知识蒸馏IRG算法实战:使用ResNet50蒸馏ResNet18
摘要
复杂度的检测模型虽然可以取得SOTA的精度,但它们往往难以直接落地应用。模型压缩方法帮助模型在效率和精度之间进行折中。知识蒸馏是模型压缩的一种有效手段,它的核心思想是迫使轻量级的学生模型去学习教师模型提取到的知识,从而提高学生模型的性能。已有的知识蒸馏方法可以分别为三大类:
- 基于特征的(feature-based,例如VID、NST、FitNets、fine-grained feature imitation)
- 基于关系的(relation-based,例如IRG、Relational KD、CRD、similarity-preserving knowledge distillation)
- 基于响应的(response-based,例如Hinton的知识蒸馏开山之作。
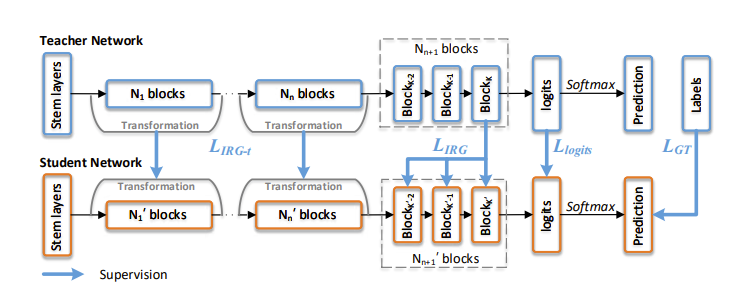
今天我们就尝试用基于关系的IRG知识蒸馏算法完成这篇实战。IRG蒸馏是对模型里面的的Block和展平层做蒸馏,所以需要返回每个block层的值和展平层的值。所以我们对模型要做修改来适应IRG算法,并且为了使Teacher和Student的网络层之间的参数一致,我们这次选用ResNet50作为Teacher模型,选择ResNet18作为Student。
模型
模型没有用pytorch官方自带的,而是参照以前总结的ResNet模型修改的。ResNet模型结构如下图:
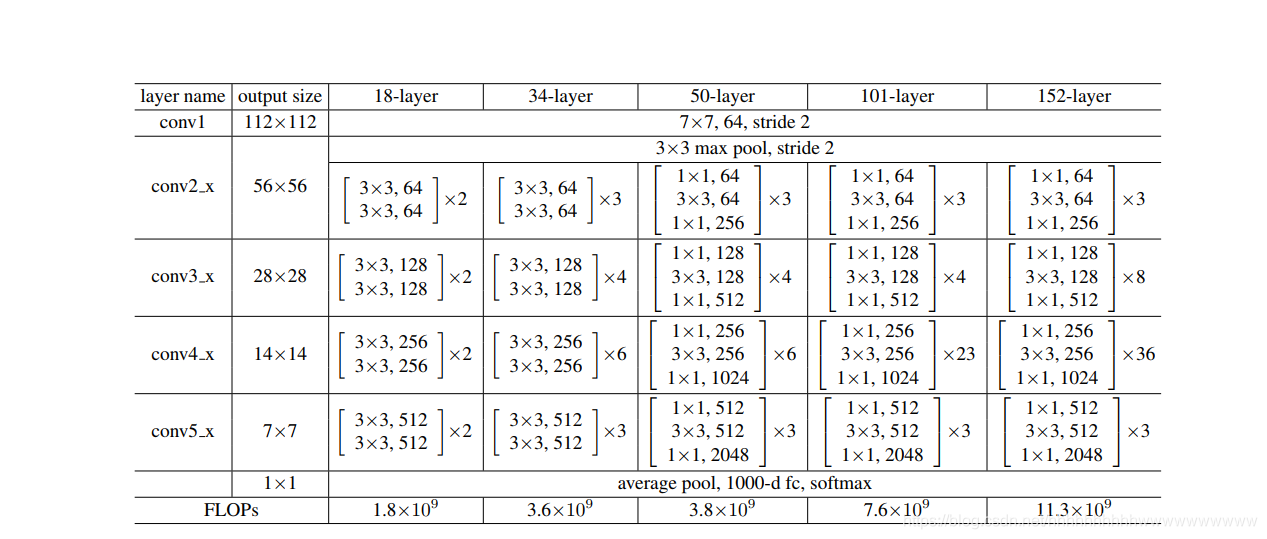
ResNet18, ResNet34
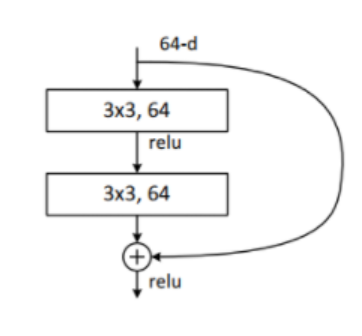
ResNet18, ResNet34模型的残差结构是一致的,结构如下:
代码如下:
resnet.py
import torchimport torchvisionfrom torch import nnfrom torch.nn import functional as F# from torchsummary import summaryclass ResidualBlock(nn.Module): """ 实现子module: Residual Block """ def __init__(self, inchannel, outchannel, stride=1, shortcut=None): super(ResidualBlock, self).__init__() self.left = nn.Sequential( nn.Conv2d(inchannel, outchannel, 3, stride, 1, bias=False), nn.BatchNorm2d(outchannel), nn.ReLU(inplace=True), nn.Conv2d(outchannel, outchannel, 3, 1, 1, bias=False), nn.BatchNorm2d(outchannel) ) self.right = shortcut def forward(self, x): out = self.left(x) residual = x if self.right is None else self.right(x) out += residual return F.relu(out)class ResNet(nn.Module): """ 实现主module:ResNet34 ResNet34包含多个layer,每个layer又包含多个Residual block 用子module来实现Residual block,用_make_layer函数来实现layer """ def __init__(self, blocks, num_classes=1000): super(ResNet, self).__init__() self.model_name = 'resnet34' # 前几层: 图像转换 self.pre = nn.Sequential( nn.Conv2d(3, 64, 7, 2, 3, bias=False), nn.BatchNorm2d(64), nn.ReLU(inplace=True), nn.MaxPool2d(3, 2, 1)) # 重复的layer,分别有3,4,6,3个residual block self.layer1 = self._make_layer(64, 64, blocks[0]) self.layer2 = self._make_layer(64, 128, blocks[1], stride=2) self.layer3 = self._make_layer(128, 256, blocks[2], stride=2) self.layer4 = self._make_layer(256, 512, blocks[3], stride=2) # 分类用的全连接 self.fc = nn.Linear(512, num_classes) def _make_layer(self, inchannel, outchannel, block_num, stride=1): """ 构建layer,包含多个residual block """ shortcut = nn.Sequential( nn.Conv2d(inchannel, outchannel, 1, stride, bias=False), nn.BatchNorm2d(outchannel), nn.ReLU() ) layers = [] layers.append(ResidualBlock(inchannel, outchannel, stride, shortcut)) for i in range(1, block_num): layers.append(ResidualBlock(outchannel, outchannel)) return nn.Sequential(*layers) def forward(self, x): x = self.pre(x) l1_out = self.layer1(x) l2_out = self.layer2(l1_out) l3_out = self.layer3(l2_out) l4_out = self.layer4(l3_out) p_out = F.avg_pool2d(l4_out, 7) fea = p_out.view(p_out.size(0), -1) out=self.fc(fea) return l1_out,l2_out,l3_out,l4_out,fea,outdef ResNet18(): return ResNet([2, 2, 2, 2])def ResNet34(): return ResNet([3, 4, 6, 3])if __name__ == '__main__': device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") model = ResNet34() model.to(device) # summary(model, (3, 224, 224))主要修改了输出结果,将每个block的结果输出出来。
