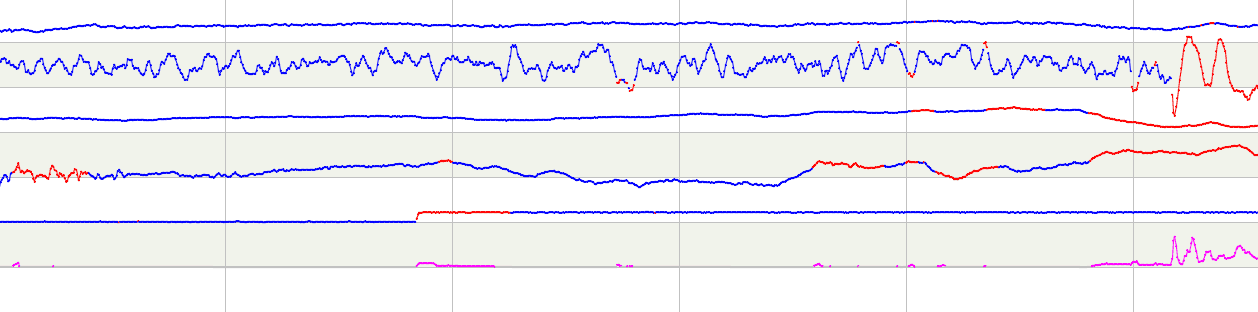
最下面一条曲线是五个仪表聚合后的异常度,其中粉色部分表示异常,从图中可以看出异常基本符合我们的判断,即异常仪表数量越多且异常度越大,聚合后的异常度越强。
进一步的关联问题
多仪表的异常度可以利用单仪表的异常度来聚合计算,如果所有仪表异常度都是0,那么聚合后的异常度肯定也是0。那是不是就说明设备工作很正常呢?
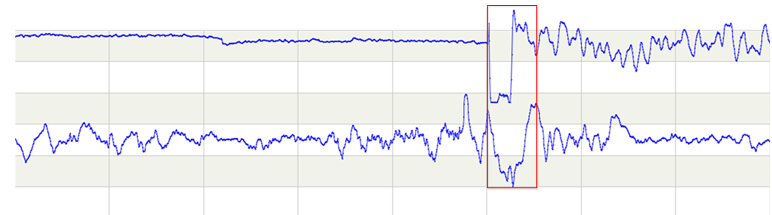
试想这样一种情况,有两个关系密切的仪表A和B,仪表A上升时B也上升,A下降B也下降,如果两个仪表都在各自正常的范围内,但是出现了A上升B却下降的情况,此时是不是也应该被认为是异常呢?如下图:

图中红框就是这种情况,这肯定要算作异常,可是前面说的聚合办法并不能解决这类问题,需要换一个角度来思考如何解决这类问题。
既然一组仪表之间存在某种关系,那么多数情况下都会保持这种关系,只有少数情况下会失去关系,回到我们单仪表发现异常的思路上——没出现或者不常出现的情况是异常。那么,只要有办法表征多个仪表共同状态中不常出现的程度,也就可以发现这种关联的异常了。
算法思路
还是先让人来观察仪表形成曲线图
观察后,人能给出红框中的数据大体属于异常数据。但是,两个曲线是否有关联关系,从这个图中是观察不到的。统计学知识告诉我们,可以用散点图来观察曲线之间的关联性,如下: 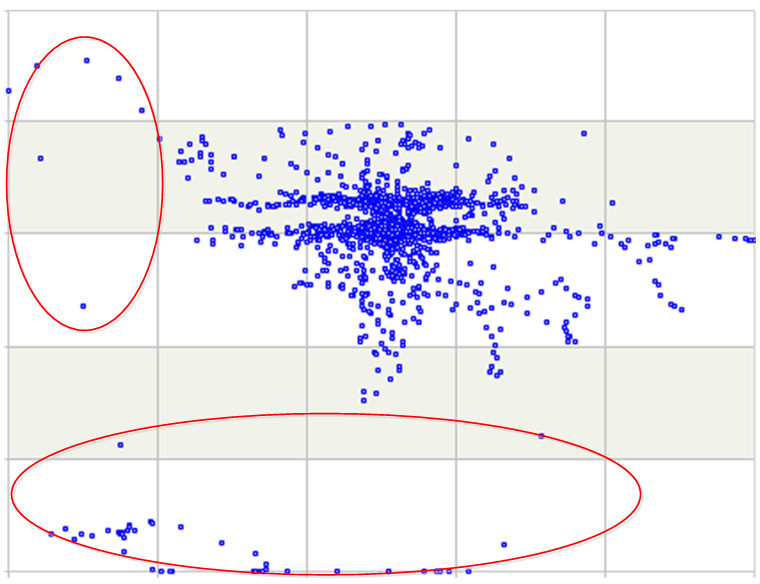
图中横纵坐标分别是两个仪表的数值。这样就一目了然了,两个仪表的数据多数都聚集在一起,只有少数分散在边缘。根据我们的判断标准——没出现或者不常出现的情况是异常,就可以判定图中红圈中的数据为异常。然后,只要利用数学方法把这些散点找出来并算出他们的异常度即可。
实践效果
用SPL实现的关键代码:
| A | |
