MYSQL的社死----死锁
目录
排查锁命令
死锁诞生
为什么会有死锁
Insert 语句会产生哪些行级锁
记录有间隙锁
insert唯一键冲突
解决死锁
update 语句事故
解决update 语句事故
排查锁命令
#查询是否锁表
show OPEN TABLES where In_use > 0;
#查询进程(如果您有SUPER权限,您可以看到所有线程。否则,您只能看到您自己的线程)
show processlist
#查看当前的事务
SELECT * FROM INFORMATION_SCHEMA.INNODB_TRX;
#查看当前锁定的事务
SELECT * FROM INFORMATION_SCHEMA.INNODB_LOCKS;
#查看当前等锁的事务
SELECT * FROM INFORMATION_SCHEMA.INNODB_LOCK_WAITS;
#杀死进程
kill 线程ID//显式锁状态
show engine innoDB status;
//查询当前MySQL进程状态
SHOW FULL PROCESSLIST;
在MySQL5.7版本中,也可以使用sys.innodb_lock_waits试图查看,但是在MySQL8.0中,该视图连接查询的表不同(把之前版本中使用的information_schema.innodb_locks表和information_schema.innodb_lock_waits)表替换为了performance_schema.data_locks和performance_schema.data_lock_waits)表
死锁诞生
测试数据,如下:
在mysql存储引擎 Innodb和隔离级别为可重复读(RR)下发生的死锁现象如下:

在没有打开死锁检测的前提下,事务A和事务B这两个事情会陷入等待状态,也就是陷入了死锁状态。
但是如果我们不使用select ... for update语句,直接使用普通的select语句,那么插入两条相同的数据,(b不具有唯一性)如下:

为什么会有死锁
因为在Innodb 引擎中为了解决「可重复读」隔离级别下的幻读问题,就引出了 next-key 锁。
从上面的例子我们知道,在执行插入语句时,会去获取插入意向锁。而插入意向锁与间隙锁是冲突的,所以当其它事务持有该间隙的间隙锁时,需要等待其它事务释放间隙锁之后,才能获取到插入意向锁。而间隙锁与间隙锁之间是兼容的,所以所以两个事务中 select ... for update 语句并不会相互影响。所以造成了循环等待,导致死锁。
Insert 语句会产生哪些行级锁