RseNet50、 RseNet101、 RseNet152
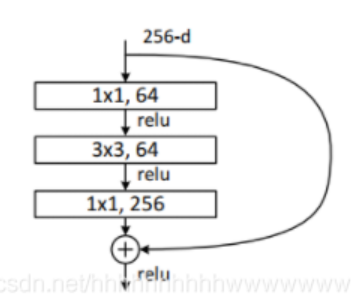
这个三个模型的block是一致的,结构如下:
代码:
resnet_l.py
import torchimport torch.nn as nnimport torchvisionimport numpy as npprint("PyTorch Version: ", torch.__version__)print("Torchvision Version: ", torchvision.__version__)__all__ = ['ResNet50', 'ResNet101', 'ResNet152']def Conv1(in_planes, places, stride=2): return nn.Sequential( nn.Conv2d(in_channels=in_planes, out_channels=places, kernel_size=7, stride=stride, padding=3, bias=False), nn.BatchNorm2d(places), nn.ReLU(inplace=True), nn.MaxPool2d(kernel_size=3, stride=2, padding=1) )class Bottleneck(nn.Module): def __init__(self, in_places, places, stride=1, downsampling=False, expansion=4): super(Bottleneck, self).__init__() self.expansion = expansion self.downsampling = downsampling self.bottleneck = nn.Sequential( nn.Conv2d(in_channels=in_places, out_channels=places, kernel_size=1, stride=1, bias=False), nn.BatchNorm2d(places), nn.ReLU(inplace=True), nn.Conv2d(in_channels=places, out_channels=places, kernel_size=3, stride=stride, padding=1, bias=False), nn.BatchNorm2d(places), nn.ReLU(inplace=True), nn.Conv2d(in_channels=places, out_channels=places * self.expansion, kernel_size=1, stride=1, bias=False), nn.BatchNorm2d(places * self.expansion), ) if self.downsampling: self.downsample = nn.Sequential( nn.Conv2d(in_channels=in_places, out_channels=places * self.expansion, kernel_size=1, stride=stride, bias=False), nn.BatchNorm2d(places * self.expansion) ) self.relu = nn.ReLU(inplace=True) def forward(self, x): residual = x out = self.bottleneck(x) if self.downsampling: residual = self.downsample(x) out += residual out = self.relu(out) return outclass ResNet(nn.Module): def __init__(self, blocks, num_classes=1000, expansion=4): super(ResNet, self).__init__() self.expansion = expansion self.conv1 = Conv1(in_planes=3, places=64) self.layer1 = self.make_layer(in_places=64, places=64, block=blocks[0], stride=1) self.layer2 = self.make_layer(in_places=256, places=128, block=blocks[1], stride=2) self.layer3 = self.make_layer(in_places=512, places=256, block=blocks[2], stride=2) self.layer4 = self.make_layer(in_places=1024, places=512, block=blocks[3], stride=2) self.avgpool = nn.AvgPool2d(7, stride=1) self.fc = nn.Linear(2048, num_classes) for m in self.modules(): if isinstance(m, nn.Conv2d): nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu') elif isinstance(m, nn.BatchNorm2d): nn.init.constant_(m.weight, 1) nn.init.constant_(m.bias, 0) def make_layer(self, in_places, places, block, stride): layers = [] layers.append(Bottleneck(in_places, places, stride, downsampling=True)) for i in range(1, block): layers.append(Bottleneck(places * self.expansion, places)) return nn.Sequential(*layers) def forward(self, x): x = self.conv1(x) l1_out = self.layer1(x) l2_out = self.layer2(l1_out) l3_out = self.layer3(l2_out) l4_out = self.layer4(l3_out) p_out = self.avgpool(l4_out) fea = p_out.view(p_out.size(0), -1) out = self.fc(fea) return l1_out, l2_out, l3_out, l4_out, fea, outdef ResNet50(): return ResNet([3, 4, 6, 3])def ResNet101(): return ResNet([3, 4, 23, 3])def ResNet152(): return ResNet([3, 8, 36, 3])if __name__ == '__main__': # model = torchvision.models.resnet50() model = ResNet50() print(model) input = torch.randn(1, 3, 224, 224) out = model(input) print(out.shape)同上,将每个block都输出出来。