| 1 | =file("Jdata.csv").read() |
| 2 | =A1.(~.array()) |
| 3 | =A2.(if(#<=100,,join_o(~[-100:0],0.7,1.5))) |
| 4 | =A3.to(101,) |
| 5 | =A4.(if(~(1)>~(2),0,(~(2)-~(1))/~(2))) |
A3格中关联方法同样要根据情况来确定。
计算结果示例如下:
先来看我们造的那组数据:

图中红色部分是多仪表联合算法发现的异常。
相应的散点图是这样:
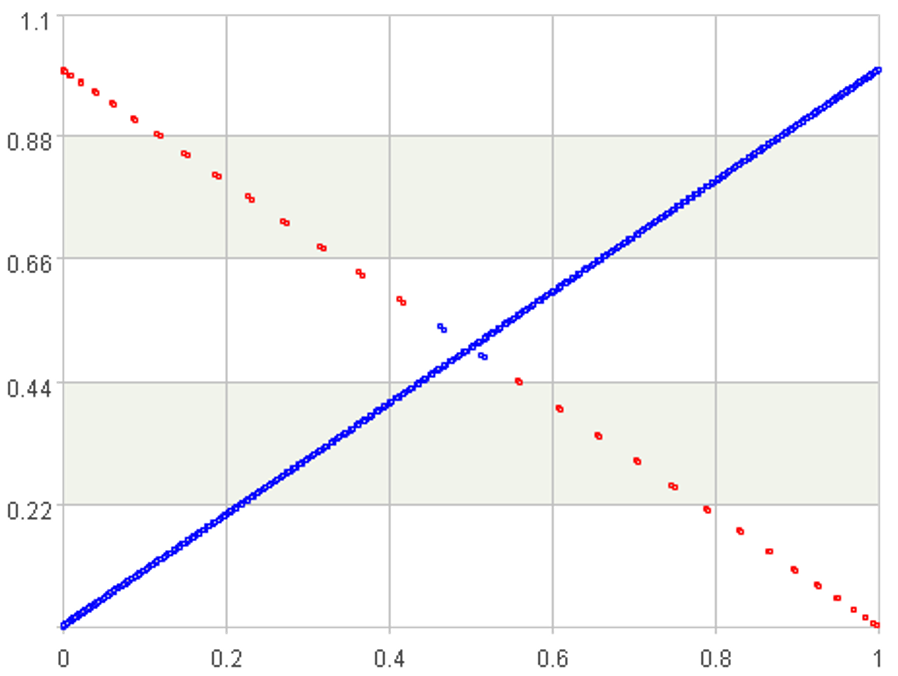
图中红色点就对应前面走势图中的红色曲线部分,也就是异常数据。
再来看刚才的实际数据:
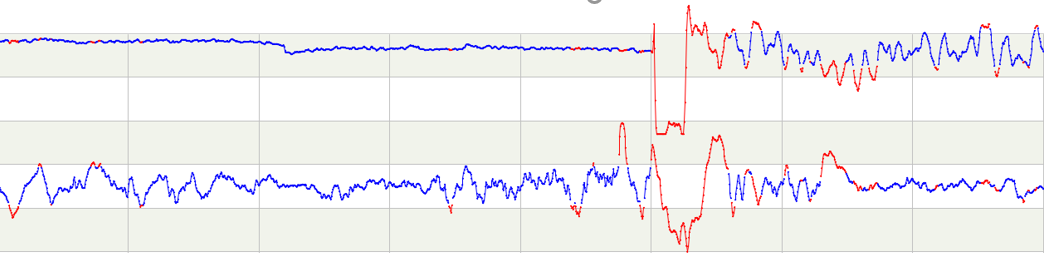
图中红色部分是基于刚才说的多仪表散点图方法发现的异常。
相应的散点图如下:
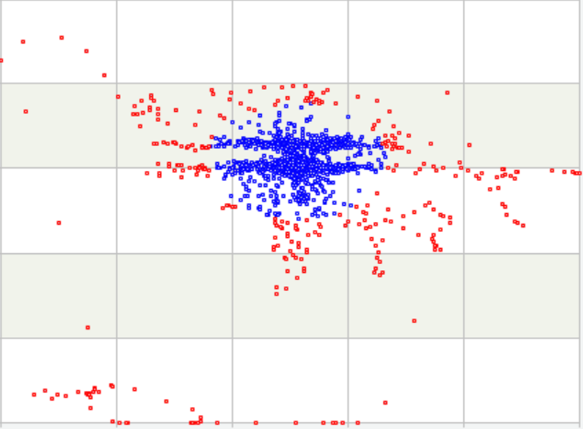
图中红色点对应曲线走势图的红色曲线部分。
可以看出,这个办法可以较准确地发现这些数据的异常。
为简单起见,上述两组数据都只有两个仪表,只是为了方便读者理解,更多仪表同样可以用这个办法来发现异常,只是把两维空间扩展到N维空间,算法并没有太大不同,只是没法画出图了。
最后,还要再重申一下:这里的代码只是示意性的,并不完整。实际情况中具体函数计算式的选择会各自不同,同时还要考虑数据归一化、离群值剔除、异常累积等各种问题,完整代码就会很长,全盘列出讲解会占用过大篇幅也没太大必要。有兴趣的读者可以和我们联系讨论,本文的重点还是解释原理。
开发这类算法常常需要做大量实验来选择合适的函数计算式并调整参数,SPL编程的高效性就会发挥巨大的作用,在同样的时间内能够尝试更多种方案。
资料
- SPL下载
- SPL源代码