insert语句在正常执行的时候是不会生成锁结构的,它是靠聚簇索引记录自带的 trx_id 隐藏列来作为隐式锁来保护记录的。
隐式锁?
隐式锁就是在事务加锁的时候,如果这个锁不可能发生冲突,那么innodb会跳过加锁环节。即隐式锁是innodb的一种延迟加锁机制,只有存在发生锁冲突可能的时候加锁,这样可以减少加锁数量,从而提高性能。也就是说只有特殊情况下,才会把隐式锁转化为显示锁,例如:
1. 记录之间加有间隙锁,为了避免幻读,此时是不能插入记录的
2. Insert 的记录和已有记录存在唯一键冲突,此时也不能插入记录
下面执行的mysql版本为:

记录有间隙锁
每插入一条记录,都需要检查待插入就记录的下一条记录是否加入了间隙锁,如果是,那么insert语句就会给堵塞,并生成插入意向锁。
如我们执行下面代码:

然后我们使用select * from performance_schema.data_locks\G; 语句可以确定事务加了那么锁类型:
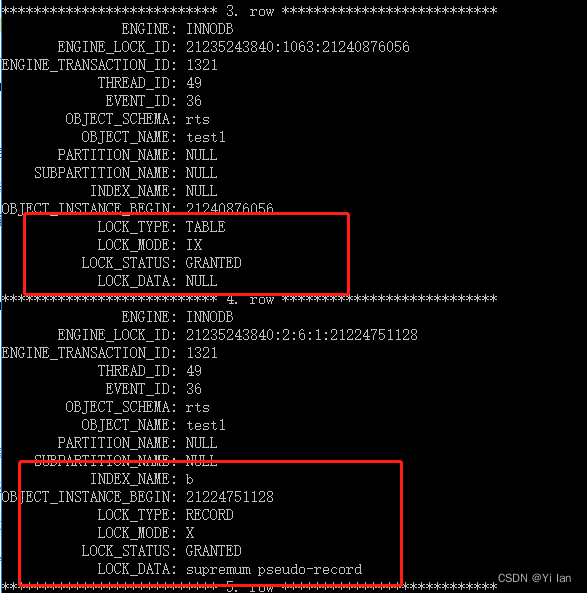
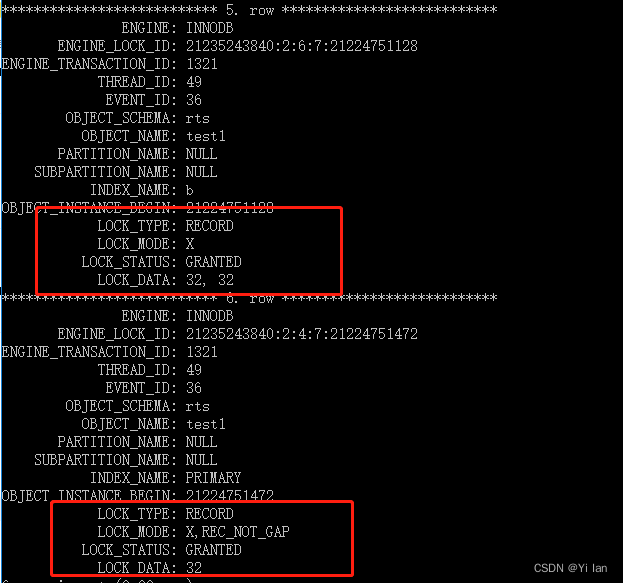
图说明:
1. 加的是 X 型得锁,注意,LOCK_TYPE 中的 RECORD 表示行级锁,而不是记录锁的意思
2.通过 LOCK_MODE 可以确认是「next-key 锁或者间隙锁」,还是「记录锁」
3. 通过 LOCK_DATA 信息来区分是next-key 锁,还是间隙锁。
LOCK_MODE区分:
1. LOCK_MODE为 X,说明是 next-key 锁或者间隙锁;
2. LOCK_MODE 为
X, REC_NOT_GAP,说明是记录锁
是next-key 锁,还是间隙锁,就要看 LOCK_DATA 信息:
1. LOCK_DATA 信息为 supremum,说明是间隙锁;
2. LOCK_DATA 信息为具体的记录值,说明是 next-key;
如果我们此时执行:
insert into test1 value(33,33,33);
那么执行图如下:
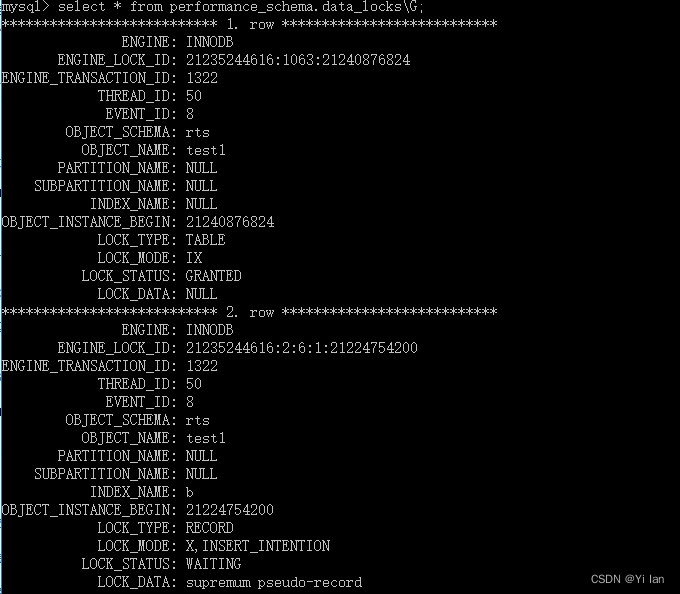
从图中我们看到该事物属于等待状态,而且生成了插入意向锁(LOCK_MODE:X,INSERT_INTENTION)
insert唯一键冲突
如果我们在插入新纪录时,插入的记录与已有的记录的主键或者唯一二级索引列值相同(唯一二级索引列的值不为NULL),此时插入就会失败,并给这条记录加上了 S 型的锁。