数据准备
数据使用我以前在图像分类任务中的数据集——植物幼苗数据集,先将数据集转为训练集和验证集。执行代码:
import globimport osimport shutilimage_list=glob.glob('data1/*/*.png')print(image_list)file_dir='data'if os.path.exists(file_dir): print('true') #os.rmdir(file_dir) shutil.rmtree(file_dir)#删除再建立 os.makedirs(file_dir)else: os.makedirs(file_dir)from sklearn.model_selection import train_test_splittrainval_files, val_files = train_test_split(image_list, test_size=0.3, random_state=42)train_dir='train'val_dir='val'train_root=os.path.join(file_dir,train_dir)val_root=os.path.join(file_dir,val_dir)for file in trainval_files: file_class=file.replace("\\","/").split('/')[-2] file_name=file.replace("\\","/").split('/')[-1] file_class=os.path.join(train_root,file_class) if not os.path.isdir(file_class): os.makedirs(file_class) shutil.copy(file, file_class + '/' + file_name)for file in val_files: file_class=file.replace("\\","/").split('/')[-2] file_name=file.replace("\\","/").split('/')[-1] file_class=os.path.join(val_root,file_class) if not os.path.isdir(file_class): os.makedirs(file_class) shutil.copy(file, file_class + '/' + file_name)训练Teacher模型
Teacher选用ResNet50。
步骤
新建teacher_train.py,插入代码:
导入需要的库
import torch.optim as optimimport torchimport torch.nn as nnimport torch.nn.parallelimport torch.utils.dataimport torch.utils.data.distributedimport torchvision.transforms as transformsfrom torchvision import datasetsfrom torch.autograd import Variablefrom model.resnet_l import ResNet50import jsonimport os定义训练和验证函数
def train(model, device, train_loader, optimizer, epoch): model.train() sum_loss = 0 total_num = len(train_loader.dataset) print(total_num, len(train_loader)) for batch_idx, (data, target) in enumerate(train_loader): data, target = Variable(data).to(device), Variable(target).to(device) l1_out,l2_out,l3_out,l4_out,fea, out = model(data) loss = criterion(out, target) optimizer.zero_grad() loss.backward() optimizer.step() print_loss = loss.data.item() sum_loss += print_loss if (batch_idx + 1) % 10 == 0: print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format( epoch, (batch_idx + 1) * len(data), len(train_loader.dataset), 100. * (batch_idx + 1) / len(train_loader), loss.item())) ave_loss = sum_loss / len(train_loader) print('epoch:{},loss:{}'.format(epoch, ave_loss))Best_ACC=0# 验证过程@torch.no_grad()def val(model, device, test_loader): global Best_ACC model.eval() test_loss = 0 correct = 0 total_num = len(test_loader.dataset) print(total_num, len(test_loader)) with torch.no_grad(): for data, target in test_loader: data, target = Variable(data).to(device), Variable(target).to(device) l1_out,l2_out,l3_out,l4_out,fea, out = model(data) loss = criterion(out, target) _, pred = torch.max(out.data, 1) correct += torch.sum(pred == target) print_loss = loss.data.item() test_loss += print_loss correct = correct.data.item() acc = correct / total_num avgloss = test_loss / len(test_loader) if acc > Best_ACC: torch.save(model, file_dir + '/' + 'best.pth') Best_ACC = acc print('\nVal set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format( avgloss, correct, len(test_loader.dataset), 100 * acc)) return acc定义全局参数
