Seata分布式事务—事务分组及高可用
目录
1、事务组与集群简介
- 事务分组:seata的资源逻辑,可以按微服务的需要,在应用程序(客户端)对自行定义事务分组,每组取一个名字。
- 集群:seata-server服务端一个或多个节点组成的集群cluster。 应用程序(客户端)使用时需要指定事务逻辑分组与Seata服务端集群的映射关系,Seata中配置相同的cluster名称就表示组成一个集群组。
事务分组如何找到Seata集群:
- 首先应用程序(客户端)中通过
seata.tx-service-group配置了事务分组。 - 应用程序(客户端)会通过用户配置的配置中心去寻找service.vgroupMapping .[事务分组配置项],取得配置项的值就是TC集群的名称。若应用程序是SpringBoot则通过seata.service.vgroup-mapping.事务分组名=集群名称 配置
- 拿到集群名称程序通过一定的前后缀+集群名称去构造服务名,各配置中心的服务名实现不同(前提是Seata-Server已经完成服务注册,且Seata-Server向注册中心报告cluster名与应用程序(客户端)配置的集群名称一致)
- 拿到服务名去相应的注册中心去拉取相应服务名的服务列表,获得后端真实的TC服务列表(即Seata-Server集群节点列表)
seata: # 事务组的名称,对应service.vgroupMapping.default_tx_group=xxx中配置的default_tx_group tx-service-group: default_tx_group # 配置事务组与集群的对应关系 service: vgroup-mapping: # default_tx_group为事务组的名称,default为集群名称 default_tx_group: default2、实践一:异地多机房容灾方案
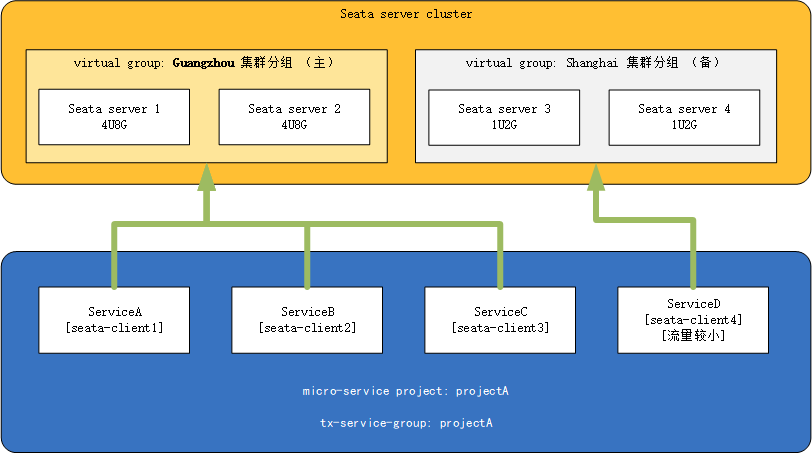
- 假定Seata集群部署在两个机房:guangzhou机房(主)和shanghai机房(备)各两个实例
- 一整套微服务架构项目:projectA
- projectA内有微服务:serviceA、serviceB、serviceC 和 serviceD
- projectA所有微服务的事务分组tx-service-group设置为:projectA,projectA正常情况下使用guangzhou的Seata集群(主)
关系图:
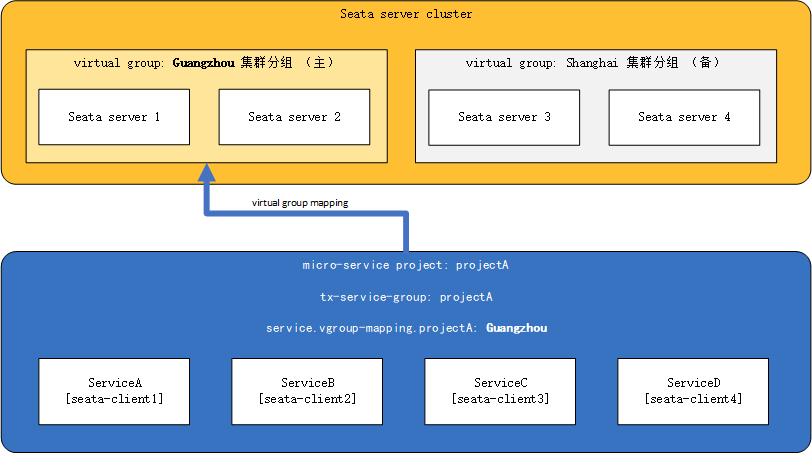
guangzhou机房的registry.conf配置:
registry { type = "nacos" .... nacos { cluster = "guangzhou" .... }}guangzhou机房的Nacos配置中心:
service.vgroupMapping.projectA=guangzhouCloud客户端配置:
seata: tx-service-group: projectA # 配置事务组与集群的对应关系 service: vgroup-mapping: projectA: guangzhou假如此时guangzhou集群分组整个down掉,或者因为网络原因projectA暂时无法与Guangzhou机房通讯,那么我们将配置中心中的Guangzhou集群分组改为Shanghai,如下:
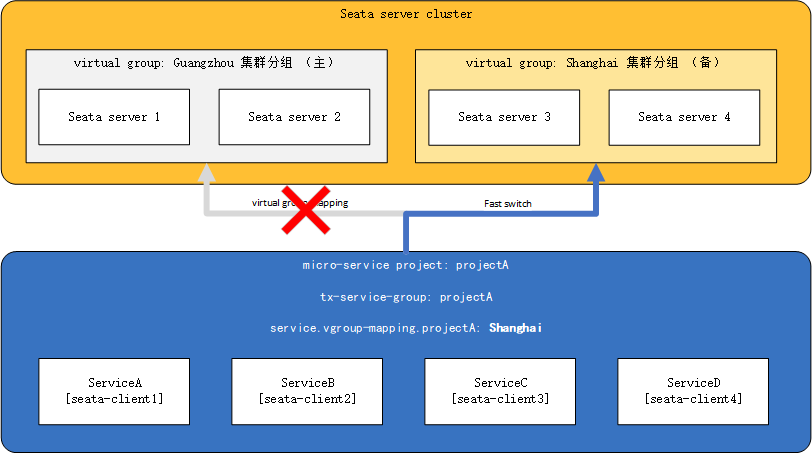
Shanghai机房的registry.conf配置:
registry { type = "nacos" .... nacos { cluster = "shanghai" .... }}Shanghai机房的Nacos配置中心:
service.vgroupMapping.projectA=shanghaiCloud客户端配置:
seata: tx-service-group: projectA # 配置事务组与集群的对应关系 service: vgroup-mapping: projectA: shanghai通过配置多套集群环境,在某个集群环境出现故障时,直接切换服务的事务分组与集群对应关系,实现快速的容灾处理
3、实践二:单环境多应用接入方案
假设只有一套seata集群,该集群中的六个seata实例,我们可以将这六个实例进行两两分组,形成三个事务组,这样就可以使用一套seata集群服务三个不同得项目。
比如:
集群名称分别为:project-a-group、project-b-group、project-c-group
事务组名称分别为:project-A、project-B、project-C
关系图:
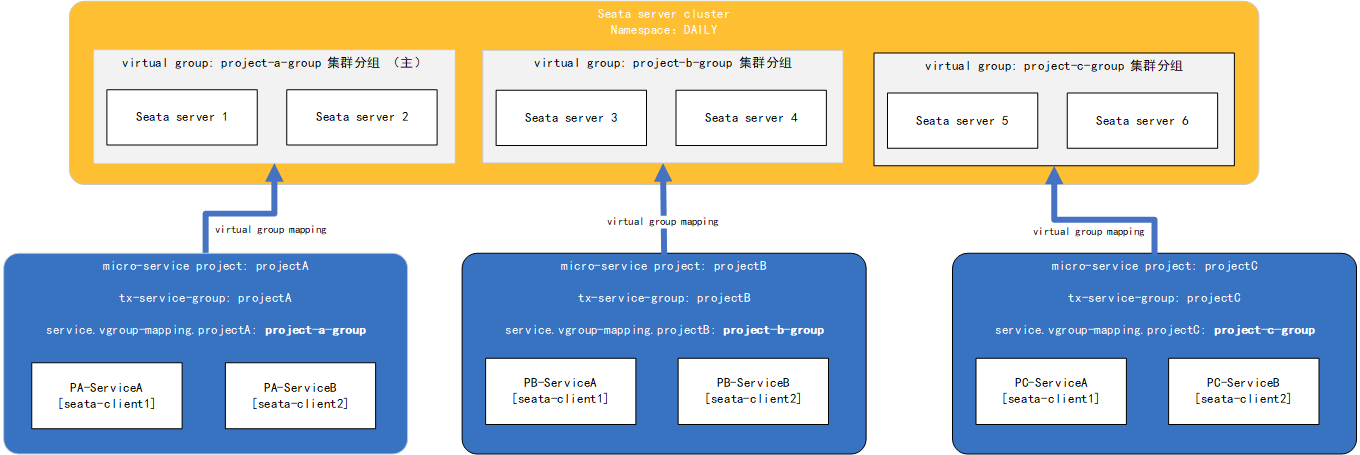
registry.conf配置:
registry { type = "nacos" .... nacos { #同理在其他几个分组seata-server实例配置 project-b-group / project-c-group cluster = "project-a-group" .... }}Nacos配置中心:
# 其他几个分组seata-server实例配置 project-B=project-b-group / project-C=project-c-groupservice.vgroupMapping.project-A=project-a-groupCloud客户端配置:
seata: # 同理,projectB与projectC配置 project-B / project-Cs tx-service-group: project-A # 配置事务组与集群的对应关系 service: vgroup-mapping: # 同理,projectB与projectC配置 project-B:project-b-group / project-C:project-c-group project-A: project-a-group4、实践三:client的精细化控制
- 假定现在存在seata集群,Guangzhou机房实例运行在性能较高的机器上,Shanghai集群运行在性能较差的机器上
- 现存微服务架构项目projectA、projectA中有微服务ServiceA、ServiceB、ServiceC与ServiceD
- 其中ServiceD的流量较小,其余微服务流量较大
那么此时,我们可以将ServiceD微服务引流到Shanghai集群中去,将高性能的服务器让给其余流量较大的微服务(反之亦然,若存在某一个微服务流量特别大,我们也可以单独为此微服务开辟一个更高性能的集群,并将该client的group指向该集群,其最终目的都是保证在流量洪峰时服务的可用)