至于加的锁类型是记录锁,还是 next-key 锁,跟是主键冲突还是唯一二级索引冲突有关系。
主键冲突:
1. 当隔离级别为读已提交时,插入新记录的事务会给已存在的主键值重复的聚簇索引记录添加 S 型记录锁。
2. 当隔离级别为读已提交时,插入新记录的事务会给已存在的主键值重复的聚簇索引记录添加 S 型记录锁
唯一二级索引冲突:
不论是哪个隔离级别,插入新记录的事务都会给已存在的二级索引列值重复的二级索引记录添加 S 型 next-key 锁。(读已提交隔离级别中为数不多的给记录添加间隙锁的场景)
下面我们向表执行下面语句:

然后执行select * from performance_schema.data_locks\G; 语句,查看锁类型:
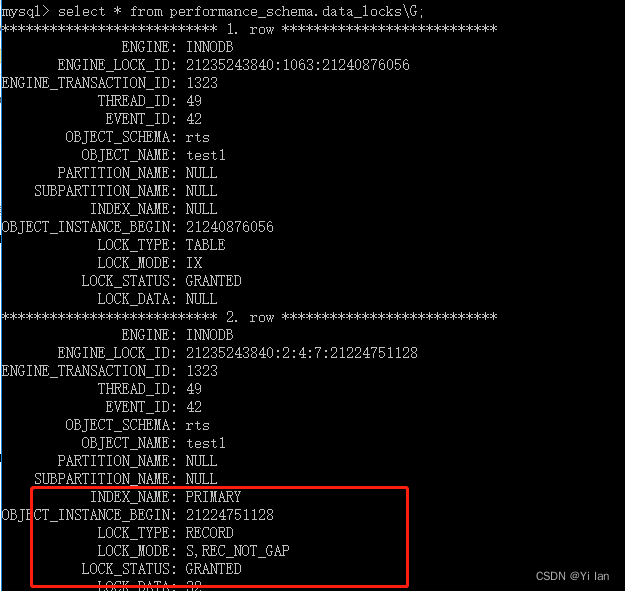
从图我们可以知道LOCK_MODE 会显示 S, REC_NOT_GAP。如果此时我们再执行select * from test1 where id = 32 for update;语句,会发现给堵塞了。因为这条语句要加 X 型的锁与之前的S 型的锁是冲突了。
我们再通过select * from performance_schema.data_locks\G; 语句,查看这个查询语句的锁类型:
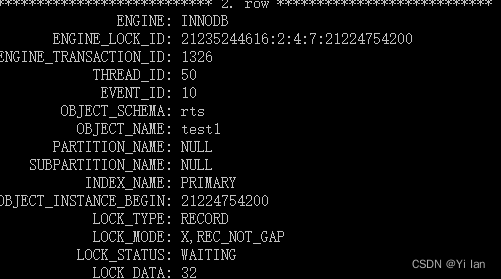
该查询语句的LOCK_STATUS是等待状态,加锁的类型 X 型的记录锁(LOCK_MODE: X,REC_NOT_GAP )。
如果我们同时向表中插入一条相同的记录会发生什么事情?
在隔离级别可重复读的情况下,开启两个事务,前后执行相同的 Insert 语句,此时后面执行 的 Insert 语句会发生阻塞。
过程分析:
1. 第一次插入(事务 A )的语句会成功,而且此时记录被「隐式锁」保护,此时还没有实际的锁结构;
2. 第二次插入遇到重复的唯一索引列值,而加上S 型 next-key 锁。但是事务 A 并未提交,事务 A 插入的 的记录上的「隐式锁」会变「显示锁」且锁类型为 X 型的记录锁,所以事务 B 向获取 S 型 next-key 锁时会遇到锁冲突,事务 B 进入阻塞状态。
我们再通过select * from performance_schema.data_locks\G; 语句,查看这个查询语句的锁类型:
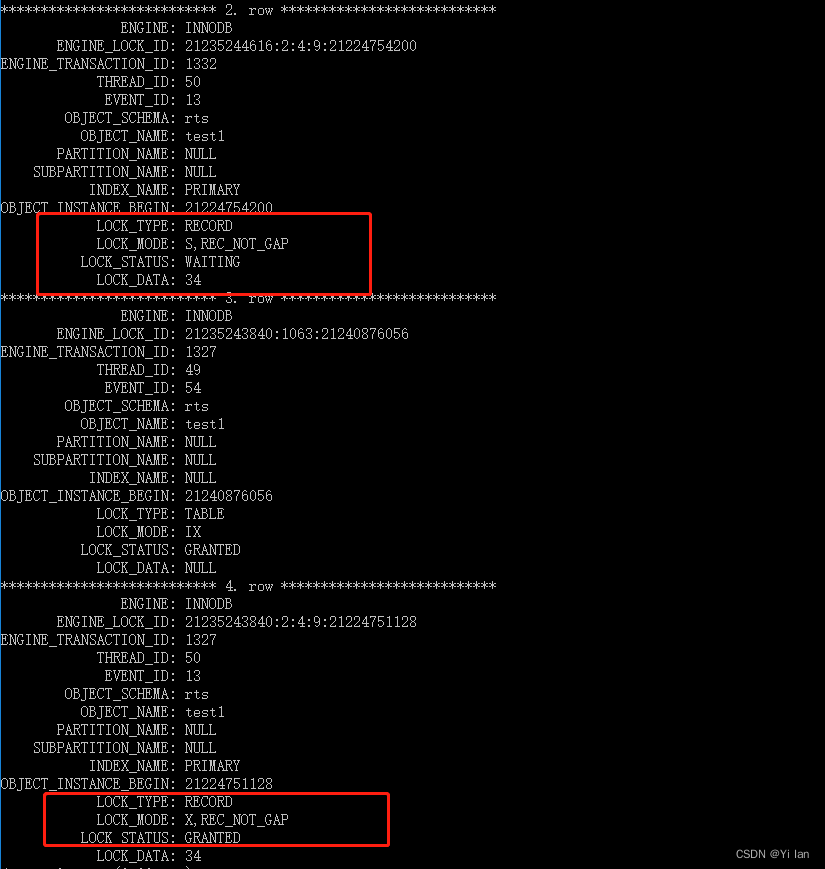