if __name__ == '__main__': # 创建保存模型的文件夹 file_dir = 'CoatNet' if os.path.exists(file_dir): print('true') os.makedirs(file_dir, exist_ok=True) else: os.makedirs(file_dir) # 设置全局参数 modellr = 1e-4 BATCH_SIZE = 16 EPOCHS = 100 DEVICE = torch.device('cuda' if torch.cuda.is_available() else 'cpu')图像预处理与增强
# 数据预处理7 transform = transforms.Compose([ transforms.RandomRotation(10), transforms.GaussianBlur(kernel_size=(5, 5), sigma=(0.1, 3.0)), transforms.ColorJitter(brightness=0.5, contrast=0.5, saturation=0.5), transforms.Resize((224, 224)), transforms.ToTensor(), transforms.Normalize(mean=[0.44127703, 0.4712498, 0.43714803], std=[0.18507297, 0.18050247, 0.16784933]) ]) transform_test = transforms.Compose([ transforms.Resize((224, 224)), transforms.ToTensor(), transforms.Normalize(mean=[0.44127703, 0.4712498, 0.43714803], std=[0.18507297, 0.18050247, 0.16784933]) ])读取数据
使用pytorch默认读取数据的方式。
# 读取数据 dataset_train = datasets.ImageFolder('data/train', transform=transform) dataset_test = datasets.ImageFolder("data/val", transform=transform_test) with open('class.txt', 'w') as file: file.write(str(dataset_train.class_to_idx)) with open('class.json', 'w', encoding='utf-8') as file: file.write(json.dumps(dataset_train.class_to_idx)) # 导入数据 train_loader = torch.utils.data.DataLoader(dataset_train, batch_size=BATCH_SIZE, shuffle=True) test_loader = torch.utils.data.DataLoader(dataset_test, batch_size=BATCH_SIZE, shuffle=False)设置模型和Loss
# 实例化模型并且移动到GPU criterion = nn.CrossEntropyLoss() model_ft = ResNet50() num_ftrs = model_ft.fc.in_features model_ft.fc = nn.Linear(num_ftrs, 12) model_ft.to(DEVICE) # 选择简单暴力的Adam优化器,学习率调低 optimizer = optim.Adam(model_ft.parameters(), lr=modellr) cosine_schedule = optim.lr_scheduler.CosineAnnealingLR(optimizer=optimizer, T_max=20, eta_min=1e-9) # 训练 val_acc_list= {} for epoch in range(1, EPOCHS + 1): train(model_ft, DEVICE, train_loader, optimizer, epoch) cosine_schedule.step() acc=val(model_ft, DEVICE, test_loader) val_acc_list[epoch]=acc with open('result.json', 'w', encoding='utf-8') as file: file.write(json.dumps(val_acc_list)) torch.save(model_ft, 'CoatNet/model_final.pth')完成上面的代码就可以开始训练Teacher网络了。
学生网络
学生网络选用ResNet18,是一个比较小一点的网络了,模型的大小有40M。训练100个epoch。
步骤
新建student_train.py,插入代码:
导入需要的库
import torch.optim as optimimport torchimport torch.nn as nnimport torch.nn.parallelimport torch.utils.dataimport torch.utils.data.distributedimport torchvision.transforms as transformsfrom torchvision import datasetsfrom torch.autograd import Variablefrom model.resnet import ResNet18import jsonimport os定义训练和验证函数
# 定义训练过程def train(model, device, train_loader, optimizer, epoch): model.train() sum_loss = 0 total_num = len(train_loader.dataset) print(total_num, len(train_loader)) for batch_idx, (data, target) in enumerate(train_loader): data, target = Variable(data).to(device), Variable(target).to(device) l1_out,l2_out,l3_out,l4_out,fea,out = model(data) loss = criterion(out, target) optimizer.zero_grad() loss.backward() optimizer.step() print_loss = loss.data.item() sum_loss += print_loss if (batch_idx + 1) % 10 == 0: print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format( epoch, (batch_idx + 1) * len(data), len(train_loader.dataset), 100. * (batch_idx + 1) / len(train_loader), loss.item())) ave_loss = sum_loss / len(train_loader) print('epoch:{},loss:{}'.format(epoch, ave_loss))Best_ACC=0# 验证过程@torch.no_grad()def val(model, device, test_loader): global Best_ACC model.eval() test_loss = 0 correct = 0 total_num = len(test_loader.dataset) print(total_num, len(test_loader)) with torch.no_grad(): for data, target in test_loader: data, target = Variable(data).to(device), Variable(target).to(device) l1_out,l2_out,l3_out,l4_out,fea,out = model(data) loss = criterion(out, target) _, pred = torch.max(out.data, 1) correct += torch.sum(pred == target) print_loss = loss.data.item() test_loss += print_loss correct = correct.data.item() acc = correct / total_num avgloss = test_loss / len(test_loader) if acc > Best_ACC: torch.save(model, file_dir + '/' + 'best.pth') Best_ACC = acc print('\nVal set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format( avgloss, correct, len(test_loader.dataset), 100 * acc)) return acc定义全局参数
if __name__ == '__main__': # 创建保存模型的文件夹 file_dir = 'resnet' if os.path.exists(file_dir): print('true') os.makedirs(file_dir, exist_ok=True) else: os.makedirs(file_dir) # 设置全局参数 modellr = 1e-4 BATCH_SIZE = 16 EPOCHS = 100 DEVICE = torch.device('cuda' if torch.cuda.is_available() else 'cpu')图像预处理与增强
# 数据预处理7 transform = transforms.Compose([ transforms.RandomRotation(10), transforms.GaussianBlur(kernel_size=(5, 5), sigma=(0.1, 3.0)), transforms.ColorJitter(brightness=0.5, contrast=0.5, saturation=0.5), transforms.Resize((224, 224)), transforms.ToTensor(), transforms.Normalize(mean=[0.44127703, 0.4712498, 0.43714803], std=[0.18507297, 0.18050247, 0.16784933]) ]) transform_test = transforms.Compose([ transforms.Resize((224, 224)), transforms.ToTensor(), transforms.Normalize(mean=[0.44127703, 0.4712498, 0.43714803], std=[0.18507297, 0.18050247, 0.16784933]) ])读取数据
使用pytorch默认读取数据的方式。
# 读取数据 dataset_train = datasets.ImageFolder('data/train', transform=transform) dataset_test = datasets.ImageFolder("data/val", transform=transform_test) with open('class.txt', 'w') as file: file.write(str(dataset_train.class_to_idx)) with open('class.json', 'w', encoding='utf-8') as file: file.write(json.dumps(dataset_train.class_to_idx)) # 导入数据 train_loader = torch.utils.data.DataLoader(dataset_train, batch_size=BATCH_SIZE, shuffle=True) test_loader = torch.utils.data.DataLoader(dataset_test, batch_size=BATCH_SIZE, shuffle=False)设置模型和Loss
# 实例化模型并且移动到GPU criterion = nn.CrossEntropyLoss() model_ft = ResNet18() print(model_ft) num_ftrs = model_ft.fc.in_features model_ft.fc = nn.Linear(num_ftrs, 12) model_ft.to(DEVICE) # 选择简单暴力的Adam优化器,学习率调低 optimizer = optim.Adam(model_ft.parameters(), lr=modellr) cosine_schedule = optim.lr_scheduler.CosineAnnealingLR(optimizer=optimizer, T_max=20, eta_min=1e-9) # 训练 val_acc_list= {} for epoch in range(1, EPOCHS + 1): train(model_ft, DEVICE, train_loader, optimizer, epoch) cosine_schedule.step() acc=val(model_ft, DEVICE, test_loader) val_acc_list[epoch]=acc with open('result_student.json', 'w', encoding='utf-8') as file: file.write(json.dumps(val_acc_list)) torch.save(model_ft, 'resnet/model_final.pth')完成上面的代码就可以开始训练Student网络了。
蒸馏学生网络
学生网络继续选用ResNet18,使用Teacher网络蒸馏学生网络,训练100个epoch。
IRG知识蒸馏的脚本详见:
https://wanghao.blog.csdn.net/article/details/127802486?spm=1001.2014.3001.5502。
代码如下:
irg.py
from __future__ import absolute_importfrom __future__ import print_functionfrom __future__ import divisionimport torchimport torch.nn as nnimport torch.nn.functional as Fclass IRG(nn.Module):'''Knowledge Distillation via Instance Relationship Graphhttp://openaccess.thecvf.com/content_CVPR_2019/papers/Liu_Knowledge_Distillation_via_Instance_Relationship_Graph_CVPR_2019_paper.pdfThe official code is written by Caffehttps://github.com/yufanLIU/IRG'''def __init__(self, w_irg_vert, w_irg_edge, w_irg_tran):super(IRG, self).__init__()self.w_irg_vert = w_irg_vertself.w_irg_edge = w_irg_edgeself.w_irg_tran = w_irg_trandef forward(self, irg_s, irg_t):fm_s1, fm_s2, feat_s, out_s = irg_sfm_t1, fm_t2, feat_t, out_t = irg_tloss_irg_vert = F.mse_loss(out_s, out_t)irg_edge_feat_s = self.euclidean_dist_feat(feat_s, squared=True)irg_edge_feat_t = self.euclidean_dist_feat(feat_t, squared=True)irg_edge_fm_s1 = self.euclidean_dist_fm(fm_s1, squared=True)irg_edge_fm_t1 = self.euclidean_dist_fm(fm_t1, squared=True)irg_edge_fm_s2 = self.euclidean_dist_fm(fm_s2, squared=True)irg_edge_fm_t2 = self.euclidean_dist_fm(fm_t2, squared=True)loss_irg_edge = (F.mse_loss(irg_edge_feat_s, irg_edge_feat_t) + F.mse_loss(irg_edge_fm_s1, irg_edge_fm_t1 ) + F.mse_loss(irg_edge_fm_s2, irg_edge_fm_t2 )) / 3.0irg_tran_s = self.euclidean_dist_fms(fm_s1, fm_s2, squared=True)irg_tran_t = self.euclidean_dist_fms(fm_t1, fm_t2, squared=True)loss_irg_tran = F.mse_loss(irg_tran_s, irg_tran_t)# print(self.w_irg_vert * loss_irg_vert)# print(self.w_irg_edge * loss_irg_edge)# print(self.w_irg_tran * loss_irg_tran)# print()loss = (self.w_irg_vert * loss_irg_vert +self.w_irg_edge * loss_irg_edge +self.w_irg_tran * loss_irg_tran)return lossdef euclidean_dist_fms(self, fm1, fm2, squared=False, eps=1e-12):'''Calculating the IRG Transformation, where fm1 precedes fm2 in the network.'''if fm1.size(2) > fm2.size(2):fm1 = F.adaptive_avg_pool2d(fm1, (fm2.size(2), fm2.size(3)))if fm1.size(1) < fm2.size(1):fm2 = (fm2[:,0::2,:,:] + fm2[:,1::2,:,:]) / 2.0fm1 = fm1.view(fm1.size(0), -1)fm2 = fm2.view(fm2.size(0), -1)fms_dist = torch.sum(torch.pow(fm1-fm2, 2), dim=-1).clamp(min=eps)if not squared:fms_dist = fms_dist.sqrt()fms_dist = fms_dist / fms_dist.max()return fms_distdef euclidean_dist_fm(self, fm, squared=False, eps=1e-12): '''Calculating the IRG edge of feature map. '''fm = fm.view(fm.size(0), -1)fm_square = fm.pow(2).sum(dim=1)fm_prod = torch.mm(fm, fm.t())fm_dist = (fm_square.unsqueeze(0) + fm_square.unsqueeze(1) - 2 * fm_prod).clamp(min=eps)if not squared:fm_dist = fm_dist.sqrt()fm_dist = fm_dist.clone()fm_dist[range(len(fm)), range(len(fm))] = 0fm_dist = fm_dist / fm_dist.max()return fm_distdef euclidean_dist_feat(self, feat, squared=False, eps=1e-12):'''Calculating the IRG edge of feat.'''feat_square = feat.pow(2).sum(dim=1)feat_prod = torch.mm(feat, feat.t())feat_dist = (feat_square.unsqueeze(0) + feat_square.unsqueeze(1) - 2 * feat_prod).clamp(min=eps)if not squared:feat_dist = feat_dist.sqrt()feat_dist = feat_dist.clone()feat_dist[range(len(feat)), range(len(feat))] = 0feat_dist = feat_dist / feat_dist.max()return feat_dist步骤
新建kd_train.py,插入代码:
导入需要的库
import torch.optim as optimimport torchimport torch.nn as nnimport torch.nn.parallelimport torch.utils.dataimport torch.utils.data.distributedimport torchvision.transforms as transformsfrom torchvision import datasetsfrom model.resnet import ResNet18import jsonimport osfrom irg import IRG定义训练和验证函数
# 定义训练过程def train(s_net,t_net, device, criterionCls,criterionKD,train_loader, optimizer, epoch): s_net.train() sum_loss = 0 total_num = len(train_loader.dataset) print(total_num, len(train_loader)) for batch_idx, (data, target) in enumerate(train_loader): data, target = data.to(device), target.to(device) optimizer.zero_grad() l1_out_s,l2_out_s,l3_out_s,l4_out_s,fea_s, out_s = s_net(data) cls_loss = criterionCls(out_s, target) l1_out_t,l2_out_t,l3_out_t,l4_out_t,fea_t, out_t = t_net(data) # 训练出教师的 teacher_output kd_loss = criterionKD([l3_out_s, l4_out_s, fea_s, out_s], [l3_out_t.detach(), l4_out_t.detach(), fea_t.detach(), out_t.detach()]) * lambda_kd loss = cls_loss + kd_loss loss.backward() optimizer.step() print_loss = loss.data.item() sum_loss += print_loss if (batch_idx + 1) % 10 == 0: print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format( epoch, (batch_idx + 1) * len(data), len(train_loader.dataset), 100. * (batch_idx + 1) / len(train_loader), loss.item())) ave_loss = sum_loss / len(train_loader) print('epoch:{},loss:{}'.format(epoch, ave_loss))Best_ACC=0# 验证过程@torch.no_grad()def val(model, device,criterionCls, test_loader): global Best_ACC model.eval() test_loss = 0 correct = 0 total_num = len(test_loader.dataset) print(total_num, len(test_loader)) with torch.no_grad(): for data, target in test_loader: data, target = data.to(device), target.to(device) l1_out_s, l2_out_s, l3_out_s, l4_out_s, fea_s, out_s = model(data) loss = criterionCls(out_s, target) _, pred = torch.max(out_s.data, 1) correct += torch.sum(pred == target) print_loss = loss.data.item() test_loss += print_loss correct = correct.data.item() acc = correct / total_num avgloss = test_loss / len(test_loader) if acc > Best_ACC: torch.save(model, file_dir + '/' + 'best.pth') Best_ACC = acc print('\nVal set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format( avgloss, correct, len(test_loader.dataset), 100 * acc)) return acc定义全局参数
if __name__ == '__main__': # 创建保存模型的文件夹 file_dir = 'resnet_kd' if os.path.exists(file_dir): print('true') os.makedirs(file_dir, exist_ok=True) else: os.makedirs(file_dir) # 设置全局参数 modellr = 1e-4 BATCH_SIZE = 16 EPOCHS = 100 DEVICE = torch.device('cuda' if torch.cuda.is_available() else 'cpu') w_irg_vert=0.1 w_irg_edge=5.0 w_irg_tran=5.0 lambda_kd=1.0图像预处理与增强