结论: 并发多个事务的时候,第一个事务插入的记录,并不会加锁,而是会用隐式锁保护唯一索引的记录。但是在第一个事务还未提交的时候,有其他事务插入了与第一个事务相同的记录,第二个事务就会被阻塞,因为此时第一事务插入的记录中的隐式锁会变为显示锁且类型是 X 型的记录锁,而第二个事务是想对该记录加上 S 型的 next-key 锁,X 型与 S 型的锁是冲突的,所以导致第二个事务会等待,直到第一个事务提交后,释放了锁。
解决死锁
形成死锁必须同时满足下面四个条件:
互斥、占有且等待、不可强占用、循环等待
所以我们只要能攻破这四大天皇之一,就可以解决。下面给出两种策略,下如:
1. 设置等待超时。就是一个事务等待时间不能超过该值,如果超过该值就会回滚事务,释放锁,让其他事务继续执行。在innodb中,我们可以通过参数
innodb_lock_wait_timeout来控制,默认是50秒2. 开启主动死锁检测。就是主动死锁检测到死锁之后,会主动回滚死锁中的某个事务,并释放锁,让其他事务继续执行下去。在innodb中,我们可以通过参数
innodb_deadlock_detect来控制,默认是ON(开启)
两种策略的提示分别是:
超时:
主动死锁检测:


当然了,我们最好的策略那就是在自己的业务上预防死锁的出现。比如上面的例子,可以在b中加上唯一性。
update 语句事故
那么会发生事务B会发生堵塞,如下图:
 如果按照MYSQL锁的探索中的行锁,我们知道事务A会加上 next-key 锁,但是由于a列是无索引列,所以所有记录都会被加锁,相当于锁住了全表。
如果按照MYSQL锁的探索中的行锁,我们知道事务A会加上 next-key 锁,但是由于a列是无索引列,所以所有记录都会被加锁,相当于锁住了全表。
结论:在 update 语句的 where 条件没有使用索引,就会全表扫描,于是就会对所有记录加上 next-key 锁(记录锁 + 间隙锁),相当于把整个表锁住了
解决update 语句事故
通过mysql官方文档我们知道,如果mysql里的sql_safe_updates参数设置为 1( 默认为0),即开启了安全更新模式
在该模式下,update 语句执行成功必须满足下面条件之一:
1. where 条件中必须有索引列
2. 使用 limit
delete 语句执行成功必须满足下面条件之一:
1. where 条件中必须有索引列
2. 同时使用 where 和 limit,此时 where 条件中可以没有索引列
如果 where 条件带上了索引列,但是优化器最终扫描选择的是全表,而不是索引的话,我们可以使用 force index([index_name]) 可以告诉优化器使用哪个索引,以此避免有几率锁全表带来的隐患。