# 数据预处理7 transform = transforms.Compose([ transforms.RandomRotation(10), transforms.GaussianBlur(kernel_size=(5, 5), sigma=(0.1, 3.0)), transforms.ColorJitter(brightness=0.5, contrast=0.5, saturation=0.5), transforms.Resize((224, 224)), transforms.ToTensor(), transforms.Normalize(mean=[0.44127703, 0.4712498, 0.43714803], std=[0.18507297, 0.18050247, 0.16784933]) ]) transform_test = transforms.Compose([ transforms.Resize((224, 224)), transforms.ToTensor(), transforms.Normalize(mean=[0.44127703, 0.4712498, 0.43714803], std=[0.18507297, 0.18050247, 0.16784933]) ])读取数据
使用pytorch默认读取数据的方式。
# 读取数据 dataset_train = datasets.ImageFolder('data/train', transform=transform) dataset_test = datasets.ImageFolder("data/val", transform=transform_test) with open('class.txt', 'w') as file: file.write(str(dataset_train.class_to_idx)) with open('class.json', 'w', encoding='utf-8') as file: file.write(json.dumps(dataset_train.class_to_idx)) # 导入数据 train_loader = torch.utils.data.DataLoader(dataset_train, batch_size=BATCH_SIZE, shuffle=True) test_loader = torch.utils.data.DataLoader(dataset_test, batch_size=BATCH_SIZE, shuffle=False)设置模型和Loss
model_ft = ResNet18() print(model_ft) num_ftrs = model_ft.fc.in_features model_ft.fc = nn.Linear(num_ftrs, 12) model_ft.to(DEVICE) # 选择简单暴力的Adam优化器,学习率调低 optimizer = optim.Adam(model_ft.parameters(), lr=modellr) cosine_schedule = optim.lr_scheduler.CosineAnnealingLR(optimizer=optimizer, T_max=20, eta_min=1e-9) teacher_model=torch.load('./CoatNet/best.pth') teacher_model.eval() # 实例化模型并且移动到GPU criterionKD = IRG(w_irg_vert, w_irg_edge, w_irg_tran) criterionCls = nn.CrossEntropyLoss() # 训练 val_acc_list= {} for epoch in range(1, EPOCHS + 1): train(model_ft,teacher_model, DEVICE,criterionCls,criterionKD, train_loader, optimizer, epoch) cosine_schedule.step() acc=val(model_ft,DEVICE,criterionCls , test_loader) val_acc_list[epoch]=acc with open('result_kd.json', 'w', encoding='utf-8') as file: file.write(json.dumps(val_acc_list)) torch.save(model_ft, 'resnet_kd/model_final.pth')完成上面的代码就可以开始蒸馏模式!!!
结果比对
加载保存的结果,然后绘制acc曲线。
import numpy as npfrom matplotlib import pyplot as pltimport jsonteacher_file='result.json'student_file='result_student.json'student_kd_file='result_kd.json'def read_json(file): with open(file, 'r', encoding='utf8') as fp: json_data = json.load(fp) print(json_data) return json_datateacher_data=read_json(teacher_file)student_data=read_json(student_file)student_kd_data=read_json(student_kd_file)x =[int(x) for x in list(dict(teacher_data).keys())]print(x)plt.plot(x, list(teacher_data.values()), label='teacher')plt.plot(x,list(student_data.values()), label='student without KD')plt.plot(x, list(student_kd_data.values()), label='student with KD')plt.title('Test accuracy')plt.legend()plt.show()总结
本文重点讲解了如何使用IRG知识蒸馏算法对Student模型进行蒸馏。希望能帮助到大家,如果觉得有用欢迎收藏、点赞和转发;如果有问题也可以留言讨论。
本次实战用到的代码和数据集详见:

